DiffRank-RF差异网络分析方法的研究与应用*
2019-11-12蔡雨晴李轶群王文杰
蔡雨晴 李轶群 徐 欢 宋 微 杨 凯 王文杰 李 康△
1.哈尔滨医科大学卫生统计学教研室(150081)2.哈尔滨工业大学生命科学与技术学院
差异表达分析常被用于各种疾病标志物的筛选研究中,如传统的t检验、显著性分析(significance of microarrays,SAM)检验、偏最小二乘(pa least square,PLS)等方法。然而,这些方法主要是通过比较不同分组之间基因表达均值的差异筛选标记物,忽视了物质之间的相互调控关系,致使研究结果不够稳定或检验效率低。在组学研究中,由于基因调控和蛋白质的互相作用,很有可能在表达量上还没有呈现出明显差别时,在调控关系上已经发生了一定的改变。差异网络分析方法更加注重不同分组情况下调控关系和网络拓扑结构的差别,并由此筛选出具有潜在生物学意义的标记物。本文提出DiffRank-RF差异网络分析方法,通过模拟实验评价该方法的准确性和适用条件,并与传统的变量筛选方法进行比较,最后应用于乳腺癌实际数据,得到相应的分析结果。
原理与方法
1.基本思想
随机森林方法提高了预测精度,对多重共线性不敏感。利用随机森林(random forest,RF)回归模型,可以建立任一变量Xk对其它变量的回归模型:
Xk=RF(X1,X2,…,Xk-1,Xk+1,…,Xm)+ε
网络共有m个变量,其中ε为模型的残差。根据衡量变量重要的VIM值作为有向连接两节点的权重,可以建立RF网络[1]。利用R包randomForest即可实现通过随机森林回归构建网络。
差异网络分析使用DiffRank[2]算法。首先根据随机森林(RF)构建网络,再结合网络拓扑结构的局部指标连接权重(connectivity)、度(degree)以及全局指标最短路径(shortest path)等统计量发现导致网络差异的重要变量。连接权重即变量之间的关联强弱,可用RF建网得到的VIM值度量,并用连接边线的粗细表示权重大小(见图1)。度是在网络中某一变量的连接边数量,图1中可见变量G1的度为5。DiffRank-RF算法将被分析节点的所有直接连接点的权重进行相加得到网络局部测量指标ΔC。最短路径是指变量间权重之和最小的一条连接路径,DiffRank-RF计算经过节点的最短路径数量占所有最短路径数量的比值来表示节点的中介中心性(between centrality,BC),可以分析网络中所有节点(包括直接连接点和间接连接点)对被分析节点的影响。当节点的度或连接权重较小,却经过网络的多数最短路径时,仍可认为该节点是网络中的重要节点,ΔBC值能够反映这一现象。
2.统计量计算
DiffRank-RF计算局部结构改变测量指标ΔC和全局结构改变测量指标ΔBC的公式分别为
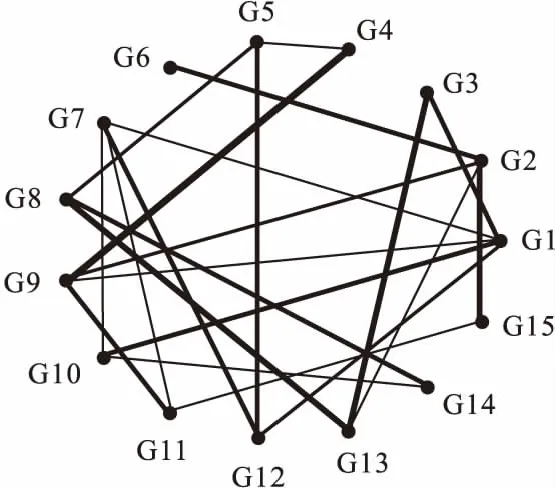
图1 网络示例图
(1)
(2)
(3)
其中,A和B分别代表两个不同分组情况下随机森林回归所构建的网络,分别包含N个变量。VIM是随机森林得到的变量重要性评分,表示变量v与其它相连变量的连接权重。πvi为变量v在网络中第i次迭代的差异评分,用参数λ结合两部分指标,λ取值范围为[0,1],可根据模拟试验选取不同情况下合适的λ值。任一变量的π初始值可设为1/N,结果收敛时循环停止。SPv(s,t)可表示为通过变量v的一个N×N矩阵,在网络中任意两变量s、t的最短路径若通过变量v,则在矩阵中用1表示,否则用0表示。ΔBC(v)计算通过变量v的最短路径数量来反映变量v在网络中的中介中心性。基于每一变量的差异评分π给所有变量排序,π越大表示在差异网络中贡献最大,即所筛选的差异位点。
模拟研究
1.模拟实验目的:通过模拟实验评价DiffRank-RF算法在不同样本量情况下筛选差异位点的准确性和稳定性,同时与SAM、PLS方法进行比较,探讨DiffRank-RF算法最优的适用范围和λ参数设置。
2.模拟实验设置:有向模拟网络设置20个变量和25条有向边(见图2),包括变量间的线性调控和非线性调控关系和交互作用,其中线性关系由线性方程产生,相关系数为随机产生的固定值,误差从正态分布中随机抽样,非线性关系在线性基础上指数形式产生。实验设置样本量分别为50,100,200,500和1000。对样本数据应用随机森林回归方法构建两个网络,通过DiffRank-RF进行差异网络分析,分别使用AUC值及预测准确率(PRE)指标与SAM和PLS方法进行比较。以上过程随机重复100次。
3.阈值选择:随机森林构建网络时,VIM值通过置换检验可以得到其均值的随机分布,选取95%分位数为阈值以判断节点之间是否存在真实边。在进行预测准确率比较时,选取PLS结果中VIP、SAM得分、DiffRank-RF结果秩次排在前5位的变量为预测差异变量。
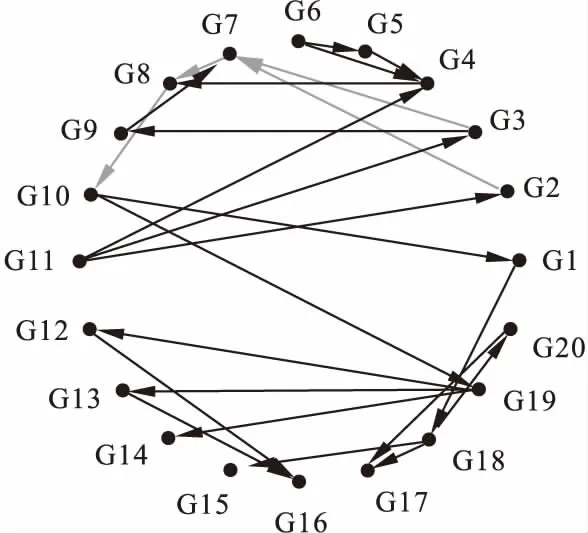
图2 有向网络模拟实验设置条件
4.模拟实验结果:表1模拟实验结果显示,在AUC评价中,DiffRank-RF方法在λ=0.5时随样本量增加AUC值增加最明显,但稳定性较差(见图3A),λ=1时稳定性最优,综合看来λ=0.75效果最好,且DiffRank-RF不管λ取何值时,效果都优于SAM和PLS方法。随样本量逐渐增加,DiffRank-RF、SAM和PLS方法AUC值都越高,当样本量大于200时效果趋于平缓,PRE指标在DiffRank-RF方法λ=0.75时要优于其他情况(图3B)。

表1 DiffRank-RF差异网络分析与SAM、PLS比较结果

图3 DiffRank-RF差异网络分析与SAM、PLS的准确性比较
实例分析
数据来源:TCGA数据库中531例乳腺癌患者及63例对照的mRNA基因表达数据,选取p53信号通路进行分析。分别选取λ=0、0.75和1,对这条通路内所有基因进行DiffRank-RF差异网络分析,分析结果见表2。
结果显示,DiffRank-RF差异网络分析方法λ取0和0.75时筛选的变量有较大重叠,而与λ=1时相比差别较大;同时可以看到DiffRank-RF方法筛选的变量与传统的SAM和PLS相比差别较大,几乎无重叠。SAM和PLS两种方法之间筛选出的结果则十分相近。

表2 乳腺癌与对照数据使用三种方法筛选变量的结果(排序前10)
通过文献查阅,CDK4是细胞周期中G1-S期调控的中心基因,已发现CDK4的高表达广泛存在于人类的多种肿瘤中,CDK4的异常表达与肿瘤的发生密切相关。CDK4、CDKN2A(p16)和CDK2同属于CDK家族与细胞周期调控有关的基因,其中CDKN2A是CDK4的抑制因子,阻止细胞进入S期,同时对CDK2也有抑制作用[3],有研究表明CDKN2A改变会影响乳腺癌患者的生存和预后[4]。PTEN是继p53后另一个较为广泛地与肿瘤发生关系密切的基因,对细胞周期进展和细胞凋亡有重要作用,同时,PTEN与CDK2抑制剂(CDKN1A)对卵巢癌细胞生长抑制具有协同作用[5]。在细胞凋亡的调控过程中,CASP3和CASP8发挥了关键作用,其中CASP3的高表达与乳腺癌生存时间有显著性关系[6]。使用GeneMINIA[7]基因/蛋白互作网络数据库可以将筛选出的基因画出网络图,图4给出了DiffRank-RF方法在λ=0.75时的网络示意图。

图4 DiffRank-RF分析结果在GeneMINIA中的关系示意图
讨 论
传统的差异基因筛选方法主要是根据基因表达量在不同分组中的差异进行筛选。实际的基因网络有可能其表达量改变不大,但其调控关系发生变化,此时传统方法有较低的检验效率,本文给出的DiffRank-RF方法则能够充分反映不同组间调控网络的差异,筛选出重要的基因。
已有的多种网络构建方法中,随机森林方法能够识别变量之间的非线性关系和交互作用,且随机森林可以构建有向网络。由于基因之间的调控通常为有向的,因此DiffRank-RF方法具有明显的优势。
DiffRank-RF算法根据λ不同取值能够发现网络中不同功能的基因,当λ=1时,基因排序靠前,表明该基因与直接关联基因的调控关系较强或直接关联基因数量较多,即在网络局部作用较大;当λ=0时,基因排序靠前,表明其在网络中的中介中心性较高,可被视为网络的中心基因,参与网络的全局调控。需要注意:当变量数目较少时,网络中的最短路径数量也会相对减少,此时全局指标(最短路径算法)应用有限,应更多的利用连接权重进行差异网络分析,λ可适当取较大的值;而当变量数目较多时,结合全局指标能够纳入更多生物学信息,此时建议λ取值0.75。
本文在筛选变量时,主要根据评价统计量值的大小排序选择最前面的基因。为了能够对其进行检验,可以使用置换检验的方法,根据检验的P值进行筛选。
