动态社会网络数据发布隐私保护方法*
2019-09-14董祥祥毕晓迪
董祥祥,高 昂,梁 英,毕晓迪
1.中国科学院 计算技术研究所,北京 100190
2.中国科学院大学,北京 100190
3.移动计算与新型终端北京市重点实验室,北京 100190
1 引言
“社会网络”是指社会个体成员之间因为互动而形成的相对稳定的关系体系,已成为人们沟通交流、获取信息和展示自我的重要途径之一。近年来,随着社会网络的发展,数据泄露事件频发,同时大数据挖掘技术的广泛应用,造成社会网络公开发布的数据和泄露的数据进一步暴露隐私,用户隐私面临威胁。表1 展示了2018 年十大数据泄露事件,其中涉及了使用范围较广泛的国内外社交网站与社交应用。由于这些线上社交网络存储了大量的用户注册与使用信息,具有隐私性,故成为时下数据泄露的重灾区。
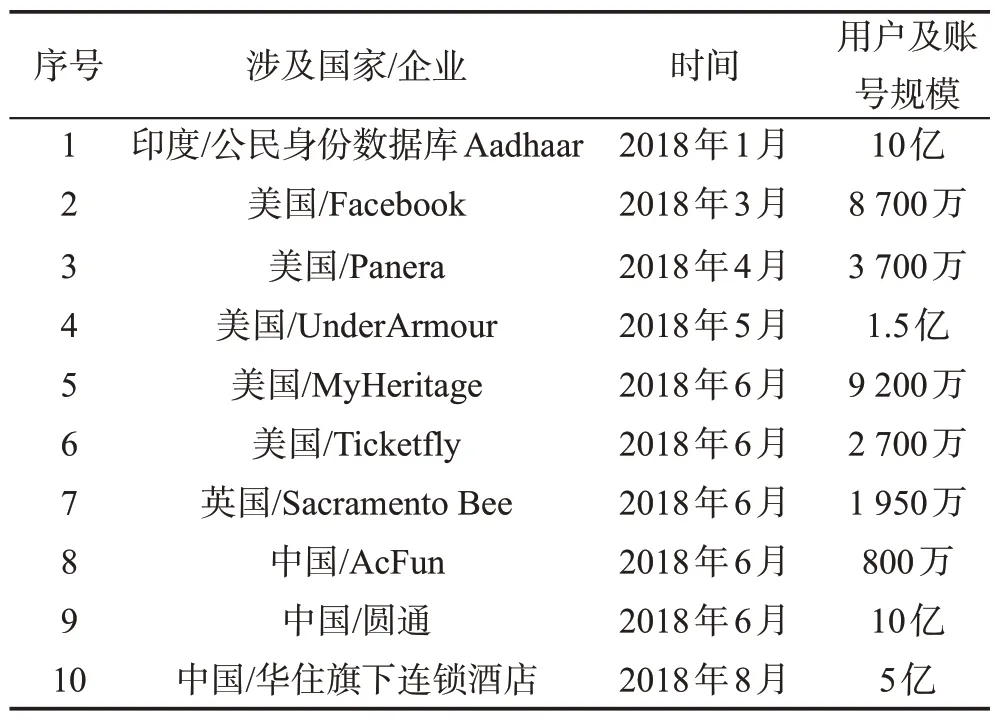
Table 1 10 biggest data breaches of 2018表1 2018年度十大数据泄露事件
据第27 次至39 次《中国互联网络发展状况统计报告》显示(如图1 所示),2011 年1 月至2017 年1 月微博用户量呈现缓慢波动的趋势。这意味着随着用户加入和退出社交应用,社会网络中的节点也存在增加和减少的变化,并且节点间会建立或去除连接关系。
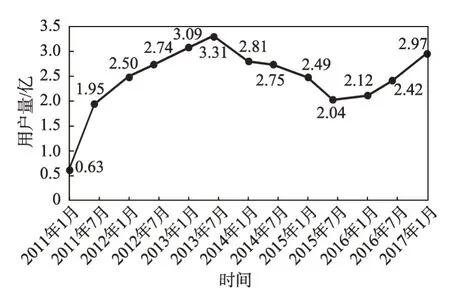
Fig.1 Sina Weibo user statistics图1 新浪微博用户量统计
Viswanath 等人[1]以Facebook 为例进行分析,得出社会网络是具有动态性的,相应的匿名方法也适应随时间变化的性质,具有动态性。社会网络中的数据无时无刻不在进行更新迭代,社会网络的动态性也决定了静态隐私保护方法不能保证动态社会网络的隐私安全[2]。攻击者可以将前后发布版本进行关联分析,可能得到个体的敏感信息,从而会导致社会网络的数据泄露[3]。因此,开展动态社会网络隐私保护方法研究,满足用户的个性化隐私保护需求,同时确保数据的可用性变得非常重要。
社会网络中的隐私信息包括节点、边和图的隐私,这些隐私信息一旦被攻击者获取并进行攻击与挖掘,将会威胁用户自身及其好友的隐私。针对社会网络数据发布的隐私泄露,隐私保护方法可分为静态方法和动态方法。静态方法指社会网络数据单实例发布,即将社会网络的每次更新视作一个新的网络,在新的网络发布时对数据进行匿名处理,隐藏敏感信息,并在发布后不再更改这些数据。而动态方法在新数据发布与匿名时,会涉及已发布的数据,再次对已发布的数据进行处理。
目前社会网络数据发布隐私保护方法多为静态的方法。在节点属性隐私保护研究方面,主要包括传统方法和关注实用价值的方法。如使用原始K-匿名、L-多样性和T-近邻对社交网络用户属性进行属性匿名[4],通过在图中增加噪音节点保护用户隐私,将相似的节点聚类成超节点[5]等。除上述传统的匿名方法,将隐私保护结合其实用价值考虑也受到广泛关注。针对实际问题,Sei等人[6]提出敏感准标识符属性的概念,采用改进的L-多样性和T-近邻的方法可以有效地对敏感准标识符属性进行匿名。Hartung等人[7]改进了NP-Hard问题——K度匿名,用动态规划和启发式方法进行求解,可以高效地应对大规模社会网络的匿名问题,但对数据随机性不敏感。付艳艳等人[8]将社会网络中节点的属性分为敏感属性和非敏感属性,以节点分割的方式保护用户的敏感属性,但其有效性很大程度上依赖于匿名区域内属性是否相关。刘向宇等人[9]提出了一种保持节点可达性的高效社会网络图匿名方法,避免可达性信息损失,但在某种程度上会降低距离查询的精度。节点属性包含了用户的基本隐私信息,上述隐私保护方法在保护节点属性的同时,虽然涉及了图结构数据的可用性,但是对于边的保护不足,存在边信息泄露的风险。在关系和边的隐私保护研究方面,最基础的图结构隐私保护方法是随机图编辑,即在图中进行随机修改或交换边的操作。Hay 等人[10]针对节点再识别和边属性攻击提出了最简单的社会网络匿名方法,仅仅从图中去掉n条边再随机增加n条边,形成新的社会网络图,但是隐私保护强度很低。Li等人[11]使用概率方法对图数据进行随机更改,提出了两种方法,分别为随机稀疏化和随机扰动化,但该方法仅以概率来衡量隐私保护,无法应对有背景知识的攻击。Liu等人[12]将社会网络中边的权重作为隐私保护的对象,在保障图中最短路径序列以及每对节点间的最短距离的同时,通过对边的权重增加高斯噪音进行扰动。Rong等人[13]把K-匿名思想应用到图结构隐私保护中,提出一种K+-同构方法对图数据进行修改,在子图中达到K-匿名状态。
现有动态社会网络隐私保护方法可分为传统的静态社会网络隐私保护移植方法、链路预测方法和增量式抽象方法。Cheng 等人[14]针对节点信息和连接信息攻击,提出K-同构的概念,将节点的标识符进行泛化后发布于社会网络中,可以有效地对节点信息进行保护,但数据的可用性和匿名的质量依赖于同构子图的划分,鲁棒性比较低。谷勇浩等人[15]提出基于聚类的动态图发布隐私保护方法,使用隐匿率作为评价指标,可以抵御多种背景知识攻击,对社会网络图结构变化具有较好的适应性,但算法复杂度较高,执行效率低。Chen等人[16]通过K分组的方法将节点被攻击识别的概率降低为1/k,但并未在真实的社会网络中进行实验,实用性未知。Bhagat等人[17]采用链接预测的方式预测未来图结构,从而对边和节点进行保护,但匿名效果很大程度上依赖于链接预测的质量,保护效果不稳定。郭彩华等人[18]首次提出加权图增量序列K-匿名隐私保护模型,将动态社会网络抽象为加权图的增量序列,提高了算法效率,但边权重的设置方式不具有普遍性。差分隐私作为隐私保护领域的一项重要技术被应用于动态社会网络隐私保护中,但在动态数据发布的应用中面临隐私预算耗尽时噪音骤增的问题。Chan等人[19]通过设置一个阈值来判断当前时刻是否需要进行隐私保护处理,但随时间增长隐私预算会被耗尽。兰丽辉等人[20]提出了一种基于差分隐私模型的隐私保护方法,其实质也是通过对社会网络的结构进行扰动实现隐私保护。
综上所述,社会网络数据发布隐私保护研究主要针对单实例发布的静态网络,即数据发布后不再进行任何改变。而社会网络是一种动态网络,由抽象的数学模型角度来看,动态网络可以认为是一个图快照序列[21]。针对单实例发布的隐私保护方法实际上就是对一个时刻的图快照进行保护,不能适应具有高度动态性的社会网络的更新迭代过程。比如,攻击者可以根据2次单实例匿名的社会网络分析出社会网络图中节点的度信息变化,结合其背景知识进行分析,获取用户隐私。其次,用户的个性化隐私保护方案较少,难以满足数以亿计的社会网络用户的隐私保护需求,用户偏好设置上只考虑了用户隐私保护程度这一单一的偏好,忽略了用户发布的社会网络数据可用性。
本文针对动态社会网络数据发布隐私泄露问题,基于匿名规则研究图数据的隐私保护方法,支持用户个性化隐私需求,抵御数据发布的关联攻击。同时采集了新浪微博数据和公开数据集进行实验,对数据安全性和可用性相关指标进行了评估。
2 定义及流程
2.1 问题提出
社会网络是一种实时更新的、动态的网络。数据发布更新时,可能会和已发布的数据产生数据关联,即使在两个时刻分别对图数据进行了隐私保护,攻击者也可能通过两个时刻的社会网络图进行关联攻击,挖掘其中的隐私信息。假设使用K-匿名技术对社会网络进行隐私保护,k值取2,同时假设同一个匿名集中的节点之间不存在连接关系。T=0,T=1时刻的社会网络图分别如图2(a)中的G0、G1所示,对这两个时刻的社会网络进行匿名后,得到如图2(a)中的所示的社会网络。从图中可以看出,匿名后的社会网络每两个节点被分为一组,同一组节点之间不存在连接关系。但值得注意的是,T=0时,节点(1,2)(3,5)(4,8)(6,7)分别在同一个匿名集中;而T=1 时,节点(1,2)(3,5)(4,6)(7,8)分别在同一个分组中。根据前文所述规则可以进行猜测,节点4与节点6、节点8均可以在同一分组中,但是其不能与节点7 分在同一个组,由此可以推测,节点4与节点7可能存在连接关系。
图2(a)中的G0、G1可以得到验证,上述猜测是正确的,即攻击者利用关联攻击获取了隐私信息。
本文算法目的在于抵御关联攻击所带来的隐私泄露威胁,对图2(a)中的G0、G1进行隐私保护,隐私保护参数设置相同的情况下,得到如图2(b)所示的执行结果,即这两个匿名图中的节点分组相同,可有效抵御关联攻击。

Fig.2 Associated attack schema in dynamic social networks图2 动态社会网络中的关联攻击示意图
2.2 概念定义
为方便阅读,本文常用的符号、公式及字母用表2进行统一说明。
定义1(隐私偏好preference)隐私偏好指用户在社会网络中的个性化隐私保护需求,包括隐私保护强度和社会网络数据可用性的需求,可用二元组表示。其中levels表示用户对其隐私的保护强度需求等级,levelu表示用户对其发布的数据在社会网络中的数据可用性需求等级。levels=0,1,…,N-1,levelu=0,1,…,N-1,N为自然数。levels的值越大,表示隐私保护强度越高;levelu越大,表示社会网络数据可用性越高。

Table 2 Explanation of symbols表2 符号说明
定义2(静态社会网络Gt)静态社会网络特指某一时刻t状态下的社会网络,是一个有向图,可用一个二元组表示,其中:
(1)Vt是t时刻图中所有节点(node)的集合,每个节点代表社会网络中的一个用户,即Vt={node},其中每个node定义为:

式中,uid表示用户唯一id。level表示隐私偏好级别,是隐私保护强度等级levels和社会网络数据可用性等级levelu的函数,可表示为level=f(levels,levelu),
其中f为levels与levelu映射到level的函数。time表示用户加入社会网络的时间。property表示用户属性集合,可表示为property={pi|i=1,2,…,np},其中pi代表用户的一种属性。
(2)Et是t时刻图中所有边(edge)的集合,即Et={edge},本文假设Gt中从nodesrc到nodedest的边代表nodesrc在社会网络中主动产生与nodedest的联系,可表示为:

式中,nodesrc表示Gt中关系的主动产生者,nodedest表示Gt中关系的被动接收者。为了叙述方便,可以使用edgeij表示nodei到nodej的连接边,如在新浪微博中edgeij表示nodei关注了nodej;Gt、Vt表示t时刻静态社会网络图Gt中的节点,同理Gt、Vt表示t时刻静态社会网络图Gt中的边,日常生活中使用的社会网络,在某一时刻数据达到相对稳定状态时,均可视作一个静态社会网络。
定义3(动态社会网络G)动态社会网络是一个有向图集合G:

其中,Gt为t时刻的静态社会网络,t为时间。当时间由t时刻增加至t+1 时刻时,社会网络中可能会出现节点和边数量的增加或减少,节点属性的更新,因此社会网络由当前时刻t的Gt更新为t+1 时刻的Gt+1,一系列时间范围内的静态社会网络则构成了动态社会网络。其中,动态强调了社会网络的结构(包括节点和边)会随时间变化而变化。为了叙述方便,下文中将动态社会网络简称为社会网络。日常使用的社会网络均存在数据的频繁更新,实际上都是动态社会网络。
G中每个时刻的静态社会网络中的节点属性更新时,其隐私偏好也可以更新,故每个时刻的隐私偏好级别(node.level)可以不同,支持用户个性化隐私需求。
定义4(匿名动态社会网络G*)匿名动态社会网络G*指动态社会网络G经匿名算法处理后的,满足某些约束条件的动态社会网络图。即,已知一个动态社会网络G={G0,G1,…,Gt,…,GT},t∈[0,T],称G*=为G的匿名动态社会网络图,其中G*t为t时刻Gt的匿名图,由变换得到。
定义5(匿名规则)匿名规则是隐私保护方法在进行节点聚类时遵循的规则。包括5个规则,其中Vgj为满足匿名规则的节点集合,称作匿名集。
规则1(节点K-匿名规则)
∀Vgi⇒|Vgi|≥k
规则2(属性多样性规则)
∀Vgi⇒Diversity(Vgi)≥L
规则3(时间一致性规则)
∀v,w∈VT,ifv∈Vgi∧w∈Vgi⇒
规则4(关系约束规则)
∀
规则5(边约束规则)
∀Vgi,Vgj,Vgi与Vgj为两个匿名集,m为Vgj与Vgj之间边的数量,且满足m≤(|Vgi|×|Vgj|)/k。
这5 个规则约束了匿名动态社会网络图的状态以及匿名分组过程,其中规则1约束了匿名后的社会网络中,每个匿名集中的节点数量不少于k个,节点识别率不超过1/k;规则2 约束了每个匿名集中的节点属性需要满足L多样性,其中Diversity(Vgi)表示匿名集中节点属性多样性,抵御同质攻击,其计算方法见算法1;规则3 约束了同一个匿名集中的节点都是同一时刻生成的,此规则确保逆向更新的正确性,避免在逆向更新的过程中出现节点缺失的情况;规则4约束了同一个匿名集中的节点不能存在连接边,因为存在连接的两个节点必然存在某种关系,他们的隐私信息存在关联,故同一个匿名集中的节点应减少连接,防止由于分析节点信息造成的隐私泄露;规则5从数学的角度约束了本文的方法,当任意两个匿名集内的节点之间的边数小于某个值时,可保证社会网络图中每条边的隐私泄露概率不超过1/k。综上所述,经过上述5 条规则匿名后的动态社会网络,在一个稳定的时刻,其节点和边被识别的概率均不大于1/k。其证明过程如下:
首先,每个匿名集中的节点数至少为k个,则每个节点被唯一识别的概率至多为1/k,且同一个匿名集中的节点属性满足L-多样性,保障了节点被识别的概率不超过1/k;其次,同一个匿名集中的节点不存在连接边,则边的起点或终点至少有k个可能的节点;接下来本文定义边的识别率EI,代表当前社会网络图中真实存在的边占全部可能边的比重,其计算公式如下:
EI=|(Vgi×Vgj)⋂Et|/(|Vgi|×|Vgj|)
令m=|(Vgi×Vgj)⋂Et|,即Vgi、Vgj之间t时刻连接边的数量,可以得出:

综上所述,当社会网络处于某一确定的时刻时,节点与边的识别率均不大于1/k。
定义6(T时刻匿名图)T时刻匿名图为满足匿名规则1~5的二元组,其中:
2.3 主要流程
本文设计了基于匿名规则的动态社会网络图数据隐私保护方法,在数据发布阶段对社会网络数据进行匿名处理,以保护用户隐私。为了抵御关联攻击,在每次数据更新时,通过图的差集对已发布的数据进行逆向更新。

Fig.3 Flow chart of method图3 方法流程图
图3 展示了动态社会网络图数据隐私保护方法的全部执行过程。首先进行个性化参数计算,判断是否符合匿名条件,若符合匿名条件则进行数据更新,接收T时刻的社会网络数据。然后根据属性优先级进行节点排序,得到一个有序节点集合。接下来根据本文所定义的匿名规则进行节点聚类,得到若干匿名集,每个匿名集中包含若干节点。进而计算T时刻数据连接关系生成匿名图。最后根据不同时刻图的差集,逆向更新已发布的数据。具体步骤如下:
步骤1T时刻接收动态社会网络中更新的数据,加入到时间窗口中。
步骤2判断时间窗口是否符合时间窗口大小设置,若符合,进入步骤3;否则返回步骤1。
步骤3判断时间窗口内的数据是否符合匿名阈值大小设置,若符合,进入步骤4;否则返回步骤1。
步骤4对当前社会网络中的节点属性的优先级排序。
步骤5对当前社会网络中的节点依据匿名规则进行节点聚类。
步骤6删除当前时刻社会网络中不是同一时刻生成的边,得到当前社会网络的匿名图。
步骤7对于t∈[0,T-1]时刻的社会网络数据,删除与当前时刻不属于同一时刻生成的数据,进行逆向更新。
上述步骤描述了一次完整的包含时间窗口和匿名阈值的基于匿名规则的动态社会网络图数据隐私保护方法,下文将进行详细介绍。
3 动态社会网络图数据隐私保护方法
3.1 隐私保护参数计算
为了支持用户个性化隐私保护,本文设置了两个隐私保护参数,分别为时间窗口和匿名阈值。用户的隐私偏好经函数计算得到隐私偏好级别level,时间窗口和匿名阈值的取值随level的变化而变化。
3.1.1 时间窗口
由于社会网络图数据隐私保护针对的是社会网络这个整体,不能由单一的用户作为社会网络隐私保护级别的决策者,故本文以网络中所有用户作为隐私保护级别的设置者。社会网络中节点的度反映了用户与其他用户的关联情况,一个用户的度越大,说明其与其他用户产生越多的联系,若此用户的隐私信息泄露,可能会危及很多用户的隐私。故本文使用加权的方式来度量社会网络中的平均隐私偏好级别levelaverage,计算方法见式(4)。
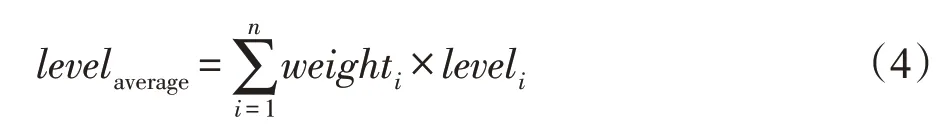
其中,weighti表示用户i的度所占权重,weighti=表示用户i的度,leveli表示由用户i的隐私偏好所计算出来的隐私偏好级别。
本文设置了两个隐私保护参数。其一为时间窗口(time window),它代表实际执行图数据更新的时间间隔。由于图数据是流式更新的,无法保证数据每次更新时的时间。然而,每当有数据更新时就进行图数据匿名对于数据量庞大的社会网络来说是很大的开销,但长时间不对数据进行处理则会增大用户隐私泄露的风险。故本文使用时间窗口来进行衡量,由社会网络中的平均隐私偏好级别确定。其计算公式见式(5)。其中window表示基础匿名窗口,单位为秒(s),window=0,1,…,N,N为自然数。
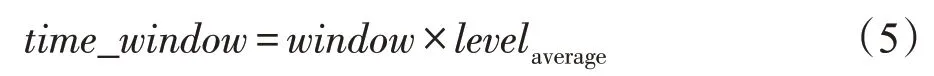
3.1.2 匿名阈值
匿名阈值(cost threshold)代表当前社会网络已更新的数据量。由于社会网络数据的匿名过程包含逆向更新过程,若每当社会网络中数据有更新时就进行匿名,会增大网络中的时间开销,但是数据大量积累会造成用户隐私泄露。故本文使用匿名阈值来计算当前网络中已更新的数据量,若此数据量小于阈值,则不进行匿名。其计算公式见式(6)。其中threshold表示基础匿名阈值,threshold=0,1,…,N,N为自然数。
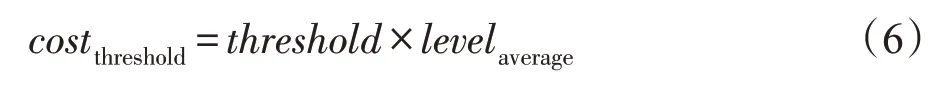
至此,本文得到了用于图数据隐私保护的参数。
3.2节点聚类
节点聚类是把社会网络中的节点聚类成若干个超级节点(称作匿名集),每个超级节点至少包括k个节点,并对超级节点的属性进行泛化处理,达到隐私保护的目的。本文遵循定义5 的匿名规则进行节点聚类,不仅确保节点和边的再识别攻击概率小于1/k,同时兼顾节点的属性多样性,抵御同质攻击。
社会网络中,每个节点都可能存在若干个属性property={pi|i=1,2,…,np},这些属性可能是敏感信息,导致用户隐私泄露,比如用户在社会网络所填写的职业可能推理出其可能的工作单位;其兴趣爱好可能会反映出他的社交圈。本文对于用户的属性进行K-匿名和L-多样性保护,即匿名后的社会网络中,对于每一个匿名集中至少有k个用户,且同一个属性的取值满足至少有L个。然而在实际的社会网络中,几乎不可能找到两个一模一样的节点,因为用户所填写的属性信息无论是内容、句式还是结构都会有区别,故本文使用SimHash语义指纹[22]来衡量不同用户的属性之间的相似程度。SimHash 算法的特点是语义指纹包含了文本特征的散列值。相似的文本有相似的散列值,不同于MD5 等加密方式中细微的差别都会映射为不同的指纹,相比于MD5 等方式只能排查完全重复的文本,SimHash的应用范围更广。
本文将每个属性作为一个token,为其分配权重后按如下步骤进行处理,可以得到文本的语义指纹[23]:
(1)将一个f维的向量V初始化为0;f位的二进制数S初始化为0。
(2)对每一个特征,用传统的Hash算法对该特征产生一个f位的签名b。对i=1 到f,如果b的第i位为1,则V的第i个元素加上该特征的权重;否则,V的第i个元素减去该特征的权重。
(3)如果V的第i个元素大于0,则S的第i位为1,否则为0。
(4)输出S作为语义指纹。
文本的语义指纹S均为f位的二进制字符串,度量两个文本之间的相似程度使用的是海明距离。海明距离是两个字符串对应位置的不同字符的个数。两个文本越相似,其海明距离越小。该算法被应用于Google 搜索引擎的网页相似度检测中,指纹长度为64 bit。由于用户在社会网络中填写的属性信息基本为短文本,其粒度与分词后的文本基本无差别,故本文将用户在社会网络中所填写的每一个属性信息视作一个特征,进行语义指纹的计算。当用户的属性更新后,重新计算语义指纹。相对于网页中的文本,用户属性的文本数量会少很多,因此本文取f=32,使用32 bit 语义指纹进行相似度判断。进行节点聚类时,为了保障每个匿名集中的节点具有L-多样性,本文使用算法1计算一个匿名集中的属性多样性。
算法1属性多样性计算算法Diversity

算法中的hammingDistance 用于计算两个语义指纹的海明距离。算法的输入为一个有序节点集合Vx,以及判断两个语义指纹是否相似的距离阈值minDis,针对每一个节点集合,若存在任意两个节点的语义距离大于阈值,则认为增加了集合中的多样性。算法的时间复杂度为O(n2),n为集合Vx的大小。
3.3 连接关系计算
节点聚类后生成了一系列匿名集,匿名集中包含若干节点,本节将介绍边的连接规则,将匿名集中的节点进行连接,生成匿名图。
边连接规则:
规则1生成连接边集合
规则2若存在node.degree=0,生成连接边
上述边连接规则描述了如何用匿名集中的节点生成边构成匿名图。规则1 描述了图中的真实节点的边的生成规则,对于一个真实节点在候选补图的边集中筛选出所有与它相连的边,即以node为起始节点或终止节点的连接边。规则2 描述了图中噪音节点的边的生成规则,对于一个噪音节点,若存在与不在同一个匿名集中的噪音节点,且该节点的度为0,即未与其他节点产生连接关系,则构造一条以为起始节点,为终止节点的连接边。
图4中展示了两个匿名集,匿名集1中所有节点的tag均为{1,3},其中1号为真实节点,3号为噪音节点。同理,匿名集2 中所有节点的tag均为{2,4},其中2号为真实节点,4号为噪音节点。图中所示,真实节点只能与和其具有原始连接关系的真实节点相连接,而噪音节点只能与和其不在同一个匿名集中且符合度数要求的噪音节点相连接。

Fig.4 Diagram of connection rules图4 边连接规则示意图
3.4 匿名图生成与逆向更新
对于T时刻的社会网络图GT,候选补图和边连接规则生成匿名图与基于图的差集进行逆向更新的方法见算法2。
算法2匿名图生成与逆向更新算法
输入:G={G0,G1,…,Gt,…,GT-1},UpdateGraph,ksets,k。

4 实验及效果评估
4.1 实验数据
实验收集了新浪微博169 246 个用户的属性数据和4 485 488条关注关系。为了模拟社会网络的动态更新过程,本文通过随机增删的方式,模拟社会网络中节点、边的增删过程,并进行多次迭代;除此之外,还获取了SNAP公开的欧洲某研究中心986个用户的332 334 条邮件往来信息(https://snap.stanford.edu/data/email-Eu-core.html),包含邮件收发的相对时间,可直接用来更新动态社会网络。
4.1.1 社会网络用户关注关系网络分析
为了评价隐私保护方法的数据安全性与可用性,本文采集了2009 年8 月至2012 年10 月期间的新浪微博169 246 个用户的2 031 393 条属性数据和4 485 488条关注关系数据进行实验。
为了更加真实地模拟社会网络数据动态更新的过程,结合《中国互联网络发展状况统计报告》(第27次至39 次)发布的2011 年1 月至2017 年1 月期间的新浪微博用户量的真实变化趋势,拟合了图5所示的用户量随时间变化的数据曲线。其含义为12个月内新浪微博用户量随时间变化的趋势,其中图5(a)约涉及1 600名用户,图5(b)约涉及10 000名用户。为了模拟准确,使用了6 次方程进行拟合,其公式分别为y1=-0.037 3x6+1.582 9x5-25.813x4+208.14x3-913.48x2+2 266.9x-1 218.1,(如图5(a)所示);y2=-0.224 1x6+9.497 1x5-154.88x4+1 248.8x3-5 480.9x2+13 601x-7 308.9,(如图5(b)所示)。
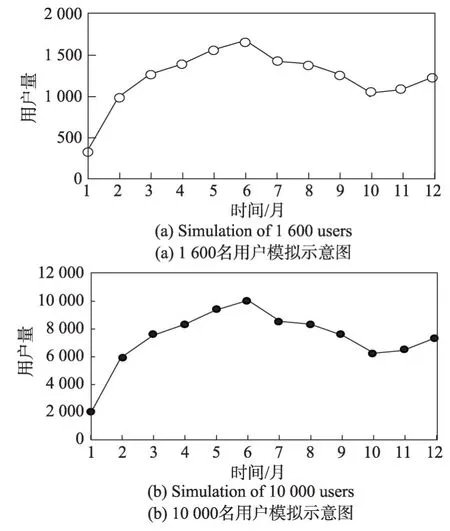
Fig.5 Changes in user quantity over time图5 用户量随时间变化曲线
本实验中将进行12 次迭代,即x=1,2,…,12,得到社会网络中用户总数,每次迭代的过程中,随机删除部分节点及与其相连的边,再随机增加节点与边,达到拟合曲线的标准。为了能够充分利用社会网络中的关系数据,采用广度优先搜索的方式,首先选取一个种子节点,然后搜索与此种子节点相连的节点,依次加入到实验集合中,接下来进行第2轮广度优先搜索,直到实验集合中的节点个数满足上述公式,最后执行匿名算法,对社会网络数据进行保护后发布。本实验将会记录x=1时刻的原始社会网络,记为G0,在每次迭代并逆向更新之后记录,共可以得到12个
4.1.2 社会网络邮件收发关系网络分析
新浪微博数据虽然属于典型的动态社会网络,但未记录用户在社会网络中行为数据(更新上述属性)的时间信息。为了验证本文方法适用于动态社会网络中数据真实的更新情况,选取了由SNAP所提供的欧洲某研究机构由2003 年10 月至2005 年5 月(共18 个月)期间的邮件往来数据,共986 个用户的332 334条邮件往来信息。每条数据包含一个时间戳,其含义为距相对起点(时间戳为0)间隔的秒数,可以按照时间戳信息还原邮件网络的动态更新过程。
本文对邮件数据度-用户数进行了统计,结果如图6所示。其中度数最小值为1,最大值为10 571,平均度数为337。度的取值共604 种情况,平均每种情况约有1.6个用户。此数据集中,用户数随度数的增加迅速减少直至趋于平缓,其分布基本符合幂律分布。

Fig.6 User quantity-degree statistics of email data set图6 邮件数据集度-用户数统计
由于此数据集中包含时间戳,为了更好地还原动态社会网络数据更新的过程,本文对时间戳信息进行了统计,时间戳的相对起点为0,每隔1 s增加一个时间单位,相对终点为45 405 138,邮件发送的最小时间间隔为0 s,最大时间间隔为58 s,平均间隔为0.625 s。图7展示了邮件发送的时间间隔统计情况,可以分析出,时间间隔-邮件数分布同样符合幂律分布。

Fig.7 Time interval-email quantity statistics图7 时间间隔-邮件数统计
4.2 评价指标
本文将从数据安全性和数据可用性两方面评价算法的有效性,评价指标见表3。
4.3 结果分析
理论上,根据K匿名算法的性质,k值越大,匿名性越好,安全性越高;数据发布时间点越密集,间隔越短,图更新的速度越快,可以执行更多次的匿名方法,匿名性也越好;网络中节点与边的数量也会影响匿名性。当节点数量和边增加时,需要更大的k值进行保护。在节点数量不够,数据发布时间间隔较长的情况下,本文算法会通过增加随机节点的方式保证匿名性,具体的匿名程度和算法中选取的k值有关。
4.3.1 社会网络用户关注关系网络分析
本文使用新浪微博的用户属性数据进行模拟实验,将每个用户视作社会网络中的一个节点,用户间的关注关系视作社会网络中的有向边,起点为关注者,终点为被关注者。每个用户选取节点id为用户的唯一标识,除此之外选取5个用户属性作为节点排序的依据,分别为性别、所在地区、描述、用户标签和教育信息。
由于新浪微博数据集中不存在用户更新属性信息、用户关注关系的具体时间,本文采用模拟的方式,将全部数据集视作全集。在数据更新的过程中,第1次数据更新时,随机选取M个节点及其之间的连接关系作为原始社会网络,称这个过程为初始化。在之后的每次数据更新过程中,随机去掉N个节点以及与这些节点相关的边,并从全集中随机增加P个节点,以及相关的边,得到一次更新后的数据。其中M、N、P为合法的随机数即N≤M,其余参数无约束条件。
(1)数据安全性
为了衡量不同隐私保护参数下的隐私保护效果,将对200个节点的社会网络进行匿名,计算k值为3~10 时的匿名率,通过匿名率来判断数据安全性。如图8所示,随着k值的增加,匿名率呈现增长趋势。可知随着k值的增大,数据的安全性逐渐增大,当k=10时,匿名率约为26%。
为了验证本文算法的属性多样性的设置效果,分别在使用与不使用属性多样性的条件下进行了实验,对比属性多样性在算法中的作用。本文设置当两个节点的属性语义指纹距离小于H时,认为它们为相似的,不会增加多样性,执行匿名算法后,统计每个匿名集中语义指纹的多样性,实验结果如图9 所示。其中,H=5,选取100个节点及其相关的边,k值取10,不设置L值,算法结束后未增加噪音节点,故产生的多样性均为节点的真实属性匿名后的结果。
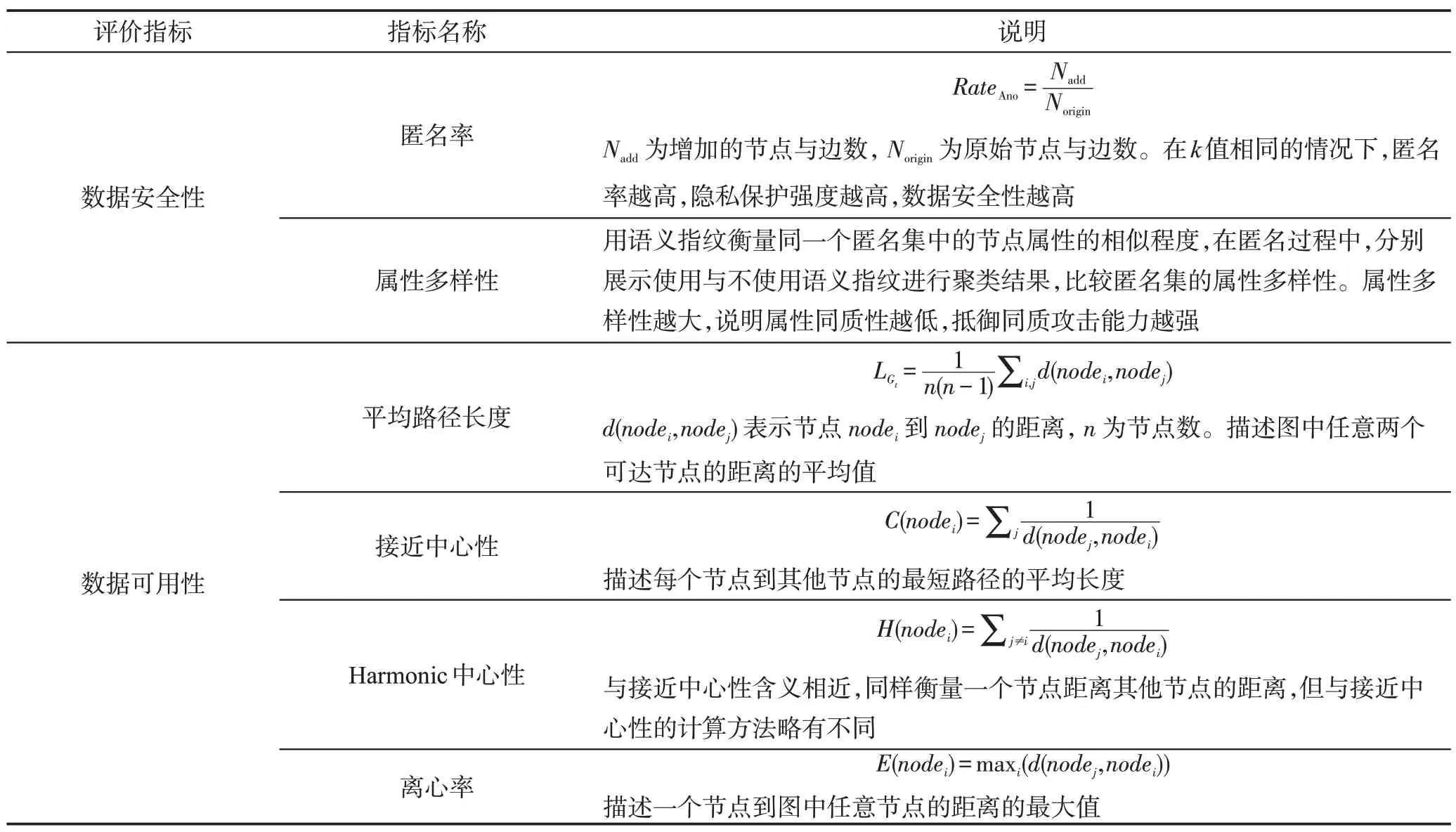
Table 3 Evaluation indexes表3 评价指标

Fig.8 Anonymity rate statistics of Sina Weibo data set图8 新浪微博数据集匿名率统计

Fig.9 Semantic fingerprint and diversity result图9 语义指纹与多样性结果
由图9可知,从多样性、海明距离两个指标来看,含语义指纹计算出的匿名方法基本优于不含语义指纹的情况。其中平均海明距离为同一个匿名集中的节点属性两两之间的距离平均值,最大最小距离虽有一定的偶然性,但使用语义指纹的方法效果普遍更好。多样性方面,通过语义指纹的设置,提高了同一个匿名集中属性的多样性。
除此之外,本文测试了数据安全性与迭代次数的关系,使用新浪微博数据进行两组实验,分别进行12轮迭代,并使用聚集系数、中介中心性作为衡量指标,分别记录了测量值与匿名前后的变化率。结果如图10 所示,图10(a)展示了原始图与经过12 次迭代的匿名图的聚集系数和中心中介性变化率统计结果,两项指标随着图数据的迭代而变化。随着迭代次数的增加,聚集系数变化率和中介中心性变化率均呈现上升趋势,说明数据安全性与迭代次数呈正相关关系,进一步说明本文所述方法在图数据匿名后可以在图结构上产生差异性,保护原始图结构。图10(b)展示的是10 000名用户的模拟实验结果,本文方法对于大数据集同样可以进行扰动,保护社会网络数据隐私。但由于数据量大,在变化数量相对稳定的情况下,变化率结果略低于小数据集实验。

Fig.10 Data security of Sina Weibo data set图10 新浪微博数据集安全性
(2)数据可用性
按照4.1 节中的模拟方法,本文使用新浪微博数据集进行两组实验,分别进行12轮迭代,以接近中心性、harmonic 中心性、平均路径长度和离心率等指标测试数据可用性。
图11(a)至图11(d)分别展示了两组数据的原始社会网络图与经过12 次更新及匿名后的评价指标。由图11(a)与图11(c)可知,两组数据经匿名后,四种衡量指标均呈现波动性变化,对原始图数据产生了扰动。由图11(b)与图11(d)可知,两组数据匿名后的四种变化率除平均路径长度外,不超过15%,从图中节点间距离的角度来衡量,保持了数据可用性。与前文所述类似,由于相同的变化量在小数据中产生的变化率更大,故小数据集实验的变化率略高于大数据集。
4.3.2 邮件收发关系网络实验结果分析
社会网络是一个动态网络,数据的更新迭代的时间不可控,它由用户参与社会网络的时间、频率和动作决定。仅仅通过模拟动态社会网络生成的方式是不能够完全展现其更新迭代过程的,也不能验证算法的有效性。故本文使用欧洲某研究机构的邮件往来数据进行实验,按照邮件的收发时间进行社会网络的动态更新,体现时间窗口、匿名阈值的作用与算法的实用价值。
(1)数据安全性
通过统计k值为3~10 时的匿名率来衡量数据的安全性。如图12 所示,匿名率随着k值的增大而增大,社会网络数据的安全性逐渐增大。
本实验从数据集中按照时间顺序进行图数据的动态更新,参数设置为:时间窗口为86 400 s,匿名阈值为0,即对于每一轮数据更新都进行匿名,进行10次迭代。对比匿名后的图数据与网络初始化时的图数据结构的差异性,使用聚集系数、中介中心性及它们的变化率来衡量图结构的变化。
由图13(a)可知,本文方法可以对真实数据集进行图数据匿名,在不同的迭代中产生不同的匿名效果。图13(b)中的变化率显示,当迭代次数为10 时,聚集系数与中介中心性的变化率分别约为40%和60%,对原始数据产生了扰动。且随着迭代次数的增加,变化率逐渐增大。
(2)数据可用性
为了验证本文方法在真实的动态社会网络隐私保护中依然有效,与之前实验类似,使用接近中心性、harmonic 中心性、平均路径长度和离心率等指标进行方法验证。本实验从数据集中按照时间顺序进行图数据的动态更新,参数设置为:时间窗口为86 400 s,匿名阈值为0,即对于每一轮数据更新都进行匿名,进行10 次迭代。对比匿名后的图数据与网络初始化时的图数据的差异性,结果如图14所示。
图14(a)中接近中心性、harmonic中心性、离心率和平均路径长度这4 项指标在数据迭代的过程中均有不同程度的变化,说明本文方法在真实数据集中也可产生效果。图14(b)中的变化率指标表明,随着数据的更新,除平均路径长度外,各项指标的变化率均在10%以内,保持了较好的数据可用性。平均路径长度由于图结构的变化,产生了相对较大的变化。
5 结束语
目前,社会网络中用户个性化隐私保护主要针对单实例发布的静态网络,不能适应具有高度动态性的社会网络的更新迭代过程,不能保证社会网络的隐私安全。本文开展了动态社会网络数据发布个性化隐私保护研究,提出基于匿名规则的图数据隐私保护方法。使用新浪微博数据和公开数据集验证,实验结果表明本文方法兼顾了用户数据隐私保护和数据可用性的个性化需求。
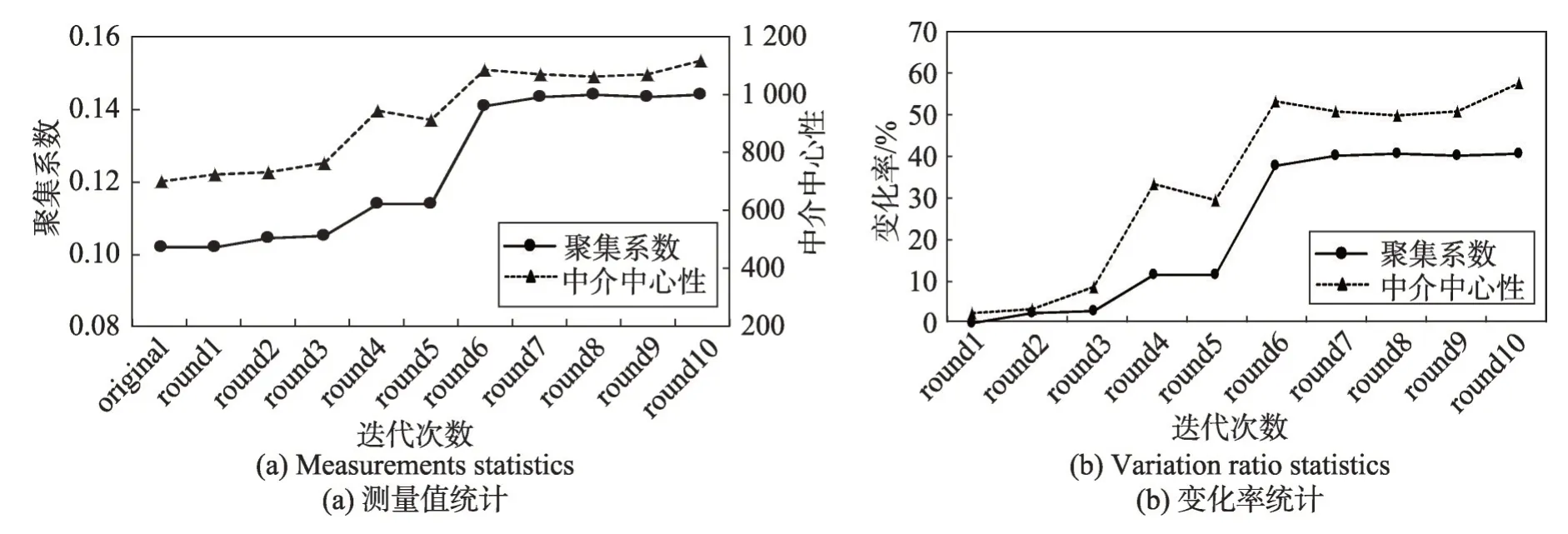
Fig.13 Data security of email data set图13 邮件数据集数据安全性

Fig.14 Data availability of email data set图14 邮件数据集数据可用性
未来研究工作将基于多维度用户隐私保护方法开展深入研究,构建多特征的联合匿名保护方案,构建隐私保护方案安全评价体系,为用户提供更加可靠的社会网络环境。
