大数据时代下慢性病管理的前景
2019-10-14
(复旦大学附属肿瘤医院 上海 200032 )
随着云时代的到来,大数据也吸引了越来越多的关注,在时下商界的流行语中,很难找出一个比“大数据”更吸引眼球的“百搭款”术语了。大数据的颠覆和创新作用几乎在每个行业都有体现,医疗行业也不例外。大数据正在帮助我们走向精准医学,我们可以提前了解卫生保健中的传统指标。然而,和其他行业相比,大数据在医疗行业的应用显得寥寥无几,在慢性病上尤为显著。利用“大数据+慢病管理”,不仅可以对慢病进行预警,还能为患者提供全过程的慢病管理服务,有利于破解社区慢病管理的困境。
一、慢性病目前的严峻形势
近年来,一方面数据仓库技术以及海量存储设备的快速发展使得收集海量数 据的能力得到质的提升,预示着大数据的时代已经到来;另一方面,随着各大医院信息化建设进程的不断推进,医院中的各生产系统如 HIS、LIS、EMR等已经积累了规模庞大 的临床数据。公共的医疗资源服务日渐紧张,如何利用好收集存储的海量数据,成为数据手机存储价值的重要标志。在此背景下,面向医疗大数据的数据分析与 挖掘技术也应运而生,并得到了快速的发展,智能医疗决策系统也因此应运而生。这种数据包含了许多隐藏的知识等待被挖掘,对于辅助诊疗、提升临床医疗质量 具有很大的价值。
二、慢性病管理的大数据时代
随着信息化的全面建设,数据呈现爆炸式增长,当传统的数据分析能力及统计学分析方法跟不上数据的增长速度时,便产生了“大数据”的概念。在慢病管理领域,由于居民健康卡的普及各种可穿戴设备的开发以及区域医疗信息化的持续推进,慢病患者的健康数据采集和共享开始成为可能口,如厦门市卫生局建立的基于健康档案的区域信息平台。这些数据不仅包括常规诊疗过程中的医疗数据如电子病历系统,也包括各种可穿戴设备及健康 APP 等上传的个人健康数据以及一些临床研究、生物信息工程等,几乎涵盖了患者整个的健康数据链。大数据通过对这些海量数据进行融合、分析与挖掘及可视化,可以得到准确的预测、推论和高效的决策支持避),为慢病防治流程中的各方面提供服务。
三、国内外研究现状
基于当前高速发展的数据处理技术,以及硬件设备的迅速更新换代,使得我们越来越有条件收集数据量巨大的数据,做好数据存储工作。面临存储的海量数 据,怎么使用这些数据成为了医疗大数据领域专家学者探索的热点课题。现有的工作主要集中在使用医疗数据对患者进行聚类和分类研究[1-3]、疾病 复发与基本指标之间的关联分析[4-6]以及一些中西药常用的药对组合,用药规律等的发现。这对这些数据可以发现,目前的主要研究工作从以下几个方面展开:
1.针对高风险人群的难以预测的问题,构建患者的分类模型,以及分析一 些影响发病的相关因素。
2.针对疾病之间可能存在的关系的关联分析。
3.发现发病规律,并应于辅助诊断,生成决策树 经过查阅相关资料和调研分析,得出目前主要的医疗大数据分析研究的方向和一些难点。
虽然目前也有很多的对医疗大数据分析的探索,但 很多只是局限在实验室研究,难有真正的应用价值。要应用首选是分析的准确性,也需要根据医疗数据的特点对大数据分析算法进行改进,或者提出针对医疗数据 和具体分析问题的算法。
在多维分析方面,基于 OLAP 技术的医疗信息多维数据集设计与分析[8]一文中以医疗信息系统仓库为基础构建 OLAP 系统,运用多维分析方法和 MDX 查询设计实现多维数据分析。在多维分析应用时,基于 SAP BW 的商务智能分析与 应用[9]文中提到使用基于 SAP BW(SAP 商务智能数据仓库)来进行分析,同时 使用 SAP BO(BI 系统中业务对象)套件,对分析结果以及数据展现的形式进 行提升。总的来说,多维分析一般使用 OLAP[10-12]技术,然后配合一些可视化业 务层展现层如 SAP BO,使分析结果更加直观、简洁。在时序挖掘方面,时间序列数据挖掘在生物医学中的应用研究[13]利用已知的时间序列、相关的理论和技术来对未知的时间序列做出预测。使用通配符的方式,提供灵活的间隔约束,从而特定的从序列中挖掘那些有研究价值的隐藏的模式。基于临床数据的分析会有更好的现实意义,突破数据本身的局限性。在多维分析时可以更好的结合现实应用的场景,增加应用价值。使用时序挖掘分析时可以更好的针对某个特征进行细化的分析,从而发现数据背后深层次的信息,更好的为慢性病管理做出有效的指引。
四、数据挖掘技术的深层解析
(一)OLAP与数据挖掘
大数据常常是由结构复杂、数据量巨大、类型众多的数据构成的数据集合。为了发掘这些数据背后隐藏的知识,常有多种方法,本节介绍 OLAP 技术和数据挖掘技术。
1.OLAP 技术
分析决策人员在分析决策过程中,往往都需要通过多角度、多层次的方式来观察某些属性之间的关系。如医生想要知道今年年龄在 60-70 岁区间内,上海市各个区的男女慢性病患者的分布情况时,这个时候就要综合考虑临床诊断情况、地区、性别和年龄等多个维度的信息,这些供分析决策使用的数据都是多维数据。多维数据被具体的看成是一个立方体,包括维度信息(Dimension)和度量值 (Measure)。维度就是观察数据的角度。度量值是指衡量数据的指标值。如慢性病患者基本信息,就包括性别、年龄、地区等维度,也可以从各年龄段占比,性别占比等度量方式具体观察。因此,在多维分析时,对事实表、维度的层次、维度的成员、度量值等的概念的理解与掌握非常重要。
(1)事实表(Fact Table):事实表的设计一般有两种形式,一种是星型结构 (Star-Schema),另一种是雪花结构(Snow-Flake Schema)。星型结构是由一个 事实表(如临床诊断事实表)同多个维度表(年龄、性别、地区等)产生外键关 联而雪花结构是在星型结构的基础上有一些维度表需要有类别属性的具体划分,比如在地区维度上,可以有省、市、区、街道等不同层次,它实际上是星型结构 的拓展。
(2)维度(Dimension):是人们分析观察问题的角度。通过把实体上的一些 重要属性如(年龄、性别、地区等)定义成维,可以使用户对不同维属性上的数 据进行比较分析。
(3)维的层次(Level):针对某个特定的维度,可以有不同的细节程度来对 它进行各个层面上的详细描述。如时间维度上的年、季度、月份等信息。
(4)维的成员:维度的某一个具体的取值,是一个具体的描述。如地区维中的上海、徐汇区等。
(5)度量(Measure):它也叫度量指标,是多维度量数组中的一组数值。如 2015 年 1 月**医院确诊糖尿病患者的人次是 2905 次。OLAP 是一种多维分析技术,有多种的操作如钻取、切片和切块以及旋转等。
2.数据挖掘的概念
数据挖掘(Data Mining,DM)是从海量数据中获取知识的过程。最早是在它最早是在 1989 年举行的第 11 届美国人工智能协会(AmericanAssociation for Artificial Intelligence,AAAI)学术会议上提出的。首先,数据挖掘中的数据源必须是真实的、大量的、含噪声的,可以是关系数据库中的结构化数据,也可以是文本、图片等半结构化的数据。其次,数据挖掘是一种多学科集成的技术,是人工智能和数据库技术领域的热点课题。最后,针对具体应用,以大量真实的业务数据为基础,采用适当算法,数据转换和建模,从而为决策者提 供决策支持。数据挖掘的主要功能表 2-1:

表 2-1 数据挖掘的功能
针对分析问题的不同,选用的分析技术也常常不一样,最常用数据挖掘技术有关联规则分析、分类、聚类、回归分析、神经网络等。数据挖掘的一个流程图如下:

图2-1 数据挖掘流程
上图2-1给出了一个数据挖掘分析的基本流程,主要有三块,确定分析目标、数据挖掘和结果分析。确定目标是根据需求明确要做什么,然后就是根据目标获取数据并搭建模型,选择相应的挖掘技术,最后就是对挖掘的结果进行分析,不断的修正实验参数,并分析实验结果,从而获得一个稳定有效、准确而有意义的 模型,使得决策者在分析决策时提供建议。
(二)时序挖掘
频繁模式的发现始于1993年Agrawal等学者提出的关联规则的发现研究,也一直是数据挖掘分析领域中的一个重要的研究课题。自从 Agrawal 等学者提出 了关联规则挖掘问题以来,诸多的学者对关联规则挖掘课题进行了大量的研究,得出了很多高效的算法,然而大多数方法都未考虑时间因素的影响。但在现实世界中,时间是数据本身固有的因素,在数据中常常会发现时序语义问题。
1.时间规准
时序数据的出现使得有必要在数据挖掘中 考虑时间因素,在现实中,附加 上某种时序约束的规则将可以更好地描述客观现实情况,因而也会更有价值,称 这样的规则为时序关联规则。时序关联规则挖掘研究[18]一文中提出了多时间粒度的时间规准,如年、月、日等多粒度时间维度表示的方法。非同步多时间序列 中频繁模式的发现算法一文中,提出了针对多个序列之间时间不同步的问题,利用线性化分段表示和矢量形态聚类实现时间序列的特征分割与符号化转换的 思想。另外在时序挖掘时,常常是对时间序列的某一个子序列进行挖掘,在时间序列相似性问题中滑动窗口的确定一文中,提出了滑动窗口在时间序列相似性降维技术的应用。
时序表达,在做时序挖掘时,常常需要先对事件做时序表达,构建事件序列。在构建事件序列时,就需要使用事件之间的相似性,进行时间规整,最常用的时间规整有两种,欧氏距离和动态时间规整两种方式。
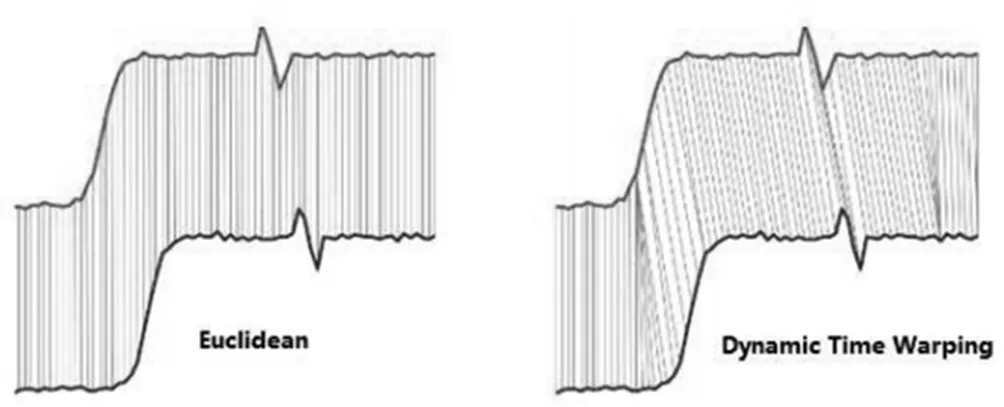
图2-2 时序规整
两种距离计算的方式稍有不同,虽然 DTW 计算的相似性有更好的优势,但在实际使用时,却需要更多的时间,从而降低算法的效率,相比之下欧式距离有更好的算法效率。
2.关联分析
关联规则反映了一个变量与其他变量之间的相互依存性和关联性;其中,关联关系指的是在两个或者两个以上的变量取值相互之间所存在着的某种规律性 的关系。关联规则挖掘则是为了发现变量之间这种依存性和关联性的规则,并利用令人感兴趣的规则来预测多个变量之间潜在的关联或是通过其他变量来预测 一个变量的存在。
在医疗数据中,临床诊断数据就有这样特点。有了诊断事件序列,就可以对序列中的事件做关联分析,进行频繁模式的挖掘。关联分析实质是从大量数据中找到出现条件概率较高的模式,理论基础主要是支持度和置信度,理论上,支持度和置信度越高则表示模式出现的概率越高关联规则的可信度也越高。
五、小结
目前的慢病管理模式已经难以满足我国慢病管理的需要,大数据分析在对慢病高危患者。对慢病患者进行个体化治疗及随访,不仅能有效降低慢病发病率,减少医疗费用,也有利于改善疾病的预后,提高患者的生活质量,适应了新医改的发展方向,有利于解决医疗卫生资源分布不均的情况。大数据在慢病管理中的应用和发展无疑将成为未来慢病管理的新方向,为慢病患者带来新的前景和希望。
