差异网络分析方法在组学数据变量筛选中的应用*
2019-09-17哈尔滨医科大学卫生统计学教研室150081蔡雨晴
哈尔滨医科大学卫生统计学教研室(150081) 蔡雨晴 宋 微 徐 欢 李 康
组学数据(omics data),如基因组、转录组、蛋白质组和代谢组等数据能够反映疾病的发生、发展和预后的情况。对于组学数据的分析,主要是筛选有用的生物标志物、分析调控网络和建立预测模型。一般是通过变量差异表达量分析不同类别之间的差别。但在实际中,也可能有这样一种情况,即在不同分类中,变量的量值变化不大,但其网络拓扑结构(network topology structure,NTS)却发生了变化,这种情况同样能反映不同的生物学特征,并据此发现重要的生物标记物。差异网络分析方法是近年来新提出的一种以网络为基础的生物信息算法,注重不同状态(如健康或患病等)下NTS的差异,从而发现导致不同生物进程的重要差异物质[1]。与传统的差异变量分析方法相比,差异网络分析方法更侧重于分析变量间关系的改变,在调控关系发生变化时使用这种分析方法更为有效[2]。本文对近年来提出和发展的几种差异网络分析方法做一综述。
基于NTS局部改变的分析方法
差异网络分析将不同分组情况下的数据分别构建网络,如图1a和图1b为两不同分组的网络调控关系,图1c标示了两组变化的调控边。
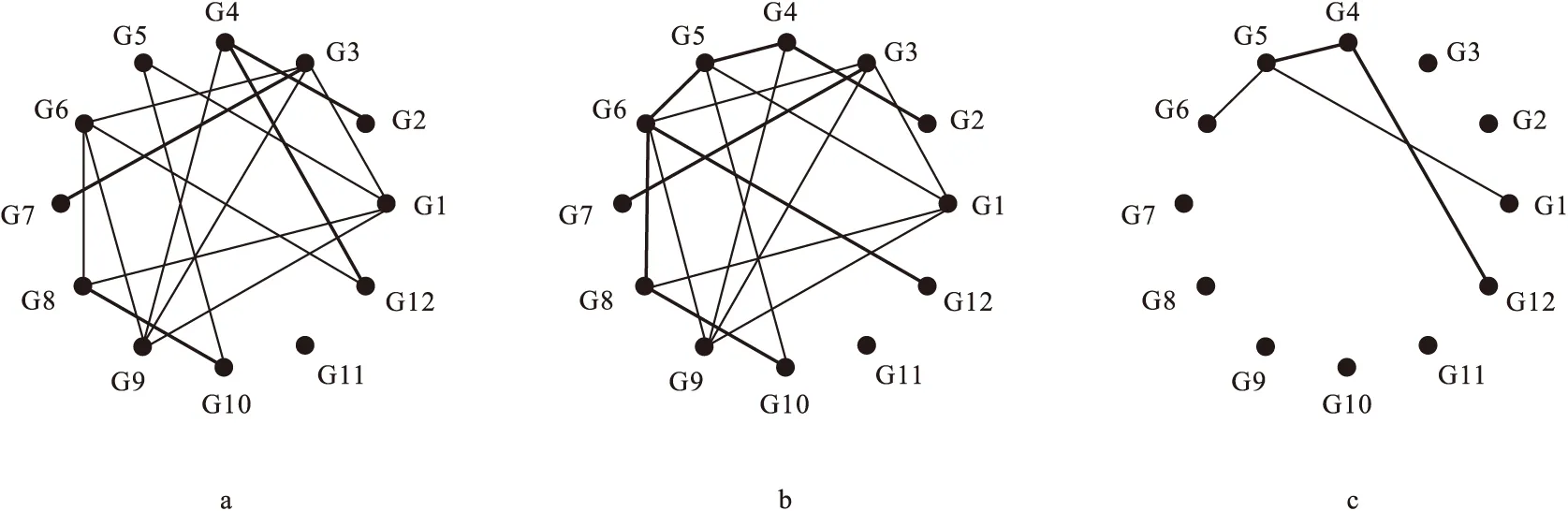
图1 两不同分组的调控网络及差异边
网络图中描述局部连接参数的指标较多,其中应用最多的为网络连接权重(connectivity),其意义为节点之间的调控关系强弱。在图1中,节点之间的连接边粗细代表不同权重大小。连接权重的求解方法有互信息法、相关系数法、偏相关系数法、回归系数法及其他非线性回归方法等[3]。网络连接权重可以通过随机置换试验选择合适的阈值,减少不显著的假阳性边,得到更为优化的网络关系。Zhang等学者提出权重基因共表达网络分析(weighted gene co-expression network analysis,WGCNA)[4],将WGCNA的思想应用在网络中的连接边上,可以得到比未加权更具稳定性的网络。
1.DiffK算法
(1)
其中,u为网络内任一节点,Nu是在网络中与节点u相关联的节点集合。kA(u,v)和kB(u,v)分别表示不同网络A、B中节点u与其关联节点的连接权重。DiffK值用于比较节点在不同网络中连接权重的差异,以网络中节点连接权重最大值max(kA)和max(kB)进行标准化以便比较。从公式(1)中可以看出,节点u与其他节点的连接权重和越大,节点u的DiffK值越大。DiffK值可在一定程度上反映节点在网络中的作用大小。Fuller等人在小鼠基因组数据中应用WGCNA方法,与传统的差异表达分析方法相比,找到了与小鼠体重有关的生物标志物和通路信息,表明结合网络特性的DiffK算法效果更好[5]。
网络连接权重从节点间的关联强度考虑节点重要性。在实际生物学现象中,节点的度(degree)同样重要。度即节点的连接边数量,如在图1a中,节点G1在网络中有4条连接边,即节点G1度为4。实际中的多数网络为无标度网络(scale-free network),其特性是仅少数节点有较大的度数,如中心基因(hub genes),多数节点只有少量的连接边。中心基因表达水平的微小变化虽不容易识别,却能明显改变网络的拓扑结构。在蛋白互作网络中,重要的功能性蛋白通常具有较高的度[6]。
2.NC算法
(2)
其中,Nu为与节点u相关联的节点集合,Zu,v表示在网络图中由节点u和v与其他任意相关节点连接边所组成的三角形数量,du、dv分别代表节点u和v的度。公式(2)每个单项式分母含义为节点u和v与其他节点连接组成的三角形最大数量,分子为相应的三角形实际数量。如图1a,G1与G3的度都为4,理论上由G1和G3构成的三角形最大数量为3个,但实际只有Δ1391个。NC算法既能考虑到节点的中心性,也能考虑到节点与相邻节点之间的联系。Wang等人将NC算法应用于三个不同的酵母菌蛋白交互网络中,与其他六种差异网络分析方法对比,NC算法在所有网络中的阳性结果,均能得到更多的必需蛋白质,同时NC算法具有更高的灵敏度和特异度[7]。
3.DCloc算法
(3)

4.PageRank算法
Page在1998年首次在网页浏览重要性应用上提出PageRank概念[9],即网页的重要性取决于网页链接指向该网页的其他网页的重要性。同理,可将其理解为网络图中一节点的连接重要性取决于相邻节点的度。如与某一节点连接的相邻节点的度大,则该节点在网络中可能起到传播或桥梁作用。其计算公式为
(4)
PageRank算法首先对所有节点进行一个简单的排秩,通过不断使用公式(4)迭代计算使其收敛。Pu表示指向节点u的节点集合,Bu为节点u指向的节点集合,Nu为Bu内节点数量。该方法假设节点u的秩R(u)被其指向的节点集合Bu均分,由于一些节点可能没有Bu而损失了u的秩,因此cA和cB分别为A、B网络的标准化系数,它可使网络中所有节点的秩和恒定。Omranian等人以PageRank算法为基础在拟南芥转录组数据中发现了不同信号通路的关键基因[10]。值得注意的是,PageRank算法是基于有向网络的一种方法,对网络中心节点的发现有重要意义,尤其当变量数量较多时。
基于NTS全局改变的分析方法
以上基于网络拓扑结构局部改变的方法都是以节点的直接连接节点出发计算其差异统计量,而无法考虑网络中的所有节点对被分析节点的影响,包括直接连接点和间接连接点。基于此,Freeman在1977年提出中介中心性(between centrality,BC)这一概念[11],其公式为
(5)
其中,s、t为网络中任意两点,ρ(s,t)表示网络中以s为起点、t为终点的最短路径的总数,ρ(s,u,t)表示在经过s、t节点的所有最短路径(沿节点s到节点t的所有路径中,各边的权重总和最小的路径)中,同时经过节点u的数量。当节点u的关联节点数目较少或节点之间连接权重较小,却是网络中最短路径的必经节点时(如图2中,G6虽然只与G5和G7相关联,但网络中大部分最短路径都要经过G6),仍可认为u是网络中的重要节点,此时BC(u)值能够反映节点u在网络全局中的重要程度。在蛋白网络应用中,一些度低但中介中心性很高(high betweenness low degree,HBLC)的蛋白也发挥着十分重要的作用[11]。Potapov将其应用于哺乳动物转录组数据的两个网络中,发现中介中心性对描述生物网络拓扑结构有重要意义,更具有实际生物学意义[12]。

图2 BC算法适用的网络图示
基于NTS的全局和局部改变分析方法
既然网络拓扑结构的局部改变与全局改变同样重要,Odibat即提出DiffRank算法[13]。DiffRank算法根据节点对网络差异改变的贡献排序,从而筛选出引起网络差异的重要节点。局部和全局结构改变评价指标为
(6)
(7)
(8)

基于每一节点的差异评分π给所有节点排序,π越大表示在差异网络中贡献越大,即我们所需要筛选的差异位点。DiffRank算法既考虑了网络中节点的局部信息,又考虑了网络全局信息,Lichtblau评价了十种差异网络分析方法对4个相同数据集的筛选效果,其中包括多个局部与全局NTS差异网络算法,根据给出的差异基因金标准(gold standard list,GSL)[14]判断,DiffRank算法在前40个差异位点中重合概率最高,Fisher确切检验表明结果具有统计学意义[1]。
结 语
本文主要介绍了网络拓扑结构的一些基本概念以及近年来提出和发展的几种差异网络分析方法,其主要特点是通过不同分组各节点或拓扑结构的变化筛选重要的变量,克服了单纯比较变量均值变化的不足。本文介绍的三类方法各有特点,如局部度数检验能够识别直接调控其他节点的关键调控因子,但不能发现间接调控其他节点的重要节点;全局中介中心性算法考虑了网络中各节点对其他节点的影响,更强调中间调节点;局部与全局结合在一起的DiffRank算法则能够更全面地分析网络调控信息。实际中,当变量数过大时,在差异网络分析之前,可以结合差异表达分析对变量进行筛选或选取与分组信息有关的通路进行分析。
网络的基本概念还包括接近中心性(closeness centrality,CC)、特征向量中心性(eigenvector centrality,EC)等,基于这些概念的差异网络分析方法也有很多,不仅能通过网络的信息筛选组学数据中的差异位点,还可以得到导致不同结局的差异边,如根据贝叶斯算法判断差异边等[15]。目前大部分差异网络分析都是基于排秩方法判断差异物质,但不同数据情况无法确定取前几位,因此如何通过统计学方法选取合适的显著性差异物质是亟需解决的问题。同时,由于基因间真实的相关关系未知,缺乏可用的金标准来评估差异网络分析方法用于真实数据的可靠性,目前可借助已有的通路信息(如KEGG、GO等数据库)对其进行验证和支持。
