基于自监督深度学习的人脸表征及三维重建
2019-09-11刘成攀
刘成攀, 吴 斌, 杨 壮
(1.西南科技大学 信息工程学院,四川 绵阳 621010; 2.特殊环境机器人技术四川省重点实验室,四川 绵阳 621010)
0 引 言
三维人脸重建能通过稠密人脸对齐获取三维几何特征解决二维人脸的大姿态和遮挡等挑战,是计算机视觉中基础且备受关注的任务。
传统三维人脸重建主要基于优化算法,如迭代最近点[1]获取3DMM模型系数进而利用单个脸部图像渲染相应的三维人脸。然而这些方法存在复杂度高、耗费时间长、难以寻找局部最优方案以及初始化效果差的问题。随着卷积神经网络的发展,利用神经网络来学习回归3DMM系数显著改善了三维重建的质量和效率。文献[2]提出的端到端带有新型损失函数的卷积神经网络(3DDFA)改善了大姿态下面部人脸对齐的性能。文献[3]提出密集脸对齐(DeFA)并用多个约束和多个数据集实现了非常稠密的三维人脸面部对齐结果。文献[4]提出基于直接体积回归的单幅图像大姿态三维人脸重建方法(VRN),绕过3DMM的构造和匹配,却需要大量时间来预测体素信息。文献[5]提出位置映射回归网络(PRN)的端到端的方法,直接从单个图像重新获得完整的三维面部形状以及语义信息并预测密集对齐。尽管上述方法高效,但构建UV映射的方法却很复杂。最近,文献[6]提出的二维辅助自我监督学习的算法(2DASL),有效利用二维人脸中的嘈杂地标信息显著改善三维人脸面部模型学习,在三维面部重建和密集面部对齐方面取得了很高的性能。
除了VRN和PRN,大部分方法都是利用卷积神经网络回归估计3DDM参数。但它们都面临同重建的三维模型由于人脸姿态变化不能很好表征区分个体。目前流行的基于3DMM的方法只考虑一对一重建过程,而不考虑输入图像的相关性或差异,这使获得的结果对于人脸表征不可信。
为解决这一问题,本文提出一种新的基于自监督深度学习的人脸表征及三维重建算法,基于EfficientNet—B4设计孪生(Siamese)神经网络并引入多个损失函数进行多对一训练,使不同姿态下同一个体的不同几何形状被约束为相同身份并保留,对3DMM参数学习的过程更有鲁棒性。
1 算法原理
1.1 三维形变模型
三维形变模型3DDM提供了三维人脸形状参数S∈R3N,S储存线性组合关系的N个网络格点的三维坐标[8]。人脸形状满足如下函数关系
(1)
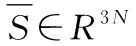
V(g)=f×Pr×R×S+t2d
(2)
1.2 EfficientNet-B4
Google在2019年ICML会上提出一种新的简单高效模型尺度缩放方法,使用固定的缩放系数集合,均匀地缩放每个维度[10]。模型的三个互连超参数的加权比例为—输入的分辨率r、网络的深度d和网络的宽度w。借助这种新的缩放方法,选取残差神经网络Resnet—50为基线网络进行复合缩放,d,w,r分别设置为4,2,2。
1.3 孪生神经网络
整体框架如图1,将EfficientNet—B4作为孪生神经网络的骨干,最后两层被替换为并行全连接层,一层输出为62维的3DMM参数,另一层是用于面部识别的512维人脸特征向量。
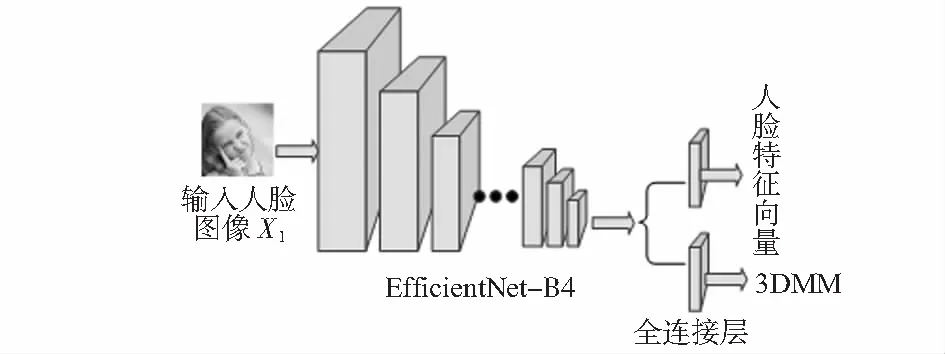
图1 整体框架
孪生神经网络如图2,最左边为输入X1和X2,W为学习得到的共享参数向量,GW(X1)3d和GW(X2)3d为回归的3DMM参数。特征空间中,GW(X1)id和GW(X2)id为输入面部图像的两种表示。从GW(X1)3d和GW(X2)3d中各选50个元素作为形状参数GW(X1)shp和GW(X2)shp。通过以下3个损失函数训练整个模型。
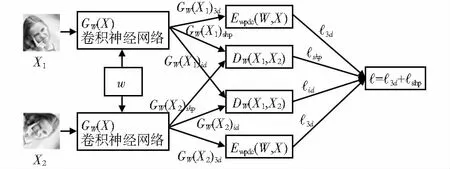
图2 孪生神经网络
第一个是三维标注图像的加权系数预测损失函数,用于衡量模型预测3DDM系数时的准确性,第二个是约束损失函数,用于减小脸部受姿态形变的影响,第三个是身份损失函数,用于确保同身份的人脸在特征空间中具有相似分布。因此,整体的训练损失函数为
(3)
1.4 损失函数
1.4.1 加权参数距离损失函数
根据3DMM参数中不同参数的重要程度引出公式
(4)
(5)
Q=diag(q1,q2,…,q62)
(6)
(7)
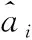
1.4.2 对比损失函数
参数化距离损失函数DW为GW(X1)shp和GW(X2)shp欧氏距离
DW(X1,X2)=‖GW(X1)shp-GW(X2)shp‖2
(8)
将DW(X1,X2)简写为DW,损失函数描述如下
(9)
(1/Y){max(0,m-DW)}2
(10)
式中 (Y,(X1,X2)j)为第j个标记的样本对,X1和X2为输入图像对,若X1和X2都属于同一人则Y的值为1,否则Y的值为0,P为训练对的数量,m为边距。
对输出GW(X1)id和GW(X2)id采用相同损失函数,唯一区别在于DW(X1,X2),其被如下定义
DW(X1,X2)=‖GW(X1)id-GW(X2)id‖2
(11)
2 实验与结果分析
2.1 训练和数据集
深度学习框架选择Tensorflow,选用随机梯度下降SGD作为优化器,神经网络回归的学习率呈指数衰减。初始化训练损失函数的学习率3d,shp,exp分别为1×10-2,1×10-3,1×10-4,批量大小设置为32。采用两阶段策略训练模,在第一阶段采用3d损失函数训练,第二阶段采用总损失函数训练。
300W—LP数据集包含超过60 000张带3DMM系数注释的人脸图片,共7 674个人,每个人有90张不同姿态的照片[11]。将数据集分为两部分,选取7 036人共计630 694张图片作为训练集,638人共57 160张图片作为验证集。输入图像尺寸为112像素×112像素。在训练期间,以相同概率生成成对真实和假冒人脸图片。
测试数据集包括两部分,一部分来自验证集(TEST1),用于评估三维重建和识别的鲁棒性,另一部分为AFLW2000—3D(TEST2),用于评估三维重建的准确性。
2.2 三维人脸重建效果分析
首先用标准严格迭代最近点(ICP)的算法[12]重建三维人脸并全局对准真实值。接着计算归一化的参考长度的坐标偏差衡量指标NME。最后,分析在不同姿态下NME分配情况并画出箱线图见图3(a)(深色表示文中的方法,浅色表示3DDFA算法)。该方法箱形图宽度比3DDFA窄,表示在姿态变化下重建模型受形变影响小。图3(b)显示在TEST2上两种算法的比较结果,本文算法实现了36.13 %的NME,略低于3DDFA的NME(36.16 %),表明在人脸重建上比3DDFA略好一些。
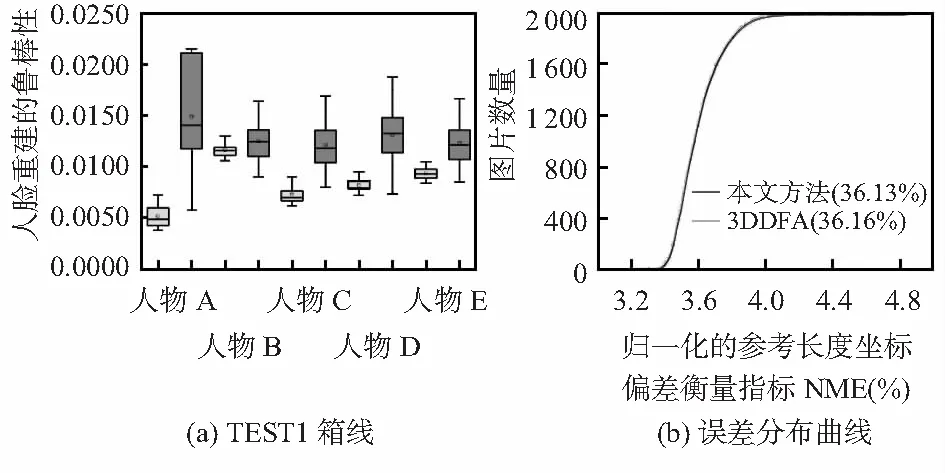
图3 TEST1箱线与TEST2误差分布曲线
2.3 在有限条件下的人脸重建效果分析
选取有表情干扰图片进行实验,效果如图4(从左至右依次为原图、3DDFA效果图、本文算法效果图),相比3DDFA算法,本文算法构建的三维模型受到表情干扰更少。

图4 实验效果图对比
从TEST1中随机取6 000对图像,其中,包含3 000真实对和3 000假冒对,随机拆分数据集进行10次交叉验证。如图5所示,该算法达到了97.92 %的识别率。
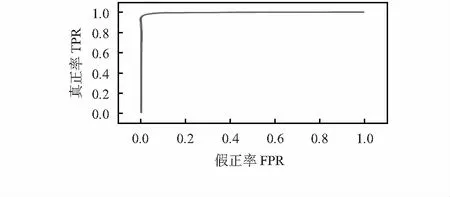
图5 TEST1上的ROC曲线
3 结 论
本文采用一种新颖的算法用于增强三维人脸重构精确性。将EfficientNet—B4作为主体框架提取3DDM参数和人脸特征向量。除此之外,引入3个损失函数增强面部重建的鲁棒性,保留面部重建输入图像的身份信息。实验表明:该算法在三维人脸重建和二维人脸识别上比3DDFA表现更为出色。
