基于Zynq7000 FPGA异构平台的YOLOv2加速器设计与实现*
2019-10-24柴志雷
陈 辰,柴志雷,2+,夏 珺
1.江南大学 物联网工程学院,江苏 无锡214122
2.数学工程与先进计算国家重点实验室,江苏 无锡214125
+通讯作者E-mail:zlchai@jiangnan.edu.cn
1 引言
卷积神经网络(convolutional neural network,CNN)已在图像分类、目标检测等领域被广泛应用[1-2]。为了满足卷积神经网络对高强度计算能力的需求,当前数据中心、服务器端不仅采用ASIC(application specific integrated circuit)或GPU(graphics processing unit)处理大批量数据[3],考虑到能效等因素也会大规模部署FPGA(field-programmable gate array)[4]。除了ASIC 外,FPGA 也可以很好地满足嵌入式端低功耗高性能的需求[5]。并且,FPGA 可重构的特点很好地适应当前深度学习日新月异的演变速度,因此已有许多基于FPGA的卷积神经网络加速器的研究[6]。
Zhang 等人设计出一种输入和输出特征图数目二维展开的SIMD(single instruction multiple data)卷积神经网络加速器架构,并且提出采用Roofline模型进行加速器设计空间的探索[7]。Qiu等人深入分析了CNN 模型的计算与存储瓶颈,提出了参数重排序以及数据量化的具体流程,并设计出了一种在卷积核长宽二维展开的加速器架构。但是,在建模时并没有将传输延时也考虑在内,导致实际性能与理论性能相差接近47%[8]。虽然Rahman等人提出了一种将带宽考虑在内的加速器模型,但只是根据传输数据量建模,并没有考虑实际传输时延[9]。Ma 等人详细分析了基于卷积循环展开SIMD架构的设计可能性,并提出在输出特征图数、宽度和高度三维展开的SIMD架构加速器。然而,由于提出的架构将特征图像素和权重都缓存在片上,导致所耗费的FPGA资源过多,很难在低端FPGA 上使用[10]。为了提高FPGA计算资源的动态利用率,Shen 等人提出设计多个加速器并发处理不同层,并且通过多通道数据传输改进传输时延[11]。Li等人设计了一种层间流水,层内输入、输出特征图数和卷积核宽三维展开的加速器架构,但也只适用于资源足够多的FPGA[12]。Zhang 等人提出通过增大突发传输长度来有效利用带宽,以及通过参数复用和多批量处理来提高处理全连接层时计算单元的利用效率[13]。卢冶等人提出了一种面向边缘计算的嵌入式FPGA 平台卷积神经网络的通用构建方法,但是用于评估的模型过于简单,并且只设计了一种类似文献[7]的加速器架构[14]。另外,硬件设计的开发周期是非常长的,这也是导致硬件相关研究缓慢的一大原因。因此,可以通过高层次综合(high-level synthesis,HLS)来快速地描述和实现所需的硬件架构,由此造成的额外资源开销和开发效率的提升相比是可以接受的[15-16]。
因此,使用HLS 设计并实现了一种在输入和输出特征图数二维展开的SIMD 卷积神经网络加速器架构,并使用了参数重排序、多通道数据传输等优化策略。以目前在业界被广泛应用的YOLOv2 目标检测算法[1]为例,来介绍将CNN模型映射到FPGA上的完整流程。在Zedboard 上获得了30.15 GOP/s 的性能,与Xeon E5-2620 v4 CPU 相比,能效是其120.4倍,性能是其7.3倍;与双核ARM-A9 CPU相比,能效是其86 倍,性能是其112.9 倍。同时,在性能上也超过现有的工作。
本文的贡献如下:
(1)设计并实现了一个基于FPGA的卷积神经网络加速器,给出将YOLOv2模型映射到FPGA上的完整流程,对加速器的性能和所需资源进行深入分析和建模,将实际传输延时考虑在内,极大地缩小了加速器理论与实际时延的误差。代码已在github 开源(https://github.com/dhm2013724/yolov2_xilinx_fpga)。
(2)改进了基于FPGA 的SIMD 二维展开的卷积神经网络加速器架构中的输入和输出模块,使得传输像素块能够以较大的突发长度进行传输,有效提高了总线带宽的实际利用率。
2 基本概念
本章主要介绍YOLOv2 模型涉及到的相关概念、突发传输以及卷积计算的优化策略。
2.1 YOLOv2模型简介
YOLOv2 一共包含4 种类型的层:卷积层、池化层、路由层和重排序层。其中,卷积层起到特征提取的作用,池化层用于像素抽样,路由层用于多层次的特征融合,重排序层用于特征的抽样重排。在训练时常用批量归一化来加速训练收敛[17],通过激活函数给网络增加非线性拟合能力。批归一化和激活函数一般都跟在卷积层后。
(1)卷积层(convolutional layer)
对多张输入特征图以对应卷积核进行卷积来实现特征提取,伪代码如下所示:
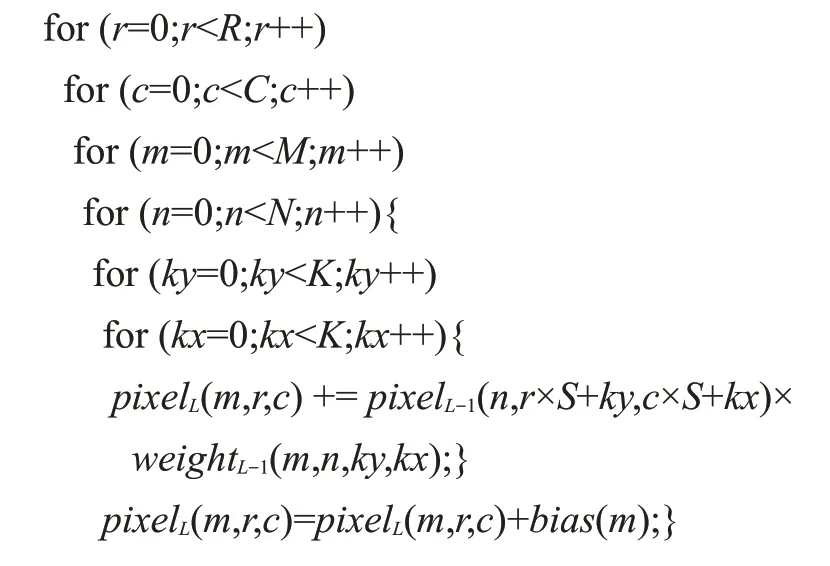
其中R、C、M、N、K、S分别代表输出特征图高度、输出特征图宽度、输出特征图数、输入特征图数、卷积核大小和步长。pixelL(m,r,c)代表输出特征图m中r行c列的像素。全连接层可看作K=1,S=1 的特殊卷积层。
(2)池化层(pool layer)
对输入特征图降采样,以降低特征图的规模,同时也具有保持某种不变性(旋转、平移、伸缩等)的功能,一般跟在卷积层后。最大池化层伪代码如下所示:
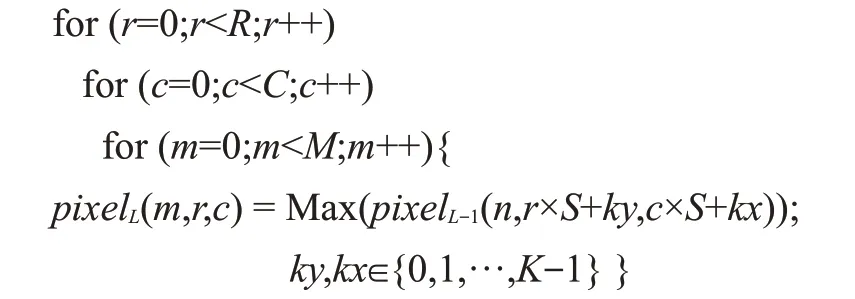
其中,Max 表示在K×K的邻域中返回最大像素,其他参数含义与卷积层类似。
(3)路由层(route layer)
将多层的输出特征图级联,作为下一层的输入特征图,实质是将多维度的特征信息简单融合。
(4)重排序层(reorganization layer)
将给定的大尺度输入特征图在邻域内按位置抽样,同位置像素形成子图,如图1所示。
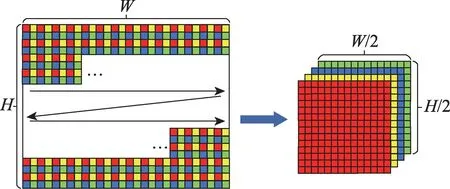
Fig.1 Reorganization with stride of 2图1 步长S为2时的重排序过程

若步长S=2,则一张W×H的输入特征图在2×2的邻域内按位置抽样,最终输出4张W/2×H/2 的子图。
(5)批归一化(batch normalization,BN)
深度学习常通过批归一化加快训练收敛[17]。如果某卷积层在训练阶段使用了批量归一化,那么在推断阶段,该层的每个输出特征图像素都需要经过以下映射:

其中,bn0、bn1、sc0、sc1在训练完成后为常数。可以将式(1)与式(2)合并,得到:

由于BN 一般跟在卷积计算后,激活函数前,并且由式(3)可知,BN实际是做一个线性变换,因此可以将其与对应的卷积计算融合,得到新的卷积核权重和偏置参数,公式如下所示:
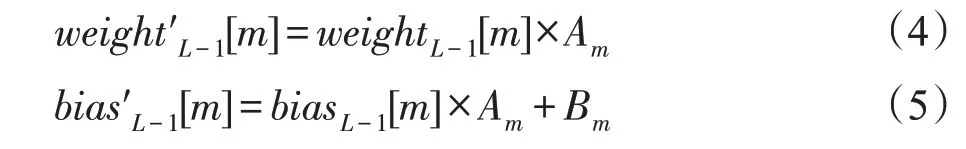
其中,Am和Bm为针对不同输出特征图m的相应常数。本文之后的权重和偏置参数默认都已经过融合。
(6)激活函数
激活函数对每个输出特征图像素做一个非线性变换,主要用于给网络增加非线性拟合的能力,一般位于批归一化后。YOLOv2 中用到的激活函数是
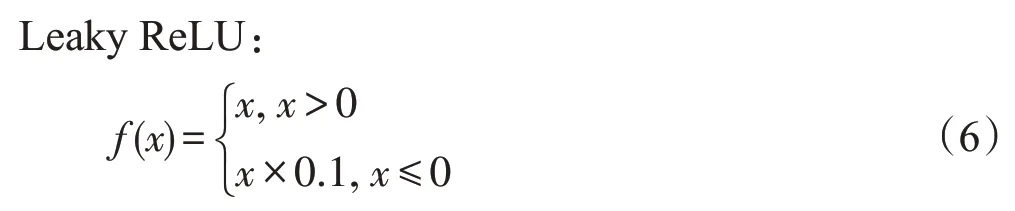
2.2 突发传输
实际读写DRAM(dynamic random access memory)的带宽往往与突发传输长度、数据位宽和时钟频率有关[13]。当数据位宽和时钟频率保持不变时,传输同样长度的连续数据,突发传输长度越长,传输时延越小。如图2所示。
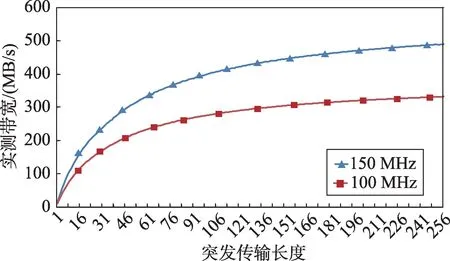
Fig.2 Effective bandwidth for 64 MB transmission图2 传输连续64 MB的有效带宽
在Xilinx 的Zedboard 开发板上测试32 位AXI4 Master 接口在不同突发传输长度下,向DRAM 写入连续的64 MB数据测得的实际带宽。纵轴是实测带宽(单位:MB/s),横轴是突发传输长度,从1 至256。100 MHz 工作频率下,在突发长度为256 时,能够得到最大有效带宽332 MB/s,此时的带宽效率为332/400 ≈83%。150 MHz 工作频率下,在突发长度为256 时,能够得到最大有效带宽489 MB/s,此时的带宽效率为489/600 ≈81%。
在已测得实际对应不同突发传输长度的有效带宽的前提下,根据算法1,对读写DRAM 的时延进行仿真。
算法1读写DRAM时延仿真
输入:(1)连续传输32 位数据长度Length(32 bit);(2)最大突发长度BurstLengthmax(1~256);(3)对应1~256突发长度的有效带宽数组Bandwidth[256](MB/s)。
输出:时延Latency(s)。
初始化时延Latency=0.0
计算以最大突发长度传输的次数Nummax∶
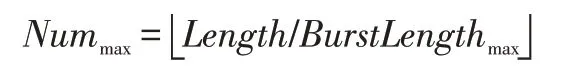
计算剩余项的突发长度BurstLengthRm:
BurstLengthRm=Length%BurstLengthmax
计算以最大传输长度传输的传输时延:
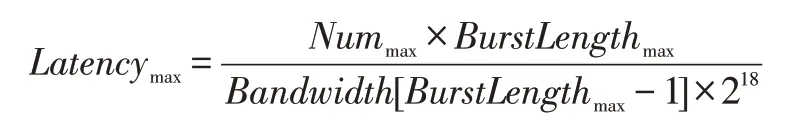
若剩余项不为0,计算剩余项的传输时延:
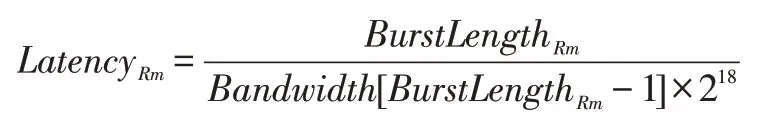
否则,LatencyRm=0
Latency=Latencymax+LatencyRm
下文以MM(Length,BurstLengthmax)来表示在最大突发长度为BurstLengthmax的前提下,传输连续Length个32位数据的传输时延。
2.3 卷积优化策略
大多数卷积神经网络中,卷积层占90%以上的计算量,而全连接层占据90%以上的参数量[8]。由于全连接层也可看作特殊的卷积层,因此针对CNN 计算和带宽瓶颈的优化主要是对卷积层加速策略的研究,一般分为展开和分块两种[10]。
(1)展开(unroll)
在不考虑访存时延的前提下,如果计算单元无法快速地计算所给数据,那么计算将成为瓶颈。当前的大部分研究通过对卷积循环中的多维度展开,设计多个并行乘法和加法计算单元来提高计算能力[7-14]。本文对输出特征图数M和输入特征图数N两维进行部分展开,形成Tm×Tn个并行乘法单元和Tm个lbTn深度的加法树,并行流水地计算卷积中的乘法和加法。其中,Tm为输出特征图数M维度的并行度/展开度,Tn为输入特征图数N维度的并行度。
(2)分块(tile)
由于FPGA的片上存储资源相对于CNN计算所需的存储空间来说是极其不足的(一般小于10 MB),因此当前大部分研究主要利用卷积计算的数据局部性,对卷积循环进行多维划分,使得在进行卷积计算时,多次复用片上数据。从而,某些数据只需要从片外存储中读取或写入少量次数,极大地降低了访存次数和访存数据量,使得访存不至于成为CNN 加速的瓶颈。
本文加速器设计所对应的卷积层分块与展开策略的伪代码如下所示:

其中I、O、W分别代表输入特征图、输出特征图和卷积核参数,一般存放于片外存储DRAM中。Ibuf、Obuf、Wbuf分别代表在FPGA加速器上设计的片上输入缓存、输出缓存和参数缓存。偏置参数由于数据量较少,在进行卷积计算前可以全部读取到片上存储bias中。
每次从片外DRAM 读取Tn张输入特征图的((Tr-1)×S+K)×((Tc-1)×S+K)大小的像素块以及对应的Tm×Tn×K2大小的权重参数,复用片上输入特征图像素块和权重参数,将中间结果保留在片上缓存中,只有得到最终的输出像素块后,向片外写出Tm张输出特征图的Tr×Tc大小的像素块。
3 从CNN模型到FPGA加速器构建
本章主要描述从CNN模型到FPGA加速的完整流程,如图3所示。
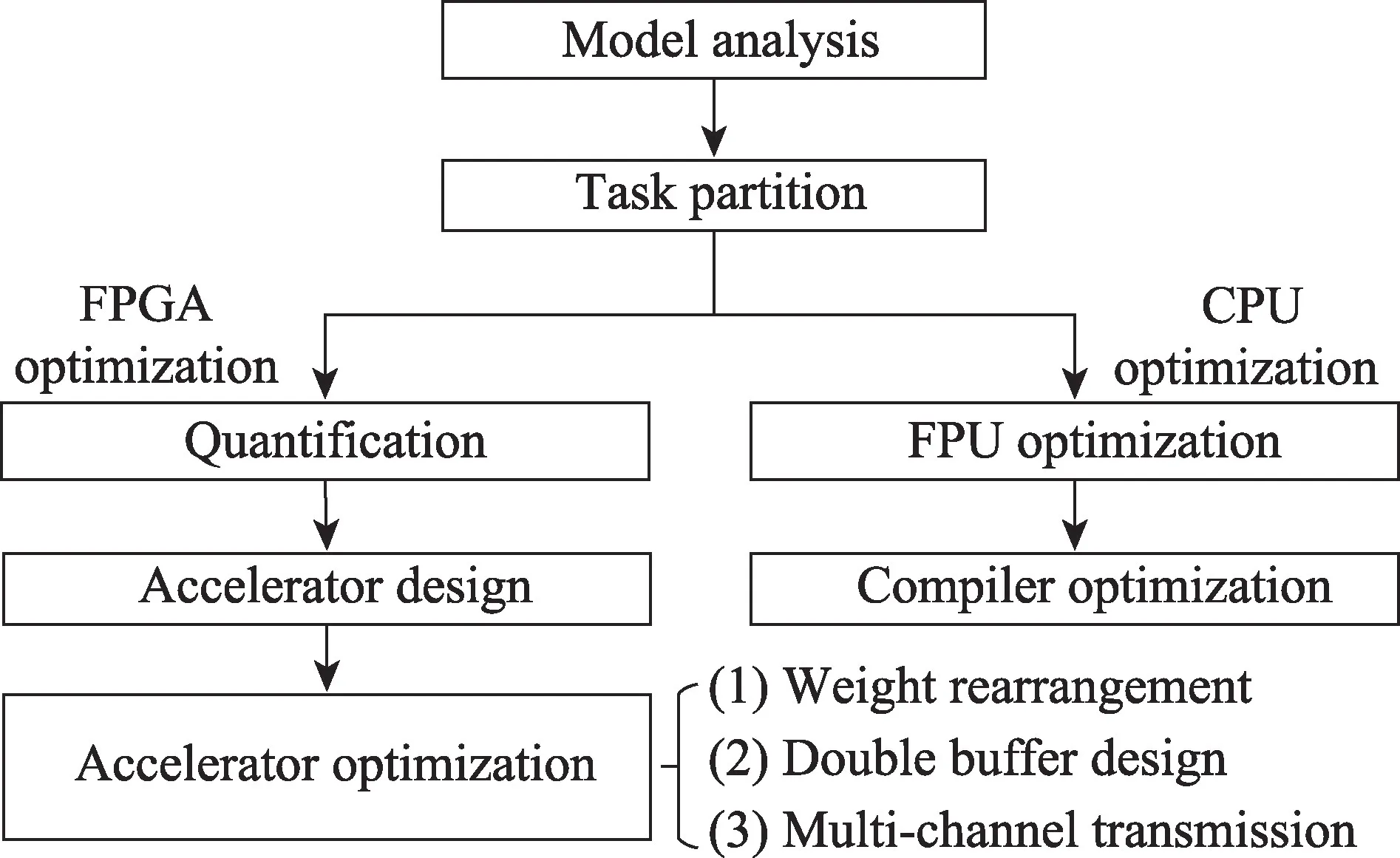
Fig.3 Flow chart from CNN model to FPGA acceleration图3 从CNN模型到FPGA加速的流程图
(1)模型分析与任务划分:首先,需要对模型进行深入分析,理解模型算法的原理和数据流。其次,根据模型在不同阶段所做的运算,考虑FPGA和CPU的特点,将任务划分给FPGA和CPU。CPU适合做控制性、串行、计算量较少的任务,而FPGA适合做并行度高、计算密集型的任务。
(2)针对分配到FPGA 上的任务:通过量化可以降低计算复杂度,减少计算单元所耗费的资源,从而设计出更多的并行计算单元,提高加速器性能。此外,需要设计对应的加速器模块来加速各层的处理,加速器的优化策略包括参数重排序、双缓冲设计和多通道数据传输等。
(3)针对分配到CPU上的任务:可利用CPU的浮点运算单元加快浮点计算。同时,在编译时可采用编译优化加速任务处理。此外,还有诸如多线程并行、cache缓存优化等优化策略。基于CPU的性能优化已非常成熟,这里不再详细叙述。
3.1 YOLOv2网络模型分析与任务划分
3.1.1 模型分析
通过对文献[1]及YOLOv2源码分析可知,YOLOv2的目标检测步骤如下:
(1)图像预处理:输入任意分辨率的RGB 图片,除以256转化到[0,1]区间,按原图长宽比调整到416×416大小,不足处填充0.5。
(2)网络检测:输入预处理得到的416×416×3 的图像数组,经YOLOv2网络检测后,输出包含检测目标信息的13×13×425大小的数组。
(3)图像后处理:对输出的13×13×425 数组进行处理,得到检测边框的中心、长宽、边框可信度和物体的预测概率等,根据原图长宽比,将得到的边框调整到原图尺度,完成检测。
3.1.2 任务划分
由于图像预处理和后处理部分计算量不大且在图像处理总延时中占比极少,同时考虑到后处理涉及指数计算,而FPGA实现指数拟合的资源耗费较大,因此将图像的预处理和后处理部分放在CPU端处理。
YOLOv2 网络中一共涉及4 类层:卷积层、池化层、路由层和重排序层。卷积层占据模型的大部分计算量,已有的研究表明使用FPGA加速卷积运算是非常有效的[7-14]。最大池化与卷积类似,只是缺少输入特征图数维度,并使用比较运算代替乘加运算。因此,将卷积层和池化层的处理放在FPGA端[18]。路由层可通过预先设置内存偏移地址来实现。重排序层的抽样重排与DMA(direct memory access)类似,但与传统DMA不同,因此也在FPGA端处理。
3.2 动态定点16位量化
CNN 对于数据精度有很强的鲁棒性,在保持准确度不变的前提下,可以通过降低数据位宽来减少计算耗费的资源[7]。并且,随着数据位宽降低,传输数据量也随之降低。本文采用与文献[8]和文献[19]类似的流程对权重参数和输入输出特征图进行动态定点16位量化。
定点数xfixed可由以下公式表示:
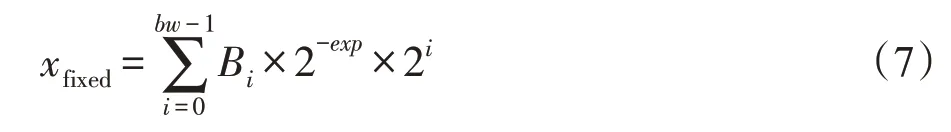
其中,bw表示定点数的位宽,exp表示阶码,Bi∈{0,1}。定点数xfixed采用补码表示,最高位为符号位。
浮点数xfloat与定点数xfixed的相互转化如下:
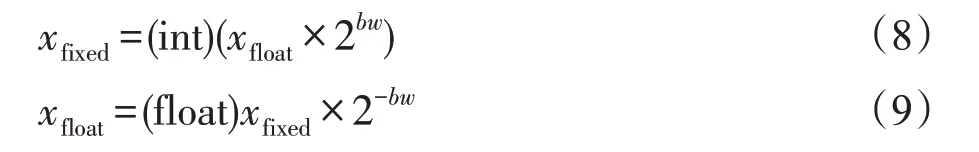
由于定点数位宽有限且阶码固定,因此将浮点数xfloat转换为定点数xfixed,再转换回新浮点数x′float后,可能会有精度误差。
动态定点数据量化由3步组成:
(1)权重参数量化
首先,找到每层的权重最优阶码expw:
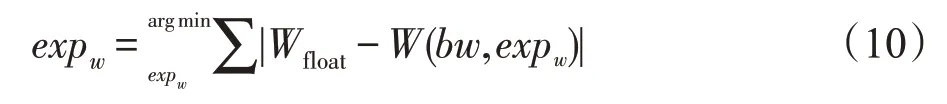
其中,Wfloat表示某层的任意权重参数原始浮点值,W(bw,expw)表示在给定位宽bw和阶码expw下将Wfloat定点化后转换回浮点的新浮点数W′float。通过式(10),希望找到最优阶码expw使得原始权重与定点化后的权重绝对误差和最小。偏置参数的量化与其类似,在此不过多叙述。
(2)输入输出特征图量化
按网络的前向顺序对输入输出特征图进行量化,使每一层的输出特征图像素有共同的阶码expout。阶码expout满足以下公式:
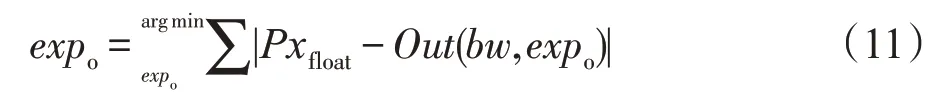
其中,Pxfloat表示某层的原输出特征图浮点像素值,Out(bw,expo)表示给定位宽bw和阶码expo下定点化后转换回浮点的浮点数Px′float。其余与权重参数量化类似。此外,由于在预处理时将RGB 像素值转化到[0,1]区间,因此当位宽bw为16时,可将第一层的输入特征图阶码定为14。
(3)中间结果量化
虽然前两步已将权重和输入输出特征图定点化,但在处理时还是先转换成浮点进行计算,并且中间结果以浮点存储。
通过量化中间结果可以用定点数的乘加和移位来拟合浮点乘加运算,使得推断过程除预处理和后处理阶段外,在FPGA 端都以定点数进行计算和传输。中间结果阶码expinter满足以下公式:
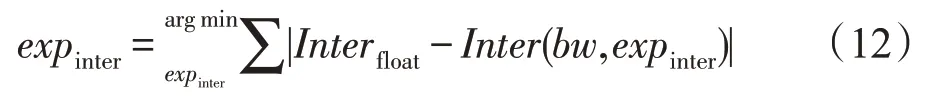
另外,使用动态定点量化时,激活函数Leaky ReLU 也要进行相应的量化操作。当位宽bw为16时,使用与0xccc相乘和右移15位的定点运算拟合与0.1相乘的操作。量化后的公式如下所示:
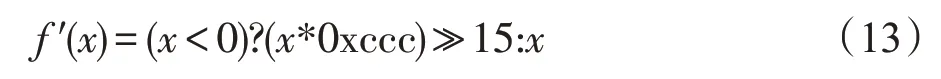
3.3 基于FPGA的设计与优化
除路由层外,其他层都是将上一层的输出作为当前层的输入,输出结果作为下一层的输入,串行顺序处理。如图4(a)所示,将路由层的功能通过预先设置存取地址偏移实现后,FPGA加速器只需根据相关参数读取内存数据、处理数据和将数据写回内存即可。
如图4(b)所示,每次读取或写入多块数据,对FPGA片上缓存的数据块复用结束后,再进行下一次读取,保证每块数据只从片外读取少量次数以减少访存次数和传输数据量。
对于每次取到的分块数据,根据图4(c)的控制流处理:将从片外读取到的数据发送到片上缓存,根据层的类别交由CONV、POOL、REORG 模块进行处理。处理后的数据写回输出缓冲,待得到最终结果后写回片外。
加速器总体架构如图5所示,加速器对外有多个AXI master 接口和一个AXILite slave 接口。通过AXILite slave接口读写控制、数据和状态寄存器。多个AXI master 接口并发读取输入特征图和写回输出特征图,一个独立的AXI master接口负责读取每层权重参数。
Data scatter模块生成对应写入地址,并将从片外读到的输入特征图像素块分发到片上缓存。Data gather生成写回地址,将输出缓存中的输出特征图像素块写回片外。
红色处理模块分别负责卷积层(CONV 和Leaky ReLU)、最大池化层(POOL)及重排序层(REORG)的处理。用于读写特征图的AXI master 接口数由以下公式决定:
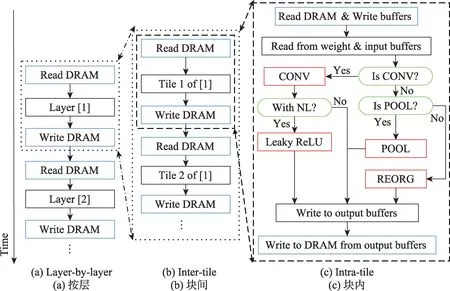
Fig.4 Execution schedule图4 执行调度流
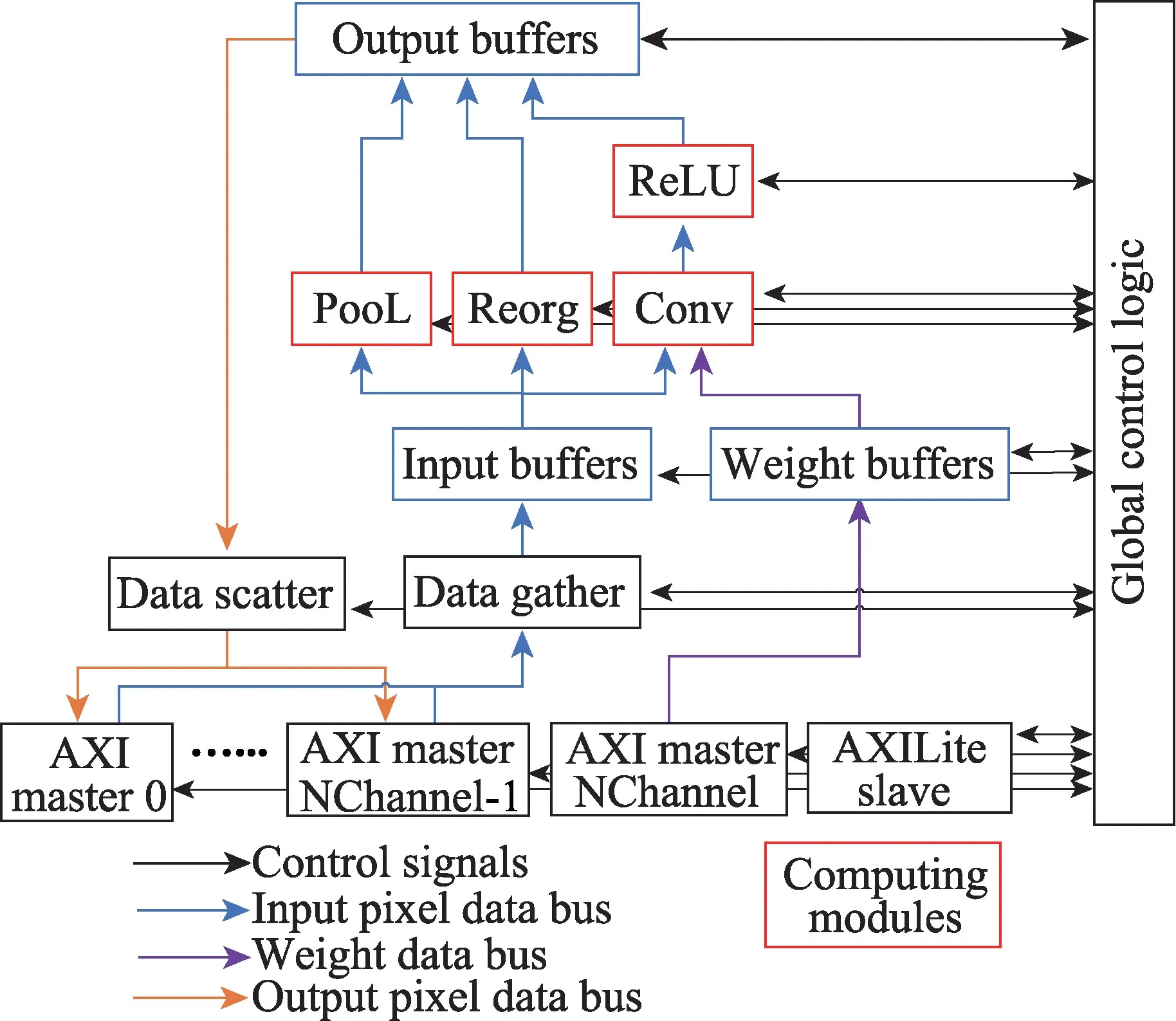
Fig.5 Accelerator overall architecture图5 加速器总体架构
其中,NCin表示并发读取特征图的AXI master 接口数,NCout表示并发写回DRAM 的AXI master 接口数。由于AXI4协议本身读写通道独立,读写操作并发,因此实际用于数据传输的AXI master接口数由并发通道多的一侧决定。再加上用于权重读取的接口,实际AXI master接口数NAXIM=NChannel+1。
另一方面,HLS 生成的AXI4 master 接口模块内部读写通道都拥有类似DMA的硬件结构,可以看作(NCin+NCout+1)个独立的DMA并发访存。
3.3.1 输入输出模块
由于AXI4 master 接口读写通道独立,因此读写操作可以并发执行。通过读通道从DRAM 读取数据,由数据分发(data scatter)模块控制多个读通道的DMA 完成输入特征图像素块的读取,并将读取的数据块分发到对应输入缓存;由数据收集(data gather)模块将输出缓存中的像素块写回DRAM,控制多个写通道的DMA完成输出特征图像素块的写入,如图6所示。
图6(a)中的TRow和TCol由输出特征图像素块的宽度Tr和高度Tc、卷积核大小K和步长S决定,公式如下:
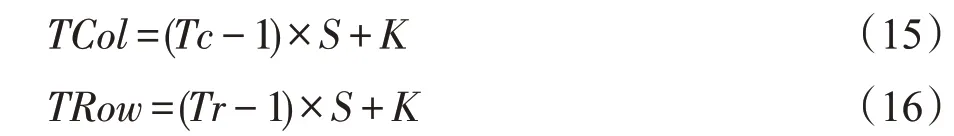
如图6(a)所示,数据分发模块从内存顺序读取Tn张TRow×TCol大小的输入特征图像素块,每个像素块按行优先顺序读取并分发到Tn个独立的片上输入缓存。与此类似,图6(b)中的数据收集模块从Tm个独立的片上输出缓存中顺序读取Tr×Tc大小的像素块写回片外。
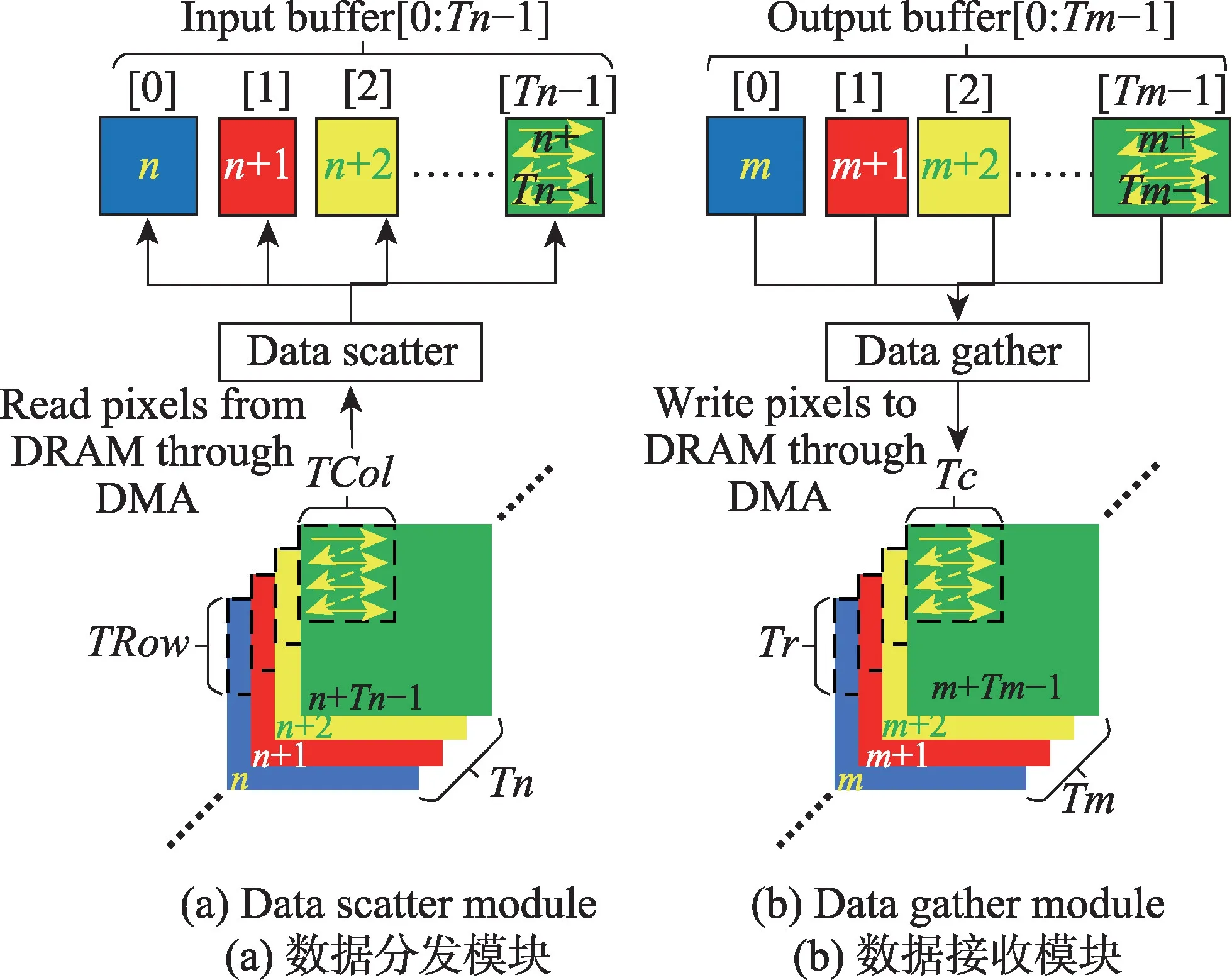
Fig.6 Single channel data transmission图6 单通道数据传输
为了减少数据的传输时延,在数据分发和收集模块中还添加了额外的行缓冲,并且进行了双缓冲设计。输入输出模块的双缓冲时序如图7所示。
(1)对于数据分发模块从片外DRAM 读取输入特征图像素块到片上缓存的过程
如图7(a)所示,数据分发模块的双缓冲的设计使得访存地址、片上缓存偏移的计算、将输入特征图像素块从DRAM读取到行缓冲的时延和像素从行缓冲写入输入缓存的时延重叠,减少数据的传输时延。
输入行缓冲所需的存储资源NLoadLineBRAM为:
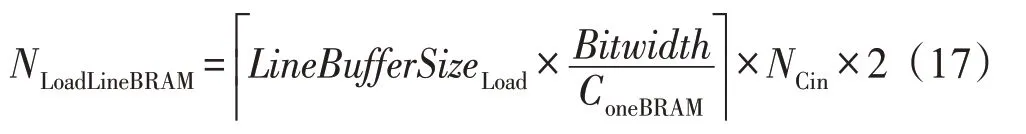
其中,行缓冲大小LineBufferSizeLoad满足:
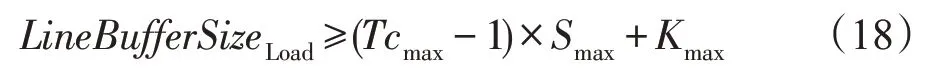
ConeBRAM表示单块BRAM(block RAM)的存储能力(典型值为18 Kb),Bitwidth表示当前的数据宽度,Tcmax表示各层的最大Tc值,Smax和Kmax以此类推。NCin表示多通道并发输入数,此处无多通道数据传输情况下为1。
根据片上缓存和特征图的宽度尽可能长地连续传输数据,提高带宽效率。行缓冲每次传输的输入特征图行数NTRowOneLine如下所示:
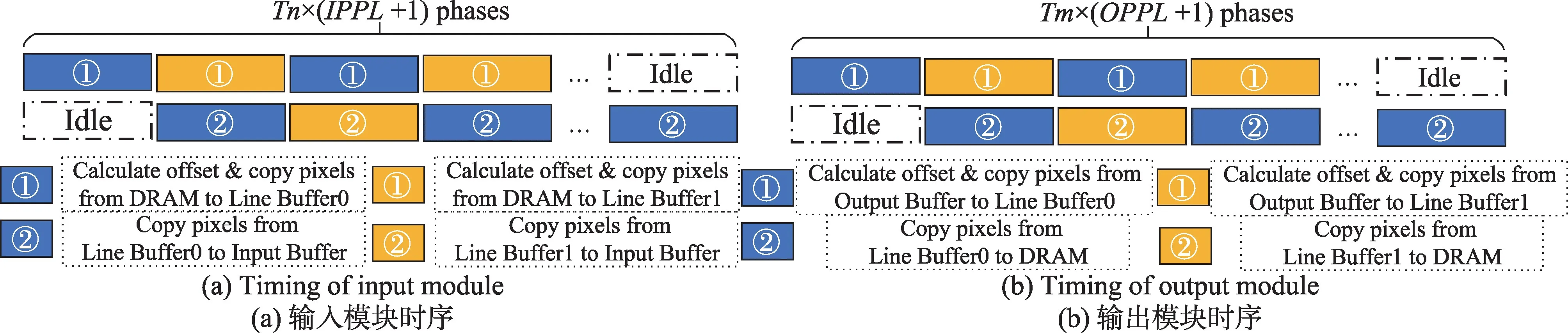
Fig.7 Timing graph for double buffered design图7 双缓冲设计时序图
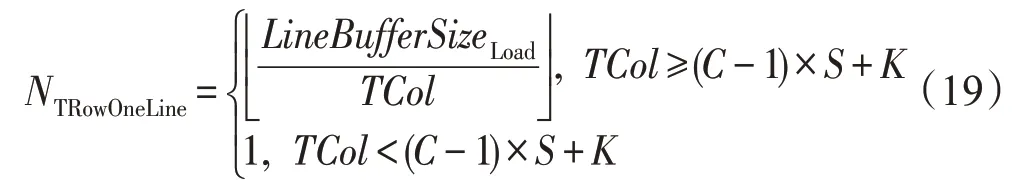
只有当读取的输入特征图的宽度小于TCol时,每次行缓冲才会读取连续的多行像素。
①访存地址、片上缓存偏移的计算、将输入特征图像素块从DRAM 读取到行缓冲的时延LatencyLoad1公式如下:
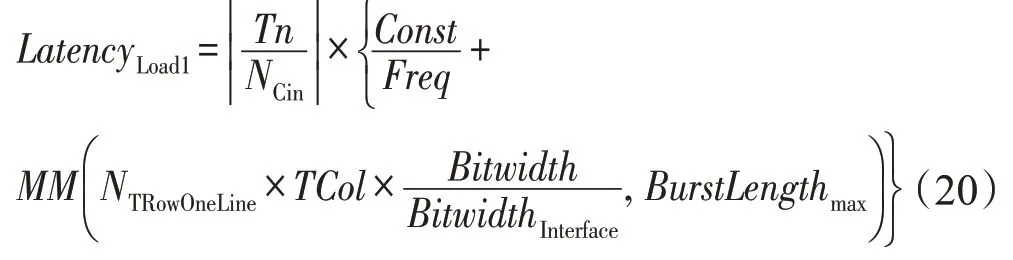
其中,Const为模块相关常数(流水线初始化时钟等),Freq为加速器工作的时钟频率,BitwidthInterface为AXI Master 接口数据位宽,BurstLengthmax为设置的最大突发长度。
②将行缓冲中的像素写入输入缓存的时延LatencyLoad2如下:
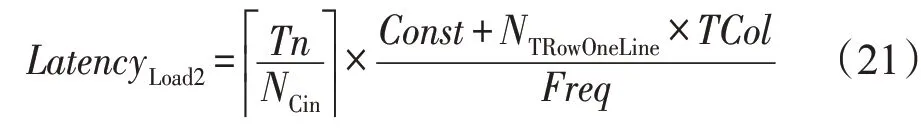
上述两个处理过程双缓冲的循环次数InputPing-PongLoops(IPPL)如下所示:

使用双缓冲设计后,输入特征图读取时延LatencyLoadIFM为:

(2)对于数据接收模块从片上输出缓存写出像素块到片外DRAM的过程
如图7(b)所示,数据接收模块将访存地址、片上缓存偏移的计算、像素从输出缓存搬移到行缓冲的时延和将行缓冲中的像素写回内存的时延重叠。
输出行缓冲所需存储资源NStoreLineBRAM为:
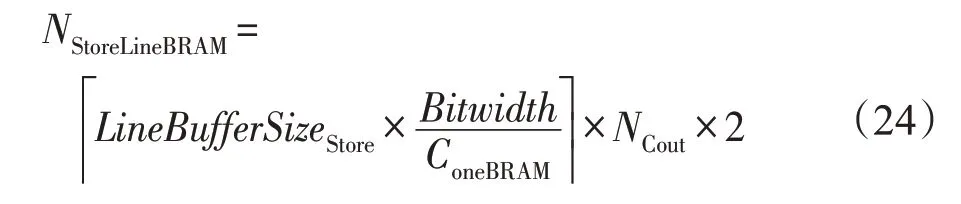
NCout表示多通道并发输出数,此处为1。输出行缓冲大小LineBufferSizeStore满足以下约束:
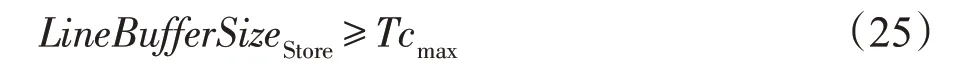
行缓冲每次传输的输出特征图行数NTrOneLine如下所示:

①访存地址、片上缓存偏移的计算、从输出缓存搬移到行缓冲的时延LatencyStore1如下所示:
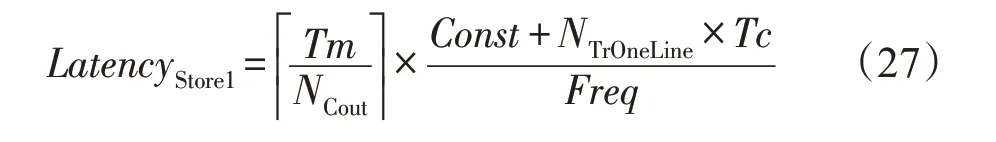
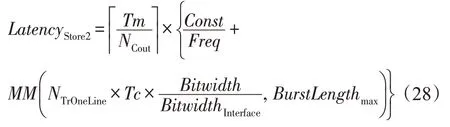
②将行缓冲中的像素写回内存的时延LatencyStore2如下所示:
上述两个处理过程双缓冲的循环次数Output-PingPongLoops(OPPL)如下:

使用双缓冲设计后,输出时延LatencyStore为:

3.3.2 卷积模块
对卷积循环中输出特征图数M和输入特征图数N两维部分展开,形成Tm×Tn个并行乘法计算单元和Tm个lbTn深度的加法树,流水地处理乘加运算[20]。其中,Tm为输出并行度,Tn为输入并行度。以Tm=2,Tn=4为例,如图8所示。
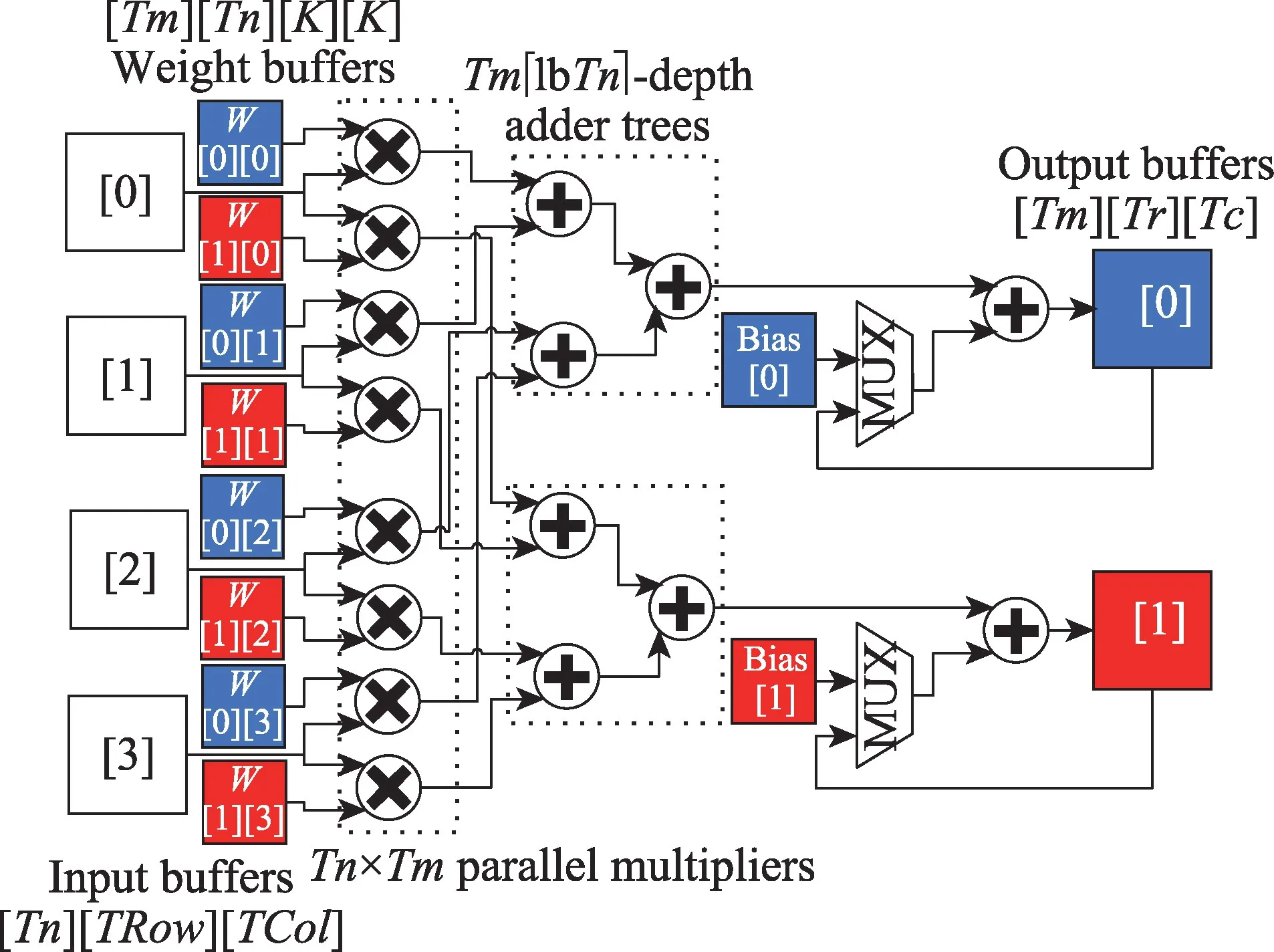
Fig.8 Convolution module(Tm=2,Tn=4)图8 卷积模块(Tm=2,Tn=4)
充满流水线后,每个时钟周期卷积模块从对应的Tn个独立输入特征图缓存中读入Tn个相同位置的像素,与此同时从Tm×Tn个独立的卷积核缓存中读入相同位置的权重,Tm×Tn个并行乘法单元复用Tn个输入像素进行乘法计算。Tm个加法树将乘积两两相加,得到的结果和部分和累加后,写回对应输出缓存或局部寄存器中。
卷积模块对应的计算时延LatencyCompute:
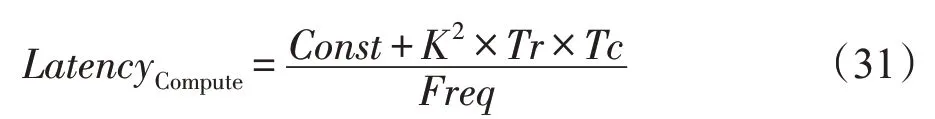
卷积模块的资源大部分用于乘法器和加法器的设计。单一乘法器和加法器的资源耗费与数据精度息息相关。由文献[7]和实际评估可知,乘法器和加法器主要耗费DSP(digital signal processing)和LUT(look-up table)资源。不同精度下,乘法器和加法器的资源耗费如表1所示。
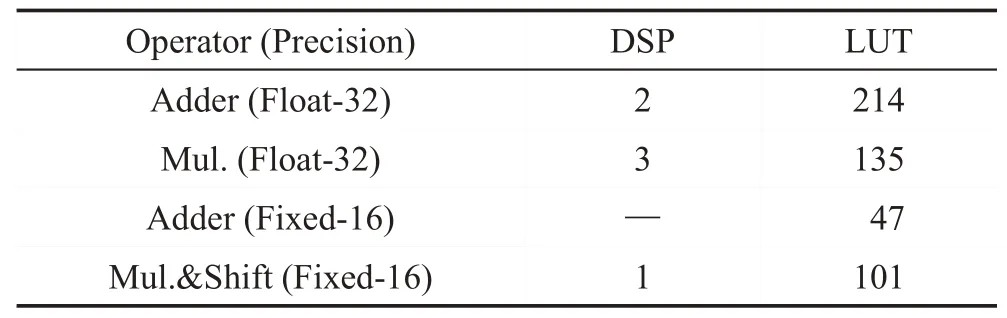
Table 1 Resource consumption comparison表1 资源耗费比较
浮点32 位精度时,设计单个乘法器和加法器的DSP 和LUT 的耗费较大。与浮点32 位时相比,定点16位精度的加法器只耗费少量LUT,不耗费DSP;乘法器和移位电路耗费的资源也大大降低。因此,在保证数据精度的前提下,定点计算具有较大的优势。
在输出并行度为Tm,输入并行度为Tn的条件下,卷积模块的主要DSP 资源耗费NDSP和LUT 资源耗费NLUT如下:
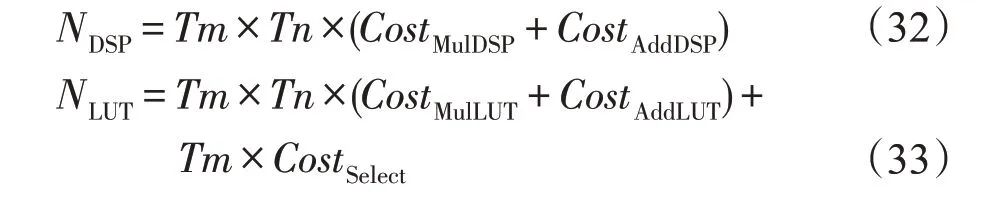
其中,CostMul和CostAdd分别对应不同精度下,乘法器和加法器的对应资源耗费。CostSelect对应图8 中的2选1选择电路和累加器的LUT耗费,本设计中典型值为8。
3.3.3 池化模块
YOLOv2 中的池化层都为K=S=2 的最大池化层。对单一输入特征图,以2×2 大小且步长S=2 的窗口滑动,取其中的最大像素作为输出。最大池化操作与卷积操作类似,不同之处在于:(1)只需要对单一输入特征图进行抽样;(2)运算单元不是乘法器和加法器,而是比较器。硬件结构如图9所示。
充满流水线后,每个时钟周期,池化模块从Tpool个独立的输入特征图缓存中读取相同位置的像素与当前最大值比较,同时有Tpool个比较器在进行不同输入特征图的比较运算。比较K2次后,将得到的最大值写入输出缓存中。由于在加速器整体架构中(图5),各层共用输入和输出模块,池化模块的并行度Tpool≤min(Tnmax,Tmmax)。
池化模块的计算时延LatencyCompute:
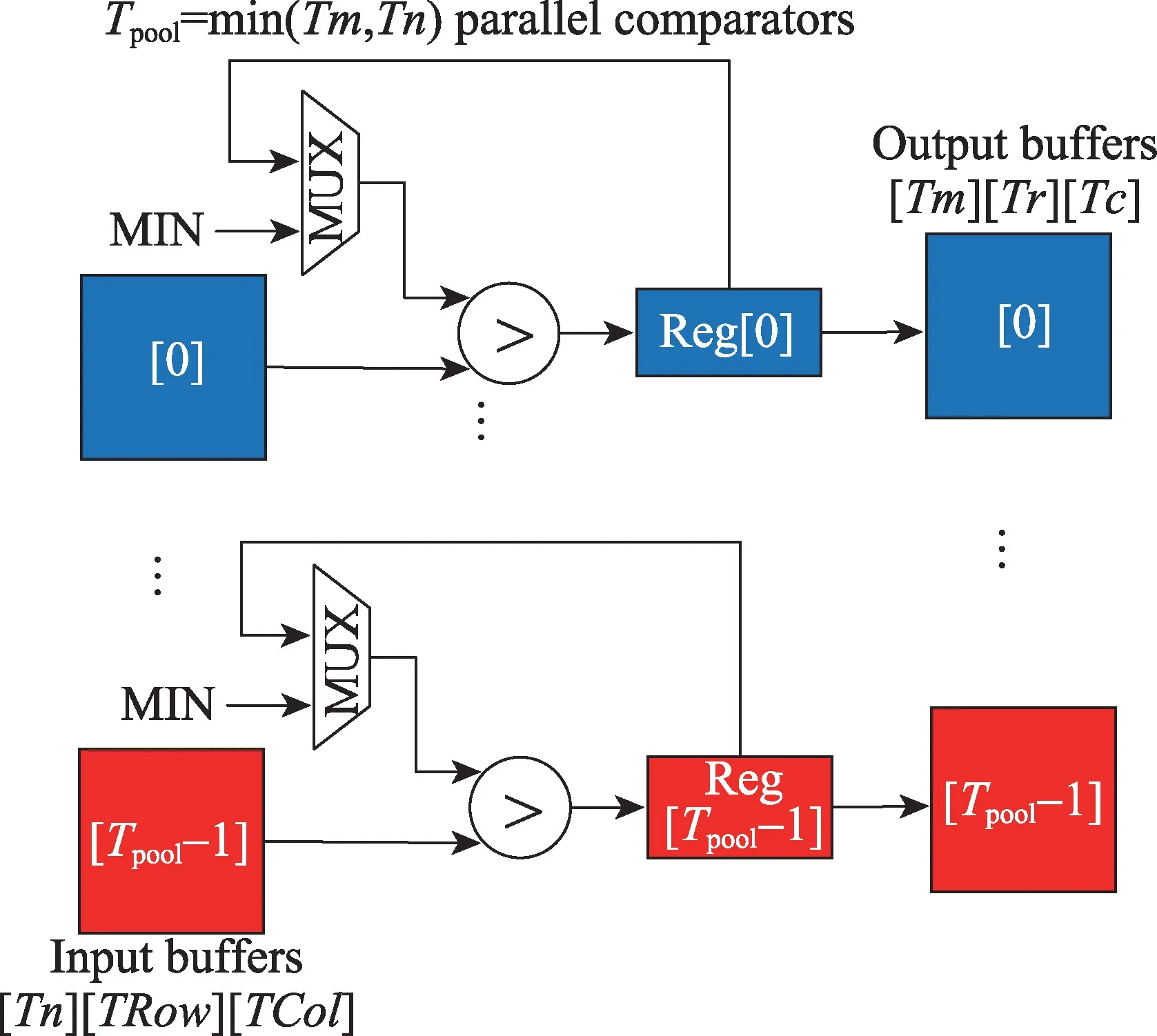
Fig.9 Pooling module图9 池化模块
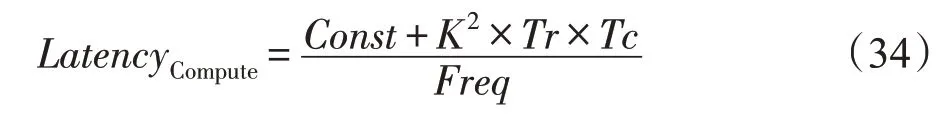
池化模块主要耗费LUT 资源用于多路选择器、比较器和寄存器的设计。考虑到其所耗费资源较少,这里不再过多说明。
3.3.4 重排序模块
重排序层的处理过程与最大池化层类似,都是对单一输入特征图的像素进行抽样。不同之处在于,最大池化层输出K×K邻域内的最大像素到单一输出特征图,而重排序层将K×K邻域内的输入像素输出到K×K张的输出特征图相同位置。因此,针对YOLOv2中K=S=2 的重排序层,重排序模块只使用1 块输入缓存和4 块输出缓存,并设计一个4 路选择器,每次从输入缓存读取1 个像素写入对应的输出缓存。
重排序模块的处理时延LatencyCompute如下:
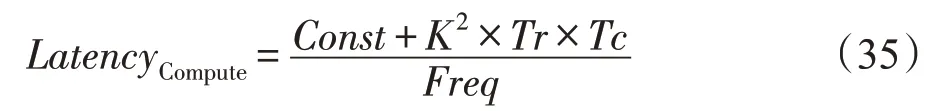
3.4 优化策略
3.4.1 参数重排序
参数重排序,将卷积层所需参数预先重排,使得每次传输的参数在DRAM 中连续存储,可以以较大的突发长度进行传输,有效提高了带宽的利用效率[13]。
对于权重参数,由于只跟当前层相关,因此根据当前层的块划分(这里指各层的Tn和Tm)对各层权重预先进行重排序,以减少访存次数和增大突发长度。以Layer 0为例,如图10所示。
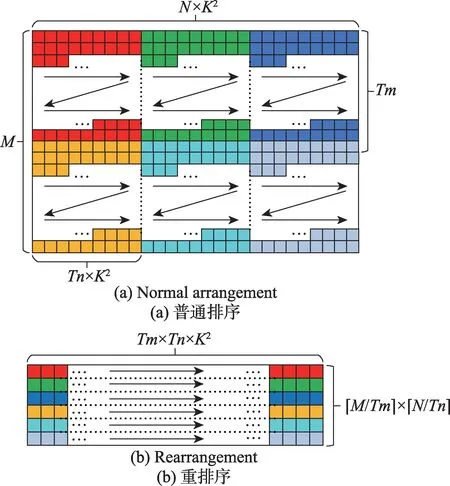
Fig.10 Weight arrangement in DRAM图10 在DRAM中的参数排序
第0 层的核权重为32×3×3×3(M×N×K×K)也可看作32×3×9(M×N×K2),其中M=32,N=3,K=3。如图10(a)所示,原始参数在内存中按行优先顺序存储。如果将卷积循环按Tm=16 和Tn=1划分,那么需要按箭头顺序从DRAM 中读取16×1×9 大小的参数6次。但由于参数不连续,共需访存32×3=96 次,每次的突发长度为9。
如图10(b)所示,参数重排序后,由于读取参数连续存放,只需访存6 次,每次突发长度为16×9=144。增大突发长度并且减少大量的访存次数,使得有效带宽大大增加。
参数读取模块与输入模块类似,也添加了行缓冲并进行双缓冲设计。不同排序下的参数读取模块的传输次数NumTrans和连续传输的参数长度LengthTrans,如下所示:

其中,Normal 表示不使用参数重排时,从DRAM 读取Tm次Tn×K×K个连续参数;而Rearrangement 表示经过参数重排序后,从DRAM读取K×K次Tm×Tn个连续参数。
行缓冲所需的存储资源为:

每次从DRAM 读取连续LengthTrans个权重参数到行缓冲中的时延如下:

将行缓冲中的LengthTrans个参数写入片上参数缓存中的时延:

从DRAM读取NumTrans次LengthTrans个连续参数的读取时延LatencyLoadW:

3.4.2 乒乓缓冲
通过乒乓缓冲的设计,将从片外DRAM 读取数据的时延LatencyLoad、在片上数据处理的时延LatencyCompute和将处理完的数据写回片外DRAM的时延LatencyStore重叠,减少总时延[7-8]。
由于读取权重和输入特征图像素块的过程可以并发执行,从片外DRAM读取数据的时延LatencyLoad由权重读取时延LatencyLoad和输入特征图读取时延LatencyLoadIFM中较大的一项决定:
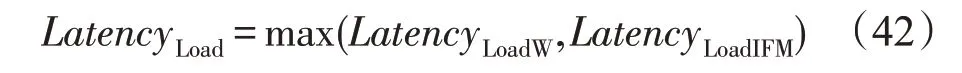
没有权重参数的最大池化层和重排序层LatencyLoadW为0。
如式(9)可知,卷积由六维乘加循环组成,与池化和重排序层不同,包括对输入特征图数维度N的遍历。故不使用乒乓时,卷积层各部分时延不重叠,输入特征图数维度N的内层循环需重复N/Tn次读取和计算操作,才能输出最终结果。此时,内层循环的时延LatencyInner:
卷积层处理的总时延Latency为:
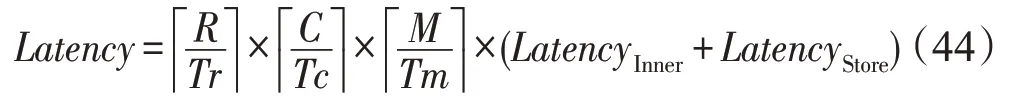
若使用乒乓缓冲,则读取时延LatencyLoad和卷积计算时延LatencyCompute重叠,读取和计算操作经(N/Tn+1)次循环后输出最终结果,此时内层循环时延LatencyInner为:
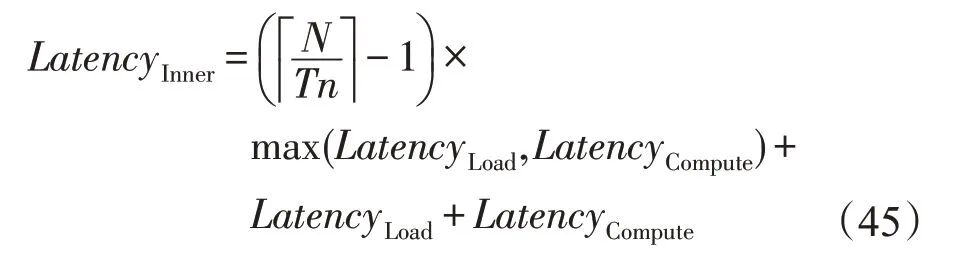
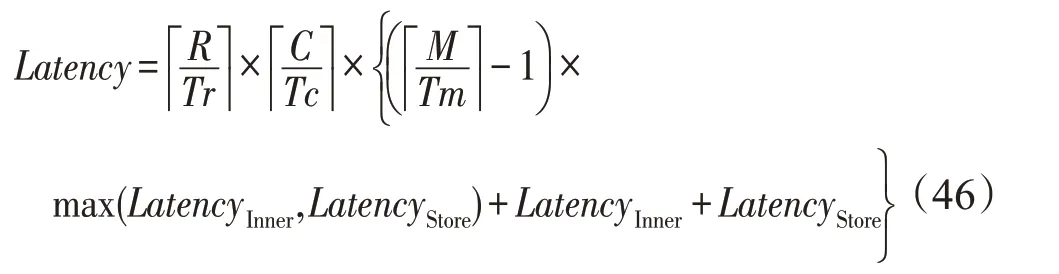
与卷积层相比,池化层和重排序层缺少输入特征图数N维度,故只考虑读取、数据处理和写回三者是否两两重叠。不使用乒乓时,三者线性进行,在时间上不重叠,处理总时延Latency为:
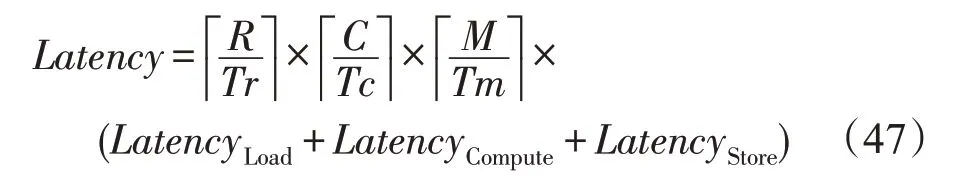
使用乒乓缓冲设计后,三者的处理过程两两重叠,此时处理总时延Latency为:
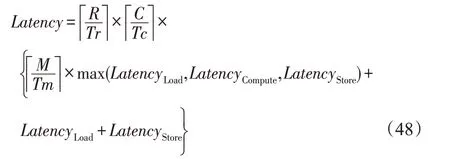
使用乒乓时,对应输入缓存和输出缓存所耗费的BRAM资源数如下:
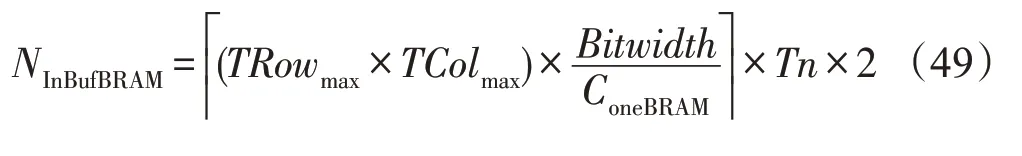
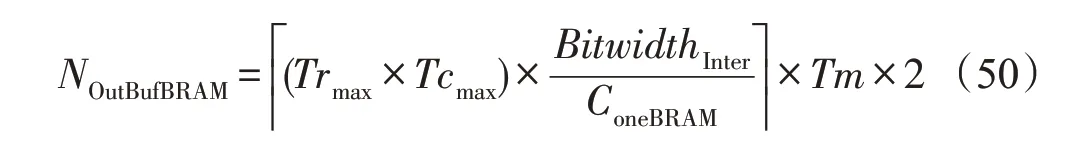
其中,BitwidthInter表示中间结果的数据位宽,典型值为32。对于权重缓存,数据量较小时使用FF(flipflop)和LUT 资源设计;数据量较大时,使用BRAM资源设计,BRAM的耗费如下:
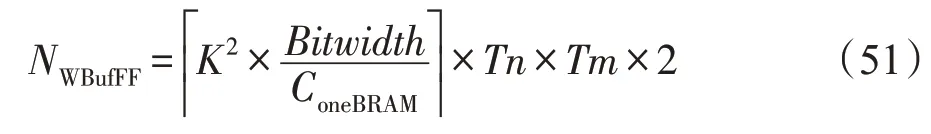
不使用双缓冲时,对应BRAM资源耗费减半。
3.4.3 多通道数据传输
3.3.1 节中的输入输出模块每次顺序地读取或写入多特征图的像素块。考虑到DRAM实际带宽大于单接口的总线带宽,可通过多通道数据传输,减少传输时延[11]。如图11所示。
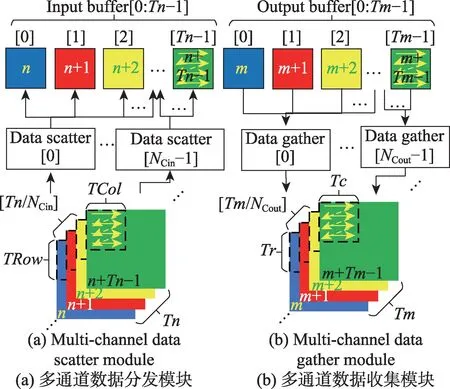
Fig.11 Multi-channel data transmission图11 多通道数据传输
图11 与图6 类似,但是图11(a)中数据分发模块变为NCin个子输入模块,每个子输入模块从DRAM读取张输入特征图的像素块到片上缓存。图11(b)中数据收集模块变为NCout个子输出模块,每个子输出模块将张输出特征图的像素块从片上缓存写回到片外。各输入输出子模块间无依赖性,并发地完成数据传输。此时,在式(20)、式(23)和式(24)中NCin>1,式(24)、式(27)和式(28)中NCout>1。同时,由于读写通道的增加,式(17)和式(24)中行缓冲占用的BRAM数目也会随之增加。
4 实验评估
4.1 软硬件实验环境
CNN 模 型:YOLOv2 和YOLOv2-Tiny(416×416),模型对应的数据集为COCO数据集[21]。
FPGA平台:Xilinx Zedboard开发板(Dual-coreARMA9+FPGA),其中FPGA 的BRAM_18Kb、DSP48E、FF和LUT资源数分别为280、220、106 400和53 200。
CPU平台:服务器CPU Intel E5-2620 v4(8 cores)工作频率2.1 GHz,256 GB内存。Zedboard上的双核ARM-A9,时钟频率667 MHz,512 MB内存。
使用Vivado HLS 2018.2 HLS 进行加速器设计,Vivado v2018.2 进行综合和布局布线。功耗采用VC470 功耗测量仪外部测量板级系统功耗。对于E5-2620 v4,采用散热设计功耗(thermal design power,TDP)作为总功耗(实际功耗大于TDP)。由于Zedboard是ARM+FPGA异构SoC平台,FPGA的计算功耗通过计算时系统的峰值功耗减去FPGA 复位后系统的空闲功耗得到。
4.2 加速器性能与资源耗费的评估
选择动态定点16 位精度下的加速器架构,采用参数重排序、乒乓缓冲和多通道数据传输三种优化策略,其中Tmmax=32,Tnmax=4,Trmax=26,Tcmax=26,Kmax=3,Smax=2,NCin=4,NCout=2。给定以上硬件设计参数后,实际加速器设计已确定。此时,还需确定各层在当前加速器设计下对应的Tm、Tn、Tr和Tc。
各层的Tr和Tc由以下公式得出:

其中,OH和OW分别表示输出特征图的高度和宽度。通过式(49)和式(51),可以得出各层输入和输出缓存能够存储的像素块的最大宽高。对于YOLOv2中的池化层和重排序层,S=K=2。
对于卷积层,Tm和Tn由以下公式得出:

当Tmmax和Tnmax给定后,已确定卷积计算模块的设计。因此,各卷积层的输入并行度Tn和输出并行度Tm不能超过相应最大值。
对于池化层,Tm和Tn由以下公式得出:
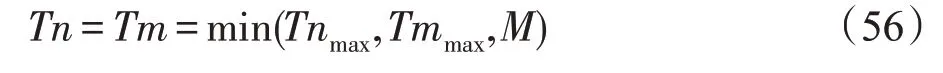
由于各计算模块复用输入输出模块,因此池化层的并行度Tpool≤Tm,实验中Tpool=Tm。
S=2 的重排序层将一张输入特征图抽样重排为4张输出特征图,因此Tn=1,Tm=4。
4.2.1 资源耗费评估
如表2所示,结合给定参数和上文中对各模块资源耗费的公式,将估计资源耗费与实际资源耗费进行对比。
DSP 主要用于卷积模块中加法器和乘法器的设计。根据式(32),DSP 耗费128 个,实际设计中多出的DSP用于其他模块的设计。
BRAM_18Kb主要用于实现存储量大的缓存,除上文中所提及的各模块对BRAM 的耗费外,AXI Master 接口也会耗费BRAM 来实现接口缓存(在当前设计下,耗费NAXIM×2=10 BRAM)。偏置参数的缓存耗费额外的两个BRAM。此外,根据式(49)、式(50)、式(17)、式(38)和式(24),加上输入缓存(3×4×2)、输出缓存(2×32×2)、片上输入行缓冲(2)、权重行缓冲(2)和输出行缓冲(2×2)所耗费的BRAM 资源,共耗费BRAM_18Kb 170 个,即85 个BRAM_36Kb,与实际BRAM耗费接近。
由于单个权重缓存的存储量过小(K2×Bitwidth=9×16=144 bit),无法充分利用BRAM资源。在设计时考虑使用LUT和FF来实现权重缓存(在当前设计下,单个权重缓存耗费约43 个LUT)。因此,当前权重缓存共耗费43×Tmmax×Tnmax×2=11 008 个LUT。由式(33)可知,此时16 位定点精度的卷积模块耗费19 968 个LUT。因此,共耗费约30 976 个LUT。剩余LUT用于其他模块的设计。
4.2.2 性能与能效评估
YOLOv2模型除路由层、图像的预处理和后处理外,剩余29层。其中包括23层卷积层、5层池化层和1 层重排序层。由于篇幅原因,表3 仅列出其中部分层的评估结果。列中的R(Real)表示该列数据为实测值,E(Estimated)表示该列数据是根据上文公式得到的估计值。
以相对误差对时延模型进行评价,相对误差δ公式如下:
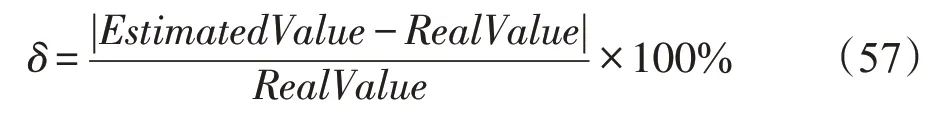
即测量的绝对误差与被测量的真值之比。
以表中最后一行总延时为例,YOLOv2模型的总时延误差约为,总计算时延误差约为0.8%,总输入时延误差约为10.7%,总输出时延误差约为10.4%。虽然本模型的主要误差仍集中于传输时延部分约为10%,但已远小于文献[8]中的误差47%。并且加速后卷积层的时延仍占总时延的95%(930.560/977.485 ≈95.2%)。
当前的工作在性能上也超过之前的工作,如表4所示。文献[22]设计了一个7×7的行缓冲,能够适应3×3 和7×7 的卷积核。由于分别设计卷积模块和全连接模块处理对应层,计算单元的利用率并不高。虽然工作频率很高,但性能仅达到18.82 GOP/s。文献[23]基于Intel的OpenCL采用通用矩阵乘法对矩阵分块,块间并行乘加的方式加速。然而,此方法需要每次将输入特征图和卷积核参数重排序,增加了预处理时延和复杂度。
如表5所示,与CPU相比,CPU+FPGA的异构系统是双核ARM-A9 能效的86 倍左右,Xeon 的120.4倍。速度是双核ARM-A9 的112.9 倍,Xeon 的7.3 倍左右。其中,将FPGA 复位后测量板级电源功耗,得到只使用双核ARM-A9计算时的功耗。此时的功耗较低,但是由于计算能力弱,使得计算时延过长,能效低。Xeon恰恰与其相反,计算性能强,使得计算时延很短,但是由于功耗过高,导致能效低下。与前两者不同,使用CPU+FPGA的异构系统,功耗略高于双核ARM-A9,但使用FPGA 加速,大幅度提高计算性能,在计算时延和能效上都获得了不错的表现。

Table 2 FPGA resource consumption表2 FPGA资源耗费
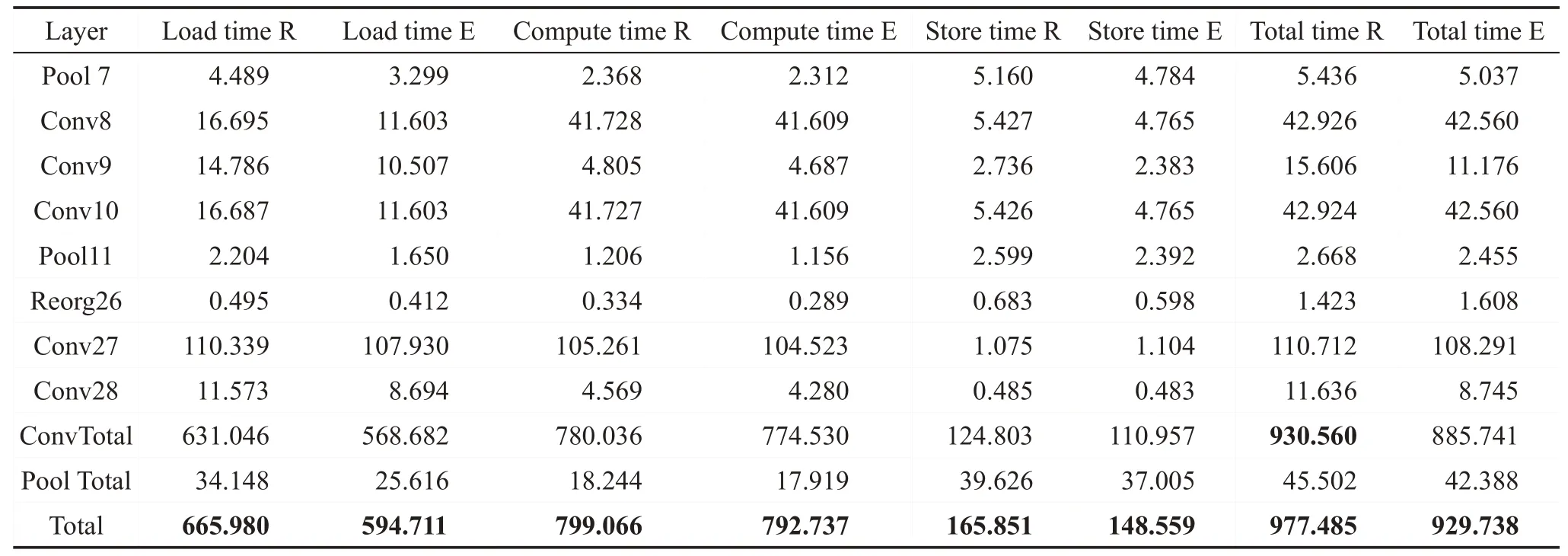
Table 3 Actual and estimated delay(partial)表3 实际与估计时延(部分) ms
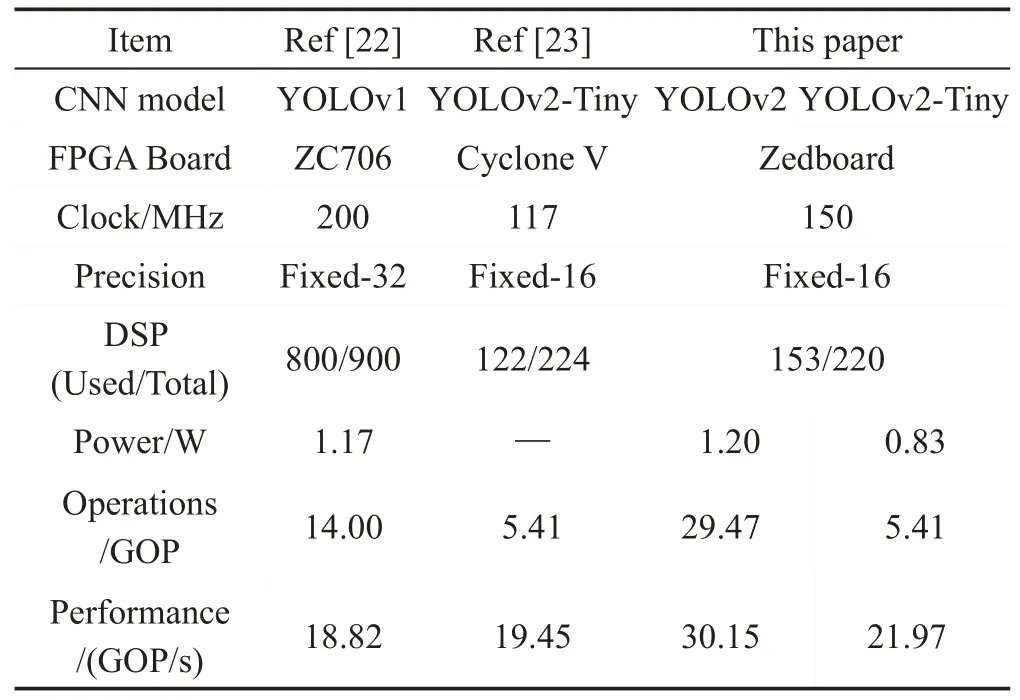
Table 4 Comparison with other FPGA work表4 与其他的FPGA工作比较
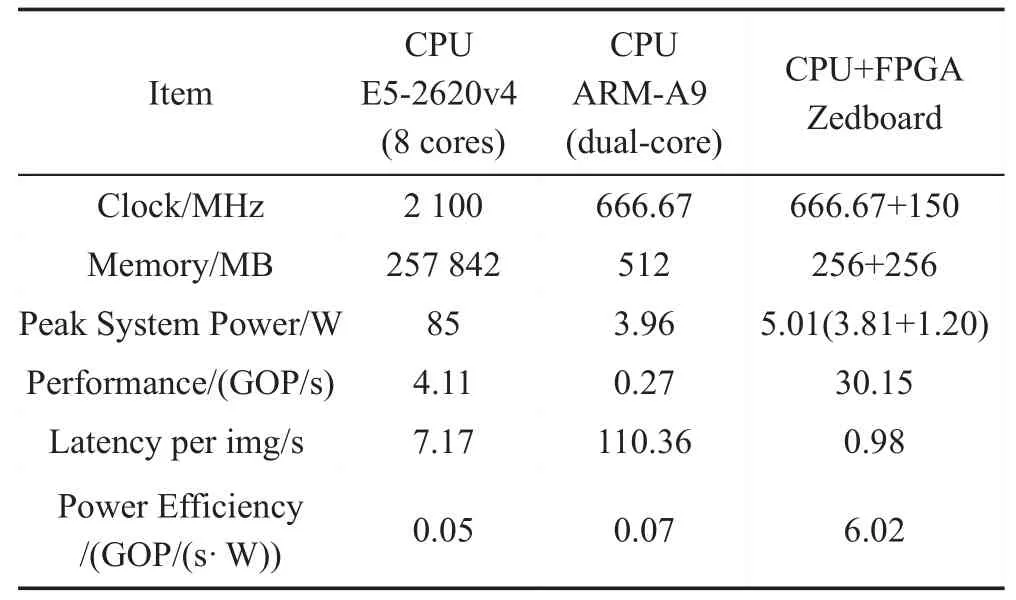
Table 5 Comparison with CPU表5 与CPU的比较
基于Xeon CPU 的评估由YOLOv2 源码编译(-Ofast)后执行得到,数据精度为float32(同条件下,Fixed16执行时间约为15.78 s)。动态定点16位数据量化得到的模型,在准确度上与原模型接近,COCO数据集上mAP(mean average precision)达到约48.1%。
5 结束语
本文以YOLOv2 目标检测算法为例,设计并实现了一种在卷积输入和输出特征图数二维展开的SIMD卷积神经网络加速器架构,介绍将卷积神经网络模型映射到FPGA 上的完整流程。对加速器的性能和所需资源进行分析和建模,将实际传输延时考虑在内,极大地缩小了加速器理论与实际时延的误差。同时,改进了加速器架构中的输入和输出模块,有效提高了总线带宽的利用效率。
未来进一步的改进方向主要有4个方面:
(1)考虑多种数据复用模式,适应不同维度“形状”下的访存需求,平衡计算与传输时延;(2)降低数据精度;(3)使用Winograd等快速矩阵乘法提高计算性能;(4)设计更细粒度的加速器或通过多层融合以减少总时延。
