基于学习的空间机器人在轨服务操作技术*
2019-09-16解永春李林峰
解永春,王 勇,2,陈 奥,李林峰
0 引 言
1957年10月,前苏联发射了第一颗人造地球卫星“Sputnik-1”,自此开启了人类的航天时代[1].早期的航天器结构简单、功能单一、按预定程序执行任务,随着人们对航天活动的功能、效益定义范围的日趋扩大,对包括空间操作(space operation, SO)在内的航天技术提出了越来越高的要求.
空间操作是指航天器为完成空间规定动作或任务而从事的在轨活动,包括在轨服务(on-orbit servicing, OOS)、空间拦截、空间规避等[2],是一种任务主导的在轨活动.航天器在轨服务是众多空间操作中最具有研究价值的方向之一,它是指在空间通过人、机器人或两者协同完成涉及延长各种航天器寿命、提升执行任务能力、降低费用和风险的一类空间操作.在轨服务涉及到许多与任务相关的操作,种类庞杂,对在轨服务的任务进行分析和划分,可将在轨服务分为在轨装配、在轨维护和后勤支持这三类[3].在轨装配包括航天器级的组装、零部件组装和在轨制造等几个层级,对于大型机构的在轨应用具有重要意义;在轨维护包括预防性维护、纠正性维护和升级性维护等,对于在轨排故和模块的增加与更换很重要;后勤支持包括消耗品的更换、气液加注、轨道清理、轨道转移和在轨发射等,为空间系统正常运行和能力扩展所需的后勤和补给提供支持和保障.
不论是哪种在轨服务,最终都是要落实到具体的技术上才可以实现,即在轨服务是通过服务航天器按照计划方案采用一定的服务操作手段来实施的,这种手段就是在轨服务操作[3].在轨服务操作涉及远距离交会/对接(rendezvous and docking, RVD)技术、消旋/捕获技术、组合体控制技术、服务操作技术等关键技术.交会对接包含两个或两个以上的飞行器在轨道上按预定位置和时间相会的过程和随后的在机械结构上连成一个整体的对接过程[4],RVD是实现其他在轨服务操作的基础和上游技术,我国已掌握快速自主交会对接技术[5].按照是否有人直接参与,在轨服务操作可分为由航天员主导或航天员直接参与的有人在轨服务操作和无人现场参与的在轨服务操作[3].早期航天员对哈勃望远镜[6]、国际通信卫星6号[3]及空间站的维修[7-8]均属于有人在轨服务操作,随着任务难度的增大,逐渐发展出以遥操作[9]、人员监控下自主服务操作和完全自主服务操作等为代表的自主程度逐渐递增的在轨服务.在完全自主在轨服务中,航天器在人工智能(artificial intelligence, AI)的支持管理下,不依赖地面测控,仅依靠自身敏感器和控制装置就能自主的完成相关操作,具有更高的灵活性,是未来的发展趋势.人工智能是研发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新学科[10],其主流方法包括以符号主义人工智能(symbolic AI)为核心的逻辑推理和以数据驱动(data-driven)为核心的机器学习.后者通过不断地训练和自我学习,可以构建出复杂的映射模型,将其用于在轨服务操作中,能够实现完全自主的复杂操作,弥补传统控制方法的不足.
为便于理解,将上文提到的空间操作、在轨服务、在轨服务操作及相关的分类在图1中进行表示.
本文研究的是在空间交会对接基础上,即在对接之后的、完全自主的、基于学习的空间机器人在轨服务操作技术.

图1 主要概念关系图Fig.1 Relationship of key conceptions
1 基于空间机器人的在轨服务操作技术研究现状
1.1 近年来国外在轨服务操作主要研究计划
在过去的50多年里,围绕在轨服务操作,世界各航天大国陆续进行了一系列探索性尝试.
在航天活动初期,受各项技术的制约,在轨服务操作大多都是以有人直接参与为主,且任务单一,多停留在在轨维护任务上,例如,1984年,美国航天员对航天峰年任务卫星进行在轨维修[3];1992年,奋进号航天飞机航天员对国际通信卫星6号进行在轨维修[3];2002年,航天员为哈勃望远镜更换太阳能电池阵[6];2008年,航天员对国际空间进行在轨维修[8].
随着航天技术的发展和对航天任务需求的提升,近20年以来,国外逐渐将研究重点转向多任务自主在轨服务操作中,以取代航天员出舱活动,降低其工作风险,提高操作的灵活性,扩展应用空间.代表性的计划项目有轨道快车(Orbital Express, OE)[11],“凤凰(Phoenix)”计划[12],“蜘蛛制造(SpiderFab)”计划[13],“建筑师(Archinaut)”计划[14-15],“地球同步轨道卫星机器人服务(Robotic Servicing of Geosynchronous Satellites, RSGS)”[16],“机器人组装模块化空间望远镜(robotically assembled modular space telescope, RAMST)[17]等,表1对这些项目包括研究机构、主要任务、时间节点、自主性及任务所属种类等在内的内容进行总结归纳.
限于表格篇幅,无法对各项计划的自主性展开说明,而理解这些计划中操作的自主性程度及趋势是很有指导意义的.在OE任务中,在轨实验分别在三个自主操作层级下(遥操作、人员监控下自主和全自主),对上述两项在轨服务操作进行了成功验证,标志着自主在轨服务已经突破了主要的关键技术;在Phoenix计划中,在“非事先设计”的场景下采用人员遥操作,以确保其安全性,在“事先设计”的场景下的接触操作及精细对准操作在人员监控下自主运行,仅需人给出进行或停止指令,而在严格时序的操作下采取完全自主服务方式,由星载软件给出进行或停止指令;在SpiderFab计划中,采用7自由度的KRAKEN机械臂来实现人员遥操作方式及全自主模式下的装配工作;在Archinaut计划中, 验证无航天员出舱活动的情况下,国际空间站的自主制造组装技术,未来将用于大型空间望远镜的在轨组装、航天器的维修、结构扩展、无人参与的新空间站的组装等;在RSGS项目中,研究了配备于机器人服务航天器(Robotic Servicing Vehicle, RSV)上灵巧机械臂FREND在三个自主层级下的在轨检查、维修、故障重定位和升级等多项功能;RAMST计划在地球轨道上进行人员监控下或全自主的包括桁架模块、镜片模块等在内的在轨装配.
从上述研究计划可以看出,操作任务由简单的模块更换等发展为更加精细、复杂的在轨装配;任务环境也逐步由确定性的“事先设计”发展到具备一定不确定性的“非事先设计”;自主性逐渐由有人参与转向无人操作[18-19],对机械臂的操纵也将由遥操作转变为空间全自主.这些转变将为航天器在空间更久地生存、更好地发挥功能、更顺利地完成使命提供保障,将提高航天活动的安全性和效益[20].
1.2 在轨服务自主操作关键技术发展趋势
2013年,美国国家航空航天局(NASA)制定了《机器人、遥机器人 和自主系统发展路线图》,对机器人在空间探索领域的发展概况进行了详细的介绍和解读.2016年11月,以加州大学圣迭戈分校、卡耐基梅隆大学、克莱姆森大学为首的美国19所大学在美国科学基金会的支持下,联合发布了《美国机器人技术路线图:从互联网到机器人》,对机器人技术目前的发展机会、面临的挑战及解决方案进行了全面的总结,详细描述了机构与执行器、移动与操作、感知、学习与适应、控制与规划、人机交互、多智能体机器人七项关键技术的发展路径.本文依托上述两个“路线图”和未来空间操作的发展趋势,对在轨服务操作所涉及的关键技术进行总结.
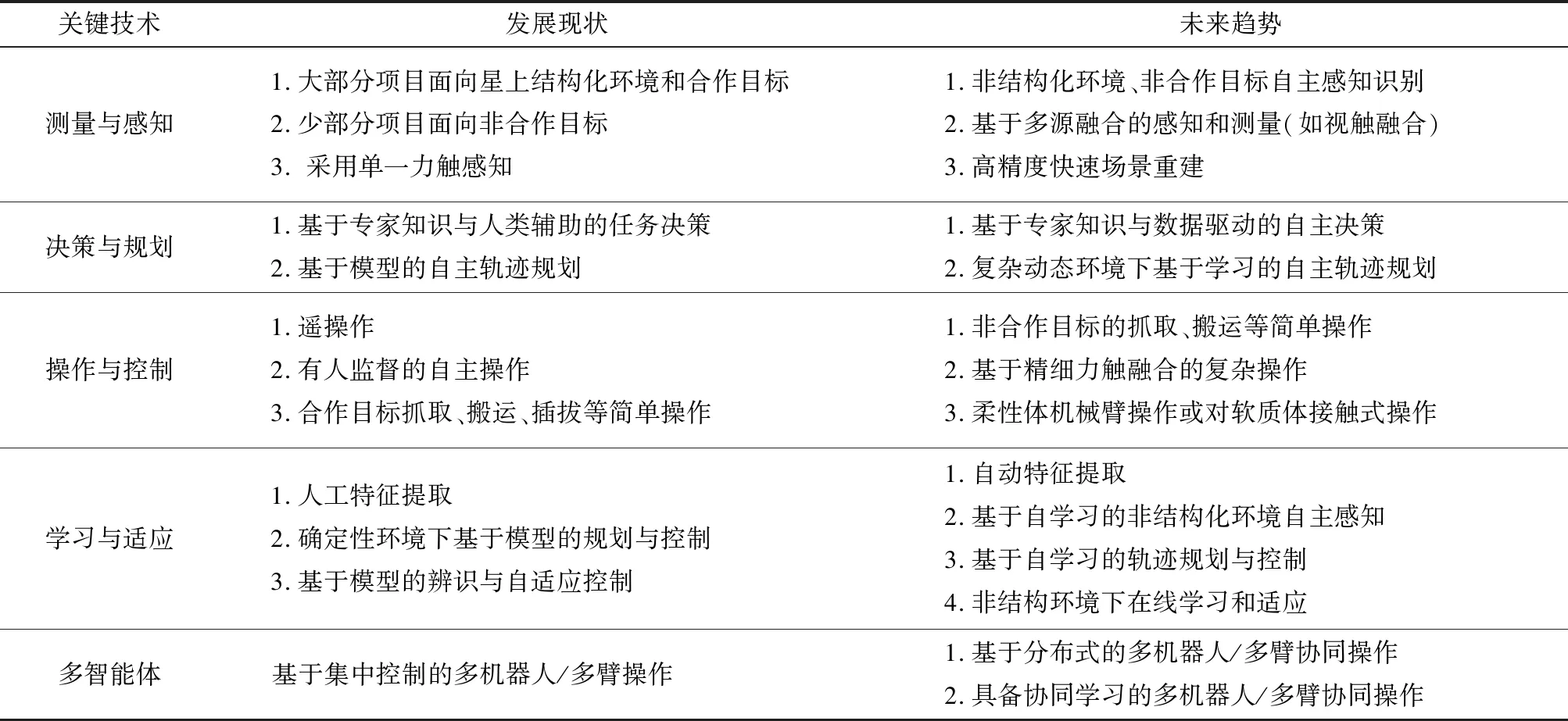
表2 在轨服务操作关键技术发展趋势Tab.2 The key technology trends of OOS manipulations
1.3 自主操作对智能化的需求
传统的机器人技术建立在确定性的环境和精确的模型之上,在应对未来复杂的、非结构化和各种不确定性的场景时存在难以克服的困难:
(1)非结构化复杂环境下空间操作困难重重
空间操作特别是针对非合作目标的空间操作属于非结构化环境,主要体现在以下几个方面:
1)目标对象外形/尺寸多种多样,运动状态不确定
分布于不同轨道的各种型号的故障卫星、飞船等,无论是外形结构还是大小尺寸都存在较大差异;故障航天器姿态往往处于快速自旋或翻滚的状态,接触碰撞后动作轨迹预估不准确.
2)目标对象表面结构复杂、不确知
受体航天器没有统一的结构设计,表面安装各种附属设备,空间机器人在轨操作需要识别安装于不同位置的各种类型的附属设备,并克服各种视觉遮挡.
3)光照条件复杂且不断变化
空间光照条件变化和目标反射特性与地面认知有较大差异,在相同光照条件下,空间目标的反射特性也有较大差异,这给目标特征识别和测量带来了不确定性和极大的困难.
(2)在轨操作任务复杂,对操作的精细化程度要求高
空间操作目标对象功能和结构复杂,造价昂贵,在维修维护时需要较为复杂的精细化操作,主要体现在:
1)在不确定环境下进行操作,要求精细的控制接触力
2)在狭小空间操作,要求末端位置控制要精细
3)操作流程较为复杂,需要精细规划
(3)遥操作无法满足空间操作实时控制的要求
通讯时延大,遥操作无法满足消旋抓捕等实时任务的要求.如对于消旋抓捕来说,空间机器人需要根据目标的实时运动状态,选择特定的消旋和抓捕位置,并快速规划消旋抓捕的接近路径,整个过程处于实时控制回路,必须精准识别、快速决策.
综上所述,为了实现对各种非结构化环境的自主感知和识别、在各种不确定场景下的自主灵活精细操作、对多种任务快速部署和实时响应,必须发展新的技术.将人工智能与空间操作相结合,赋予机器人自主学习能力,是满足未来复杂、精细空间操作任务的一个必然发展方向.
2 基于学习的机器人操作技术研究现状
2.1 概述
学习是人工智能的核心.引用 H. Simon的观点可以这样描述学习:学习是系统中的任何改进,这种改进使得系统在重复同样工作或进行类似工作时,能完成得更好[21].面对各种不确定性的环境,人类包括各种智能生物,正是通过学习来适应各种环境、并与环境进行交互.机器人本质上是一个经常与不确知的环境进行主动交互的智能体,必须基于不完全和不确定的知识进行感知、决策、规划和控制.因此,赋予机器人学习能力,是使其灵活应对复杂多变的环境的重要手段.
20世纪中期,得益于优化理论和最优控制的发展,动态规划为学习控制设定了早期的研究框架[22].发展至今,学习控制已成为控制、优化与机器学习的综合交叉.而基于学习的机器人操作技术,是学习控制方法在机器人领域的重要应用.
机器人的学习控制包含三个要素(如图2所示),即控制策略、学习方法、任务[22].控制策略是状态到动作的映射,可分为基于模型的控制(先建模或估计模型,再学习控制策略,如以微分动态规划DDP、顺序二次规划SQP为典型代表的轨迹规划方法,以及模型预测控制MPC)和无模型的控制(也被称为直接学习,如近似TD-learning[23],近似Q-learning,策略梯度[24]等).学习本质上是一种优化,利用先验知识或历史数据,更新控制策略的参数,使系统实现输出最优;学习方法的划分标准不尽统一,基本可分为监督、无监督、半监督、强化学习等.任务是控制策略在时间、空间序列上的综合;任务可分为基本任务与复杂任务,基本任务包括常规动作任务(如定点路径规划、轨迹跟踪)、离散动作任务(如抓取、放置)、周期动作任务(行走)等,复杂任务是多种基本任务的复合.

图2 机器人学习控制的三要素Fig.2 Three essential factors of the learning-based robot control
机器人学家很早就开始了对学习控制的探索,并把机器学习的方法和技术引入到机器人的感知、决策、规划和控制等环节.例如,迭代学习控制(Iterative Learning Control)就是在机器人领域应用学习控制的早期尝试.迭代学习控制最早由日本学者Uchiyama于1978年提出,其核心思想是“积累经验——提高性能”.迭代学习控制采用“在重复中学习”的学习策略,它具有记忆系统和修正机制,通过对被控系统进行控制尝试,以输出轨迹与给定轨迹的偏差修正不理想的控制信号,产生新的控制信号,进而提高系统的跟踪性能[21].该方法广泛应用于具有重复运动性质的工业机器人底层控制中,如搬运、装配、焊接、喷涂等.此外,借鉴人类直接套用经验的思路,懒惰学习被应用于机器人轨迹规划与控制中,在许多复杂的问题中取得很好的控制效果.相比于以上两种方法,强化学习是一种能够更好的模拟人类与环境进行交互并学习的理论框架,被广泛用于棋类博弈、任务决策、机器人的路径规划与控制等方面.
在深度神经网络出现之前,高维信息(如视觉)的特征提取往往需要复杂的人工设计,经降维后再用于机器人控制.因此,早期的机器人学习控制系统通常被划分为“感知—规划—执行”三个阶段,学习大多体现在后端的规划层和执行层.近年来,随着深度神经网络的崛起,系统具备了高维信息自动特征提取的能力,因此,一种被称为“端到端(end-to-end)”的设计思想成为当前研究的热点.端到端设计的核心是统一化,这种统一化一方面体现在结构上,把感知-规划-执行器的控制统一定义为状态到动作的映射,进行整体学习与优化;另一方面体现在信号层,系统所有的输入、输出都依托于同一框架,即深度神经网络,实现像素到动作的映射.端到端模拟了人类的控制模式,不进行“图像—位姿—动作”的转化,直接通过学习建立“图像—动作”的映射.
在本节的后续部分中,针对机器人的学习控制,我们将首先对懒惰学习、强化学习等早期方法进行阐述;接着,结合应用范例,对引入深度神经网络的深度强化学习、元学习和模仿学习等方法进行讨论.
2.2 懒惰学习(lazy learning)
所谓懒惰学习,又称为机械式学习,基于实例的学习,即时学习或基于记忆的学习,是一种最简单最原始的学习策略,主要通过简单记忆和重现来实现学习.当学习系统解决完一个问题(或称为实例)后,就把该实例于其解存储起来构成知识库.当遇到一个新的问题时,从知识库中查询相似的实例,然后根据知识库中相似实例的解决方案来得到新问题的解决方案.由于整个过程仅仅是存储(记忆)与查询,并不包括对信息的进一步处理,因此称为懒惰学习或机械式学习.此类方法主要包括最近邻法和局部加权回归(LWR)法,更复杂的还包括基于案例的推理法.由于该方法思想简单,实现容易,并且在实例比较丰富时效果显著,因此,大量的应用于各种学习和控制问题.20世纪90年代初期,该思想被卡内基梅隆机器人研究所的SCHAAL和ATKESON发展为一种局部线性回归建模方法(LWPR)可以有效解决在线模型学习问题,比传统的基于神经网络等全局建模方法具有更好的性能.在此领域,ATKESON等采用LWPR训练机器人学习杂技演员挑竹竿(Juggling)的复杂动作[25].英国Aberystwyth大学的LAW等为了模拟婴儿学习基本运动技能的过程,利用 LWPR在线学习机器人动力学模型,利用iCub机器人模拟了从双目扫视、固定凝视目标、躯干控制到手眼协调进行接触抓取等基本动作[26].
2.3 强化学习(reinforcement learning,RL)
20世纪80年代,基于试错方法、动态规划和瞬时误差方法形成了强化学习理论.1984年Sutton提出了基于Markov过程的强化学习.强化学习主要解决这样的问题:一个能够感知环境的自治agent怎样通过学习选择能达到其目标的最优动作,即智能系统通过反复试错,把环境提供的强化信号当作其执行动作好坏的评价作为反馈从而得到最优行为的学习过程.强化学习的机理较为符合人及生物的学习过程,不同于监督学习,强化学习可使智能体在环境中自发学习,从而构成一个实时的学习控制系统.特别是在智能机器人的应用中,一方面可以构成底层的控制基础,另一方面还可以实现高层的行为学习如路径规划、复杂操作等.强化学习主要有瞬时差分法(TD Learning),Q学习算法等,多用于各种棋类游戏、路径规划、任务调度等离散状态问题.
由于固有的维数灾难,传统的强化学习难以解决高维空间、连续系统控制问题.在90年代后期,随着研究的深入,大量学者通过引入各种策略梯度算法,如Episode Natural Actor-Critic[27]、Episodic REINFORCE∥PI2∥PoWER[28-29]等,已经使得强化学习能够在高维、连续系统的机器人控制中成功应用.
2.4 深度强化学习(deep reinforcement learning,DRL)
深度强化学习是近两年来深度学习领域迅猛发展起来的一个分支,目的是解决计算机从感知到决策控制的问题,从而实现通用人工智能.以Google DeepMind公司为首,基于深度强化学习的算法已经在视频、游戏、围棋、机器人等领域取得了突破性进展.
深度强化学习将深度学习和强化学习结合起来,深度学习用于表达或归纳经验知识,而强化学习为深度学习提供学习的目标(数据),这使得深度强化学习具备构建出复杂智能体的潜力,使机器人能够实现从感知到决策控制的端到端自学习,具有非常广阔的应用前景.
Actor-Critic框架是目前深度强化学习的一种通用架构,能够囊括很多DRL算法,如图3所示.主要包括策略网络(Actor)和评价网络(Critic).如果把整个系统看作大脑,那么Actor是大脑的执行机构,输入外部的状态S,然后输出动作A.而Critic则可认为是大脑的价值观,根据历史信息及回馈r进行自我调整,然后影响整个Actor.这种Actor-Critic的方法非常类似于人类自身的行为方式.
适用于机器人学习控制的深度强化学习,主要分为价值学习(Value-learning)方法和策略梯度 (Policy gradient)方法.在解决实际问题时,一般综合使用这两种方法.
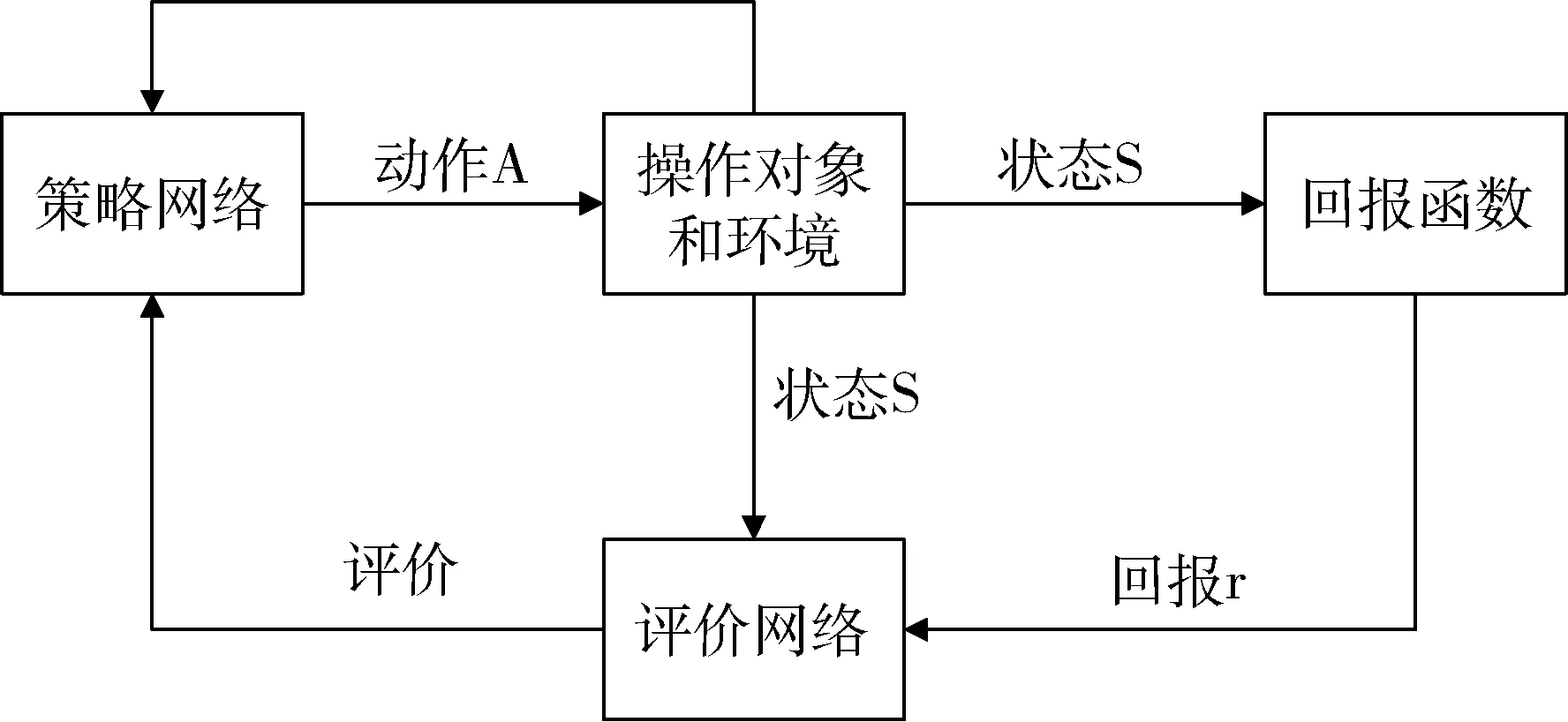
图3 Actor-Critic框架原理图Fig.3 Actor-Critic framework diagram
2.4.1 价值学习方法
基于价值的方法,近似估计、逼近价值函数V(s)或者动作价值函数Q(s,a),是一种近似动态规划的方法.在传统的Q-learning中,当状态s和动作a的组合数量庞大时(例如,视频游戏任务),Q函数的计算与存储代价过大.DQN (Deep Q-Network)利用深度神经网络逼近Q函数,成功应用于ATARI视频游戏[30],以及著名的围棋对弈AI系统Alpha Go[31].
DQN的核心思想在于,让Q-learning中的更新具有类似监督学习的平稳性.关键实现包括两部分,即经验重演(Experience Replay)和目标网络(Target Network).经验重演使用批量的过去经验,替代在线的更新,增加了数据之间的独立性,数据的分布更趋于平稳.在DQN中设定有两组网络,目标网络和Q网络,分别以θ-和θ参数化;前者用来检索目标Q值,后者在训练中实时优化与更新;周期性地将θ-与θ同步,两次同步之间,目标Q值是固定的,增加了学习的稳定性.整体目标函数定义为目标Q值和Q网络输出之间的误差平方期望,如下式所示:
Ui(θi)=

DQN方法的改进包括DDQN (Double DQN)、Dueling DQN等.由于DQN输出默认为离散量,由于动作维数过大,因此很难直接应用于机器人等控制输入为连续量的系统中.该方法的重要性在于它用到的两项技术,即经验重演和目标网络,加上以它们为基准的改进拓展了诸多策略梯度方法.
2.4.2 策略梯度方法
区别于以价值学习为代表的动态规划方法,策略梯度是一种基于直接对策略网络优化的方法.相比于价值学习,它的求解目标更加直接.
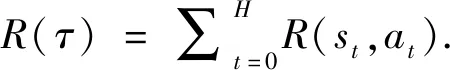
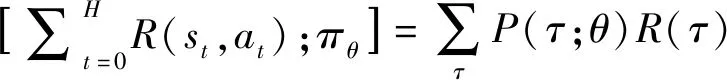
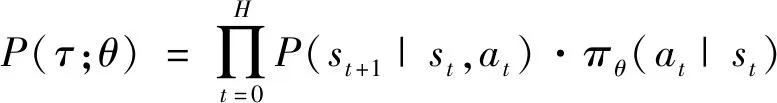
DDPG (deep deterministic policy gradient)[32]是一种无模型的、离线策略的、actor-critic方法.它学习确定性的策略,将DQN的性能与优势拓展到连续空间上.为了达到更好的探索效果,DDPG通过在原策略μθ(s)上叠加噪声项N,构建了探索策略μ′(s):=μθ(s)+N.此外,DDPG在actor网络和critic网络上进行软更新(conservative policy iteration),目标网络的输出被限定为慢变信号,区别于DQN中对于目标网络的冻结.Actor网络参数利用如下式所示的目标函数梯度进行更新:
VECERIK等[33]将DDPG和人工示教结合,在EDRIAD工业机械臂上,实现了插销入洞任务.该工作对于损失函数的设计颇为精细,关键步骤包括:训练了一个分类器用以计算任务奖励、添加了正面和负面示教、优化actor网络时添加了行为克隆 (behaviour cloning) 损失,将标准的TD损失替换为分布式的critic损失等.
DDPG的主要缺点是学习过程受到学习速率的影响可能会不稳定.为了解决此问题,引入了TRPO (Trust region policy optimization)[34]方法.为了增加训练稳定性,避免每次迭代参数更新过大,对步长添加了KL散度约束,并引入优势函数(advantage function)
其中,m为采样轨迹数.上式表明,目标函数的梯度可以由对数策略梯度和优势项表示.
具体地,问题描述为
s.t. εs,a~πθold[DKL(πθ(·|s)‖πθold(·|s))]≤δ
(1)
PPO (Proximal policy optimization)[36]方法对问题(1)的约束做了进一步简化,将新旧策略比例项rθ强制限定在[1-ε,1+ε]区间内,其中ε是一个超参数.具体地,目标函数变为
εs,a~πθold[min{rθ(a|s)Aθold(s,a),
clip(rθ(a|s),1-ε,1+ε)Aθold(s,a)}]
ANDRYCHOWICZ等[37]利用PPO算法,实现了多指灵巧手翻转立方块.系统由姿态估计网络和策略网络构成,前者利用三个视角下的RGB图像,预测立方块姿态;后者利用预测姿态和灵巧手的关节测量信息,输出关节控制电压.由于系统需要处理的信息量巨大,该工作用到了分布式的训练方法.尽管这项工作并未引入人工示教,但结果最终呈现出了诸多类人特性,如利用重力操控,以及多指协调等.
SQL (Soft Q learning)[38]是一种基于最大熵的方法,它利用Boltzmann分布这种基于能量的模型,表示随机策略,相应的能量对应于Q函数.这种表示相比于高斯分布,具有多模态的特征.训练结果表明,该方法产生的模型探索更充分,探索到有用的子模式更多.进一步的研究[39]表明,独立训练得到的最大熵策略,可以通过叠加它们的Q函数,得到更加接近最优的整合策略,这种整合性质将有利于任务的迁移.HAARNOJA等[39]利用SQL,在Sawyer机器人上实现了堆乐高积木操作.针对定点到达任务,相比于DDPG和NAF(normalized advantage functions)[40]方法,SQL在训练速度上具有明显优势.此外,实验结果验证了SQL策略的可整合性:先独立训练机械臂躲避障碍和堆放积木,在两组策略经整合后,可以实现绕障碍堆积木操作.
至此,上文介绍的深度强化学习方法都是无模型的.基于模型的搜索方法,相比于无模型方法,具有采样效率高的优势.GPS(guided policy search)[41]是这类方法的典型代表,它的核心思想是利用模型生成采样,并以此引导学习.具体环节包括控制阶段和监督阶段:控制阶段利用最优控制方法,生成好的轨迹;监督阶段利用这些轨迹进行监督学习.在PR2双臂协作机器人上,LEVINE等[41]最早使用GPS方法实现了图像到动作的端到端训练,完成了拧瓶盖、柱上套环等任务.MONTGOMERY等[42]进一步提出 MDGPS (mirror descent guided policy search)方法,减弱了对于确定性初始状态的要求,实验结果表明,PR2机械臂可以从任意初始位置将积木移至目标点.
2.5 元学习(Meta-learning)
人类学习某种技能时,很少从零开始.我们会下意识地从已习得的类似技能中提取经验,而这些经验将加速我们对于新技能的学习过程.为了在机器学习系统上复现这种机制,研究者们提出了元学习(Meta-learning)这一概念.元学习也被称为学习如何学习(learning to learn),是一门系统地观察机器学习方法在多种学习任务上的性能差异,学习这些经验(元数据)并快速适应新任务的科学[43].
根据元数据类型的不同,文献[43]将元学习方法划分为三类,即从模型评价学习、从任务属性学习和从先验模型学习.第三类方法与深度神经网络的联系更加紧密.FINN等提出的MAML (Model-agnostic Meta-learning)[44]是这类方法的代表性工作.MAML的核心思想是:先在原任务集上学习好的参数初始化,面对不同的新任务,做相应的优化更新.在小样本图片分类任务上,MAML及其衍生方法Reptile、PLATIPUS等的分类准确率排名前列.
结合模仿学习的MAML方法在机器人操作上具有应用前景.FINN等[45]在元更新环节引入了人工示教,在PR2机器人上实现了对未学习物体的放置、抓取操作.在这里,示教是由人远程控制机械臂完成的,示教信息包括了视频和机械臂的测量信号.在后续工作中,YU 等[46]实现了仅利用人手臂本身的动作视频作为示教信息,在PR2机器人和Sawyer机械臂上,实现了推动、抓取-放置等操作.
2.6 模仿学习(imitation learning)
在没有任何先验知识的情况下,采用强化学习处理复杂问题时由于存在较大的搜索空间,往往导致不可接受的学习次数和极大的运算量.因此,学者们开始考虑模仿动物和人类的方式进行学习.首先由某一问题领域的专家(或老师)给出示范,然后学习示范实例,并在此基础上进一步根据自身条件或具体任务不断优化.这种学习途径称为模仿学习或演示学习.
(1)DMPs(dynamics movement primitives)
在机器人领域常用的一种模仿学习是基于2002年由IJSPEERT提出的称为 DMPs的方法[47].DMPs本质上是一种表示运动轨迹的参数化方法,可以通过调节参数来拟合任意形状的轨迹,因此,首先利用DMPs直接拟合演示示例轨迹,然后在此基础上以调节参数作为优化对象,利用强化学习的策略优化方法,如PI2,PoWER等根据实际任务进一步优化.利用上述学习方法,德国Darmstadt技术大学的J.Peters等采用模仿学习的方法,训练机械臂完成了一种被称为ball-in-cup的游戏[48],即把杯子和一个小球用细绳连接,机械臂的末端与杯子固定,通过机械臂的运动带动绳子和球一起运动,并最终使球落入杯中,在此基础上通过进一步强化学习做到了任意条件下的成功操作.
(2)逆强化学习(inverse reinforcement learning)
强化学习是在确定的状态空间下,根据设定的平均函数通过环境反馈从确定的动作集合中得到一组可使评价函数取最优值的动作序列的过程.因此,评价函数起着非常关键的作用,然而,对于一些复杂的问题难以给出确定的评价函数,如教练通过演示教学员打球,司机通过实际操作教学员如何开车.对于此类复杂的问题,人类通过较少的演示实例即可学习其中的机理,然后通过自身大量的反复训练来不断提高应用这些技术的水平.按照这个思路,2000年斯坦福大学的吴恩达(Andrew Ng)提出了基于逆优化学习的评价函数学习方法.基本思路是首先从问题中提取一系列关键特征,把评价函数表示为特征的线性回归函数,以专家给出的若干演示示例作为最优解,利用逆优化学习方法不断优化评价函数的未知参数.在求取未知参数后,即可获得评价函数.然后利用此评价函数在类似的问题中进行求解.由于评价函数和动作空间与专家一致,因此,可以认为学习者已经具备了专家水平.逆强化学习在直升机特技飞行自动控制[49]和四足机器人自主规划[50]等很多项目中获得成功应用.
(3)GAIL(generative adversarial imitation learning)
GAIL 是逆强化学习与深度神经网络相结合的最新成果,最初由JONATHAN 等[51]于2016年提出,主要用于解决如何从专家示例中学习reward函数并应用于深度强化学习的问题.整个系统框架如图4所示.
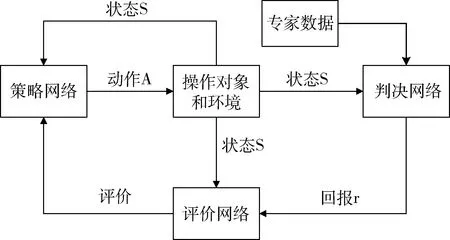
图4 GAIL结构图Fig.4 GAIL diagram
在Actor-Critic框架的基础上增加了判决网络,用于生成一个介于0和1之间的评价信号r(reward).判决网络可以看作是生成对抗网络(GAN)中的判别网络(D),一方面接受专家数据,另一方面接受学员数据(当前系统的输入输出),用于判别学员数据与专家数据的相似度(差异越大输出趋向于0,差异越小输出趋向于1).因此,整个系统的训练目标是在给定某专家行为的基础上,通过训练策略网络与判央网络,使得当前策略网络的输出与专家行为近似.GAIL借助GAN把深度强化学习很好的引入逆强化学习框架中,在训练自主行走、机器人操作、自动驾驶等问题上得到很好的应用.
3 基于学习的在轨燃料补加控制系统研究
为了探索人工智能在在轨服务操作中的应用,我们以深度强化学习为主要工具,开发了一个具备自主学习能力的在轨燃料补加机器人地面试验系统,以解决非结构化环境自主感知和在各种不确定情况下的自主操作问题.
在空间在轨维修维护领域,推进剂在轨补给技术处于核心地位,是带动其他在轨服务技术的先导和基础.卫星推进剂在轨补给是指将推进剂通过特定装备从服务卫星传输至目标卫星的过程,它是延长卫星有效工作寿命、提高卫星经济效益的主要技术手段.未来高价值卫星应配置标准化的推进剂补加接口可接受服务航天器定期的推进剂补给.服务航天器需要具备能自主、快速补加、双向输送、精确控制功能,可对一定轨道范围内卫星实现“燃料快充”.燃料补加装置主要由主动端和被动端及其附属系统组成.自主补加系统的任务目标是由机械臂抓取补加系统的主动端,自主识别安装于模拟卫星端面的被动端,并完成“对接——插入——锁紧——加注——撤出”等整套补加动作.整个过程涉及对非结构化环境的智能感知、路径自主规划和柔顺力触控制等复杂操作.整个系统主要由如下几个部分组成.
(1)物理试验系统
物理试验系统主要由一个UR10工业机械臂(模拟服务星),燃料补加系统(包括主动端和被动端)、模拟卫星端面(模拟受体星)和智能算法服务器组成,如图5所示.机械臂操作系统配置单目手眼相机和6维力传感器.
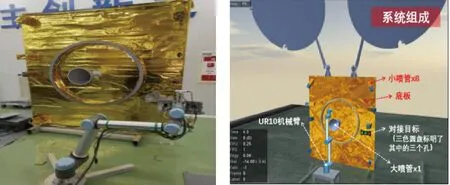
图5 物理试验系统(左)与虚拟学习训练系统(右)Fig.5 The physical experimental system(left) and the virtual learning & training system(right)
(2)虚拟学习训练系统
采用MUJOCO软件搭建了燃料加注数学模拟学习训练系统,为机器人自我训练提供训练环境,具体如上图所示,包括:UR10机械臂(配置单目相机和力传感器)、模拟卫星端面(对接环、490 N发动机、10 N发动机和加注端口、天线等).
系统的整体结构可用图6表示.
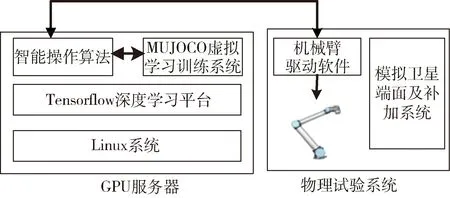
图6 燃料补加系统结构框图Fig.6 The refueling system diagram
(3)基于目标检测与识别的智能感知
本项目采用基于深度学习的Mask-RCNN网络实现对兴趣目标的自主识别与语义分割.目标识别与语义分割是指从复杂的环境中区分出目标图像与背景图像,并与背景分割,本质上是对每个像素自动识别并标注,从而实现目标在整个视觉场景中的精确定位.通过采集样本图像对网络进行监督训练,最终实现了对模拟卫星端面上主要部件(对接环、490 N发动机、10 N发动机和加注端口)的全方位准确分割,精度达到95%以上,如图7所示:

图7 语义分割效果Fig.7 The effect graphs of semantic segmentation
(4)基于深度强化学习的自主规划
本项目采用深度强化学习的标准框架(图3)研究在轨燃料补加的自主规划问题.首先在虚拟学习训练系统中构建几十个机器人进行反复试错训练,使策略网络建立了由单目视觉图像到机械臂运动轨迹的直接映射.然后把训练好的策略网络迁移到物理试验系统中,使机械臂具备端到端的视觉伺服能力.最终末端位置达到±5mm,角度±5°的控制精度,满足插入条件,实现柔顺插入.
本项目利用深度强化学习,成功构建了一套学习训练系统,使机器人从零开始,通过自主训练具备了自主感知和智能规划能力,最终实现了类人的端到端燃料补加全自主操作.

图8 从虚拟学习训练环境训练(左)到物理环境部署(右)Fig.8 The deployment of from the virtual learning & training system(left) to the physical experimental system(right)
4 总结与展望
4.1 面临的技术挑战
考虑到天地环境差异,将基于学习的机器人操作技术运用到空间操作这一领域面临着以下几个方面的问题:
(1)小样本数据问题
深度神经网络对数据的数量、质量要求很高,然而,空间操作任务数量少、天地数据传输成本大,导致真实的数据量(如真实场景图片)非常有限,且地面很难模拟出真实的太空环境,因此,如何在小样本条件下训练高质量的感知和操作策略网络是一个挑战.
(2)鲁棒性问题
鲁棒性问题主要体现在感知和控制两个方面.在感知层次,需要解决同一类样本不同相对位姿下的成像、带遮挡的成像、不同光照条件下的成像等问题.由于小样本限制,会导致感知网络鲁棒性较差.在控制层次,要提高系统的鲁棒性,需要为机器人提供各种可能的训练条件,由于操作场景限制,这些条件不易满足.
(3)测量信息的精度问题
在空间操作任务中,特别是那些复杂、精细的操作,往往对操作精度有极高的要求,例如在燃料加注时,加注枪与加注端的精准对接是成功实现燃料的安全加注的保障,而高精度操作在一定程度上也依赖于精确的测量,对于非结构化场景,需要研究融合视觉、触觉等多种信息的高精度测量问题.
(4)迁移学习问题
迁移学习是学习控制方法的一个核心问题,特别对于深度强化学习来说,主要包括两个方面:一是由虚拟学习训练环境到物理环境的迁移,二是不同任务场景的迁移.由于空间操作环境的限制,机器人需要在虚拟仿真环境下进行大量训练,当把训练结果应用到真实场景时,由于存在视觉、触觉、以及机器人动力学等各种差异,精度会下降很多甚至导致任务失败.其次,如何把一个训练场景下学会的操作策略推广应用到其他场景下相同的任务中,也是考验系统学习能力的一个关键.
(5)快速学习问题
利用强化学习或深度强化学习训练机器人进行操作的关键是回报函数(reward函数)设计问题,Reward函数指导着训练的方向,还与算法收敛性和收敛速度息息相关,设计的好坏直接影响到学习的快慢甚至成败.实践证明对于一些奖惩结果反馈滞后(称为稀疏reward函数)的问题训练起来非常困难,需要耗费大量的时间,甚至无法收敛.因此,研究奖励函数的设计方法或是其他的替代方法是保证基于学习的控制方法在轨服务操作成功的关键.
除了上面提到的问题之外,在空间操作中还存在有限的载荷空间对计算能力限制的问题,能否攻克这个难题对人工智能能否上天起到了决定性的作用.
4.2 未来的研究方向
针对空间操作中所面临的技术挑战,提出以下几个具体的研究方向.
针对小样本问题,研究同分布样本生成技术及不同场景间的自适应学习问题;针对鲁棒性问题,在感知层面研究基于上下文信息的高效神经网络,研究将常识推理、功能推理、关系推理及因果推理等知识与深度学习相结合的新方法,研究目标跟踪方法,在控制层面,研究迁移学习的理论和方法,解决场景差异问题;针对操作精度问题,研究基于深度学习的目标位姿估计、3D场景估计以及多感知数据融合方法;针对迁移学习问题,需要研究新的机制和方法提高学习系统的泛化能力;针对快速学习问题,研究模仿学习、元学习等高效的学习方法;在计算能力的改善方面:可采用网络修剪来简化复杂的网络结构;在计算能力方面,考虑研究FPGA来替代GPU的方案和分布式计算以实现高性能计算.
此外,未来的全自主在轨服务操作有两个发展方向:一是,多模人机共融协作,即航天员与空间机械臂配合,各取所长,共同高效的完成操作任务;二是,多智能体协同.因此,在研究单体机器人学习操作技术的同时,还应重点研究人机混合智能、多智能体自学习协同操作等方向.
致谢:
本文工作得到了中国空间技术研究院张洪太研究员、李明研究员、北京控制工程研究所袁利研究员、黄献龙研究员、刘磊研究员等的指导和大力支持,参与本项目研究的还有北京控制工程研究所唐宁高工、徐栓锋高工、胡勇高工、李文高工、姜甜甜高工等,在此一并表示衷心感谢!
