基于文本挖掘的输变电设备疑似家族性缺陷预警分析
2019-10-15杨维张弦程飞飞
杨维 张弦 程飞飞


摘要:目前,针对输变电设备家族性缺陷的认定主要通过专业人员通过对设备进行试验、解体分析,周期较长。本文通过收集设备缺陷情况,采用大数据分析技术,提取设备缺陷信息特征,并通过计算设备缺陷信息相似性,利用Kohonen神经网络聚类算法实现对设备缺陷信息类别打标签,基于同类厂家设备缺陷信息进行分组统计分析、预警,实现输变电设备疑似家族性缺陷的自动辨识、预警。
关键词:输变电设备;文本分析;家族性缺陷
0引言
输变电设备家族性缺陷来源主要包括:国家电网公司(以下称“公司”)下达的有关设备的家族事故通报、公司下达的设备家族性缺陷、各省市公司提供的家族性缺陷等。针对家族性缺陷的认定往往基于复杂的机理,目前电力变压器家族性缺陷识别主要有专家识别、聚类识别等方法,周期较长,严重依赖人工投入,效率低下且缺陷识别遗漏,不利于家族性缺陷的认定及处理。[2-3]
本文阐述的输变电设备疑似家族性缺陷分析模型,通过收集设备缺陷信息,采用大数据分析算法技术,对海量缺陷描述分词处理,提取设备重要缺陷特征,同时,基于凝聚Kohonen神经网络聚类算法,实现输变电设备同类型缺陷标识,进一步利用多维分析为设备家族缺陷辨识、认定提供辅助依据。
1输变电设备疑似家族性缺陷定义
不同电压等级的变压器由于对设备材料、工艺等要求不同, 通常电压等级高的设备, 技术要求越高,故障率较低。实际工程中,一般通过设备生产厂家、设备型号、生产批次等因素与故障的关联性,反映其家族性缺陷。运行经验表明,设备生产厂家、型号、批次等因素与家族性缺陷相关主要有以下特点: ① 同厂家、同型号或同批次产品故障率高于正常设备; ② 同厂家、同型号或同批次产品故障分布较为平均,不集中于少数几台设备[1]。
2模型输入
梳理输变电设备疑似家族性缺陷分析模型所需数据,包括设备台账设备缺陷、生产厂家、设备分类等信息,数据来源系统为PMS2.0系统,数据需求表如表1所示。同时,对主变压器台账表、设备缺陷表、生产厂家表、设备分类表等涉及的设备名称、类型、缺陷部位等字段进行梳理,梳理各属性间的关联关系。
3模型设计
3.1数据准备
针对模型输入环节梳理的涉及到的各表之前的关联关系,按照pms2.0系统数据库业务表逻辑模型进行关联合并,形成缺陷分析模型数据分析宽表,作为输变电设备疑似家族性缺陷分析模型的输入。
3.2数据清洗
数据清洗是针对梳理形成的缺陷分析宽表中涉及到的含有噪声的数据,通过采用标准化、规范化、降维等数据清理的方式,提升数据分析质量。
数值化:由于设备原始数据形式各自不同,需对其进行标准化操作,经典的处理方式:对字符串取值,按照ANSI码值求和得到字符串的值,并映射到一个区间。
标准化:在数据分析的时候,计算相关性或者方差等相关的指标时,有必要对整体数据进行归一化处理,映射到一个指定的数值区间。较常用一个做法是:min-max标准化。
完整性:对缺失的数据主要有添补或删除等方法,如果数据量较大,而数据缺失量较少,对于缺失数据,删除其所在行即可;但如果缺失值所占样本数比例较高,则采用数据填充的方式来添补缺失数据。
3.3模型构建
3.3.1 分析方法介绍
3.3.1.1 文本挖掘算法
文本挖掘是指对文本的表示及其特征项的选取,它把从文本中抽取出的特征词进行量化来表示文本信息。文本挖掘算法涉及分析和停用词定义、词频因子TF、逆文档频率因子(IDF)、TF*IDF框架、特征词提取以及文本相似度计算等技术。
- 分析和停用词
每篇文档的主体内容可以由最能代表它内容的特征词表示,但是对于中文文档来说,首先需要把句子分成一个个单词。
- 词频因子TF
TF计算因子代表了词频,即一个单词在文档中出现的次数,一般来说, Tf值越大,越能代表文档所反映的内容,那么应该给于这个单词更大的权值。
- 逆文档频率因子(IDF)
IDF的计算公式为:IDFk=log(N/nk),其中N代表文档集合(包含不相關和相关文档的总和)中总共有多少个文档,而nk代表特征单词k在其中多少个文档中出现过,即文档频率。由公式可知,文档频率nk越高,其IDF值越小,即越多的文档包含某个单词,那么其IDF权值越小。IDF反映了一个特征词在整个文档集合中的分布情况,特征词出现在其中的文档数目越多,IDF值越低。
- TF*IDF框架
TF*IDF框架是结合了词频因子和逆文档频率因子的计算框架,一般是将两者相乘作为特征权值,特征权值越大,则越可能是好的关键词,即:Weight(word) = TF * IDF。可以选取权重值最大的几个单词(比如10个或20个)作为特征词,用由这几个特征词的权重组成的向量来表示这篇文档。
3.3.1.2 Kohonen神经网络聚类算法
Kohonen神经网络是自组织竞争型神经网络的一种,该网络通过自组织特征映射调整网络权值,使神经网络收敛于一种表示形态,在这一形态中一个神经元只对某种输入模式特别匹配或特别敏感。
Kohonen神经网络算法工作机理为:网络学习过程中,当样本输入网络时,竞争层上的神经元计算输入样本与竞争层神经元权值之间的欧几里德距离,距离最小的神经元为获胜神经元。调整获胜神经元和相邻神经元权值,使获得神经元及周边权值靠近该输入样本。通过反复训练,最终各神经元的连接权值具有一定的分布,该分布把数据之间的相似性组织到代表各类的神经元上,使同类神经元具有相近的权系数,不同类的神经元权系数差别明显。
3.3.2缺陷分析模型
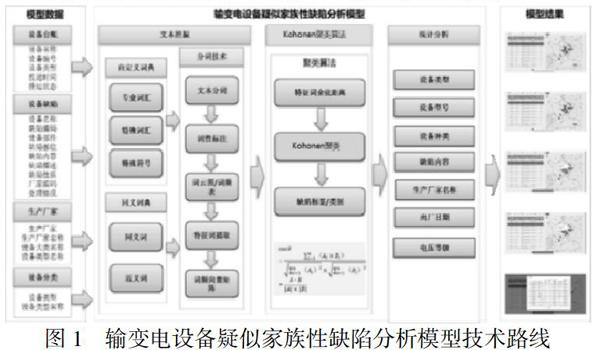
输变电设备疑似家族性缺陷分析模型主要包括文本挖掘、Kohonen神经网络聚类算法和多维统计分析三部分内容,如图1所示。
由于变压器涉及的零部件较多,其出现家族性缺陷的概率较高,是重点监测的对象本文以输变电设备中的主变压器设备为例,阐述输变电设备疑似家族性缺陷分析模型的构建过程。
1)文本挖掘
受各运维单位、运维班组人员地域、文化教育程度、用语习惯等限制,不同的班组人员在输变电设备缺陷上报的过程中,针对同一缺陷现象,用于描述缺陷内容的文字存在较大差异。为了能够从“缺陷内容”中更好提取设备缺陷特征词,根据设备“缺陷内容”信息,进行运检专业词汇和停用词定义,形成自定义词典,同时,对“缺陷内容”进行同义词定义、合并,完成对“缺陷内容”信息的预处理。
①自定义词典
按照自定期词典形成规则,形成:“主变压器”、“ 就地”、“纳河南线”、“硅胶”、“把手”等合计3500余例自定义词汇,构成自定义词词典;同时,定义与变压器设备本体缺陷无关的相关词汇,在文本分词的过程中摒弃该部分词汇,例如:“的”、“与”、“三星变电站”等词汇,共构建4300余个停用词,构成变压器设备缺陷分析停用词词典。
②同义词词库
针对不同运维人员在变压器设备缺陷上报过程中的针对同一设备缺陷的描述用词不一致等问题,依据“缺陷内容”信息进行同义词定义、合并,解决缺陷信息录入过程中缺陷内容描述不规范造成的数据质量问题,例如:将 “不能复归”、“复归不了”等词汇统一定义为“不能复归”,共形成70余组同义词库
③文本分词
基于已经构建的自定义词典和同义词词典,进行文本分词,利用R分析工具加载jieba分词包,并对分词词汇进行词性标注(名词/动词/副词),并对自定义词库、同义词词库、停用词词库进行不断完善,以提升文本分词的效果。在完成文本分词后,对进行词频统计,形成变压器设备缺陷信息词云图。
④文本特征词提取
根据分词结果形成“缺陷内容”词云图/词频表,并根据词频表计算具体词频(TF[1])和逆文档词频(IDF[2]),并利用![]() 衡量词的重要性,提取特征词,计算除停用词外所有分词的权重,提取权重最大的若干词作为特征词,由特征词权重组成的组成的向量为特征词向量矩阵。
衡量词的重要性,提取特征词,计算除停用词外所有分词的权重,提取权重最大的若干词作为特征词,由特征词权重组成的组成的向量为特征词向量矩阵。
基于变压器文本特征词提取公式,提取变压器设备缺陷特征词,并针对特征词形成特征词向量矩阵,并将词频向量矩阵转化为数据框格式。
④文本相似度计算
基于文本挖掘生成的特征词生成词频向量矩阵,计算各词向量的余弦值,利用词向量的余弦值进行Kohonen神经网络聚类。
如公式(3)所列,A、B分别代表两个缺陷特征词的词频向量,![]() 值越接近1,表明夹角越接近0度,也就是两个向量越相似。结合输变电设备疑似家族性缺陷分析模型,通过对设备缺陷的缺陷内容提取的设备缺陷特征词进行相似度计算,并对其按照相似性的大小进行排序。
值越接近1,表明夹角越接近0度,也就是两个向量越相似。结合输变电设备疑似家族性缺陷分析模型,通过对设备缺陷的缺陷内容提取的设备缺陷特征词进行相似度计算,并对其按照相似性的大小进行排序。
3)Kohonen神经网络算法聚类分析
在实现输变电设备缺陷内容相似度计算的基础上,结合其向量矩阵,利用Kohonen神经网络算法进行无监督的聚类分析,在用R实现Kohonen神经网络聚类分析的代码中,在算法参数中重点输入聚类个数和算法迭代的次数,对设备缺陷类别进行打标签和分类,从Kohonen神经网络算法的评价系数中看轮廓系数为0.701,DUMN系数为0.5817,从聚类效果的评价参数来看,聚类效果良好。同时,结合专家经验法,算法的蕨类效果良好,能够满足输变电设备疑似家族性缺陷的预警分析应用。
3)统计分析
基于缺陷分析模型实现对每一条设备缺陷进行标识,最后按照家族性缺陷的定义,通过对缺陷设备的生产厂家名称、设备类型、设备种类、设备型号、具体部件、部件类型、缺陷部位等信息进行分组统计(将同生产厂家、同设备类型、同设备种类、同设备型号、同部件类型、同缺陷部位数量>=5的设备缺陷,定义为输变电设备疑似家族性缺陷),实现对输变电设备疑似家族性缺陷的自动辨识。
4应用实例
结合某网省公司pms2.0设备缺陷信息,利用文中提到的基于文本挖掘技术的输变电设备疑似家族性缺陷分析模型,通过对历史缺陷数据的分析挖掘,找出具有家族性缺陷嫌疑的设备,如常州变压器厂1987年出厂的多台SFSZ7-31500/110变压器均冷却器系统缺陷,应加强对该型号在役设备的巡视巡检,并缩短检修周期或进行技术改造。同时,将输变电设备疑似家族性缺陷分析模型可以应用于业务系统,通过在Gis地图上展示已发现疑似输变电设备的其他单位的应用,并通过对设备信息进行钻取,以便了解该设备缺陷信息。
5结语
本文结合输变电设备家族性缺陷的定义,以pms2.0系统相关的设备缺陷等信息為输入,实现了输变电设备疑似家族性缺陷分析模型的自动辨识,本文中仅以主变压器设备为例,详细的阐述了输变电设备疑似家族性缺陷分析模型的构建原理和实现过程,同理,输变电设备疑似家族性缺陷分析模型能够适用于断路器、隔离开关、互感器等输变电设备的疑似家族性缺陷分析。基于文本挖掘的输变电设备疑似家族性的应用,能够为输变电设备家族性缺陷的认定提供了支撑,能够为运维检修部门开展运维检修工作提供指导,保障了电网的稳定运行。
参考文献(References) :
[1] 朱海冰,张齐韬,郭雅娟,吴奕,郝思鹏.基于数据挖掘的电力变压器家族性缺陷预警[J].实验室研究与探索.2016,35(6):37-41.
[2] 李新叶,李新芳.基于改进层次聚类的同家族变压器状态变化规律分析[J].电力系统保护与控制,2011,39( 19) : 104-109.
[3] 饶威,王凤云,丁坚勇.基于改进层次聚类法的电力设备家族缺陷评估[J].浙江电力,2013( 3) : 9-13.
[4] 朱振玉,张海宁,马甲军,等.基于粗糙集数据挖掘的瓦斯突出预测模型[J].实验室研究与探索,2009,28( 6) : 41-43.
[5] 黄映恒,童张法,廖森,等.工艺因素对固相反应制备 LiMPO4的影响[J].实验室研究与探索,2010,29( 9) : 11-18.
注释
[1] TF计算方法参见公式(1);
[2] IDF计算方法参见公式(2)。
