超密集异构网中的Q学习资源调度算法
2019-09-23尼俊红史上乐
尼俊红,史上乐
(华北电力大学 电子与通信工程系,河北 保定 071003)
0 引 言
超密集异构网络被认为是提高系统吞吐量的有效方法[1]。在超密集网络中,增加本地频谱的重用可以应对覆盖和容量增长的需求[2]。但所有基站(Base Station,BS)同时使用相同的频率资源,小区间干扰(Inter-cell Interference,ICI)会变得很强,这将会导致信号干扰噪声比(Signal to Interference plus Noise Ratio,SINR)的降低,从而限制系统的整体吞吐量[3]。因此,超密集部署中的干扰管理尤为重要。
现阶段对小区间干扰管理和增强学习算法应用的研究已取得一些成果。文献[4]研究基于Q 学习的毫微微蜂窝系统的功率控制,提高了边缘用户的服务质量。文献[5]根据用户密度和干扰水平进行区域划分,针对不同的区域进行资源分配。文献[6]提出一种分布式Q 学习算法,但由于毫微微蜂窝基站之间没有信息交换,影响了调度速度。文献[7]提出基于多主体的Q 学习方案,来提高小区边缘用户的吞吐量。文献[8]提出一种分布式Q 学习算法在采用不同技术的接入节点之间进行卸载和接入。文献[9]利用Q 学习在不同场景下进行资源分配,有效提高吞吐量,但由于收敛时间过长,在一定程度上影响了用户通信。文献[10]根据干扰对小小区进行分簇和资源正交化处理,但通过这样的方式进行干扰协调是以降低整个系统的频谱利用率为代价的。
现有资源分配方面的研究多以小小区用户为研究对象,研究如何对每个用户进行合理的资源分配。本文主要工作体现在以下方面:
1)将小基站进行分簇,簇内用户只接入簇内小小区基站;
2)将用户变动作为触发条件,联合考虑了用户接入和资源优化问题,以系统吞吐量和能量效率为优化目标,利用Q 学习方法来学习簇间资源调度和簇内小小区资源分配的最佳策略;
3)通过阈值因子和时间系数加快Q 表的收敛速度。
1 系统模型
本文考虑超密集异构网络场景,研究区域中心有一个宏基站,其覆盖范围内均匀分布着H个小小区基站。设蜂窝用户设备(Cellular User Equipment,CUE)的数量为M,小小区用户设备(Small-cell User Equipment,SUE)的数量为N,这些用户随机分布在系统覆盖范围内。本文考虑超密集异构网络的下行链路传输,由超密集网络的定义可知[11],H>N。为了简化接入过程,每个小小区只接入一个用户,每个用户选择簇内参考信号接收功率(Reference Signal Receiving Power,RSRP)最高的小区作为其服务小区,若该小小区基站已经存在服务用户,则选择簇内其余小小区中参考信号接收功率最高的小小区进行接入。
假设宏小区和小小区共享相同的信道环境,所有CUE 之间采用相互正交的频谱资源,则存在两种类型的干扰,即跨层干扰(宏小区和小小区之间)和同层干扰(小小区之间)。 就UDN 而言,同层干扰可能非常强,这极大地限制了小小区的容量。如何有效地将资源分配给H个小小区将是需要解决的主要问题。
本文的优化目标是通过寻找最佳的资源分配策略,在保持宏小区吞吐量的基础上最大化小小区吞吐量。假设系统有NRB个资源块(Resource Block,RB),定义Tp为系统的总吞吐量,即:

式中,TUCE和TSUE分别表示系统内所有 CUE 和 SUE 的吞吐量之和。用T mCUE表示第m个宏基站用户单位带宽的容量:
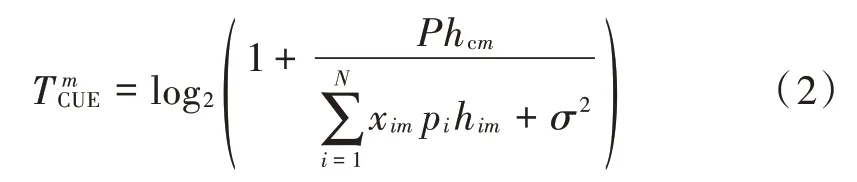
式中:xim为资源占用指示变量,为 1 时表示第i个 SUE 占用与第m个CUE 相同的资源,为0 时表示不占用;P为宏基站的发射功率;pi为与第i个SUE 关联的小小区基站的发射功率;σ2为高斯白噪声;hcm为宏基站c 到第m个宏基站用户的信道增益;him为第i个小小区用户关联的小基站到第m个CUE 的信道增益。综上可得系统内所有CUE 的吞吐量TCUE为:

式中Bwi为第i个CUE 获得的带宽。类似地,系统内所有SUE 的吞吐量TSUE为:
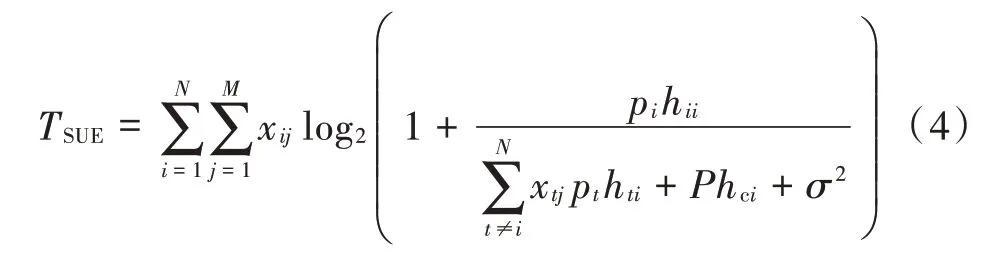
资源分配的最终优化目标即找到合适的资源占用指示变量矩阵X来最大化系统的总吞吐量Tp。其中,限制条件为:
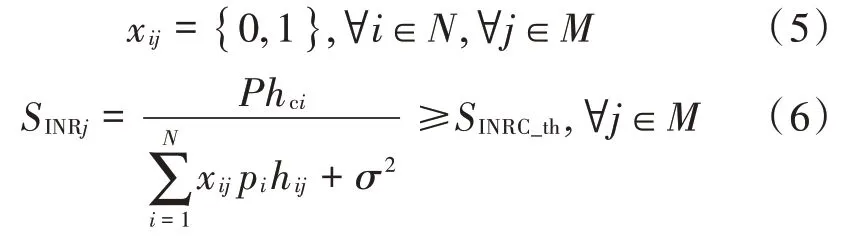
即:资源占用指示变量只等于0 或1;系统内宏基站的信噪比不低于预先设定的蜂窝阈值下限SINRC_th。
2 基于Q学习的资源调度算法
引入Q 学习(Q-learning,QL)算法,以获得最佳资源调度和分配策略。
2.1 Q学习在资源分配下的参数
Q 学习是增强学习的典型方法,已被证明可以收敛[12]。Q 学习的主体称为代理,Q 学习代理必须具有以下参数:
S(S={s1,s2,…})是一组状态,A(A={a1,a2,…})是一组动作。本文中,在时刻t,对于某个SUE,状态设定为st=(r,k,w)。对所有小小区基站按照位置进行均匀分簇,r表示用户的位置处于哪一个小小区c簇内;k为用户接入的小小区基站;w为此基站当前资源的占用状态。将小小区可复用的连续资源块依次分为W组,小小区用户每次只占用一组,w=1,2,…,W,表示占用的资源组编号。
在状态s下,动作集被定义为表示在状态s时,小基站k的资源分配行为,即重新分配哪一组资源块给用户,动作集的大小由可复用的资源组数量决定。
γ(0<γ<1)是对学习过程有影响的折扣因子;α(0<α<1)是学习率,它定义了新学习知识对以前学习知识的影响。本文中,折扣因子和学习率的值经过超参数优化分别设置为0.87 和0.56。
Q(s,a)函数是Q(s,a)表,它存储状态-动作对及其值。估计在状态s下选择动作a的预期奖励,并根据奖励更新Q(s,a)表的值。
对于某个状态s,根据固定策略选择动作a,如下:
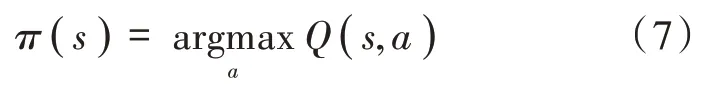
因此,Q 学习的最终目标是获得最优策略π(s),为此,这里需要获得最佳Q(s,a)表。对于在特定状态下采取的每个动作,代理与环境交互并估计所选动作的奖励,然后根据固定规则更新Q(s,a)表。 每次更新Q(s,a)表时,代理都可以从中学习。一旦Q(s,a)经过多次学习后收敛,就得到最优的Q(s,a)函数。
假设在状态st下执行动作后,状态变为st+1,Q(s,a)表可以更新如下:
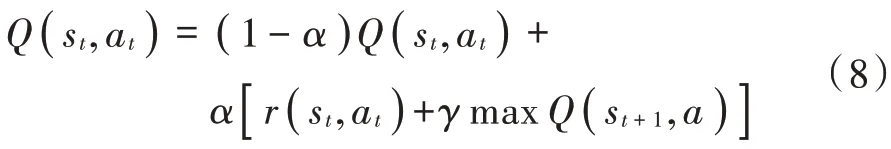
式中,r(st,at)是在状态st下进行行动at的奖励。如果此行动at可将状态st变为预期的st+1,则r(st,at)获得正值;否则r(st,at)获得负值。
奖励函数反映了所采取行动实现目标的有效性。在本文中,将反馈Δ作为奖励函数考虑的主要因素,并将能量效率作为辅助因素。式(9)、式(10)中的奖励函数R1,R2分别反映系统的速率优化目标和能效优化目标。
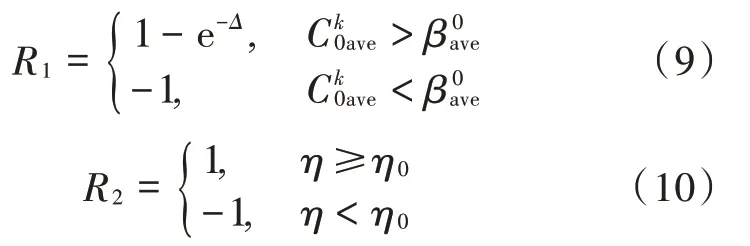
反馈Δ定义为:

式中:Cave为所有小小区的平均吞吐量;Cth为小小区用户最低速率需求。小小区的平均吞吐量越大,奖励函数值就越大。
总的奖励函数为R1和R2的加权和,w1,w2为权值,分别设为0.9 和0.1。奖励函数可表示为:

此外,为了使算法保证足够的公平性且能够快速收敛,本文设置了随机数x和阈值因子f,使代理在开始时随机学习。x∈( 0,1 ),若x>f,则选取动作集中对应Q值最大的动作;反之,则随机选取动作。f的值为:

式中:f0为f的初始值,设为 0.8;td是从给用户进行第一次资源分配以来经过的调度周期。
2.2 算法具体实现过程
本文在宏小区范围内以集中方式进行资源调度和策略的学习,在为簇和小小区进行资源调度时,能够更有效降低干扰的影响,实现近乎最优的资源分配策略。
由于每个小小区复用资源的变更都会相应地改变系统内的干扰状态,Q 表未收敛时,若系统内有新用户进入或旧用户离开,采用轮询方式为小小区簇重新进行资源调度,并在每个调度周期对簇内小小区进行资源分配策略的更改,循环往复直到Q 表收敛。当Q 表收敛后,直接根据Q 表为新用户分配资源即可。
3 仿真结果分析
3.1 仿真参数
本文采用的路径损耗模型和基站设置参照文献[13],其系统仿真环境参数如表1所示。

表1 系统仿真参数Table 1 Simulation parameters of system
本文提到的折扣因子γ和学习率α的值分别设置为0.87 和0.56,阈值因子f的初始值f0设为0.8。系统内有50 个资源块,每个资源块180 kHz。宏基站覆盖区域半径为500 m。
3.2 仿真结果
图1为系统中所有用户的吞吐量之和随小小区用户数量变化的情况。本文设置了2 种对比算法,分别为随机算法与比例公平算法。其中随机算法为在其他条件不变的情况下,小小区用户与QL 算法使用相同数量的资源,系统随机为用户进行分配。比例公平(Proportional Fair,PF)算法为资源分配中的经典算法,它为每个用户设定一个PF 度量值来表示他们的优先级,对优先级高的用户进行优先分配。如图1所示,从整体趋势来说,3 种算法的系统总吞吐量均随着小小区用户数量的增多而增加,但是随着小小区用户的增多,用户之间的干扰有所上升,故而吞吐量的增加速度有所减缓。本文在QL 算法奖励函数的设定中,将吞吐量作为优化指标之一,使得每次算法迭代都会让系统为用户分配最优的资源,从图中可以看出QL 资源分配算法要优于随机算法与比例公平算法。图2绘制了系统的能量效率在不同算法条件下随小小区用户数量的变动,系统能量效率为系统的总吞吐量与基站总能耗的比值。
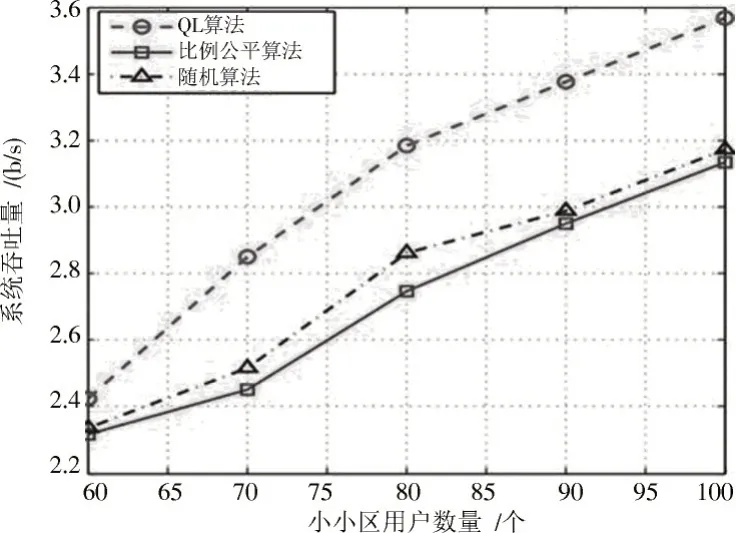
图1 系统吞吐量随小小区用户数量变化Fig.1 Variation of system throughput with the number of small-cell users
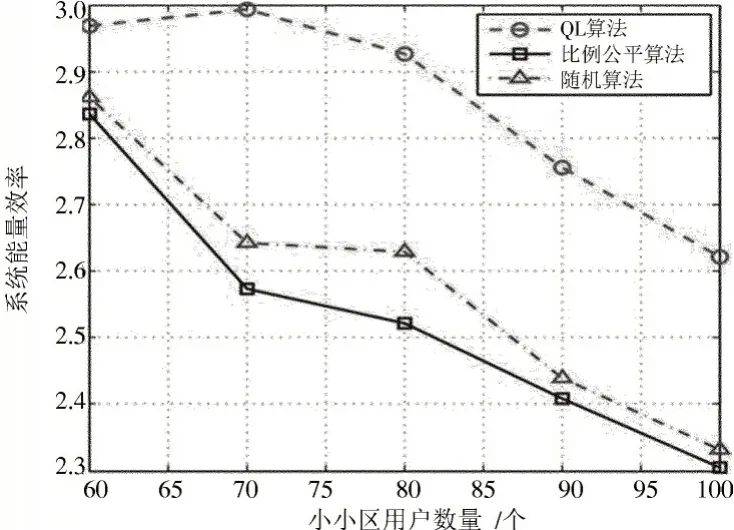
图2 系统能量效率随小小区用户数量变化关系Fig.2 Variation of system energy efficiency with the number of small-cell users
从图2可知,当用户数量增加时,用户间干扰会变大,系统总吞吐量增加速度减缓,然而基站的能耗稳定增加,所以图中整体的系统能效趋势变化是逐渐减少。QL 算法奖励函数中将系统能效作为副优化指标,从图中可以看出QL 算法性能优于其他两种算法。
图3是Q 表累计回报总值随算法迭代次数的变化曲线。图4是固定小小区用户数量为100 时,系统吞吐量随算法迭代次数的变化曲线,体现Q 表的收敛情况。从图中可以看出在算法执行约80 000 次时,Q 表变化已经十分微小,在约进行90 000 次时,Q 表基本趋于稳定,可以证明此算法可以有效收敛。
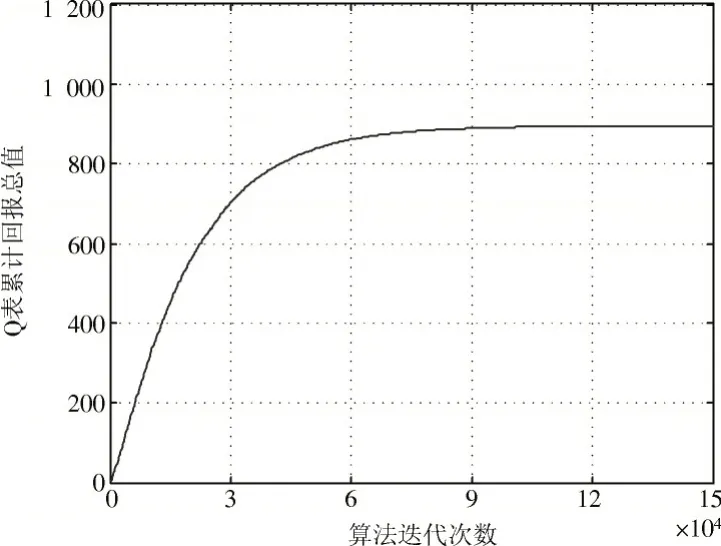
图3 Q 表累计回报总值随算法迭代次数变化关系Fig.3 Variation of Q table cumulative return value with the number of iterations of the algorithm
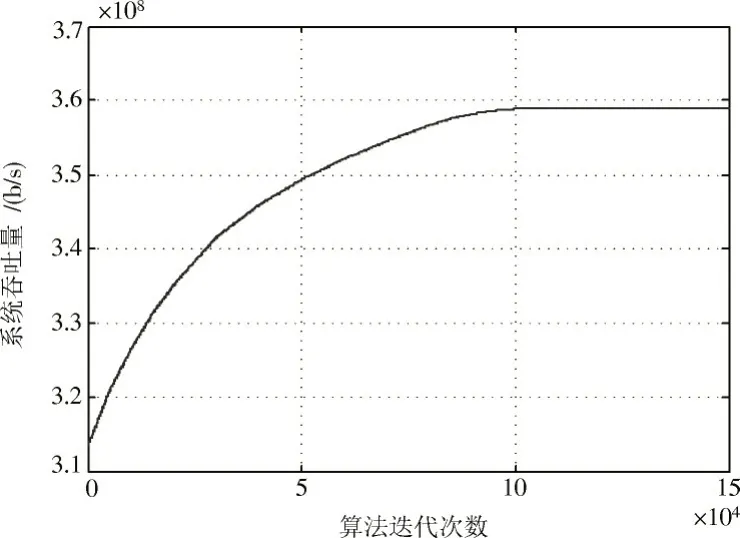
图4 系统吞吐量随算法迭代次数变化关系Fig.4 Variation of system throughput with the number of iterations of the algorithm
4 结 语
本文针对超密集部署的场景,研究了异构系统的资源调度和分配问题。制定融合最大化系统总吞吐量和提高系统能效的优化目标,设计基于超密集网络的Q 学习资源调度算法,通过仿真对算法性能进行了验证,并与经典资源分配算法进行了对比。仿真结果表明本文提出的Q 学习资源调度算法在吞吐量、能量效率等方面均优于其他算法,同时也验证了Q 学习的选择过程的可收敛性。由于采用集中式的学习方式,使得系统最初的收敛速度较慢,但依旧可以保证用户的基本通信需求。如何对Q 学习进行更合理的状态和行为空间设置,以及如何让算法更快收敛,是本文后续工作的重点。
