考虑匹配可行性的长期合乘问题建模与求解*
2019-11-12郭羽含胡芳霞
郭羽含,胡芳霞
辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105
1 引言
近年来,我国私家车保有量大幅增长,使出行车辆数量迅速增加,产生了城市交通拥堵、通行速度减慢、空气污染和停车困难等问题[1]。公共交通可以有效缓解城市交通拥堵,但其灵活性、舒适度和自由度低于私家车,因此私家车出行仍是迄今为止最受欢迎的通勤方式。然而,私家车占据大量道路通行空间,却空载率很高,一辆私家车通常只运送1~2 个人。通过车辆合乘可以提高座位利用率并有效减少私家车出行数量,是一种环境友好且可持续的出行方式,对于减少碳排放、停车位需求以及缓解交通压力具有重要意义。此外,合乘可以减少参与用户的人均出行成本(比如油费、过路费)以及驾驶交通工具带来的压力[2-3]。
车辆合乘(car pooling,CP)又称共乘或者拼车,是指用户在出行时,与出行时间和目的地相同或相近的用户共享车辆,以减少往返于目的地的车辆数量[3]。实际操作中出现了两种不同形式的车辆合乘问题。第一种是单次车辆合乘问题(daily car pooling problem,DCPP),即事先知道某一天可用的司机和车辆,问题在于将用户和司机进行匹配,并确定司机的驾驶路径,在满足时间窗和车容量限制的基础上,最小化服务成本和未分配用户的惩罚值之和[4-5]。第二种是长期车辆合乘问题(long-term car pooling problem,LTCPP),将参与合乘的用户分为若干合乘小组,其合乘关系长期保持,每天由组内成员轮流担任司机,目标是划分用户以及确定每组中各成员担任司机时的驾驶路径,以最小化每天的行驶总距离,同样受车容量和时间窗限制[6]。此外,存在两种车辆合乘问题的变型。在第一个变型中,共享乘车去程的合乘组也将同样共享返程。在第二个变型中,去程和返程的问题是不同的,需独立解决。本文研究车辆合乘问题的第二种形式的第一个变型,即长期车辆合乘去程问题。
尽管车辆合乘是减少交通拥堵及其相关诱导效应的有效手段,但相关的研究还处在起步阶段。Baldacci等人为组织员工通勤合乘的公司提出了一种基于拉格朗日列生成的精确方法[4],但Varrentrapp 等人证明了LTCPP 是NP 完全问题[7],因此精确算法只能处理小规模问题。对于大规模问题,无法利用计算机在多项式时间内找出全局最优解。因此,为了在可接受的计算时间内获得较优的解决方案,近似算法、启发式和元启发式算法被设计用于解决车辆合乘问题。例如,Manzini 和Pareschi 提出了一种解决LTCPP 的基于聚类分析的分层方法,用于合乘组的形成以及寻找最优的车辆路径。基于该方法,作者还介绍一个原创的决策支持系统[8]。Yan等人使用网络流技术构建一个LTCPP 的模型,并通过拉格朗日松弛算法解决该模型[9]。Hussain 等人设计了一个基于智能体的框架用于求解LTCPP,介绍了沟通、协商和协调的概念,并考虑了灵活的活动调度[10]。Filcek等人研究了考虑驾驶员和乘客的不同方面和相互矛盾的偏好的多标准合乘优化问题,通过加权函数聚合所有标准,然后设计了启发式规则匹配合乘组以及应用贪婪算法为所有的合乘组生成最佳的驾驶路线[11]。相近的研究领域,邵增珍等人针对单车辆合乘问题,提出基于匹配度的聚类算法,用于将服务需求分配到具体某一辆车,且实现了车辆及服务需求的双向优选[12]。针对确定性多车辆合乘匹配问题,提出针对服务需求分派的启发式聚类算法[13]。此外,已有关于车辆合乘方面的实际应用。Bruck 等人介绍了一家意大利服务公司的实际车辆合乘案例,开发了一个集成的Web 应用程序,供该公司的员工每天组织合乘人员,使用数学公式和启发式算法寻找可能的合乘方案,结果表明通过合乘可以有效减少CO2排放[14]。Bruglieri 等人[15]介绍了一个实际项目PoliUni-Pool,旨在为大学提供车辆合乘服务。
现有的研究大多只考虑用户间的地理距离,就近匹配生成合乘组,以最小化所有用户前往目的地所行驶的路径距离之和。从社会角度来看,这一目标非常重要,因为它有助于减少污染(排放)和交通拥堵。该目标还与最小化总出行成本相一致,这是用户选择合乘的重要考虑因素。但是,以行驶总距离作为单一的优化目标,得到的合乘方案往往实际操作中缺乏可行性。因为它忽略了合乘组成员构成、合乘所导致的用户额外驾驶时间以及用户的启程时间和到达时间等。其中,合乘组成员构成是指在一个合乘组中各个成员所具有的各项个体特征的分布和组成情况。经调研发现,合乘组成员的性别、年龄、社会关系、历史评价等个体特征是影响用户参与合乘以及合乘关系长久保持的重要因素。(1)性别:目前,女性出行安全已成为社会关注的焦点,为了降低危险系数,应尽量使合乘组成员中女性结伴出行,避免出现一名女性单独与男性合乘。(2)年龄:一般而言,年龄差越小,用户的观念和兴趣差异越小,沟通和相处越容易,合乘关系更容易长久保持。(3)社会关系:本文只考虑同事关系,优先将具有同事关系的用户分在同一个合乘组,可以降低由陌生人带来的不确定危险因素。(4)历史评价:减少匹配到历史评价较差的用户,可以有效降低合乘的不稳定因素,确保长期的合乘关系。除了需要考虑合乘组成员构成外,合乘所导致的用户额外驾驶时间以及用户的启程到达时间也是影响匹配可行性的重要因素。额外驾驶时间过长、用户实际启程到达时间与用户期望的时间的差距过大会降低用户合乘的积极性,进而影响合乘关系的长久保持。因此,为了获得长久稳定的合乘关系,考虑匹配可行性是非常必要的。此外,现有的研究在求解大规模的车辆合乘问题上存在局限性。
针对以上问题,本文基于匹配可行性,构建了带有车容量和时间窗约束的多目标优化模型,并提出了一种有效的分布式聚类蚁群算法(distributed clustering ant colony algorithm,DCAC)用于高效地求解LTCPP。该算法在生成合乘组期间,除了以用户间地理距离作为分组依据外,还考虑了用户的性别、年龄、社会关系、历史评价等个体特征等。此外,该算法应用了Spark编程模型,可以分布式并行地运行在Spark 集群或云计算平台中,可高效求解大规模的LTCPP。实验结果表明DCAC 能为LTCPP 提供高质量的解,并在处理大规模问题上具有明显优势。
2 问题定义和数学模型
2.1 问题定义
在LTCPP中,每位参与合乘的用户都拥有车辆,且出行时间和目的地相同或相近,问题在于将参与合乘的用户分为若干个合乘小组,每天轮流由一名用户驾车依次接载组内其他成员共同前往目的地,其合乘关系长期保持,以最小化所有用户每日的行驶距离之和,同时受车容量和时间窗限制。LTCPP可以被视为聚类问题和路由问题的组合,即它需要找到相对靠近的合乘组成员,并确定合乘组中每个成员的行驶路线和各成员的接载时间表。图1 显示了一个合乘小组每日出行情况。

Fig.1 Example of car pooling图1 一个合乘组示例
本文使用有向图G=
LTCPP 包括划分用户形成合乘组及确定合乘组中每个成员的行驶路线和各成员的接载时间表。下面将介绍有效路径、有效合乘组、有效合乘方案的概念。
例如,合乘小组G=(i1,i2,…,im),用户i1作为司机时,驾车依次接载组内成员i2,i3,…,im并到达目的地0,如果满足车容量和时间窗约束,则P=(i1,i2,…,im,0)为有效路径。
(1)车容量约束

(2)时间窗约束
时间窗约束包含两部分内容:①最大驾驶时间约束。路径P的总行驶时间不能超过。②启程/到达时间约束。用表示用户h作为司机时,用户i的启程时间(即用户h接载用户i的时间);表示用户h作为司机时,用户i的到达目的地时间;tij表示顶点i、j间的行驶时间。则需满足:
用户实际启程时间不早于最早启程时间:

用户实际到达时间不晚于最晚到达时间:

相邻接载用户的启程时间之差不小于他们间的行驶时间:

若i1,i2,…,im担任司机时,均存在有效路径,则G为有效合乘组。将用户集合U划分为各个有效合乘组,即得到一个有效合乘方案。LTCPP 的目标是找到最优的合乘方案,以最小化平均每日用户行驶距离之和。
为了增加匹配可行性以及使合乘关系长久保持,本文除了以降低总行驶距离为目标外,新增以下优化目标:
(1)最小化额外驾驶时间。额外驾驶时间是指用户参与合乘导致的相对于单独出行所增加的额外驾驶时间。可以被计算为所有用户额外驾驶时间之和。
(2)最小化实际启程到达时间与用户理想时间的差距。该目标可以被计算为所有用户平均每日实际启程、到达时间与理想启程到达时间差之和。
(3)最小化匹配不可行性。匹配不可行性体现在合乘组成员构成,具体考虑的因素有性别、年龄、是否为同事关系。
2.2 数学模型
2.2.1 集合
U=合乘参与者集合
A=所有有向边集合
K=所有合乘组集合
2.2.2 参数
参数dij、tij、ei、iei、ri、iri、Ti、Qi、gi、ai、ci、si的定义同2.1节,除此之外,有:
w1=所有用户平均每日行驶距离之和权重因子
w2=所有用户平均每日实际启程到达时间与理想时间差值之和的权重因子
w3=所有用户担任司机时的驾驶时间与独自出行时间差值之和的权重因子
w4=所有合乘组不可行级别之和的权重因子
决策变量:
yik=0-1变量,1表示用户i在合乘组k中,0表示不在
φi=0-1变量,1表示用户i与其他用户合乘,0表示用户i单独出行
ti=用户i担任司机时的驾驶时间
Sk=合乘组k的不可行级别
2.2.3 模型

目标函数(1)最大限度地降低了用户每日行驶距离以及匹配的不可行性。它包括(从左到右的顺序)平均每日用户行驶距离之和、所有用户实际启程和到达时间与理想状态的差距之和、所有用户参与合乘产生的额外驾驶时间之和以及所有合乘组的不可行级别之和。
2.2.4 约束
(1)合乘组不可行级别约束关系。在计算合乘组的不可行级别时,考虑的因素有性别、年龄、是否同事关系。分别表示从性别、年龄、是否同事关系角度考虑,合乘组k成员组成的不可行级别,值越大,不可行性越高。Sk为这三者之和。具体计算公式如下:
①性别。令mk、fk分别表示合乘k中男性、女性成员数量,则性别不可行级别可以被计算为当合乘组女性数量少于男性数量时,男性数量与女性数量的差值。具体计算公式如下:

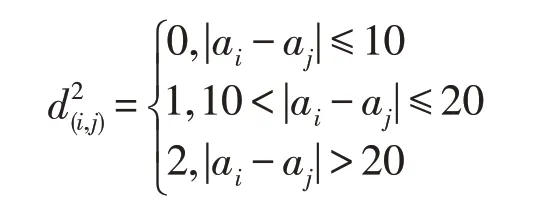

③同事关系。具体计算公式如下:

合乘组k的不可行级别Sk可以通过的求和得到:

(2)约束(3)确保合乘组人数满足车容量约束。

(3)约束(4)确保司机总行驶时间不超过其最大驾驶时间。

(4)约束(5)~(8)确保用户满足启程/到达时间约束。
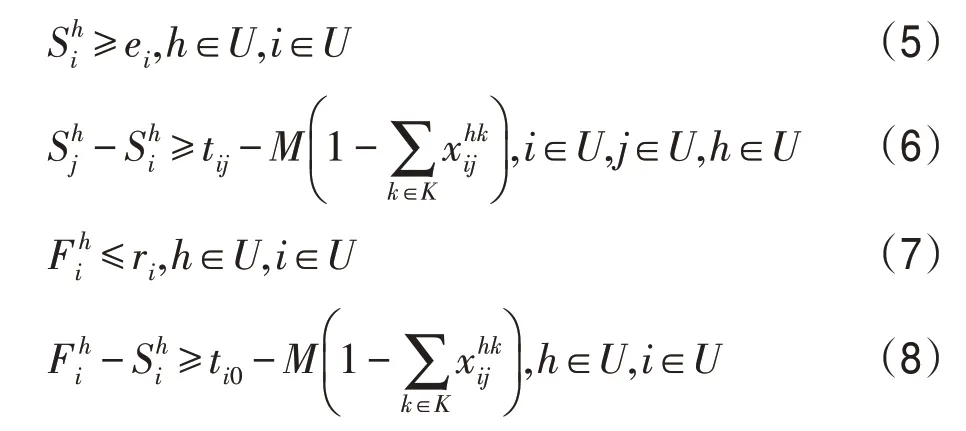
(5)约束(9)~(11)确保若顶点i(或j)在司机h的驾驶路径中,则将用户i(或j)加入合乘组k中。

(6)约束(12)确保用户或者单独驾驶前往或者被划入某一合乘组。

(7)约束(13)~(18)为二进制和非负约束。


3 分布式聚类蚁群算法
LTCPP 是聚类问题和路由问题的组合,其将用户分为各个合乘组,并为各用户规划最佳行驶路径以接载组内其他成员共同前往目的地。蚁群算法是一种模仿蚂蚁觅食行为的启发式算法,最先用于解决旅行商问题(traveling salesman problem,TSP)。与解决TSP 思路类似,让蚂蚁访问所有的用户,即完成蚂蚁的一次旅行,并在蚂蚁旅行访问用户期间进行聚类,形成各个合乘组,再通过枚举法为用户设计最佳的行驶路径。当蚂蚁完成一次旅行时,便可以得到LTCPP 的一个解。此外,蚁群算法具有并行和分布式的特点,因而可以在Apache Spark分布计算框架进行分布式实现,借助云计算平台或集群增强其求解效率,使其能更高效地解决大规模问题。因此,蚁群算法非常适于求解LTCPP,尤其是大规模的LTCPP。
基于上述思路及作者之前的研究[16]提出了分布式聚类蚁群算法(distributed clustering ant colony algorithm,DCAC)用于求解LTCPP。首先,介绍DCAC的非分布式版本聚类蚁群算法(clustering ant colony algorithm,CAC),算法的主要结构见3.1节,3.2节至3.6节对CAC 每个子过程进行具体阐述,3.7 节介绍DCAC。
3.1 主要结构
在CAC中,为了指导蚂蚁的聚类活动,本文引入了偏好和吸引力的概念。其中,偏好信息用来取代传统的信息素,偏好和吸引力的详细定义在3.2 节。求解过程主要分为两个步骤:聚类和路由规划。聚类是通过蚂蚁旅行活动得到分组方案,即定义合乘小组成员;路由规划是在得到分组方案后,定义每位用户担任司机时的最佳行驶路径、各合乘成员的启程到达时间等。
首先,蚂蚁随机选择一个用户作为旅行的起点,并建立一个合乘小组。蚂蚁之后的行为是基于偏好和吸引力的轮盘赌选择,它可以访问一个新用户,并将其插入到当前的合乘小组,或结束当前的合乘小组,并选择一个新用户去开始一个新的合乘小组。当所有的用户都被蚂蚁访问后,蚂蚁的旅行结束。出于降低时间复杂度的考虑,聚类过程中,只检查车容量约束。然后,根据当前分组方案,进行路由规划,在此过程中,进行时间窗约束检查,对于不满足时间窗约束的无效合乘组,将其划分为更小的合乘组直到所有的合乘组都满足时间窗约束为止。最后,选择几个具有最佳适应度的解,应用局部搜索过程进行进一步的优化。改进后的解用于更新偏好信息。通过这种机制,聚类经验总是记忆和更新,以引导未来蚂蚁的搜索。CAC的主要结构如算法1描述。
算法1聚类蚁群算法
1.初始化偏好矩阵和吸引力矩阵;
2.While不满足退出条件do
(1)Fork=1,k≤蚂蚁数量do
聚类:
①选择新用户访问并建立新的合乘小组;
②检查车容量约束:
If车容量已满,转至步骤①;
③基于偏好和吸引力信息以一定的概率选择接下来的操作:
If 选择新用户访问并加入当前合乘组,然后转至步骤②;
Else 结束当前合乘小组并转至步骤①;
Until所有用户都被遍历到;
路由规划:
④计算每位用户作为司机时的最佳行驶路径、行驶时间、各合乘成员的启程和到达时间。对于在计算过程中发现的无效合乘组进行划分,直到所有的合乘组都是有效的;
⑤计算解的适应度;
(2)End for
(3)选择m个具有最佳适应度的解应用局部搜索;
(4)依据改进后的解结构更新偏好矩阵;
(5)记录截止目前的最优解;
3.End while
4.输出最优解;
其中退出条件设置为:迭代次数达到最大迭代次数或者连续迭代达到一定次数,最优解仍未得到改进,程序终止。
3.2 初始化
CAC 算法的第一步是初始化偏好和吸引力矩阵,本节将给出偏好和吸引力信息的定义和计算公式,公式中出现的参数与第2章中介绍的参数相同。
3.2.1 偏好信息
对于任意用户i,j∈U都有一个非负值wij与之关联,它揭示了将用户i和用户j分到同一合乘组的偏好级别。初始偏好值由用户间的地理距离、时间窗差值、是否为同事关系以及用户性别、年龄、历史评价决定,如式(19)所示,其中α,β是调整因子。用户间的地理距离和时间窗差值越大,它们之间的偏好值越小,被分到同一合乘组的机会也越小。出于匹配可行性考虑,增加用户与同性、同年龄段、高历史评价用户间的偏好值。偏好值以百分比γ增加。例如,依照距离和时间窗得到U1 与U2 间的偏好值w12为0.3,若U1 与U2 同性,w12=(1+γ)×0.3,若U1 与U2 年龄差在10 岁以内,则w12再增加γ。同理,若U2 的历史评分高于所有用户的平均分数,则w12继续以百分比γ增加,否则w12保持不变。

对于任一用户i∈U,都有一个非负值wii与之关联,它揭示用户对与其他用户分到一起的容忍程度。初始wii值通过计算用户可额外驾驶时间来评估,如式(20)所示,其中θ是调整因子。用户可额外驾驶时间越短,他/她的服务区域越小,因此用户可能具有较少的合乘成员。

在初始化偏好信息时,需检查时间窗约束(21)~(28)。如果用户i担任司机去接用户j共同前往目的地,约束(21)和(22)检查了用户i和用户j是否都能满足到达时间约束。约束(23)检查对于用户i到达目的地时间来说,用户j的接载时间是否太晚。约束(24)保证用户j居住地在用户i可服务的区域内。

相应的,若用户i与用户j可以被分在一个合乘组,则分别由用户i与用户j担任司机一次,故同样的,需检查用户j作为司机时的时间窗约束(25)~(28)。

如果用户i和j不能满足上述约束,则偏好值wij被设置为0,这意味着用户i和j不可以被蚂蚁聚集在一起。通过这个过程,能够避免生成多数无效合乘组。如果所有约束都能满足,则按照式(19)、式(20)进行初始化。
偏好信息可以被认为是变体信息素信息,可以将它存储在n×n矩阵中,其中n=|U|。
3.2.2 吸引力信息
使用式(29)和式(30)定义用户间的吸引力信息ηij。这两个公式与初始化偏好信息的公式相同,不同的是在初始化吸引力矩阵时,不进行时间窗约束检查,并且不会在每次迭代后进行更新。当偏好信息收敛到最佳值时,吸引力信息可以为算法提供多样性。

其中,α、β、γ和θ与式(19)和式(20)相同。
3.3 聚类
初始化之后,蚂蚁开始旅行访问各用户,并在旅行过程中聚类,形成各个合乘小组。为了避免每次添加用户到合乘组中都进行时间窗检查(启程到达时间约束、最大驾驶时间约束)增加昂贵的时间开销,在蚂蚁旅行过程中,只检查车容量约束。待蚂蚁旅行完成,即得到了一个满足车容量约束的分组方案,时间窗检查将在路由规划阶段进行。图2 展示了蚂蚁旅行产生分组方案的全过程。
首先,蚂蚁会随机选择一个用户访问并开启一个合乘组,如果合乘组人数未达到最大车容量,蚂蚁会通过轮盘赌选择访问下一个用户并添加到当前合乘组,或者直接结束当前合乘组,选中概率如式(31)、式(32)所示。蚂蚁结束当前合乘组后,搜索新用户以启动新的合乘组,用户被选中的概率基于吸引力信息,计算公式如式(34)所示。当所有的用户都被访问,则认为蚂蚁的旅行完成。
在聚类过程中,蚂蚁被赋予在达到车容量之前结束当前合乘组的概率。当合乘组中的现有用户与其他未访问用户具有较低的偏好值时,蚂蚁具有很高的概率结束该合乘组。这是因为所有未被访问的用户添加到当前合成组都是不经济的,所以更好的行为是结束聚类,而不是再将一个用户添加到其中。这种机制在CAC 中是至关重要的,通过它可以避免由于新加入用户距离过远而导致合乘组内部旅行成本过高。同时,除了车容量和时间窗约束之外,它是唯一的对合乘组成员数量进行控制的方式。
式(31)给出了蚂蚁选择新用户j访问并将其插入到当前合乘组k中的概率Psjk。式(32)给出了蚂蚁结束当前合乘组k的概率Pek。


其中,δjk是用户j与合乘组k之间的偏好值,通过式(33)计算得到;ηij是用户i、j之间的吸引值;wii和ηii是用户i与自身的偏好值和吸引力值;K是合乘组k中现有用户的集合;H是尚未访问的用户集合;a和b是调整参数。

当蚂蚁需要建立一个新的合乘组时,吸引力变得至关重要。在蚂蚁结束当前的合乘组后,它将通过轮盘赌选择一个新用户开始一个新的合乘组,找到该用户的概率只受到吸引力的影响。在该过程中,偏好信息被忽略,因为偏好矩阵中的零值将禁用选择一些用户并影响完整解构造的概率。
因此,以类似的方式,蚂蚁搜索一个新用户开始一个新合乘组的概率Pnjk被计算为新用户j与当前合乘组k中现有用户之间的吸引力之和,如式(34)所示。


Fig.2 Travel process of ant图2 蚂蚁旅行过程
其中,ηij是用户i和用户j之间的吸引力值;K是当前合乘组中现有用户的集合;H是尚未访问的用户集合;b是调整参数,同式(31)、式(32)。
3.4 路由规划
得到分组方案后,进行具体的路由规划。路由规划的目的是确定合乘组中用户i担任司机的行驶路径Ri,或者称为接载组内其他成员的次序。此外,需要还记录与行驶路径Ri相对应的其他信息,如用户担任司机时的总驾驶时间disi和时间timi、接载合乘组成员的时间表Ti、到达目的地时间arvi以及用户是与其他用户合乘还是单独出行φi,这些信息在计算解的适应度时会使用,图3显示了一个完整的解决方案表述。

Fig.3 Representation of a solution图3 一个解决方案的表述
当天担任司机的用户从其起点出发,依次接载合乘组内其他成员,共同前往目的地。寻找用户最佳行驶路径,该问题可以看作是不闭合的旅行商问题,即指定起点和终点,寻找连接所有点的最短路径的问题。目前已有多种精确算法(如枚举法、动态规划法)和启发式算法(如贪心算法、蚁群算法)用于求解该问题。在本文环境下,一辆私家车通常最多可搭载5人,加上目的地,点的个数不超过6。以6个点为例,该问题的解空间是除起点和终点外的其他4个点的全排列,可行解个数为24(4!)。由于该问题的解空间极小,采用枚举法便可在很短的时间内得到问题的最优解。具体求解过程如下。
为了得到用户作为司机时的最佳行驶路径,即行驶距离最短(或时间最少),通过对同一合乘组中的其他成员的接载次序全排列得到全部的行驶路径,比较各路径的行驶距离得到最短的行驶路径,并确定其他的路由信息。例如合乘组G=(U1,U2,U3),求解U1 担任司机时的路由信息时,先对U2、U3 进行全排列得到全部行驶路径P1=(U1,U2,U3,0)、P2=(U1,U3,U2,0),进一步计算确认最优的行驶路径。得到路由信息后,计算每个解的适应度。
在这个阶段,进行时间窗检查,不满足时间窗约束的合乘组,通过将其不断划分为更小的合乘组直到所有的合乘组都满足时间窗约束。这些被划分后的合乘组会在后面的局部搜索中进行改进以得到更优分组方案。
3.5 局部搜索
在每次迭代中,待所有蚂蚁完成旅行之后,选择具有最佳适应度的m个解,应用局部搜索过程进行改进,改进之后的解用于更新偏好矩阵。局部搜索包含4种操作,划分(divide)、合并(merge)、交换(swap)、移动(move)。对每个选定的解,依次执行这4种操作。
对于每个操作,首先根据定义的选择规则来选择一个或者几个合乘组。然后,对选定的合乘组应用该操作,看是否有改进,并且一旦在当前的合乘组中获得改进,它就移动到下一个选择的合乘组。当所有选择的合乘组处理完之后,应用下一个操作。图4给出了这4种操作改进解的示例,其中具有相同线条形状的用户为同一个合乘组。
(1)划分操作
划分操作将所选择的合乘组划分为两个合乘组,以降低总出行成本。该操作选择n%的具有相对较高的内部旅行成本的合乘组,内部旅行成本是不包含用户与目的地之间的旅行成本的用户之间的旅行成本。根据每个合乘组的内部旅行成本,通过轮盘赌进行选择。选择合乘组i的概率Pi是按式(35)计算的。

其中,incosti是合乘组i的内部旅行费用,K是所有合乘组的集合。然后,对于每个选定的合乘组,该操作尝试将合乘组i中的任何成员划分到一个新的合乘组中。如果解得到改进,则确认此举。

Fig.4 Instance of local search图4 局部搜索例子
(2)合并操作
合并操作尝试将任何未达到车容量的合乘组进行合并。对于每个未满的合乘组,有一个合乘组列表与之关联,列表中的合乘组与该合乘组合并后仍满足车辆容量约束,且按照已在合乘组成员数量降序排列。然后,从列表的顶部开始,尝试将合乘组i与列表中的每个合乘组j合并。如果获得改进,则确认此举。
(3)交换操作
交换操作尝试在两个合乘组中交换两个用户。首先选q%的内部旅行成本高的合乘组,选择方式同划分操作。对于每个选定的合乘组i,选择与其重心距离最近的合乘组j。然后,尝试交换合乘组i中的每个成员与合乘组j中的每个成员。如果获得改进,则确认此举。
(4)移动操作
移动操作尝试将用户从选定的合乘组移动到非达到车容量的合乘组中。首先选择k%的合乘组,选择方式同划分操作。对于每个选定的合乘组i,选择与其重心距离最近的非达到车容量的合乘组j。然后,尝试将合乘组i的每个成员移动到合乘组j中,每次尝试一个成员。如果获得改进,则确认此举。
3.6 偏好信息更新
根据局部搜索改进后的解结构,更新偏好矩阵。在更新偏好值之前,偏好矩阵中的所有权重值wij将以蒸发速率μ减小,以便扩大在当前迭代中获得的新偏好信息的影响。对于每个选定解,同一合乘组中的用户之间的偏好值以值φs更新,φs按式(36)获得。

其中,favg是整个蚁群解的平均适应度,fs是当前选择解的适应度。λ是一个加权因子,用于在前面的迭代中保持φs较低的值,以及在后向迭代中保持较高的值,使得蚂蚁在开始迭代中更自由地探索解空间。
因此,新的偏好值wij将按照式(37)更新,其中是先前迭代的偏好值,S是所有选定解的集合。

偏好值wii根据式(39)更新。更新是基于合乘组中的车辆的空位级别vi,被计算为用户i所在合乘组的最小车容量与合乘组中已有用户数量的差值,如式(38)。
例如,对于最小车容量为4 个用户的合乘组,如果合乘组中已有3个用户,则合乘组中每个用户的空位级别是1。因此,较高的空位级别表示,与其车容量相比,合乘组的用户数量较少,则合乘组中的用户能够接受更多的用户加入合乘组。相反,空位级别越低,合乘组中的用户对拥有其他合乘成员具有越低容忍水平。

3.7 分布式计算实现
CAC 是群体智能算法,其寻优过程具有并行和分布式的特点,因此很容易进行并行化实现。为了克服集中式串行环境下对大规模LTCPP求解效率较低的问题,本文提出了基于Spark的CAC的分布式版本,即分布式聚类蚁群(DCAC)。DCAC 应用Spark编程模式,使算法分布式并行地运行在Spark集群或云计算平台中,增强了对大规模问题的处理能力。
3.7.1 Apache Spark简介
Spark 的核心数据结构是弹性分布式数据集(resilient distributed datasets,RDD)。它表示一组已分区、不可变且可并行操作的数据。可以以操纵本地集合的方式操作分布式数据集。生成RDD有三种方法:(1)从外部存储创建RDD;(2)从数据集合中创建RDD;(3)从其他RDD 变换获得新的RDD。RDD 提供两种类型的操作:(1)转换操作。转换操作返回一个新的RDD,并且转换的RDD 是惰性求值的,也就是说,它仅在使用这些RDD 时进行求值。(2)行动操作。行动操作将最终结果返回给驱动程序或将其写入外部存储器。
因此,只需将数据转换成RDD,并对RDD 应用转换和行动操作,即可达到数据的分布式处理,借用集群的强大计算能力,提高算法的效率。
3.7.2 分布式聚类蚁群算法
每次迭代过程中,各个蚂蚁旅行构造解的过程是完全独立的。因此,该过程可以采用分布式计算,即多个个体同时进行搜索,以提高算法的计算效率。
采用Spark编程模型对CAC算法重新编程,将蚁群封装为一个RDD,这样在集群各节点中就会存储RDD的各个分区,即将蚁群分散到集群各节点,从而达到蚁群搜索过程的并行化。
CAC 算法必须经过多次迭代才能得到最优解,每次迭代结束后根据较优的解结构更新偏好信息,更新后的偏好信息作为下次迭代中蚂蚁聚类的选择依据。为此采用Spark提供的共享机制,将偏好矩阵作为广播变量进行广播,传递到集群中的每一个节点,以供各个蚂蚁搜索过程使用。需要注意的是,每次迭代后需要移除旧的偏好信息,重新对更新后的偏好矩阵进行广播。DCAC 算法主要过程如算法2所示。
算法2分布式聚类蚁群算法
1.设置参数,初始化偏好矩阵和吸引力矩阵,初始化蚁群List
2.使用SparkContext.broadcast()方法对偏好矩阵、吸引力矩阵、用户数据、距离表等进行广播
3.RDD
4.While 不满足退出条件do
①RDD
②Solutions=solutions.collect()/*将solutions 返回给驱动器程序*/
③选择s中具有最佳适应度的前m个解,应用局部搜索过程
④根据改进后的这m个解更新偏好矩阵
⑤重新广播偏好矩阵
⑥记录截止目前的最优解
5.End While
6.输出最优解
4 实验与分析
本章进行了大量的仿真实验,以验证算法的有效性和效率,并对实验结果进行分析。
4.1 实验环境
本文算法均由Java语言实现。分别在单机环境下与集群环境下进行实验。用于测试的Spark 集群由11 个节点组成,1 个节点作为Master,其余节点为Worker 节点,每个节点软硬件环境配置相同。实验环境如表1所示。
4.2 参数设置
算法相关参数设置如下:种群规模(蚂蚁数量)为100;初始化偏好矩阵和吸引力矩阵时的调整参数α=1,β=1,θ=5,γ=0.2;计算轮盘赌选择概率时的调整参数a=2,b=1;选择具有最佳适应度应用局部搜索的个体数量为10;φs的调整因子λ=0.5;偏好信息蒸发速率μ=0.9;局部搜索中,划分操作选择合乘组占总合乘组的比率n=0.3,合并操作选择率为1,交换操作选择率q=0.3,移动操作选择率k=0.3;计算解的适应度时,各优化目标的权重因子w1=1,w2=0.2,w3=0.2,w4=0.2。连续迭代次数达到N=10,解未得到改进,或者迭代次数达到100,程序终止。

Table 1 Experimental environment表1 实验环境
4.3 实验结果
本文模拟了LTCPP 的输入数据得到多个实例,其中参与合乘用户数量(Size)分别设置为100、200、400、600、800、1 000、1 500、2 000。实例中的用户分别采用3 种分布方式:集中方式、随机与集中混合分布以及随机分布,分别用C-、RC-、R-标识。对这24个实例,运行10次,选择目标函数为中位数的解决方案进行记录,仿真结果如表2 所示。在表2 中,记录了每个解决方案中合乘组数量(Npool)、单独出行的用户数量(Nalone)、私家车数量减少率(Rcar)、合乘前所有用户每天的行驶距离之和(Disbefore)、合乘后所有用户平均每天的行驶距离之和(Disafter)、合乘后行驶距离减少率(Rdis)、平均每位用户每天实际启程到达时间与理想时间之差(TGap)、合乘后平均每位用户每天的额外驾驶时间(Textra)、CAC(未分布式)运行时间(TCAC)、DCAC 5 节点集群计算时间(T5node)、DCAC 10节点集群计算时间(T10node)。

Table 2 Experimental results表2 实验结果
4.4 结果分析
4.4.1 有效性分析
为了观察DCAC算法的分组效果,本文选取3个不同规模、不同分布方式的实例分组结果进行了可视化。图5、图6、图7展示了实例C-1、RC-2、R-3的分组结果,其中坐标原点(0,0)代表目的地,具有相同图案、相同颜色且用虚线连接在一起的用户为同一个合乘组。

Fig.5 Grouping result(C-1)图5 分组结果(C-1)
从图5~图7可以看出,不管用户位置属于哪种分布方式,DCAC算法都有很好的分组效果。距离近的用户会被分在同一合乘组,这是因为合乘后,用户的出行成本会降低。位置分散的用户大多独自出行(参照图6),这是为了避免合乘后用户的驾驶时间过长。这与本文的研究目标相一致。

Fig.6 Grouping result(RC-2)图6 分组结果(RC-2)

Fig.7 Grouping result(R-3)图7 分组结果(R-3)
图8 显示了各实例合乘后行驶总距离减少率。合乘后行驶总距离能减少60%左右,其中分布集中(C)的用户合乘后行驶距离减少最多,其次是集中与随机混合分布(RC),最后是随机分布(R)。可以观察到,当用户数量达到1 600以上,这3种分布方式合乘后减少的行驶距离逐渐接近,这是因为大量的用户分布在目的地(0,0)周围km 范围内,无论哪种分布方式,用户分布均比较集中。因此分组结果相近,这也反映了算法有较高的稳定性。
图9 显示了各实例合乘后私家车出行数量减少率。私家车数量即为合乘组数量,单独出行的用户也视为一个合乘组。图9和图8趋势很相似,合乘后私家车数量能减少68%左右,其中分布集中(C)的用户合乘后私家车减少数量最多,其次是集中与随机混合分布(RC),最后是随机分布(R)。当用户数量达到1 600 以上,这3 种分布方式合乘后的私家车数量减少率相近,原因同上。

Fig.9 Private car reduction rate after car pooling图9 合乘后私家车减少率
图10显示了各实例合乘后的平均每位用户对比单独出行时所产生的额外驾驶时间。合乘后,分布集中(C)的用户以及集中与随机混合分布(RC)的用户的额外驾驶时间相近,在6 min 左右,这说明合乘组内部旅行成本在6 min左右。随机分布(R)的用户额外驾驶时间相对较高,在7.5 min左右,这是由于用户分布过于零散所致。

Fig.10 Extra driving time from car pooling图10 合乘导致的额外驾驶时间
图11 显示了用户平均的实际启程/到达时间与理想时间的差距。从图11 可知,用户平均每日的实际启程/到达时间与其理想的启程/到达时间的差值在14 min左右。

Fig.11 Difference between actual departure/arrival time and ideal time图11 实际启程/到达时间与理想时间的差距
本文从分组结果、总行驶距离减少率、私家车出行数量减少率、用户的额外驾驶时间、用户实际启程/到达时间与其理想的启程/到达时间的差距5个角度进行了分析,以此来验证算法的有效性。结果表明,实行车辆合乘,所有用户平均每日的行驶距离之和可以减少60%左右,每日私家车数量大约能减少70%,平均每位用户的额外驾驶时间在7 min左右,用户平均每日的实际启程/到达时间与其理想的启程/到达时间的差值在14 min左右。
4.4.2 效率分析
将表2 中相同规模的3 个测试实例的平均计算时间作为当前问题规模的计算时间,可以得到计算时间随着参与合乘用户数量增加的变化趋势,如图12所示。

Fig.12 Graph of computing time trend图12 计算时间趋势图
从图12可以观察到:(1)CAC与DCAC算法均能高效地处理小规模问题(200人以内),时间在10 s左右。(2)随着问题规模的增大(400以上),CAC算法计算时间有明显的增加趋势。相比CAC,DCAC 算法增加趋势更为缓慢,即DCAC 算法在处理中等以上规模的问题更有优势。(3)当参与合乘人数达到600以上,10节点集群计算时间明显比5节点集群计算时间少。(4)对于2 000人的实例,10个节点的集群计算时间相较于5 个节点集群的计算时间降低了52.4%,相较于CAC的计算时间降低了77.7%。
由于Spark Master 和Worker 节点之间存在网络通信开销以及Master 任务调度开销,对于小规模问题(200人以内),分布式计算时间与单机计算时间相差不多。但随着问题规模增大,通信时间和任务调度时间所占的时间损耗比例逐步降低,分布式计算的优势开始显现。对2 000人的实例,10个节点集群计算时间比单机计算时间降低了77.7%。因此,CAC算法能很好地解决小规模问题,DCAC算法能更好地处理大规模问题。
4.4.3 局部搜索性能分析
为了验证局部搜索过程对算法全局搜索性能的影响,将局部搜索作为可选的操作,分别在局部搜索启用(ON)和局部搜索禁用(OFF)情况下,对实例进行计算。观察应用局部搜索过程最优解改进比例,其中Ropt表示最优解,t表示计算时间(单位为s),实验结果如表3所示。

Table 3 Local search experimental results表3 局部搜索实验结果
实验结果表明,应用局部搜索过程,解的质量得到显著提升,平均改进达到10.5%。因此,局部搜索过程能极大提高CAC的全局搜索能力。
4.4.4 与经典蚁群算法比较
为了客观表明CAC 算法的性能,使用经典蚁群算法(ant colony optimization,ACO)对24个测试实例求解,比较两种算法的求解效率和所提供的解的质量。为了避免局部搜索过程对实验结果影响,两种算法均不应用局部搜索过程。为公平起见,实验参数保持一致,即蚂蚁个数均为100,程序终止条件均为连续迭代次数达到10,解未得到改进,或者迭代次数达到100,程序终止。表4是程序运行10次的平均结果,其中Ropt表示最优解,t表示求解时间(单位为s)。

Table 4 Comparison of experimental results表4 实验结果对比
由表4 可见,对于较大规模实例(1 000 人及以上),ACO已无法在可接受的时间(30 min以内)内获得问题的解。综合最优解的质量和求解时间指标,CAC 明显优于ACO。由CAC 得到的最优解比ACO获得的解平均改进25.7%,并且CAC 的计算时间比ACO的计算时间平均减少53.4%。因此,对于任意规模的LTCPP,CAC都比ACO具有明显的性能优势。
5 结论
车辆合乘可以有效减少私家车出行数量,对于缓解城市交通拥堵,削减停车位需求,减少空气污染等具有重要意义。针对LTCPP,本文构建了考虑匹配可行性的带有车容量和时间窗约束的多目标优化模型,并提出一种有效的分布式聚类蚁群算法(DCAC)用于高效地求解该问题。实验结果表明,DCAC可以为LTCPP 提供高质量的合乘方案,合乘后总的行驶距离约减少60%,私家车出行数量减少68%,且合乘用户担任司机时的额外驾驶时间仅在7 min左右,用户平均每日的实际启程/到达时间与其理想的启程/到达时间的差值在14 min 左右。从求解效率来看,DCAC在求解2 000人的大规模合乘问题时,10个节点的集群计算时间在3 min 左右,通过与5 个节点的集群计算时间对比可以得到,继续增加集群节点数量,可以进一步加快算法的求解速度。因此,本文提出的DCAC 算法可以为LTCPP 提供有效的合乘方案,且在处理大规模问题上具有明显优势。
