基于文本相似度的评审专家推荐方法研究
2019-09-17郑新宇徐建良
郑新宇 徐建良
摘 要:在科研项目申报过程中,当前多采用人工方式进行评审专家遴选,由于人工对领域知识的理解有限,且具有一定的主观性倾向,随着项目申报数量的增加,人工选择的效率和准确率逐渐降低。为解决此问题,该文提出一种基于文本相似度的评审专家推荐方法。通过对项目论文信息进行数据挖掘,利用编辑距离模糊匹配和Wordnet语义扩展方法改进文本相似度计算,设计对比实验分别说明方法的可行性,并对推荐结果给出解释。实验结果表明,该文方法能够有效解决评审专家遴选问题。
关键词:专家推荐 数据挖掘 文本相似度 语义扩展
中图分类号:TP391.1 文献标识码:A 文章编号:1672-3791(2019)06(b)-0173-04
Abstract:In the process of applying for scientific research projects, the selection of review experts is often carried out manually. Due to the limited understanding of domain knowledge and the subjective tendency of manual selection, the efficiency and accuracy of manual selection gradually decrease with the increase of the number of project declarations. To solve this problem, this paper proposes a method of expert recommendation based on text similarity. Through data mining of project paper information, the text similarity calculation is improved by using editing distance fuzzy matching and Wordnet semantic extension methods. The validity of the method is illustrated by designing comparative experiments, and the recommendation results are explained. The experimental results show that this method can effectively solve the problem of selecting evaluation experts.
Key Words:Expert recommendation; Data mining; Text similarity; Semantic extension
随着计算机应用技术的迅猛发展,越来越多的科研单位选择使用线上信息管理的方式,来进行科研项目的申报工作。在科研项目申报的过程中,有一个极为重要的流程就是评审专家推荐过程[1-3]。评审专家推荐是指根据项目的一些文本信息,选择出几个相关领域的专家成为评审专家。评审专家对项目进行评估审查工作,来确认项目是否具有研究的价值[4]。但由于项目申请数量多、类型多样,并且专家的科研信息比较复杂,管理人员很难恰当地评估某个专家在一定时间内的研究偏重方向,所以使用人工来选择评审专家的工作方式效率不够高,不能满足工作需要。因此,需要借助计算机技术,为人工选择评审专家提供自动化的帮助。因此,如何选择出合适的评审专家则成为该文研究的关键问题[5-7]。
评审专家推荐系统本质上是属于个性化推荐技术范畴,目的是满足系统用户对专家这一特殊实体的推荐需求[8]。2005年Reichling、Schubert等学者第一次对专家推荐进行准确的定义,指明专家推荐是一种检索技术,根据一定的信息输入,检索出能解决具体问题的相关专家,帮助用户提高检索效率和精确率[9]。专家推荐系统一般应用于专业领域性较强的工作,如学术论文的审查工作、工程建设的评估工作、项目招标的评审工作。在科研项目申报立项的过程中,对专家推荐的专业性要求标准更高,对推荐技术也有着更高的要求。胡斌等使用概念层次模型挖掘科技项目与专家相似性,解决科技项目专家推荐问题[10]。刘一星等使用经过改进的ATSVM算法用于论文投稿的评审专家推荐研究[7]。李莹等使用主题信息完成企业需求的专家推荐工作[11]。蒲珊珊等建立知识互补的科研合作专家推荐模型来完成专家推荐工作[12]。
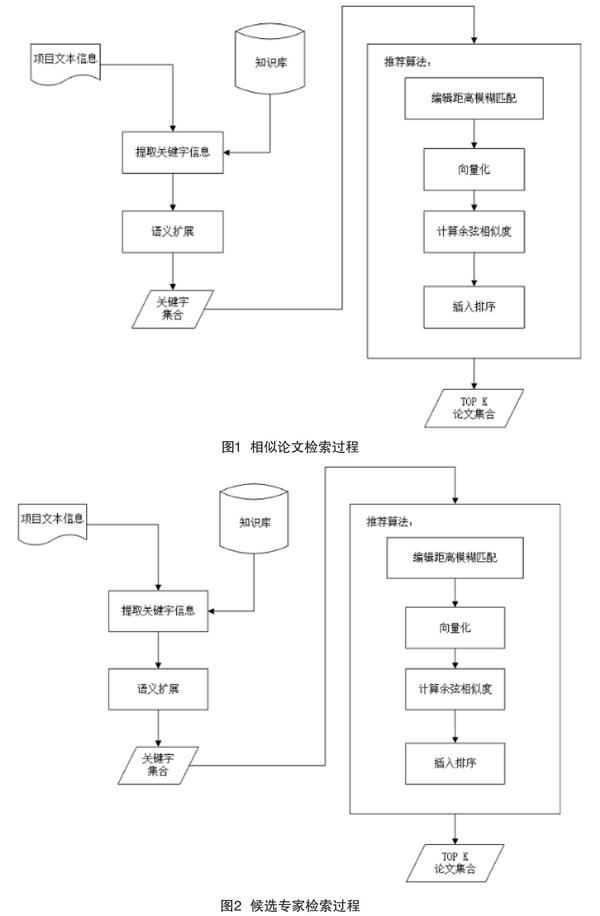
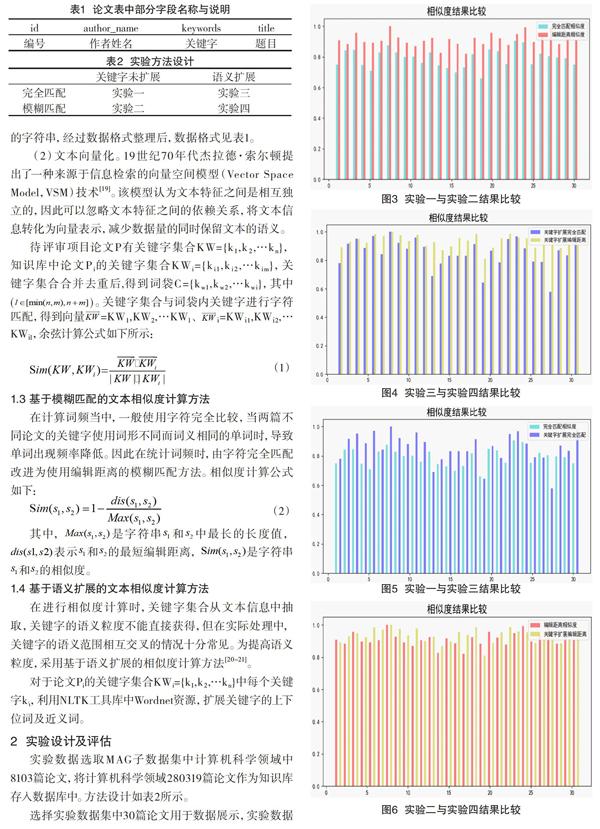
该文设计的基于数据挖掘的评审专家推荐方法,抽取项目中论文关键字和知识库中论文关键字,对关键字集合进行数据规整、语义扩展,得到扩展后的关键字集合[13]。计算项目论文与知识库论文的余弦相似度,得到知识库中相似度排序前K个论文集合。根据论文集合,得到候选专家集合。对候选专家集合中的每个专家的论文进行检索,检索出的论文与项目进行余弦相似度计算,得出的相似度值取平均值作为专家的权威性衡量,候选专家集合中按专家权威性排序,得到权威性排名前N个专家,系统将把这些专家作为推荐结果推荐给用户[14]。
1 评审专家推荐方法设计
1.1 方法思路分析
評审专家推荐的关键问题是根据项目中给出的文本信息,与知识库中的专家进行分析对比,选择出研究相关的人作为评审专家。
该文中专家推荐分为两个阶段:首先,根据项目文本信息在知识库中找到相关论文;其次,根据相关论文,得到候选专家推荐列表,对列表中专家进行分析,分析后得到推荐结果。流程图如图1、图2所示。
1.2 文本数据处理
(1)实验中所用数据集来自微软学术图谱MAG的子数据集。目前MAG主要用于量化学者影响力研究[15]、异构学术网络中学者位置的影响力研究[16]、学术社交网络的提取与挖掘[17-18]等。
对于MAG中的论文信息,每篇论文都是一个JSON对象的字符串,经过数据格式整理后,数据格式见表1。
(2)文本向量化。19世纪70年代杰拉德·索尔顿提出了一种来源于信息检索的向量空间模型(Vector Space Model,VSM)技术[19]。该模型认为文本特征之间是相互独立的,因此可以忽略文本特征之间的依赖关系,将文本信息转化为向量表示,减少数据量的同时保留文本的语义。
1.3 基于模糊匹配的文本相似度计算方法
1.4 基于语义扩展的文本相似度计算方法
在进行相似度计算时,关键字集合从文本信息中抽取,关键字的语义粒度不能直接获得,但在实际处理中,关键字的语义范围相互交叉的情况十分常见。为提高语义粒度,采用基于语义扩展的相似度计算方法[20-21]。
对于论文Pi的关键字集合KWi={k1,k2,…kn}中每个关键字ki,利用NLTK工具库中Wordnet资源,扩展关键字的上下位词及近义词。
2 实验设计及评估
实验数据选取MAG子数据集中计算机科学领域中8103篇论文,将计算机科学领域280319篇论文作为知识库存入数据库中。方法设计如表2所示。
选择实验数据集中30篇论文用于数据展示,实验数据集与知识库中的论文进行匹配后,计算得出余弦距离并排序。
由图3、4可知,管是关键字集合在扩展前还是扩展后,基于编辑距离的相似度都要高于完全匹配的相似度,说明在完全匹配中检索不出来的关键字,在基于编辑距离相似度计算方法中被检索出来,且每一篇的数值模糊匹配要高于完全匹配,说明在进行相似度计算时,选择模糊匹配的方法是有效的。
由图5可知,经过关键字扩展后,完全匹配的相似度升高。由此可证明,完全匹配失败的关键字,在关键字扩展后,拥有相同的上下位词或者近义词,经过字符串完全匹配后,余弦相似度增加。
根据图6余弦距离结果可知,关键字在扩展前后经过模糊匹配后,相似度整体表现差别不是特别大。原因在于关键字经过语义扩展后关键字集合维度增加,根据式(1),造成余弦距离结果相差较小。从另一方面来说,关键字集合经过扩展后,相似度变化不大说明关键字集合携带的信息量增加,但对整体的语义偏向没有太大的影响。
3 结语
该文设计了一种通过计算文本余弦相似度来推荐评审专家的方法,解决人工遴选评审专家中效率较低、主观选择专家等问题。由于方法是基于文本内容相似度进行专家推荐,因此该方法对所有文本推荐具有一定的普适性。
目前对于评审专家的推荐方法,大多从语义概念模型方向解决推荐问题。但在研究领域中存在专业内专有名词,因此需要人工建立领域词典,建立语义之间的联系,未来的进一步工作是在Wordnet基础上,加入专有名词语义关系,进一步提高语义扩展的相似度。
参考文献
[1] 张勇勤.科技计划项目经费预算评审评估制度研究[J].天津科技,2008(3):77-79.
[2] 陈月英,穆仕华.科研项目在线评审体系的研究与应用[J].中国新通信,2015,17(9):69-70.
[3] 沈才俊,徐暑芬,常云志.科技项目评审过程中项目分组与专家推荐流程的设计[J].江苏科技信息,2016(6):29-31.
[4] 梁保磊.政府科技项目评审主体、过程及应用系统开发研究[D].东南大学,2009.
[5] 万猛.关于科技评审专家的选择及其评审行为的判断方法[J].研究与发展管理,2007(3):119-122,129.
[6] 靳健,杨海慈,李凝,等.基于主题契合度的专家推荐模型研究[J].数字图书馆论坛,2017(4):47-55.
[7] 刘一星.论文投稿系统评审专家自动推荐模型研究[D].重庆大学,2009.
[8] 李有超.基于项目属性与偏爱比较的协同过濾推荐算法研究[D].燕山大学,2010.
[9] Reichling T,Schubert K,Wulf V.Matching human actors basedon their textsdesign and evaluation of an instance of the Expert Finding framework[A].Proceedings of the2005 international ACMSIGGROUP conference on Supporting group work[C].ACM,2005:61-70.
[10] 胡斌,徐小良.科技项目评审专家推荐系统模型[J].电子科技,2012,25(7):1-5.
[11] 李莹.面向企业需求的专家推荐算法研究[D].北京交通大学,2018.
[12] 蒲姗姗.基于知识互补的科研合作专家推荐模型研究[J].情报理论与实践,2018,41(8):96-101.
[13] 滕岩,李玉忱.基于《知网》的语义信息检索[A].第二届全国web信息系统及其应用会议[C].2005.
[14] 朱昆磊,黄佳进.基于信念网络的协同过滤图模型的推荐算法[J].模式识别与人工智能,2016,29(2):171-176.
[15] 周金梦.基于学术异构网络的学者影响力评估算法[D].大连理工大学,2016.
[16] 张君.基于异构学术网络的学者影响力评估与预测[D].大连理工大学,2018.
[17] Tang J, Zhang J, Yao L, et al. Arnetminer: extraction and mining of academic social networks[A].Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining[C].ACM,2008:990-998.
[18] Sinha A, Shen Z, Song Y, et al. An overview of microsoft academic service (mas) and applications[A].Proceedings of the 24th international conference on world wide web[C].ACM,2015:243-246.
[19] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[M].Communications of the ACM,1975.
[20] 王良芳.文本挖掘关键词提取算法的研究[D].浙江工业大学,2013.
[21] 王进,陈恩红,施德明,等.一种基于语义相似度的信息检索方法[J].模式识别与人工智能,2006,19(6):696-701.
