基于Jetson TX1的目标检测系统*
2019-09-19张雯婷孙旭泽
葛 雯, 张雯婷, 孙旭泽
(1. 沈阳航空航天大学 电子与信息工程学院, 沈阳 110136; 2. 国家电网辽阳供电公司 信息通信分公司, 辽宁 辽阳 111000)
计算机视觉领域中,目标检测一直是工业应用中比较热门且成熟的应用领域,它涉及场景中目标分类和目标定位的结合,比如人脸识别、车牌识别及行人检测等.因为近年来硬件计算能力变得越来越强,所以在卷积神经网络基础上进行深度学习的研究也得到了不断发展,特别是在机器视觉方面已有不错的成果.刘文生等提出了SSD(单镜头多箱检测器)算法,采用回归方法进行检测,并将定位和分类集成到一个网络中.SSD算法基于VGG-16网络结构,将VGG-16中的全连接层替换为卷积层[1],然后将各个卷积层分别输出到各自的特征映射,作为特征图预测的输入,最后生成一个多尺度的特征映射进行回归.而YOLO算法是将目标检测转换成一个回归问题,使检测速度得到了极大的提升,不过仍存在一些不足,即检测小目标所得的结果无法达到较高精度[2].通过各路学者不断的努力,YOLO算法得以一次次升级,现在已经升级为YOLOv3,它采用K-means聚类的方法在数据集中得出其边界框最佳的初始位置.为了提高小目标的检测精度,算法采用了多尺度融合[3],但上述算法的速度还达不到实时效果.对于无人驾驶问题,在提高检测精度的同时,也需要提高实时性能,为了平衡速度与精度两者之间的利弊,本文中改进了YOLOv3网络,使其更适合在硬件上运行.
1 目标检测系统
将自动驾驶应用到实际中,既要提高计算能力,又要考虑实物的成本以及大小等问题,若要满足这些需求,则需使用高性能并具有GPU的多核平台.本文使用了NVIDIA公司开发的嵌入式视觉计算系统Jetson TX1,TX1以256核Maxwell架构GPU为主,在性能上十分节能高效并且外观小巧[4].以Jetson TX1作为核心开发板,将前置摄像头采集到的图像信息输入到TX1中,再通过目标检测算法,检测、识别多种目标,并将读取的信息存储至数据库,同时通过显示屏显示,系统硬件原理框图如图1所示.目前,应用在TX1上的图像检测计算的帧速率虽然很可观,但对于实际应用来说,还有一定差距,因此本文选用最新的YOLOv3算法在此平台上进行改进、提速.

图1 系统硬件原理框图Fig.1 Block diagram of system hardware principle
2 YOLOv3及改进的检测算法
2.1 YOLOv3算法
基于端到端YOLO系列算法的步骤为:首先输入图像并提取网络特征,得到一定大小的特征图(比如13×13),然后将输入图像划分成13×13个单元格,接着进行边界框预测.某个目标的中心坐标落在哪个单元格中,则由该单元格来预测该目标,每个单元格都会预测固定数量的边界框(YOLOv1中是2个,YOLOv2中是5个,YOLOv3中是3个),这几个边界框中只有最大的边界框才会被选定用来预测该目标[5].
相较于前两代YOLO,第三代YOLOv3有了很大进步,各方面都复杂得多,而且无论是在速度方面还是结果的精度方面,对比其他深度学习算法(SSD、R-FCN等),YOLOv3的优势都是最明显的[6].YOLOv3首先对边界框预测,采用K-means聚类的方式对Anchor Box进行初始化,得到多个Anchor Box的尺寸、位置信息[7],其次,采用多标签分类,该操作是通过logistic分类器来实现的,取代了以往的softmax分类,这是YOLOv3的一大亮点,解决了重叠类别标签检测不出的问题.另外,类别预测中的损失函数采用二元交叉熵,特别针对小目标检测,还采用了多尺度融合进行特征提取,采用Darknet-53特征提取网络,包括53个卷积层和残差结构.YOLOv3虽然改进了YOLO一直以来不擅长检测小物体的缺点,并一直保证着高检测速度,但平均准确率(mAP)并不高.
2.2 改进的YOLOv3检测算法
2.2.1 激活函数的改进
YOLOv3中所采用的损失函数主要由激活函数sigmoid和二元交叉熵组成,其中输入的连续实值经过sigmoid函数激活后,输出值都会在0~1范围内,但在深度神经网络中梯度反向传递时,要对sigmoid求导,求导后两边趋向于0,也就意味着很大几率会出现梯度消失的现象,甚至还有几率发生梯度爆炸,而且sigmoid所输出数据都大于0,那么收敛速度会受到相应的影响[8].本文结合sigmoid函数和ReLU函数存在的问题,将激活函数改进为
(1)
式中,参数α、β为可调整参数,神经网络更新α的方式为
(2)
式中,μ、ε分别为激活函数通过反向传播进行训练得到的动量和学习率.本文采用αi=0.25作为初始值,β则控制着负值部分在何时饱和,最终通过不断测试对比,选取β=0.5[9].改进后的激活函数其总体输出接近0均值,这样下一层的神经元得到0均值作为输入,能够提升收敛速度,还解决了梯度消失以及ReLU函数中的Dead ReLU问题.加入参数α、β后,可以避免引起某些神经元可能永远不会被激活,导致相应的参数永远不能被更新的情况.
2.2.2 采用多级特征金字塔网络
YOLOv3中采用的多尺度融合(FPN)是通过自上而下的方式融合深层和浅层的特征来构造特征金字塔.虽然采用FPN后,大幅度提升了小物体的检测能力,但对于一些大、中物体检测能力偏弱,这是因为金字塔中的每个特征图(用于检测特定大小范围内的对象)主要或甚至仅通过骨干网络单层构建,即主要或仅包含单层信息.图像中所包含的各个目标大小不一,所以应当根据相应的特征分别进行检测,目标可大致分为简单目标与复杂目标两种,对于前者仅仅是浅层特征便可检测到,其所包含语义信息不多,可优势在于目标位置准确;对于后者,则需要较深层的特征,其语义信息相对更多,可不足在于目标位置较模糊[10].而多级特征金字塔网络最后可以提取同一尺度在不同层内的特征,解决了FPN方法的局限性.
本文的多级特征金字塔网络(MLFPN)结构如图2所示,结构保留YOLOv3中的DarkNet-53并作为主要特征提取网络.将MLFPN嵌入到DarkNet-53网络后,首先将DarkNet-53网络提取的3个层次特征(大小分别为13×13、26×26、52×52)通过特征融合模块(FFM)融合,将融合后的特征图(大小为52×52)作为基本特征,再依次由多个U形模块(TUM)和FFM对基本特征进行处理,这样所提取的特征代表性会更强.其中TUM用来产生多个不同尺度的特征图,且不同TUM内解码器层的深度基本一致,每个TUM由5个跨步卷积(编码器)和5个上采样组成,最终将输出6种尺度的特征,本文输出大小依次为52×52、26×26、13×13、7×7、3×3、1×1的特征图.每一级的输出可表示为
(3)


图2 MLFPN结构图Fig.2 MLFPN structure diagram
3 实验结果
3.1 数据集及实验环境
本文的实验环境如表1所示,本文所用的数据集是公开的目标检测标注对比数据集PASCAL VOC 2012.为了确定现有算法是否具备更高的性能,本文所建模型不管是在训练时还是在测试时,都是通过开放数据集而实现.Pascal VOC 2007数据集共包含20个类别,11 540幅图像,27 450个被标注的目标.设置召回率阈值等于0.5,最大边框检测数量是20个.

表1 实验环境Tab.1 Experimental environment
3.2 结果分析
本文分别用改进的YOLOv3网络和Faster-rcnn、YOLOv3算法来检测目标,通过数据集的样本验证训练模型的检测效果,最终检测结果如图3所示.由图3可知,改进后的YOLOv3准确率超过80%,并且其检测效果相比另两种算法有较大的提升.
本文选取数据集中几张图片的检测结果进行对比,对比结果如图4所示.由图4中标出的准确率和识别框数以及表2中各类别mAP对比可证明,无论是普通背景单目标图像、多目标图像,还是有遮挡目标图像,改进的YOLOv3算法都展现了比YOLOv3更好的检测能力,可以更为精准地检测目标,降低了漏检率.

图3 检测方法对比Fig.3 Comparison of detection methods

图4 YOLOv3和改进的YOLOv3检测结果图Fig.4 Detection results of YOLOv3 before and after improvement
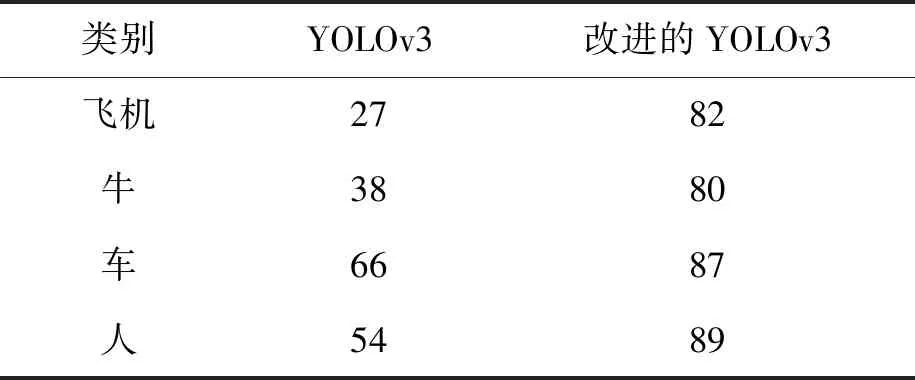
表2 各类别mAP对比表Tab.2 Comparison of different mAP %
将改进的YOLOv3算法应用到TX1开发板中的检测结果如图5所示.静态图像检测结果如图5中a、b、c、d所示;导入一段视频后,动态视频检测结果截图如图5e、f、g、h所示.根据对比图可以看出,改进后的算法可以将较远的小目标和重叠的目标识别出来,漏检率明显降低.其中图5e、f和图5g、h分别为视频中截取的第13帧和32帧,由图5以及表3(对视频进行目标检测的速度及mAP对比表)可以看出,改进的YOLOv3相较于YOLOv3的mAP增长了1.47倍,且检测速度提高了1.13倍.
4 结 论
文中将YOLOv3中的特征金字塔、激活函数改进后,利用嵌入式GPU平台在Jetson TX1上实现目标检测,借助CUDA编程进行并行算法,从而实现目标检测,改进的YOLOv3可以更高速地提取精确结果.由于GPU硬件技术近年来不断获得发展,并且随着研究进一步深入,将深度学习算法应用到具有实时处理能力的、带有强大高性能运算能力的GPU设备中已经成为可能,届时整个目标检测与跟踪过程可以更加高效、准确的实现.

图5 TX1上的实验结果图Fig.5 Experimental results on TX1
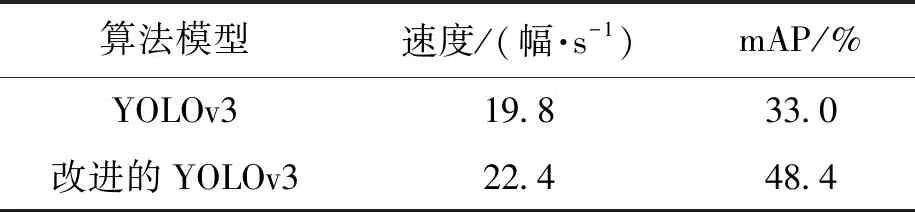
表3 实验结果Tab.3 Experimental results
