堤防工程数据标准化研究
2019-10-23罗登昌于起超3马丹璇
罗登昌,韩 旭,于起超3,马丹璇
(1.长江勘测规划设计研究有限责任公司,武汉 430010; 2.长江岩土工程总公司(武汉),武汉 430010;3.中南设计集团(武汉)工程技术研究院有限公司,武汉 430071)
1 研究背景
21世纪水利面临3大问题:洪涝灾害、水资源短缺、水环境恶化,其根源是水资源不合理的开发与利用,而解决这一根源的最好方法是水利信息化。通过水利信息化可实时有效的配置、治理及保护水资源。
堤防工程作为水利工程重要组成部分,其信息化成果势必会推动水利信息化进程,然而堤防信息化的基础是堤防数据标准化,数据标准化的研究将助力堤防数据信息化发展。通过查阅大量数据标准化文献了解国内外研究现状,目前,国外未见堤防数据标准化的文献。
国内学者主要在生态环境数据、引调水工程、城市地质调查等方面对数据标准化进行研究:李喆等[1]深入分析长江流域生态环境数据的主要种类及其特点,分别给出长江流域生态环境信息库中特征数据集、栅格数据集和TIN数据集的组织方式,讨论空间数据与属性数据的连接方法;饶小康[2]针对水利工程灌浆大数据,设计平台总体架构,搭建Hadoop分布式集群,设计并行化数据挖掘算法,实现水利工程灌浆大数据平台,实现了数据资源的集成共享、业务的高效处理、数据信息的知识发现,提高了数据存储和处理效率和精度;牛广利等[3]对安全监测实际工作需求,设计和研发了一套基于云平台的大坝安全监测数据管理及分析系统,实现了安全监测数据的智能感知、云端管理、专业分析与监控预警;Zhang等[4]等先对多源数据的来源进行分析,然后从基础数据组、钻孔数据组、地质测绘数据组及岩石属性数据组4方面分析各自数据的特点并制定了多源数据标准;王继民等[5]结合南水北调东线工程,提出数据标准化的内容范围、要素单位、取用精度和采集频率及操作要点;黄伟等[6]在异构系统中利用数据平面、应用平面以及对应用系统整合的方式实现了数据共享;吴涵宇等[7]采用数据集成方式把异构的、分布式的水利行业相关数据汇集,以空间数据为框架,通过统一的数据模型设计和对象编码体系构建数据库群,从而实现科学、高效、有序的应对体系和资源共享模式;徐德馨等[8]针对武汉市地质条件和城市地质调查工作需要,建立了武汉市城市地质调查数据分类和编码体系,制定了数据库设计规范,为地质调查数据信息化管理奠定了坚实基础;刘慧梅[9]从数据管理方面、信息系统建设方面、管理制度方面及行业交流4个方面阐述了信息化必须要做好的工作。
国内外学者在堤防工程数据标准化领域的研究鲜见,而且目前数据标准化主要是对结构化数据标准化的研究,对于非结构数据标准化的研究较少,标准化的研究具有片面性,同时在标准化的过程中没有或较少涉及数据的清洗,然而数据清洗是标准化中很关键的一步,标准化的研究缺乏系统性。
本文根据堤防工程数据的特点,并对数据收集到清洗入库的全过程进行分析,数据标准化主要包含3方面内容:结构化数据标准化、非结构化数据标准化、数据入库与清洗。
2 结构化数据标准化
本文堤防工程结构化数据的标准化主要包括3个步骤:①堤防工程数据分类;②数据编码;③数据表设计。
2.1 数据分类
堤防数据来源于多专业、多部门,根据其属性特点分为8类数据,分别为工程、水文气象、人文经济、地理、地质、物探、险情和监测数据,见图1。
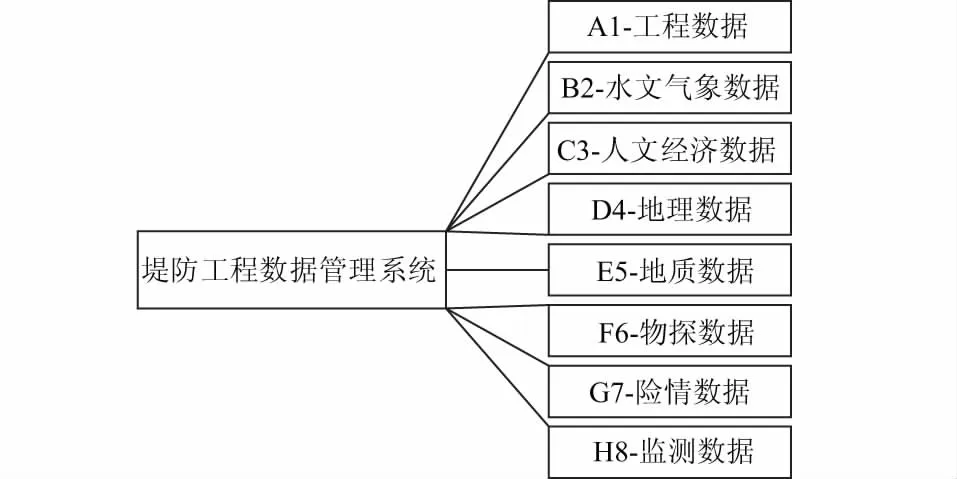
图1 堤防工程数据管理系统数据分类
堤防工程的8类数据分述如下:
(1)工程数据。工程数据包括堤防设计工程数据、堤防堤基处理工程数据、堤防加固工程数据、堤防扩建工程数据、堤防改建工程数据、堤防管理工程数据、建筑物与构筑物数据、护岸工程数据。
(2)水文气象数据。水文气象数据包括河段概况信息数据、气象信息数据、水文站信息数据、平均径流量年内分配数据、平均输沙量年内分配数据、暴雨信息数据、洪水信息数据、设计洪水位数据、设计枯水位数据及施工分期设计水位数据。
(3)人文经济数据。人文经济数据包括社会信息数据、经济信息数据、生态环境状况信息及灾害信息数据。
(4)地理数据。地理数据包括基本GIS信息数据及测量成果数据。其中基本GIS信息数据包括测量控制点数据、水洗数据、居民点及设施数据、交通数据、管线数据、境界与政界数据、地貌数据、植被与土质数据、地名数据、数字正射影像数据及地籍测量数据;测量成果数据包括地形图和断面图。
(5)地质数据。地质数据包括勘探数据、工程地质数据及试验数据。其中勘探数据包括钻探数据和坑探数据;工程地质数据包括区域地质数据、工程地质成果数据、水文地质基本数据以及施工地质数据;试验数据包括室内试验数据和原位试验数据。
(6)物探数据。物探数据包括直流电阻率法数据、自然电场法数据、瞬变电磁法数据、探地雷达法数据、拟流场法数据、弹性波法数据、温度场法数据、同位素示踪法数据、层析成像数据及其他方法得到的数据。
(7)险情数据。险情数据包括险情概况信息数据、险情段的水文信息数据、堤身形态数据、堤身地质信息数据、堤基地质信息数据、岸坡地质信息数据、微地貌信息及其他信息数据。
(8)监测数据。监测数据包括堤防水下变形监测数据、渗流与地下水监测数据、物探监测数据、压力监测数据、应力应变及温度监测数据、变形监测数据及环境因子监测数据。
2.2 数据编码
分析8类数据中每类数据包含的层级关系,得到各类数据最多所需要的层级,其中工程数据、水文气象数据、人文经济数据、地理数据、地质数据、物探数据、险情数据、监测数据需要的层级数分别为4,2,1,4,6,4,1,4。根据折中又不影响数据全部录入原则,最后确定用五级节点目录来划分数据结构,每级目录给予一个分类码,前4级目录分类码从“1~9”及小写英文字母中取值,其中小写英文字母去掉“o”和“z”,目录等级不够的用数字0填补,最后的底层目录(第5级目录)用2位数字编码,范围从“01~99”中取值,以给文档和表格编号,见图2。每级分类码及底层编码均未满,数据库的扩展性强。
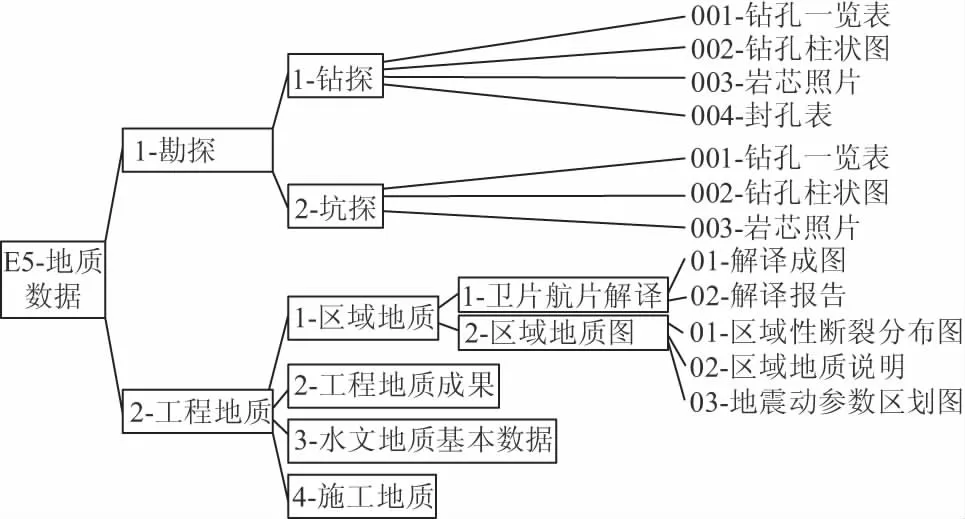
图2 堤防工程数据管理系统数据编码示意图
2.3 数据表设计
针对数据编码底层目录中的结构化数据表进行设计[10-12],其主要包括6方面内容。
(1)中文表名。由汉字组成,一般来说字数<20,简明扼要地表达该表所描述的内容。
(2)表主题。进一步阐述表的内容和目的。
(3)表标识。该表在数据库中的真实表名,命名规则是:T_xxx_X,其中T为表格式类码;xxx为中文关键字的英文简写,一般来说长度不超过30个字符;X为主题标识,一一对应8种数据,从大写字母A—H中取值。
(4)表号。即为数据编码,从编码图中获得。
(5)表体。表体设计主要包含7方面的内容:序号、字段名、字段标识、类型及长度、必填项、单位及主键,其中序号是对字段个数的统计;字段名根据表格所要表示内容确定;字段标识是字段在数据数据库中的表现方式,命名规则是字段名中文关键字的英文缩写,一般来说字母个数<10,不足10个时用全名;类型及长度是对字段的类型和长度进行定义,其中类型一般包括定长字符串char、变长字符串varchar、整型int、双精型double、日期型date及时间型time,长度需要根据字段可能表示长度确定,宜多不能少;必填项是对字段名是否为非空字段进行定义,非空就填Y,否则不填;单位是根据字段的属性选用国际通用单位,有则填,无则不填;主键是对字段是否为主键进行设定,主键必须为非空。
(6)代码。字段取值为固定选项时,宜以字段代码代替文字输入[13-14]。本数据代码采用一个表格将所有的代码填入其中,下不封口,见表1。
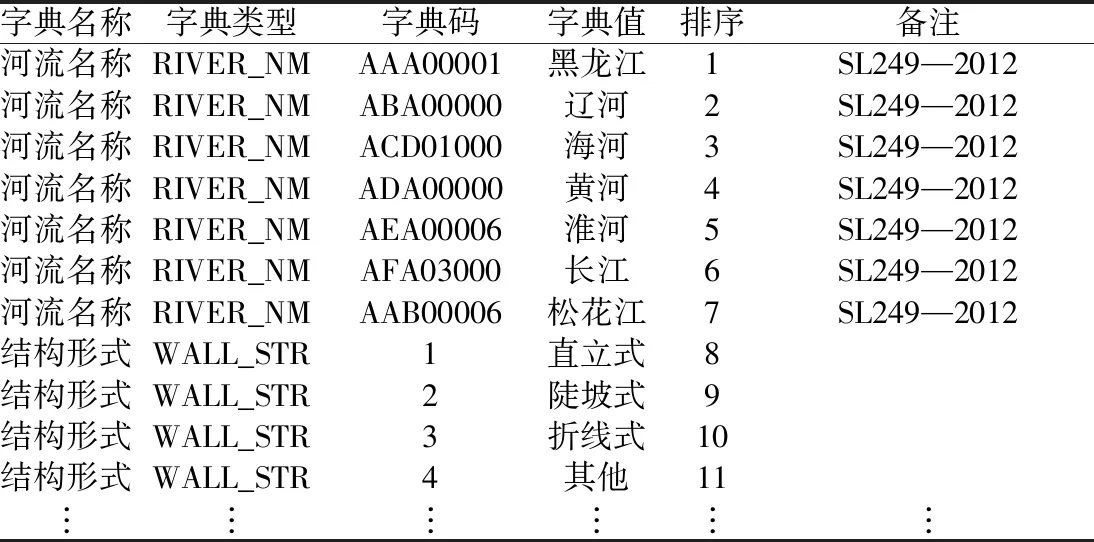
表1 堤防工程数据管理系统数据代码
代码表主要包含6方面内容:字典名称即为字段名;字典类型为标段标识;字典码为不同字典值的代码;字典值为每个字典码代表的中文含义;排序是字典值的顺序;备注主要标识应用的规范,对于已有规范规定的代码,字典码按规取值,备注里填写引用的规范;对于无规范规定的字典码,按照字典值个数,用数字来表示字典码。
3 非结构化数据标准化
Java Script对象表示法(Java Script Object Notation,JSON)是一种轻量级的数据交换格式,具有良好的可读性以及快速编写特性,可以在不同平台间完成数据交换。
本文采取“非结构化数据-JSON-结构化数据”的转换方式,将非结构化技术资料的元数据信息转换为可存储在数据库中的结构化数据,为非结构化数据标准化问题提供解决方法。
针对堤防工程数据的分类,利用JSON对堤防工程相关非结构化数据的共有属性进行描述和表达。这些非结构化数据多以Word文档、图片和多媒体文件的形式表现,其共有属性具有一定的结构性,例如Word文档中的工程地质勘察报告,其共有属性包含:描述堤段所在流域、省份、堤坝分段(描述堤段所属大范围堤段),数据分类(8类数据中的一种),桩号(描述堤段的起始桩号),主要描述内容等。在文档上传的时候录入这些共有信息,见图3,然后根据这些结构性信息编写相关的JSON文档,最终将带有JSON信息的非结构化文档储存在数据库中,方便后期对非结构化数据进行检索。
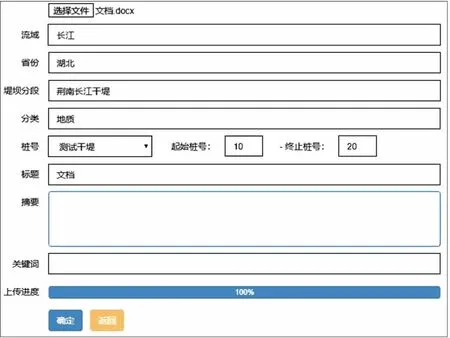
图3 堤防工程数据文档上传界面
4 数据入库与清洗
堤防工程数据来源于多个部门,且分属不同的系统,数据在标准化过程中有以下2方面的问题。
(1)数据源的异构性。堤防数据的数据源较为复杂,主要包含2类数据:结构化数据,如关系型数据;非结构化数据,如Word文档、视频、图片等。针对不同的数据类型,采用的数据清洗和入库的方式是不同的。传统方式只能对每一种数据源单独开发一套数据采集、清洗、入库规则程序,数据标准化过程复杂,很难做到对数据的统一管理。
(2)数据质量不高。主要表现在以下几个方面:①源表与目标表存在“一对一”“一对多”或“多对一”的映射关系;②源表字段与目标字段的名称、数据类型、呈现方式等存在差异;③数据字段格式不统一,比如时间和参数等,存在大量的转换、合并、拆分、截取、替换、计算等处理等清洗操作。因此在数据标准化过程中需制定大量的清洗规则。
基于上述问题,本文提出一种关于数据清洗的数据标准化的方法,能够实现异构数据源统一接入和数据清洗的动态配置,降低了数据标准化的复杂度。
4.1 数据清洗架构
数据清洗架构如图4所示,主要包括数据接入、数据清洗、调度中心几个模块。数据接入模块解决了异构数据源不能统一处理的问题,不同类型数据通过不同方式接入到系统中,并通过数据清洗模块进行统一处理,最终统一放入目标库中。
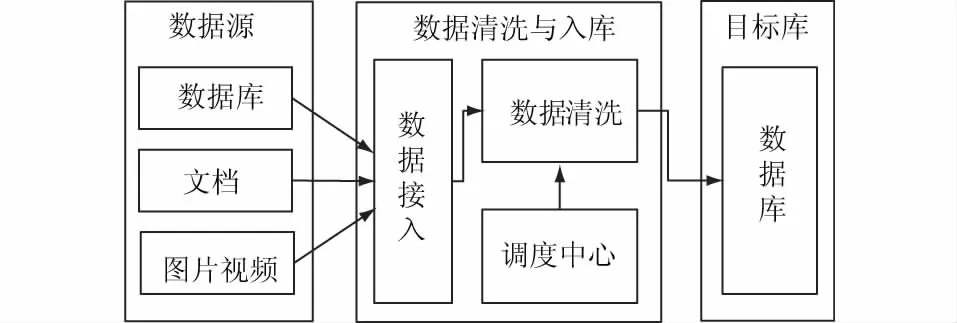
图4 数据清洗架构
4.2 数据接入
对2种不同数据结构的数据源分别进行数据抽取,数据接入模块如图5所示,其主要由SQL执行模块、定时器模块和文件监听模块组成。将抽取后的数据统一推送至消息队列Kafka中,Kafka是一种高吞吐量分布式发布订阅消息系统,数据清洗模块再对消息队列中的数据进行数据清洗。
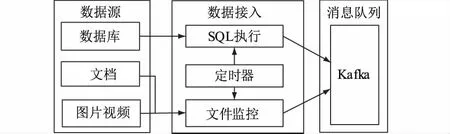
图5 数据接入模块
(1)SQL执行模块。SQL执行模块是针对关系型数据库的一种抽取模块,通过编写SQL脚本,定时获取数据库中某些列的数据,并将数据推送到Kafka中。
(2)定时器模块。定时调用SQL执行模块和文件监控模块,读取结构化、半结构化数据和非结构化数据,通过调节定时参数,可以控制数据读取的速率。
(3)文件监听模块。文件监听模块主要是监听某个或某些文件夹文件的增加情况,当有新文件增加时,读取并解析文件,并将解析后的数据推送到Kafka中,主要实现流程如下:
①利用定时器模块的定时循环执行文件监控程序。
②利用WatchService实时监听文件夹是否有新文件增加,通过阻塞式IO流实现文件上传服务器,并进行解析文本操作,如果是Excel,则按照行进行提取。
③将解析后的结构化数据推送到Kafka中。
4.3 调度中心
调度中心用来管理数据清洗的脚本文件,实现清洗脚本的动态注册与加载。当增加一种数据源时,首先进行数据调研,建立源表和目标表,源字段和目标字段之间映射关系,制定数据迁移方案,然后对不同的数据编写各自的数据清洗脚本,并通过WEB界面动态注册到调度中心。
4.4 数据清洗
数据清洗主要包括数据验证和数据转换,其主要任务是解析用户注册的数据清洗脚本和配置信息,并生成数据清洗的程序,从源数据库抽取相应数据,进行相应转换操作(字段合并、字段拆分、类型转换、值替换、字段计算等)。
(1)数据验证。进行数据验证基于以下2个原因:①防止出现无法预料的异常错误造成转换操作中止;②审核数据是否满足预先设定要求,因此需在数据清洗预处理阶段进行数据验证。数据验证主要是通过正则表达式验证字段数据的有效性,正则表达式可验证数据是否是数字、字符、连字符、空格、取值范围等,例如:验证输入文本文件名称以“txt”开始,后面紧跟日期格式“yyyy-mm-dd”,正则表达式可设置为“txt(20)dd-(0[1-9]|1[012])-([01][1-9]|3[01]).txt”,“txt2016-12-15.txt”为符合规则文件名称,“txt5016-24-35.txt”为不符合规则文件名称。
(2)数据转换。脚本解析模块解析用户提交的脚本和配置,生成字段映射表和相应执行程序,抽取源数据库数据,根据字段映射表对字段数据进行格式转换、合并、拆分、计算等操作,数据转换模型如图6所示,最后将标准化数据写入目标数据库中。
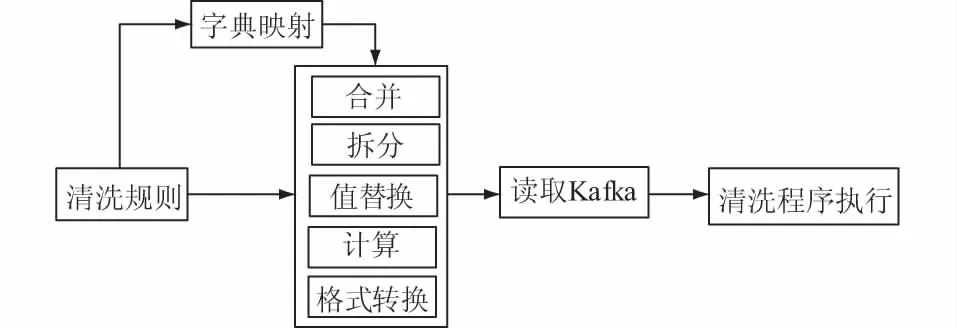
图6 数据转换模型
5 结 论
(1)通过数据分类、数据编码及表设计3个步骤的操作,对结构化数据进行标准化,可为其他数据库中存储结构化数据提供借鉴。
(2)利用JSON描述文档的关键信息,将带有文档属性的JSON连同文档一起存入数据库,可为非结构化数据标准化提供思路。
(3)统一接入和动态配置的数据接入和清洗方法,大大提高了数据清洗的兼容性,降低了数据清洗过程的复杂度,提高了堤防工程数据标准化过程的效率,可为其他多源数据快速而高效清洗提供参考。
