基于循环神经网络的歌曲旋律与人声分离系统设计与实现
2019-10-19董兴宁蔡宇航
董兴宁,蔡宇航
(江苏大学计算机科学与通信技术学院,镇江212013)
0 引言
随着科技的进步,多媒体技术的不断发展,人们对音乐的追求在不断地提高。然而,现今并没有一款专门的应用可以做到分离歌曲的人声与伴奏,这使得许多人在听歌时不能切换到伴奏状态进行哼唱和练习。此外,歌曲人声分离还可用于自动歌者识别、音乐标注、音乐的去噪与增强、基于内容的音乐检索等方面。因此,开发歌曲人声分离的软件势在必行。
对于实际歌曲中的复杂声音,由于其声源的复杂性和多样性,加之可能存在的背景噪声的干扰,使对于这一领域的研究还不够成熟。目前主流的人声分离算法大致可分为基于时频分解的分离技术和基于基音分解的分离技术。在时频分解领域,Vembu[1]用非负矩阵分解(Non-negative Matrix Factorization,NMF)来重组混合频谱中的不同音源,该方法能有效地进行简单的音乐分离,但当乐器数量增加时效果就会明显下降;在基音分解领域,Hsu[2]利用基音检测算法来检测人声部分,然后将人声的基音反复迭代以优化人声和伴奏的分离效果;但其学习模型需要足够多的数据进行先验分离,且精确的基音检测本身仍是一个未解决的问题。
1 技术路线及原理
图1 为本系统算法的总体设计路线:首先对原始音频进行预处理,然后提取人声特征,并放入搭建好的语音模型中训练学习,最后输出降噪处理后的人声流和乐声流。
以下就四个重要的技术环节做分开阐述。
1.1 预处理
由于原始歌曲存在格式、码率、噪声等问题,不能直接放入模型中训练,故须进行预处理,其中包含了预加重,分帧和加窗的操作。预加重(Pre-emphasis)是发
送端对输入信号高频分量的提升,其目的是补偿高频分量在传输过程中的过大衰减。由于语音信号具有短时平稳性,故把其分为一些短段进行处理,即分帧操作;同时为了避免丢失语音信号间的动态信息,在相邻帧之间须留有一段重叠区域,即帧移;然后逐帧乘以窗函数,以增加每帧左端和右端的连续性,避免出现吉布斯效应。本文所设置的帧长为30ms,帧移为15ms,所加的窗函数为汉明窗。
1.2 特征提取
预处理完成后,须提取语音信号的梅尔频率倒谱(Mel-scale Frequency Cepstral Coefficients,MFCC)特征,作为训练模型的输入。Mel 频率倒谱参数能很好地反映人耳听觉系统的非线性特性,并在特征提取过程中利用了歌唱者的音调特性,是用于人声特征提取最有效的特征之一。
MFCC 的提取分为以下几个步骤:快速傅里叶变换(Fast Fourier Transformation,FFT)、三角带通滤波,离散余弦变换(Discrete Cosine Transform,DCT)和动态差分参数提取。其中,FFT 是为了将语音信号从时域信息转换为更易处理的频域能量分布;三角带通滤波是为了对频谱进行平滑化,突显原语音的共振峰;DCT 是为了计算L 阶的Mel 参数,这里的L 阶是指MFCC 的系数阶数,本文选取为12;最后,分别提取该系数的一阶差分和二阶差分,得到整段音频的MFCC 特征。
(5)当数据到达入口隧道路由器ITR后,对其实行解封装,并将解封装后的数据发至主机X。至此,端到端的交互过程全部完成。
1.3 模型训练
本模型是一个由多层全连接组成的循环神经网络,该部分用于学习上文得到的人声特征,并通过多层的非线性结构不断优化学习,最后根据训练完成的隐层表达来重构人声和伴奏部分。具体而言,本模型的RNN 网络共分为3 层,除最后一层由tanh 函数激活外,其余各层均由relu 函数激活。同时选取了Adam优化器作为优化算法,使得模型能够自动调整学习率;最后,选用了二值时频掩蔽函数作为损失函数,其公式如下所示,其中代表模型在第t 帧的输出,y1t和y2t代表在t 时刻的纯净人声与伴奏声,∂是一个性能常量。式中第一、三个平方差旨在使分离后的人声、乐声与纯净的人声、乐声进一步接近;其余的平方差旨在使分离后的人声、乐声包含更少的混声。
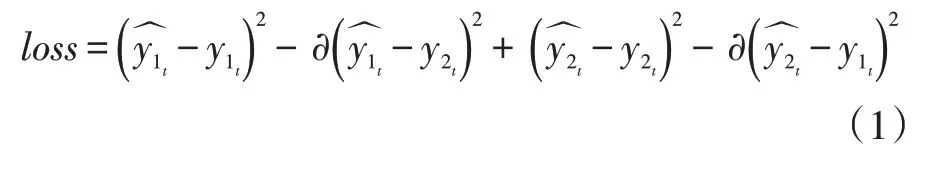
本模型首先输入混合信号x_mixed,藉由其内部进行非负矩阵分解,计算合成等操作初步得到2 个输出,分别对应着的人声流和乐声流,然后和纯净人声、乐声频段进行二值运算,将结果送入到Adam 算法优化器中进行调整,最后反馈给RNN 的网络进一步优化和学习。
1.4 后处理
为了进一步提高分离后的音频质量,须对得到的人声流和乐声流进行降噪处理,然后再做快速傅里叶逆变换(IFFT)得到相应的人声、乐声输出。本文选取了Berouti 的改进谱减法进行降噪处理,即用带噪信号的频谱减去噪声信号的频谱;其公式如下所示,其中PS( w )为输入的语音频谱,Pn( w )为估计的噪音频谱,D( w )为差值频谱,α 为相减因子。

由于相减后D( w )可能会出现负值,故须通过以下公式进行相应的调整,其中PS'( w )为最终确定的语音频谱,β 为频谱下限阈值参数,max()为求最大值函数。
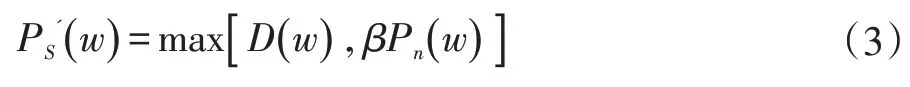
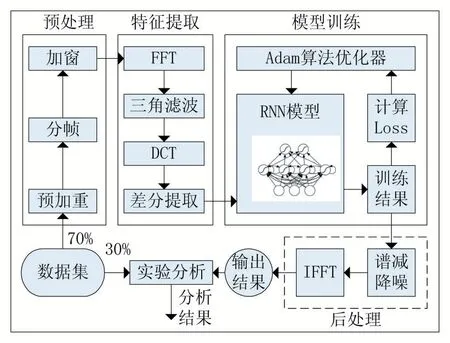
图1 系统算法流程图
2 实验测试与分析
2.1 数据集
本文采用了两种方法构造可供训练与测试的数据集。部分数据直接来源于MIR lab 的MIR-1K 数据集,该数据集由1000 余个歌曲片段构成,人声和伴奏声分别存放在不同的通道里,且每个歌曲均为16kHz 的采样率,均为wav 格式,片段长度由4~13s 不等;但该数
据集大多为偏抒情性质的歌曲,缺少重金属、摇滚类等背景嘈杂的音频;故剩余数据仿照MIR-1K 的制作方法,多选取上述所欠缺类型的音乐,采用人声清唱+伴奏独播的方式合成,并将其放在两个通道,手动分片后添加了标签。其目的是丰富总体数据集的多样性,提高整体模型的训练效果。
2.2 实验设置
根据上文第一节所介绍的技术路线,首先构造相应的RNN 模型;并将数据集分为训练集(70%)和测试集(30%),在模型训练完成后,输入测试集数据,得到待测试的人声组和乐声组输出。
首先进行有效性分析;随机抽取测试结果中的16组歌曲,将输出的人声流、乐声流和原歌曲在经过声道分离后的人声流、乐声流同时进行波形输出,比较分离前后的波形图。
其次进行性能对比评价分析;这里采用了平均主观意见分(Mean Opinion Score,MOS)作为评价分离后音频质量的主要指标。MOS 是目前最被广泛使用的语音评定方法,其评分的标准主要包括人声与伴奏的分离程度、信噪比、失真程度等;它的取值范围为[0,5],其结果从低到高共分为1~5 共5 个等级,1 为差,2 为一般,3 为正常,4 为好,5 为最好。在实际环境中人们交谈的MOS 值一般在2.0~3.0 之间,此时人耳很难辨别出差异;低于此阈值则信号衰落的较为明显,人耳可明确分辨。
本实验中,采用PESQ 算法估算歌曲的MOS 值。PESQ 是国际电信联盟(International Telecommunication Union,ITU)提出的一种语音质量客观评价算法,与MOS 评分的相关度达到了0.97。其算法具体步骤如图2 所示:首先将参照语音信号和待测语音信号调整至标准听觉电平,再进行输入滤波,并将两个信号的时间对齐,然后进行听觉转换,并将转换之后的输入和输出信号差值通过认知模型再处理,计算出最终的PESQ 分值,即PESQMOS 值。

图2 PESQ算法流程图

计算最后PESQ 得分的公式如下所示,其中dsym为对称干扰,dasym为非对称干扰;PESQMOS 值的最终范围为[-0.5,4.5]:
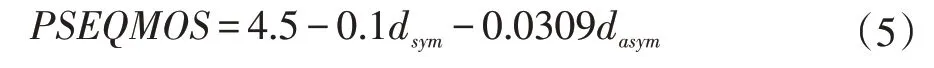
所有的实验都在Windows 10 操作系统下完成,开发语言为Python 3.6.0,深度学习框架为TensorFlow-GPU 1.10.0,编译器为MSVC 2015 update 3;批量训练的数量设置为96,总迭代次数设置为80000;而再约50000 次迭代后loss 值趋于稳定,表明训练完成。
2.3 性能评估
有效性分析:随机抽取测试结果中的部分歌曲,以abjones_2.wav 歌曲为例,其分离前后的波形图如图3所示。对比分离前后的乐声波形(子图1 和子图2)与人声波形(子图3 与子图4),可以发现分离后的人声流和乐声流与原始音频的波形几乎一致,且在背景音乐中也没有残留的人声基音及其谐波分量,反映出该算法能有效地实现人声与乐声的分离。
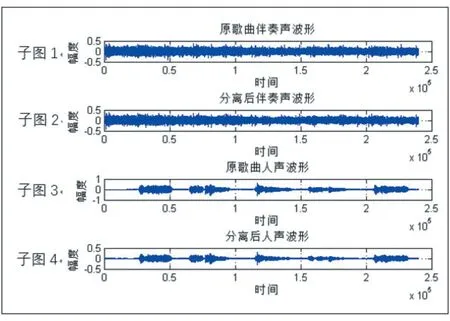
图3 abjones_2.wav原歌曲与分离后歌曲的波形对比图
性能对比评价分析:随机抽取测试结果中的10 组歌曲,按上文实验设置中的方法计算其PESQMOS 值,其中参照方法如表1 所示,所得结果如表2 所示。

表1 参照方法
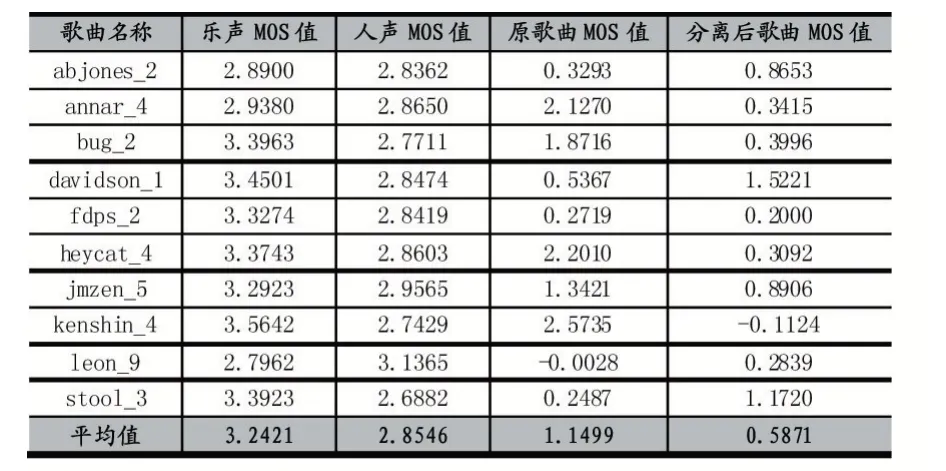
表2 10 组歌曲的PESQMOS 值
由表2 可知,对比原歌曲,分离后的人声流和乐声流的PESQMOS 评分均在2.6-3.6 分之间,平均得分约为3.0 分左右,即所谓的“正常”等级。在该等级下,分离后的信号失真程度较低,人耳不易辨别出差异,其效果近似于全速率的语音编码无线通信的话音质量(MOS 值一般为3.1-3.2),可以达到实际的应用需求。同时注意到,对比原歌曲MOS 值1.15 分的均分,本算法分离后音频间的MOS 值更低,为0.59 分,这说明了本算法分离后的人声与乐声之间无关性更强,冗杂的混音更小,一定程度上体现了本算法的优越性。
3 系统设计
本文以网站的形式将上述成果落地,系统的整体设计如图4 所示。
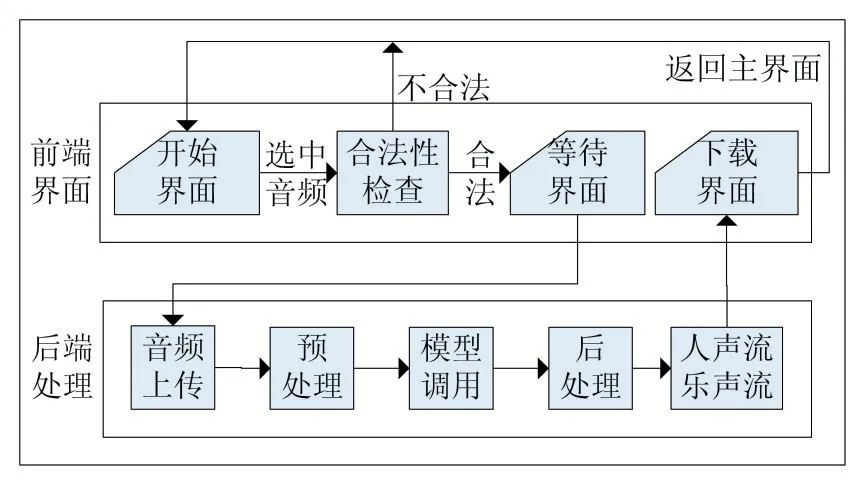
图4 系统设计实现图
3.1 前端设计
在网站主页面中植入了一个浮动框架(iframe),作为提示用户输入歌曲位置、进行下载操作的交互窗口。其页面的书写主要为HTML 语言,并使用了CSS语言进行美化,使用了JavaScript 脚本语言处理部分控件和事件。
3.2 后端设计
本文采用了Python Web 的Django 框架作为支持后台脚本运行的语言。Django 是一个开放源代码的Web 应用框架,采用了MVC 的框架模式,并拥有多个组件及许多功能强大的第三方插件,这使得Django 具有很强的可扩展性。
本文采用了Django 框架中的表单机制进行前后端交互,通过统一资源定位符(Uniform Resource Locator,URL)进行前端控件名称和后端处理函数的绑定,以此实现文件上传、文件处理、文件下载、页面转移的功能。本系统还引入了Session 机制,其目的是为了防止有多个用户在使用网页时,所可能产生的数据冗杂或混乱的问题,以提高网站的并发性和健壮性。
3.3 系统测试
考虑到实际应用中用户上传歌曲的复杂性,本文选择了多种类型的音乐进行了验证和测试,包括中文乐曲(曲1~2)、现场录制乐曲(曲3)、男女合唱乐曲(曲4)、英文乐曲(曲5),其结果如表3 所示;由于各歌曲清唱人声的获取难度远大于伴奏资源,本文只将分离后的歌曲伴奏与原声伴奏进行了对比,并计算其MOS值;各歌曲及相应的伴奏音频均来源于正版授权音乐。

表3 5 首歌曲的分离效果评估
由表3 可知,对于时长在5 分钟(300 秒)内的歌曲,本系统的处理时间一般小于80 秒,处理速度较快;同时,本系统分离后的人声与乐声音频大小相比原歌曲均有超过半数的下降,这有效地节省了内存;此外,分离后的伴奏声与原歌曲的MOS 评分均在2.9 分左右,与实验值接近,说明其分离失真程度并不影响实际使用体验。这些都说明本系统能较好地完成歌曲人声与伴奏分离的任务。
4 结语
本文设计并实现了一个基于循环神经网络的歌曲旋律与人声分离系统,通过MFCC 提取特征参数,利用RNN 进行建模学习,并进行实验验证了该算法的有效性,最终迁移实现了相应的Web 端系统,完成了将原歌曲分成人声流和乐声流的目标。该系统操作简单,分离的乐曲较清晰、混音小,且具有较高的用户友好性;但本系统所得到的输出音频质量仍不是最好,且在线处理的耗时较长,未来可通过进一步调整参数以优化训练模型,及裁剪神经网络以缩短后端处理时间,从而提高整体系统的处理效果和吞吐速度。
