基于高斯混合-时间序列模型的轨迹预测
2019-10-23高建毛莺池李志涛
高建 毛莺池 李志涛
摘 要:針对不同时间道路车流量变化下轨迹预测误差变化大的问题,提出基于概率分布模型的高斯混合 时间序列模型(GMTSM),对海量车辆历史轨迹进行模型回归和路段车流量的分析以实现车辆轨迹预测。首先,针对均匀网格划分方法容易造成相关轨迹点分裂的问题,提出迭代式网格划分来实现轨迹点的数量均衡;其次,训练并结合高斯混合模型(GMM)和时间序列分析中的差分自回归滑动平均模型(ARIMA);然后,为了避免GMTSM中子模型自身的不稳定性对预测结果产生干扰,对子模型的预测进行误差分析,动态计算子模型的权重;最后,依据动态权重组合子模型实现轨迹预测。实验结果表明,GMTSM在路段车流量突变情况下,平均预测准确率为90.3%;与相同参数设置下的高斯混合模型和马尔可夫模型相比,GMTSM预测准确性提高了55%左右。GMTSM不仅能在正常情况下准确预测车辆轨迹,而且能有效提高道路车流量变化情况下的轨迹预测准确率,适用于现实路况环境。
关键词:智能交通;迭代网格划分;轨迹预测;模型可靠性;轨迹相似性
中图分类号: TP391.4
文献标志码:A
Trajectory prediction based on Gauss mixture time series model
GAO Jian*, MAO Yingchi, LI Zhitao
College of Computer and Information, Hohai University, Nanjing Jiangsu 211100, China
Abstract: Considering the large change of trajectory prediction error caused by the change of road traffic flow at different time, a Gauss Mixture Time Series Model (GMTSM) based on probability distribution model was proposed. The model regression of mass vehicle historical trajectories and the analysis of road traffic flow were carried out to realize vehicle trajectory prediction. Firstly, aiming at the problem that the uniform grid partition method was easy to cause the splitting of related trajectory points, an iterative grid partition method was proposed to realize the quantity balance of trajectory points. Secondly, Gaussian Mixture Model (GMM) and AutoRegressive Integrated Moving Average model (ARIMA) in time series analysis were trained and combined together. Thirdly, in order to avoid the interference of the instability of GMTSM hybrid models sub-models on the prediction results, the weights of sub-models were dynamically calculated by analyzing the prediction errors of the sub-models. Finally, based on the dynamic weight, the sub-models were combined together to realize trajectory prediction. Experimental results show that the average prediction accuracy of GMTSM is 92.3% in the case of sudden change of road traffic flow. Compared with Gauss mixed model and Markov model under the same parameters, GMTSM has prediction accuracy increased by about 55%. GMTSM can not only accurately predict vehicle trajectory under normal circumstances, but also effectively improve the accuracy of trajectory prediction under road traffic flow changes, which is applicable to the real road environment.
Key words: intelligent transportation; iterative grid partition; trajectory prediction; model reliability; trajectory similarity
0 引言
随着交通工具的发展和出行规模的扩大,用户出行需求日益多样化,如何解决用户面临的交通拥堵、交通不安全等问题是所有城市需要共同解决的问题。随着无线通信设备和全球定位系统(Global Positioning System, GPS)设备的发展,获取用户出行的位置信息并非难事,对这些轨迹数据进行挖掘是当今研究热点。
在时空轨迹数据挖掘中,对移动对象未来位置预测是当今热点研究方向之一,有广阔的应用场景,具体如下:
1)基于位置的推荐。当一名用户通过社交网络分享了自己当前的位置,如果轨迹预测模型能够预测到该用户将要到达的区域,那么我们可以向该用户推荐必要信息,如餐饮信息、商场折扣信息等。
2)车辆之间未来轨迹共享,缓解交通堵塞。随着智能城市的发展,很多城市安装了监控系统,交通路况被实时记录下来。轨迹预测模型可以实时预测车辆未来的运行轨迹,交通部门可以预知未来的交通状况,同时,用户可以根据其他车辆的预测路线调整自己的路线,起到缓解交通压力的作用。
3)防止车辆碰撞。《青海交警发布2018年“春运”期间全省交通安全出行提示》中指出交通路口是车辆碰撞的高发地带,如果通过路口的用户提前预知其他车辆将来的轨迹,那么就可以提醒用户在通过路口时注意自己的開车路线,防止车辆碰撞发生。
移动对象未来位置受个人和集体移动模式影响。例如,去上班的路径选择主要受个人移动模式影响;去陌生的地方时,采用地图导航或询问他人等方式选择路径,主要受集体移动模式影响。现有位置预测方法只采用个人或集体的一种移动模式,具有局限性,没有考虑到轨迹影响因子(如时间、天气、季节等)。
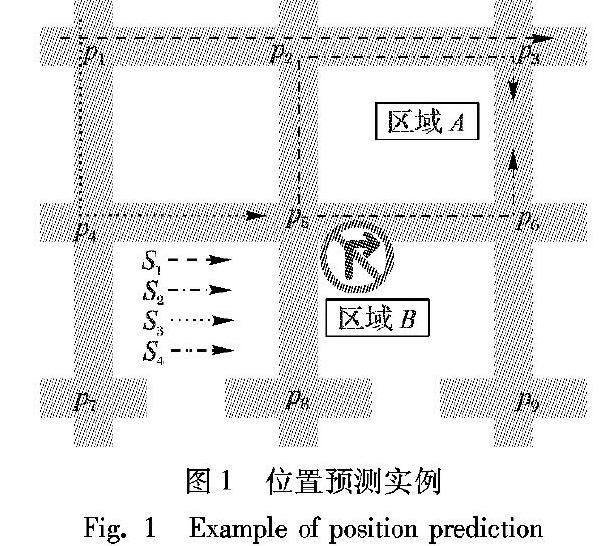
如图1所示,存在4条轨迹,S1=〈p1,p2,p3〉,S2=〈p5,p2,p3〉,S3=〈p1,p4,p5〉,S4=〈p5,p6〉,其中pi(1≤i≤9)是线性轨迹链中的轨迹点。当一辆车经过p1、p4,包含位置序列〈p1,p4〉的历史轨迹中出现次数最多的下一个位置将作为预测结果。在4条轨迹中,位置序列〈p1,p4〉和历史轨迹S3部分匹配,因此选择p5为下一个位置点。用户从区域B到区域A,在车流量非高峰期间,选择路线S4;在车流量高峰期间,点p5所在路口禁止右转,选择路线S2。因此,稳定、准确的轨迹预测模型需要考虑时间因素。
现有移动对象轨迹预测方法包括贝叶斯推理、马尔可夫链、隐马尔可夫模型、神经网络方法以及状态预测方法。Killijian等[1]考虑到历史状态的影响,提出高阶的马尔可夫链模型,扩展了马尔可夫链的流动性。李万高等[2]提出了一种改进的贝叶斯推理算法(Modified Bayesian Inference, MBI),解决了有限的历史轨迹数据问题,MBI建立的马尔可夫模型量化了相关的相邻的位置,划分历史轨迹能得到更多精确马尔可夫模型。
现有的轨迹预测方法中只对历史位置信息进行分析,很少将时间因素考虑在内。文献[3]对不同时间段的车流情况建立车辆移动模式(Vehicular Mobility Pattern,VMP)进行轨迹预测,这种方法虽然进行了时间箱的分割,但是很难找到合适大小的时间箱适配所有的移动模式。Zheng等[4]提出将空间预测数据和时序预测异构数据融合的方法,将道路结构、兴趣点分布等空间信息运用在半监督学习框架中,但预测效果不佳。
本文通过对现有轨迹预测模型的分析,结合道路车流量分析,提出基于高斯混合 时间序列模型(Gauss Mixture Time Series Model, GMTSM)的轨迹预测方法。主要内容有:1)针对均匀网格划分方法容易造成相关轨迹点分裂问题,提出迭代式网格划分,实现轨迹点的数量均衡。2)训练并结合了高斯混合模型(Gaussian Mixture Model, GMM)和时间序列分析中的差分自回归滑动平均模型(Autoregressive Integrated Moving Average model, ARIMA)。3)为了避免GMTSM混合模型中子模型自身不稳定性对预测结果产生干扰,通过对子模型的预测误差分析,动态计算子模型的权重。4)通过实验验证GMTSM的准确性和稳定性。
1 轨迹预测模型分析
移动对象的轨迹预测需要考虑自身因素、道路车流量因素、时间天气因素等多种因素。现有的轨迹预测模型主要分为以下三类:基于运动模型的轨迹预测、基于历史数据挖掘的轨迹预测和基于混合方法的轨迹预测。
1.1 基于运动模型的轨迹预测
移动对象的运动信息包括运动速度、运动方向和运动时间等。很多模型通过构造线性运动函数预测移动对象的运动信息。线性模型虽然高效,但不符合现实生活中移动对象非线性运动情况,导致预测误差大。若通过不断更新移动对象运动信息的方法降低预测误差,模型预测效率会下降。因此,线性模型轨迹预测不适合实际应用。
针对线性模型轨迹预测的缺陷,有学者提出了基于非线性模型的轨迹预测方法。文献[5]中改进线性轨迹预测模型,提出了一种并行的轨迹序列模式挖掘方法,结合了三个关键技术:前缀投影、并行表示、候选序列修剪。其中:利用前缀投影技术对搜索空间进行分解,减少候选轨迹序列;并行公式集成了数据并行公式和任务并行公式来划分计算,并以高效的方式将它们分配给多个处理器,从而降低跨处理器的通信成本。Tao等[6]提出一种支持任何运动模型的预测算法,基于未知模型对任何轨迹模式进行位置预测,但得到的运动函数仅适用于短时间的数据预测,无法预测长时间的数据。
1.2 基于历史数据挖掘的轨迹预测
基于运动模型的预测方法是建立线性或非线性函数进行预测,但预测误差大、预测时间短,考虑到运动模型没有充分用到移动对象的历史数据,基于历史轨迹数据的预测算法被提出。通过对历史轨迹数据的学习,观察移动对象频繁活动区域,挖掘数据隐含的规律。
基于历史数据的轨迹预测方法有贝叶斯网络、隐马尔可夫模型、神经网络以及高斯混合模型等。乔少杰等[7]在多种运动形式下建立GMM来实现移动对象复杂运动形式下的概率分布进行轨迹预测;同时,乔少杰等[8]还提出了基于隐马尔可夫模型的自适应轨迹预测模型,通过发现不连续的隐藏状态进行长期的轨迹预测。
Best等[9]提出了贝叶斯预测模型实现对人体运动的预测,但不适合快速移动对象预测。Xue等[3]提出了变阶的马尔可夫模型(Variable-order Markov Model, VMM),利用车辆互联的关系对车辆网络数据进行分析,挖掘车辆之间的移动模式;但只是对交通状况信息的获取,不能针对车辆使用者作出轨迹预测。
移动轨迹数据包含空间信息和时间信息,Lei等[10]通过获取移动对象在空间和时间上的运动行为建立时空轨迹模型,该模型建立轨迹后缀树,树上每个节点记录了下一个位置的空间信息和时间信息,实现了空间位置的预测,同时预测预定时间到达的概率。Gao等[11]充分考虑时间信息对轨迹的影响,使用贝叶斯公式进行位置点预测,实验结果显示,时间信息的引入可以提高预测准确性。
1.3 基于混合方法的轨迹预测
不同移动对象表现的运动规律性不完全相同,随着时间的变化,同一个移动对象在不同时间段内的运动模式也存在差别。同时,由于移动对象具有独特的生活方式和访问偏好,对历史位置的访问呈现幂律分布现象,只有少量位置被频繁访问,大多数位置访问次数稀少。针对不同移动对象、不同时间段以及不同位置需要混合多种预测方法进行预测。
Jeung等[12]采用分时预测的方式,提出依据预测时间选择不同预测方法的新思路;李昇智等[13]提出基于混合多步Markov模型的位置预测方法,将原始轨迹转化为区域轨迹,对各多步模型进行融合;Wiest等[14]提出结合贝叶斯网络和高斯混合模型(Variational Gaussian Mixture Model, VGMM)预测车辆行驶路径,该方法预测精度较高且时间开销较低;夏卓群等[15]提出基于VGMM环境自适应方法(Environment Self-Adaptive Prediction Method based on VGMM, ESATP),使用参数自适应选择算法自动调节参数组合,灵活调整混合高斯分量的个数和轨迹段大小。
综上所述,基于混合方法的轨迹预测通过分析移动对象运动模式进行不同方法的选择,对实时性要求高的移动对象轨迹预测适用性较弱。同时,这些混合方法没有考虑到移动对象流量变化对轨迹的影响,不能在任何时间保持稳定的预测效果。因此,本文提出GMTSM,对历史轨迹数据和历史车流量数据分析建模,在保证预测准确性的基础上,保持预测长期稳定性。
2 轨迹预测框架
马尔可夫模型、卡尔曼滤波模型和高斯混合模型都是常用的轨迹预测模型。一阶马尔可夫只考虑当前轨迹点对未来轨迹点的影响,不能充分利用历史轨迹点数据,预测准确率比较低;高阶马尔可夫预测模型增加了模型计算复杂度,不适用于海量轨迹数据的训练学习;卡尔曼滤波对长时间(如10s以上)的轨迹预测会由于预测误差的变大而严重影响预测准确性,并且模型复杂性增加,仅当处理的轨迹数据无噪声点时预测效果比较有效。
高斯混合模型(GMM)是一种基于非参数的概率模型,对具有噪声点的轨迹数据预测效果较好。概率模型进行轨迹预测的优势是:避免了轨迹数据离散性质的弊端,可以依据概率模型的精确度评判模型的预测误差。但是单独使用高斯混合模型进行轨迹预测,解决不了不同时间点预测误差差别较大的问题。
针对道路车流量數据变化大、随机性强、非线性等特点, 采用时间序列分析中的差分自回归滑动平均模型(ARIMA)对道路车流量进行预测。ARIMA模型优势是对数据序列的形式没有限制,训练需要有限的样本序列,车流量样本序列具有时序性和自相关性,为数据建模提供了足够信息,可以建立高精度的预测模型。ARIMA模型解决了交通流量预测存在的问题。
GMM是一种概率模型,能根据不同轨迹概率的比较确定预测轨迹;ARIMA则通过对不同路段车流量的预测得到各个路段车流量的比值,可以转化为车流量概率比。如果将GMM概率值和ARIMA概率值直接相加操作,可以解决不同维度信息不易混合的问题,不会出现文献[16]所提到的固定时间划分带来的预测不连续问题;同时,采用概率模型描述运动轨迹的方式,可避免轨迹数据离散性质的弊端,依据概率模型精度度量概率模型预测误差。
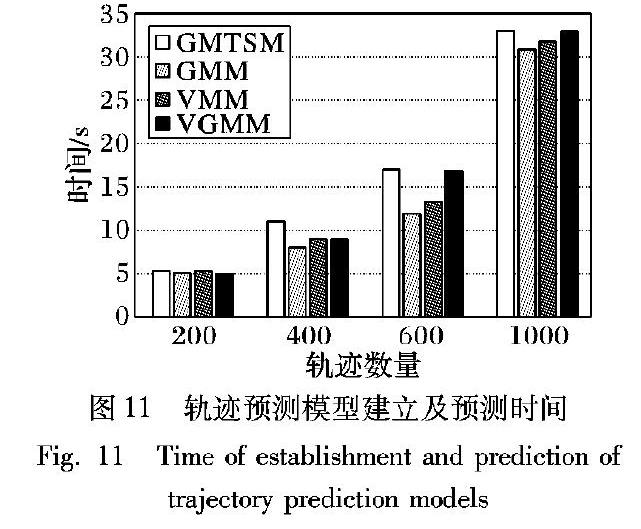
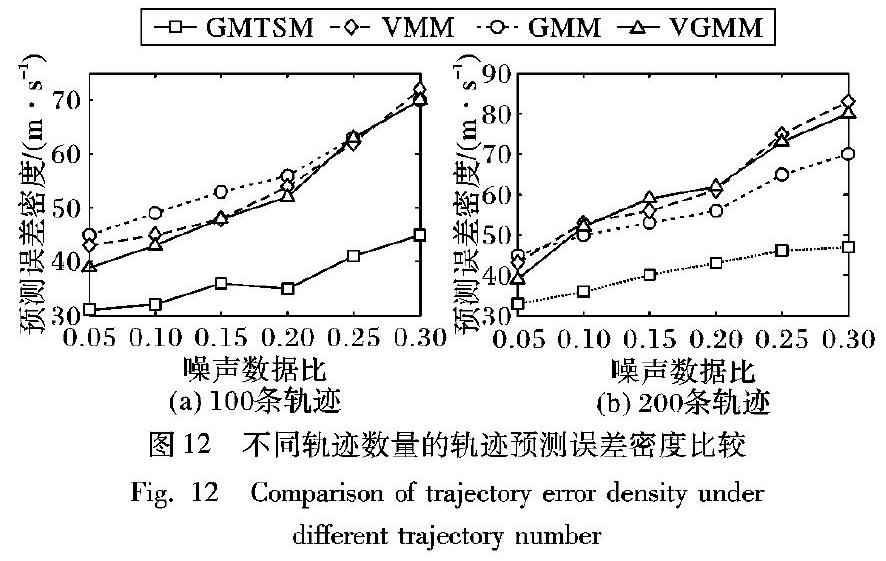
本文提出GMTSM轨迹预测模型框架如图2所示。首先将数据通过两个单模型训练,分别是迭代网格划分后的GMM和数据平稳化后的ARIMA模型;然后通过对单模型的误差分析调整模型权重,对模型进行加权融合;最终使用融合后的模型进行轨迹预测。主要研究内容有:1)针对均匀网格划分方法容易造成相关轨迹点分裂和划分尺度不明确的问题,提出迭代式网格划分,实现轨迹点初始聚类,并完成子模型训练学习。2)为了避免GMTSM中子模型自身不稳定性对预测结果产生干扰,通过对子模型的预测误差进行分析,计算子模型的可靠性,动态改变子模型的权重。
3 轨迹预测建模与实现
轨迹预测模型GMTSM首先对移动轨迹数据采用迭代网格划分进行轨迹链序列化,以便于建模处理;其次进行两个单模型的训练,分别为GMM和ARIMA模型;然后对两个模型进行误差分析,计算模型的权重;最后依据权重融合单模型,构造预测模型。
3.1 迭代网格划分
移动轨迹数据具有离散性和数据量大的特点,为了实现轨迹链序列化,通常采用均匀网格划分的方法对轨迹数据进行聚类处理。移动对象的相关轨迹空间被均匀划分到n×n大小相等的网格中,将映射到网格中的轨迹点连接形成轨迹链。但是,均匀网格划分存在以下两种问题:1)划分尺度没有明确依据,需要对轨迹数据的采样频率、活动范围和运动速度等因素进行分析。2)轨迹数据相关点容易分离到不同网格,造成数据分裂问题,增大数据分类误差。如图3所示,轨迹 TR 1、 TR 2的轨迹点被划分到不同网格中,得到3个聚类{C1,C2,C3}。通过计算欧氏距离判断两条轨迹的相似性,原本相似性比较高的轨迹 TR 1、 TR 2在均匀网格划分下相似性比较低,造成了轨迹相关点割裂。
迭代网格划分对高密度样本区域进行层次划分,划分层次的不断深入可以提高轨迹点覆盖网格的精度。迭代式划分对样本分布进行高密度的细分,使网格单元格尺寸得到一个合适值,实现单元格数据量的均衡,并在划分的网格上形成轨迹点初始聚类,排除了噪声数据,避免了关联数据的割裂问题。如图4所示。
迭代网格划分的优点是:
1)排除大量离群轨迹点,减少噪声数据干扰。
2)高密度区域迭代划分,减少网格数据量计算时间。
3)迭代划分结果使单元格数据量达到均衡状态,保证轨迹序列的有效性。
本文提出的迭代网格划分(Data-Iterative-Grid-Partition, DIGP)算法描述如算法1。
算法1 DIGP算法。
输入 轨迹数据集合D;网格划分初始参数s;单元格内轨迹点数量阈值num;
输出 迭代划分的网格集合G。
程序前
BE GIN //移动对象轨迹点被初始化为s×s长方形
Rects=initial_Partition(D);
//每一个分割的长方形重复迭代分割{g0,i | 0≤i≤(s×s)}
for each gi in Rects:
N=count_Points(g0,i);
//计算g0,i内轨迹点
if N>=num then //大于或等于阈值num
TmpG=Iterative-Grid-Partition(G,g0,i,num);
//IGP迭代
G.push(TmpG);
//在迭代网格分区集G中添加TmpG
el se
G.push(g0,i);
//将gi存入G
END
程序后
轨迹空间初始化为s×s个大小相同的矩形网格,初始划分得到的网格记为g0,i(0≤i≤(s×s))。通过阈值num判断单元格是否需要进一步划分,如果网格满足迭代划分条件,通过调用迭代划分函数Iterate-Grid-Partition(IGP)实现递归划分。IGP函数体现了DIGP“迭代划分”的特点,它的实现如下:
算法2 IGP算法。
输入 划分结果网格G;待划分单元格gi;单元格内轨迹点数量阈值num;
输出 经过迭代划分后的网格集合G。
程序前
BE GIN
for each gi, j in gi
gi+1, j=Partition(gi, j)
//将待划分的单元格四等分
N=count_Points(gi+1, j);
//计算gi+1, j中轨迹点数
if N≥num then
Iterate-Grid-Partition(G, gi+1, j, num);
//递归对gi+1, j进行划分
el se
G.push(gi+1, j);
END
程序后
其中,參数gi, j表示一个网格,i表示划分次数, j表示单元格的划分排序。每次将待划分的网格进行四等分划分,划分后的单元格被标识为gi+1, j(0≤j≤3)。
3.2 基于高斯混合模型的训练
高斯混合模型(GMM)是多个加权的高斯模型对样本概率密度分布进行估计的概率模型,每一个高斯模型都可以称为一类或一种模式。聚类过程中数据点的生成需要满足以下条件:
1)每个轨迹点随机来自于历史轨迹的迭代划分区域。
2)轨迹点映射到网格的概率为wi,且满足∑ m i=1 wi=1,m为单元格个数,也是初始聚类的个数,m值采用迭代网格划分算法得到。
为了准确地描述一条轨迹,将移动对象轨迹数据的空间信息按X、Y方向划分,实现轨迹线性化。如图5所示,通过对X、Y方向分别进行建模(螺旋状线),最后得到轨迹链(直线)。
轨迹链 S i={( x i, y i,ti) | 1≤i≤n}的概率由对X和Y方向特征矢量的高斯概率混合计算得到,如式(1)和(2)所示:
p(x | λ)=∑ m i=1 ωiGP( x n | μ x,i, Σ x,i)
(1)
p(y | λ)=∑ m i=1 ωiGP( y n | μ y,i, Σ y,i)
(2)
其中:GP( x n | μ x,i, Σ x,i)表示X方向上轨迹特征矢量 x n符合高斯过程的概率函数;Y方向上同理。将轨迹链划分到X、Y方向上的d维矢量表示为 X =( x 1, x 2,…, x d)T和 Y =( y 1, y 2,…, y d)T,d是轨迹链中轨迹点数量,概率函数定义如式(3)和(4):
GP( x i | μ , Σ )=
1 (2π)d | Σ | exp - 1 2 ( x i- μ )T Σ -1( x i- μ )
(3)
GP( y i | μ , Σ )=
1 (2π)d | Σ | exp - 1 2 ( y i- μ )T Σ -1( y i- μ )
(4)
其中: x i、 y i分别表示横坐标、纵坐标数据集合; μ 、 Σ 表示样本数据在X方向上经过高斯过程得到的均值和协方差矩阵,均值 μ =[E( x 1), E( x 2), …, E( x d)]T,协方差矩阵 Σ =(Cij)d×d,Cij=Cov( x i, y j);Y方向上同理。
GMM的聚类问题较为复杂,本文采用最大期望(Expectation Maximization,EM)方法实现参数求解。EM方法中迭代周期分为两个步骤,计算期望(E-step)和最大化(M-step),执行迭代直到收敛。对于轨迹 TR =( x n, y n),在E-step中,迭代网格划分得到GMM的初始聚类参数,第k个高斯模型在X方向生成的概率公式如式(5)所示,Y方向上同理。
p(i | x n,λ)= ωip( x n | i,λ) p( x n | λ) = ωiGP( x n | μ x ,i, Σ x,i) ∑ M k=1 ωkGP( x n | μ x,k, Σ x,k)
(5)
在M-step中,基于E-step计算出的样本概率值,通过最大期望方法确定第k个高斯模型的参数,如式(6)所示,求出的参数值作为式(5)的参数,进行下个迭代周期的计算,重复迭代过程直到收敛。
ω′i= 1 T ∑ N n=1 p(i | x n,λ)
μ ′i= ∑ N n=1 p(i | x n,λ) x n ∑ N n=1 p(i | x n,λ)
Σ ′i= ∑ N n=1 p(i | x n,λ) x 2n ∑ N n=1 p(i | x n,λ) - μ ′2i
(6)
其中:E-step是对每个高斯模型参数的估计;M-step的实现基于E-step估计的参数,M-step得到的值作为E-step中的参数参与计算,确定高斯模型参数,不断迭代上述步骤,直到参数波动很小,近似达到极值。
EM方法求解结果是参数的极值,与参数初始值相关性强,为了获得合适的求解结果,提升算法的收敛速度,文献[7]采用k-means方法获得求解参数初值,但是,k-means方法不能根据数据分布情况自动确定聚类个数,聚类个数的选择对聚类结果有较大的影响。针对上述问题,使用迭代网格划分的算法对轨迹进行聚类,将聚类结果作为EM方法的初始值,可以达到数据均衡的效果。
训练数据集Dtrain=( x , y ), x 表示输入数据, y 表示输出数据。测试数据集可表示为Dtest=( x *, y *), x *表示输入的测试数据, y *表示输出的预测值。则GMM概率密度函数如式(7):
p( y * | y )=∑ m i=1 Φi( y )F( y , μ i, Σ i)
(7)
其中:m是聚类个数; F( y * | y , μ i, Σ i)是模型回归函数;Φi( y )= ωiGP( y , μ iy, Σ iy) ∑ M i=1 ωiGP( y , μ iy, Σ iy) 表示轨迹点所在聚类的权重;ωi是第i个高斯权重,∑ M i=1 ωi=1; μ i=E[ y * | y ]= μ iy*+ Σ iy*y Σ -1iyy( y - μ iy)表示均值, Σ i= Σ iy*- Σ iy*y Σ -1iy*y Σ iyy*表示方差。
GMM首先對训练轨迹数据进行聚类分析;然后通过EM算法获得模型参数,符合正态分布的条件,得到m个高斯分量回归函数;最后通过式(7)得到轨迹概率模型。
3.3 基于时间序列模型的训练
ARIMA模型是差分运算与自回归移动平均模型(ARMA)模型的组合,ARMA(p,q)模型适用于平稳的时间序列,而在道路车流量预测应用中,轨迹数据的时间序列是非平稳的,需要通过差分运算将非平稳时间序列转化为平稳时间序列。ARMA(p,q)模型与差分运算组合形成ARIMA(p,q,r)模型,AR是自回归,p为自回归项数;MA为移动平均,q为移动平均项数;r为时间序列成为平稳时所作的差分次数。模型结构如式(8):
Φ(B)rxt=Θ(B)εt
E(εt)=0; Var(εt)=σ2ε,E(εtεs)=0,s≠t
E(xsεt)=0;s (8) 记为ARIMA(p,d,r)模型。其中,▽为差分算子,一阶差分指序列中连续相邻两项之差,即xt=xt-xt-1; r阶差分是对r-1阶差分再进行差分运算,即rxt=r-1xt-r-1xt-1;B为延迟算子,Φ(B)=1-φ1B-φ2B2-…-φpBp表示p阶自回归系数多项式;Θ(B)=1-θ1B-θ2B2-…-θqBq表示q阶移动平均系数多项式。 当ARIMA(p,d,r)模型默认q=0时,避免了参数求解过程中不确定性识别的复杂过程,降低了模型的时间开销,因此本文设定q=0。 路段车流量的预测分为下面四个步骤: 1)从数据库选取短时的动态车流量数据作为样本序列。 2)通过相关图和偏相关图对车流量序列进行平稳性检验,对于非平稳性时间序列,则采用差分方法将原始序列进行平稳化处理,变为平稳序列。 3)对初步选取的ARIMA(p,d,r)模型进行参数估计,包括对参数的显著性检验和随机性检验。本文使用最小二乘法进行参数估计,利用贝叶斯信息准则(Bayesian Information Criterion, BIC)进行模型阶次的确定。准则BIC的定义为BIC(p)=N lg σ2+p(lg N)/N,其中,N表示训练数据的总量;σ2表示模型的方差;p表示模型阶次的上限。 4)为了实现对车流量的动态预测,需要采集实时的车流量数据并更新数据库,最后重复步骤1)~3)。 ARIMA模型预测流程如图6所示。 3.4 模型预测误差分析 城市道路交通比较复杂,用户路径的选择受到上下班高峰期、天气、节假日等多种外界因素影响,同时也受自己主观意愿影响,任何轨迹预测模型都存在预测误差。 定义1 轨迹预测误差。轨迹预测模型将车辆历史轨迹数据集和车流量历史数据集作为输入,将车辆未来轨迹作为输出,其中,预测的轨迹链(虚线)和实际轨迹链(实线)之间存在的偏离度为预测误差,如图7所示。 均方根误差(Root Mean Squared Error, RMSE)用来衡量观测值同真实值之间的偏差,与平均绝对误差(Mean Absolute Deviation, MAE)相比,RMSE相当于L2范数,而MAE相当于L1范数,次数越高,计算结果对于较大值表现越突出,而忽略较小值。 因此,RMSE对异常值更敏感(即有一个预测值与真实值相差很大,那么RMSE就会很大),本文选择RMSE作为模型的误差计算。均方根误差如式(9),(xi,yi)是真实轨迹点坐标,(x′i,y′i)是预测轨迹点坐标,N为预测的轨迹点数。 RMSE= 1 N ∑ N i=1 (x′i-xi)2+(y′i-yi)2 (9) 定义2 预测误差密度。表示单位时间内偏离度的均方根误差大小,记为预测误差密度(unit Time Prediction Error Density, TPED)。TPED用于计算预测轨迹与实际轨迹之间的几何空间误差,如式(10)所示,N是轨迹点数,T是模型开始进行回归学习到下一时刻预测结束所消耗的时间。 TPED= 1 NT ∑ N i=1 (x′i-xi)2+(y′i-yi)2 (10) 在给定时刻t,模型在某一个轨迹点的失效概率称为失效分布函数F(t),该函数反映了预测误差的趋势,如式(11): F(t)=∫10 RMSEi T·∑ N i=1 RMSEi dt (11) 其中: RMSEi ∑ N i=1 RMSEi 表示某一轨迹点在整个回归周期的误差概率,T表示模型训练的一个回归周期,将二者相除,得到失效概率密度分布函数。通过将失效概率密度分布函数积分,得到模型在该轨迹点的失效概率分布。 3.5 模型权重计算 式(11)定义了模型的误差分布函数F(t),它可以呈现模型的预测误差分布,实现未来模型预测误差的计算。式(12)引入了模型可靠性R(R表示模型准确预测的概率),在规定时间内,模型预测误差越小可靠性越大。 R=1-F(t) (12) 本文通过微软亚洲研究院T-Driver项目[17-18]的数据得出GMM和ARIMA在正常情况和突发情况(节假日)下模型可靠性与TPED的关系,如表1。 从表1可以看出两种模型的可靠性随着预测误差的增大而降低,模型可靠性与TPED呈负相关关系。在正常情况下,GMM的可靠性在0.80~0.95,准确性比较高;在突发情况下,GMM预测误差变大,可靠性也大幅度减低,只有0.20~0.40,因此GMM在突发情况下可靠性比较差。ARIMA只是对车流量的预测,在兩种情况下,预测误差变化比较小,可靠性比较稳定,保持在0.80~0.95,但时间序列模型不能实现对车辆轨迹的预测。为了在两种情况下实现准确的轨迹预测,本文将两种模型进行混合,并且通过可靠性动态分配它们的权重。 本文采用文献[19]提出的模型相似性,记为SI(Ri,Rj),其中i≠j。Ri、Rj分别是两种模型的可靠性,DI(Ri,Rj)= | Ri-Rj | 表示不同模型之间可靠性的差异程度,并且SI(Ri,Rj)和DI(Ri,Rj)满足正态分布。模型相似性如式(13),可靠性分析结果之间的距离越大,则两个模型的相似度越小。 SI(Ri,Rj)=e-DI(Ri,Rj) (13) 两个模型的相互支持程度可表示为: A(Mi)= 1 n-1 ∑ n j=1, j≠i SI(Ri,Rj) (14) 两个模型结果之间的相互支持程度分别作为各模型的动态权重,可表示为: ωi= A(Mi) ∑ n i=1 A(Mi) (15) 本文将GMTSM、GMM和ARIMA三种模型之间的相似度计算的权重(式(15)得到的权重)和GMM、ARIMA两种子模型可靠性得到的权重(每个子模型可靠性与所有子模型可靠性之和的比值)进行混合模型可靠性比较。数据来源于微软亚洲研究院T-Driver数据,分别在法定节假日期间采集的三组数据集(D1,D2,D3)上进行比较,如表2所示。 从表2可以看出,通过计算GMTSM、GMM和ARIMA三种模型之间的相似度求得子模型权重比直接通过子模型可靠性得到权重的混合模型可靠性要高,因此,本文选用三个模型的相似度进行权重的计算。 3.6 预测模型实现 高斯混合 时间序列模型的轨迹概率公式定义式(16): p( x n, y n | λ)=ω′1 ( ∑ m i=1 ωiGP( x n, y n | μ i, Σ i) ) + ω′2 ( ∑ m i=1 ωiARIMA(p,d,0) ) (16) 其中:ω′1+ω′2≠1, S d+1 =f( S d, S d-1,…, S d-k+1), S d+1 =f( S d, S d-1,…, S d-k+1)的值是基于三种模型(GMTSM、GMM和ARIMA)相似度求得,因此子模型的权重之和不等于1。 GMTSM混合模型采用线性回归的思想理论对时空轨迹数据进行处理,采用轨迹点迭代的方式进行长距离预测。首先,模型输入当前时刻位置信息进行第1步的预测,表示为 S d+1 =f( S d, S d-1,…, S d-k+1);然后,将第1步预测轨迹点存入历史轨迹数据集合,实现第2步轨迹预测;依此类推,第n步(d+n位置)预测轨迹链表示为 S d+n =f( S d+n-1, S d+n-2,…, S d+n-k)。其中,{ S 1, S 2,…, S d | S i=(xi,yi,ti)}为真实有序的历史轨迹链,k为回归预测过程输入的历史轨迹长度。轨迹位置预测需要将上一步预测值作为历史轨迹点数据,迭代预测移动对象未来位置。GMTSM预测流程如图8所示。 GMTSM通过对历史轨迹聚类和建模,进行回归预测,将训练数据集Dtrain={(xi,yi)}Ni=1=(X,Y)分为Dx={(xi-1,Δxi)}Ni=2和Dy={(yi-1,Δyi)}Ni=2分别处理。已知轨迹位置序列为{x1,x2,…,xd},GMTSM轨迹预测具体工作原理如下: 步骤1 步骤在X和Y方向对移动对象分别进行预测建模,得到各自轨迹预测的回归函数f,以X方向为例,表示为xd+1 =f(xd,xd-1,…,xd-k+1)。预测下一个位置点xd+1,其中,xd+1 =fx(x)+εx,d,通过Δx={Δx2,Δx3,…,Δxd}求出下一个位置增量Δxd+1=xd-xd-1,ε为轨迹噪声,ε~N(0,σ2),计算公式如式(17): Δxd+1 =fx(Δx)+εx,d (17) 步骤2 利用真实数据值x=[x1,x2,…,xd-1],Δx=[Δx2,Δx3,…,Δxd],预测xd+1=xd+Δxd+1的值,得到d+1位置点在X方向的坐标为:xd+1=xd+Δxd+1,得到回归方程式(18): Δxd+1 =fx(Δx)=∑ M i=1 Φi(x)f ^ i(Δx) (18) 其中:f ^ i(Δx)=Ki(x*,x)(Ki(x,x)+σ2I)-1Δx, Φi(x)= ωiGP(Δx;0,Ki(x,x)) ∑ M i=1 ωiGP(Δx;0,Ki(x,x)) 。 步驟3 从轨迹链 TR ={ S 1, S 2,…, S n}提取部分历史轨迹{ S 1, S 2,…, S d},通过回归方程得到d+1时刻X和Y方向上的预测增量Δxd+1 、Δyd+1 ,得到位置点的预测值式(19): S d+1 = (xd+1 ,yd+1 ,td+1)=((xd,Δxd+1 ),(yd+Δyd+1 ),td+1) (19) 步骤4 通过步骤3得到的第i个聚类中的 S d+1 的值记为 S d+1 i,利用式(20)比较不同聚类形成的多条预测轨迹链,选择概率最大的记为最终轨迹链 S d+1,如式(20): Sd+1= max{Sd+1 i}=max { ω′1 ( ∑ m i=1 ωiGP( x n, y n | μ i, Σ i) ) +ω′2 ( ∑ m i=1 ωiARIMA(p,d,0) )} (20) 本文提出的基于高斯混合 时间序列模型的轨迹预测算法如算法3所示。 算法3 GMTSM算法。 输入 训练历史轨迹数据集D; 输出 模型预测轨迹链 S 。 程序前 Be gin data=ReadFile(filename); //获得历史轨迹序列 CM=DIGP(D); //迭代网格划分,获得聚类 set_parameter(ω, μ , Σ ); //混合模型参数初始化 wh ile(True): E_step(CM,ω, μ , Σ ); //EM算法参数预计过程 M_step(CM, ω, μ , Σ ); // EM算法最大化过程 flg=Judge(ω, μ , Σ ); //判断参数是否达到规定阈值 if (flg) BREAK; G=GP(ω, μ , Σ ,CM); //获得高斯混合模型G rolmean=Rollmean(N); //获得车流量平均数 rolstd=Rollstd(N); dftest=Adfuller(N, rolstd, rolmean); //用adf检验平稳性 dfoutput=Series(dftest[0:4]); ts_log=Log(N) moving_avg=Rollmean(ts_log); decomposition=Decompose(N, moving_avg); P=ARIMA(N); //获得时间序列模型P fo r i in K //K为预测的时刻数量 Dω=Train(G,P,i); //子模型的权重训练x S =predict(G,P, Dω); //预测轨迹链 END 程序后 4 实验验证和分析 4.1 实验环境 本文的实验数据是微软亚洲研究院T-Driver项目GPS采集的轨迹数据,含有2009年北京一万多辆出租车一周的轨迹数据。该数据集的轨迹数据由一系列时间戳表示,每个点包含经度、纬度、时间和车辆编号信息。实验过程中,将数据分为工作日数据组和非工作日数据组两类,D1、D2、D3组为工作日轨迹数据,D4、D5、D6组为非工作日轨迹数据,实验中所用的参数见表3。 为了对本文提出的GMTSM进行性能上的检验,从三个条件选择对比算法: 1)概率模型。概率模型在轨迹预测上具有一定优势,GMTSM是一种概率模型,通过概率模型之间的对比分析,可以展示GMTSM的混合优势。 2)混合模型。混合模型对轨迹预测达到优势互补的效果,GMTSM是一种混合模型,通过混合模型之间预测效果的对比,可以分析GMTSM将车流量预测考虑到轨迹预测中产生的效果。 3)非概率、非混合模型。选择一种与GMTSM不同类型的轨迹预测模型,可以检测GMTSM子模型选择的可行性,同时分析GMTSM预测效果的稳定性。 实验部分选取了高斯混合 时间序列模型(GMTSM)、高斯混合模型(GMM)、贝叶斯网络-高斯混合模型(VGMM)和变阶隐马尔可夫模型(VMM)四种模型进行对比分析,分别从预测误差密度、预测时间、抗干扰性分析以及不同时长的预测四个方面作对比分析。 4.2 预测误差密度分析 本节实验实现了四种模型在工作日数据组(D1、D2、D3)和非工作日数据组(D4、D5、D6)下对轨迹预测误差密度的对比分析,每组数据包含100~1000条测试数据。实验对轨迹预测误差密度进行比较,比较结果如图9所示。 从图9得出以下结论: 1)在工作日数据组(D1、D2、D3)下,四种模型的预测误差密度均在25~50m/s,预测效果都比较稳定。 2)在非工作日数据组(D4、D5、D6)下,GMM、VMM和VGMM均出现预测误差密度变幅比较大的现象,误差密度在60~110m/s,而GMTSM模型的预测误差密度仍保持40m/s左右,相比其他三种模型准确度平均提高了50%~60%。原因是:非工作日期间,GMM和VGMM只学习车辆历史轨迹数据,沒有考虑到因车流量突变情况导致历史轨迹数据的可信度降低;VMM虽然考虑到交通流量的变化,但是通过出租车的相互通信来寻找车辆规律,提供当前交通拥堵情况,不能预测所有车辆的轨迹;GMTSM对历史轨迹进行学习,并且对道路车流量进行预测,提前预测到非工作日道路的车流量情况,动态调整子模型权重进行线路的概率选取,在道路车流量突变情况下也能准确预测轨迹。 本文同时给出了在道路维修或新道路启用等突发情况下模型的轨迹预测情况,如图10所示。在实验测试路段,30s之后进入街道维修路段。从图10可知,在道路维修突发情况下,GMTSM出现刚开始预测误差密度变大,后来逐渐变小的现象。因为GMTSM在模型参数自动更新后,检测到某些路段车流量为零的情况时,会调整混合模型中的子模型权重,按车流量变化的方向进行预测,并训练最新的历史轨迹数据进行重新学习,从而降低了预测误差密度。而其他三种模型只是根据车辆历史轨迹进行预测,不能识别突发情况信息,导致交通情况的误判。 4.3 预测时间比较分析 在车辆轨迹预测应用系统中,轨迹预测模型输出时间十分重要,为了计算轨迹预测模型的时间代价,本节实验比较了四种模型在工作日和非工作日不同数据组下的时间消耗。在实验过程中,模型建立时间和预测时间单独计算,模型建立时间是对子模型的构建和混合模型的初始化时间,不包括轨迹迭代网格划分的时间;模型预测时间包括子模型可靠性分析和混合模型预测值的输出时间。实验结果如图11所示。 从图11可以得出以下结论: 1)四种模型预测时间都随着轨迹数据量的增大而增加,在正常线路下,30min内车的轨迹条数在400条左右,四种模型的预测时间消耗均在10s左右,保证了预测的实时性。 2)不同数据组下,GMTSM的时间消耗比其他三种模型多5s左右,原因在于:GMTSM由两种子模型混合而成,子模型需要进行单独预测。为了实现数据动态性,需要进行模型参数更新,经实验得出,高斯混合模型为5min更新一次,时间序列模型每3h更新一次,预测准确性较高。虽然预测时间和轨迹数量正相关,但是,相对于轨迹预测准确性的重要性,消耗的时间在可接受的范围内。训练数据集中最大的训练轨迹数量为1000条时,混合模型的建立及轨迹预测总时间为30s,说明GMTSM实时性较好。 4.4 抗干扰性分析 GPS采集的数据存在噪声,会对轨迹预测模型产生干扰。本文选取工作日的轨迹数据进行抗干扰性分析,结果如图12所示。 因为除GMTSM外的三种模型在非工作日数据组下误差比较高,进行抗干扰性分析意义不大,所以只选取工作日数据进行实验。 1)在相同的参数设置下,GMTSM的预测误差密度比其他三种模型都要低,原因在于:GMTSM对轨迹点初始化聚类使用了迭代网格划分,达到了数据量均衡的效果,能降低噪声数据的干扰;同时GMTSM预测模型会对道路车流量进行预测,能减少预测误差、提高预测准确度。 2)在相同轨迹数据量下,四种预测模型预测误差密度都随噪声数据比的增大而增大。原因在于:GMTSM、GMM和VGMM需要对历史轨迹点进行聚类分析,若轨迹数据中噪声数据比增加,则有些轨迹点被划分到距离远的聚类中,出现较大的预测误差;而VMM是通过可观察的参数推算需要的隐含参数,当噪声数据比重增加时,对观察参数产生影响,因此对模型的预测误差密度产生了很大的影响。 [9] BEST G, FITCH R. Bayesian intention inference for trajectory prediction with an unknown goal destination [C]// Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE, 2015: 5817-5823. [10] SU I, LEI P, SHEN T J, et al. Exploring spatial-temporal trajectory model for location prediction [C]// Proceedings of the 2011 IEEE International Conference on Mobile Data Management. Piscataway, NJ: IEEE, 2011:58-67. [11] GAO H J, TANG J L, LIU H. Mobile location prediction in spatio-temporal context [EB/OL]. [2018-05-12]. https://www.researchgate.net/profile/Huan_Liu6/publication/265437484_Mobile_Location_Prediction_in_Spatio-Temporal_Context/links/551c9ba80cf20d5fbde557eb.pdf. [12] JEUNG H, SHEN H, LIU Q, et al. A hybrid prediction model for moving objects [C]// Proceedings of the IEEE 24th International Conference on Data Engineering. Piscataway, NJ: IEEE, 2008:70-79. [13] 李昇智, 乔建忠, 林树宽, 等. 基于GPS轨迹数据的混合多步Markov位置预测[J]. 东北大学学报(自然科学版), 2017, 38(12): 1686-1690. (LI S Z, QIAO J Z, LIN S K, et al. Hybrid multi-step Markov location prediction based on GPS trajectory data[J]. Journal of Northeastern University (Natural Science), 2017, 38(12): 1686-1690) [14] WIEST J, HFFKEN M, KREEL U, et al. Probabilistic trajectory prediction with Gaussian mixture models [C]// Proceedings of the 2012 IEEE Intelligent Vehicles Symposium. Piscataway, NJ: IEEE, 2012:141-146. [15] 夏卓群, 胡珍珍, 羅君鹏, 等. 不确定环境下移动对象自适应轨迹预测方法[J]. 计算机研究与发展, 2017, 54(11):2434-2444. (XIA Z Q, HU Z Z, LUO J P, et al. Adaptive trajectory prediction for moving objects in uncertain environment [J]. Journal of Computer Research and Development, 2017, 54(11):2434-2444.) [16] BILJECKI F, LEDOUX H, van OOSTEROM P. Transportation mode-based segmentation and classification of movement trajectories [J]. International Journal of Geographical Information Science, 2013, 27(2): 385-407. [17] WEI Y, ZHENG Y, YANG Q. Transfer knowledge between cities [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York,: ACM, 2016: 1905-1914. [18] ZHENG Y, CAPRA L, WOLFSON O, et al. Urban computing: concepts, methodologies, and applications [J]. ACM Transactions on Intelligent Systems and Technology — Special Section on Urban Computing, 2014, 5(3): No.38. [19] MUSA J D. A theory of software reliability and its application[J]. IEEE Transactions on Software Engineering, 1975, 1(3): 312-327.
