基于分布式网络爬虫的Web空间数据获取方法研究
2019-09-10冯玲黄亮曾李阳朱齐华
冯玲 黄亮 曾李阳 朱齐华


摘 要:本文針对单机网络爬虫获取Web空间数据在抓取覆盖率和抓取效率上均受到一定程度的限制,难以保证所抓取数据的及时性以及全面性问题,研究了基于分布式网络爬虫的Web空间数据获取方法,设计了基于分布式网络爬虫的Web空间数据获取原型系统并且最终实现,并且通过对原型系统进行相关的测试来证实了本文所提出解决方法的有效性。
关键词:Web空间数据;分布式网络爬虫;原型系统
中图分类号:P208
文献标识码: A
GIS是一门以数据为基础的学科,空间分析、空间统计和空间数据挖掘等研究都离不开空间数据的支撑,而互联网中存在海量空间数据,这些数据与人们的日常生活活动密切相关并且包含的信息量十分丰富、现势性极强。如果能够对互联网中广泛存在的空间数据高效地进行获取,一方面可以补充基础地理信息的不足,提供丰富的细节和准实时更新,另一方面还能够为GIS空间分析和空间数据挖掘提供信息量丰富、高时效性的数据源。
Web空间数据获取主要采用网络爬虫技术,国内外许多学者在这方面进行了研究。Leasure D R指出,利用网络爬虫技术,可以丰富GIS空间分析的数据来源[1]。 Tezuka T等研究提出的网络爬虫技术降低了Web空间数据获取的难度[2]。Zhang C J提出了基于网络爬虫技术的地名地址库更新方法[3]。Hua ̄Ping Zhang等研究了从互联网新闻报道中自动提取POI数据的方法[4]。Li W研究了基于网络爬虫的OGC服务发现方法[5]。Chen X基于网络爬虫实现了自动化发现和检索WMS服务[6]。Jiang J研究了检索WFS服务的网络爬虫[7]。王明军在普通网络爬虫技术基础上提出了空间敏感爬虫的思想体系,并从多个方面对其进行了阐述[8]。蔡地在研究开源网络爬虫框架的基础上,提出通过多线程和异步I/O两种策略来优化Web空间数据的获取效率[9]。Ager A则在研究中指出,如果能够对Web空间数据进行有效的利用,将对GIS的发展产生深远的影响[10]。
通过分析国内外研究现状发现,目前基于网络爬虫的Web空间数据获取研究大多数采用单机网络爬虫的形式。然而,Web空间数据广泛分布于不同的网络站点中且更新频率快,依赖单机网络爬虫抓取数据在抓取覆盖率和效率上难以满足需求,难以保证抓取数据的及时性和全面性,因此本文针对单机网络爬虫获取Web空间数据存在的问题,研究基于分布式网络爬虫提高Web空间数据获取效率。
1 分布式网络爬虫实现原理
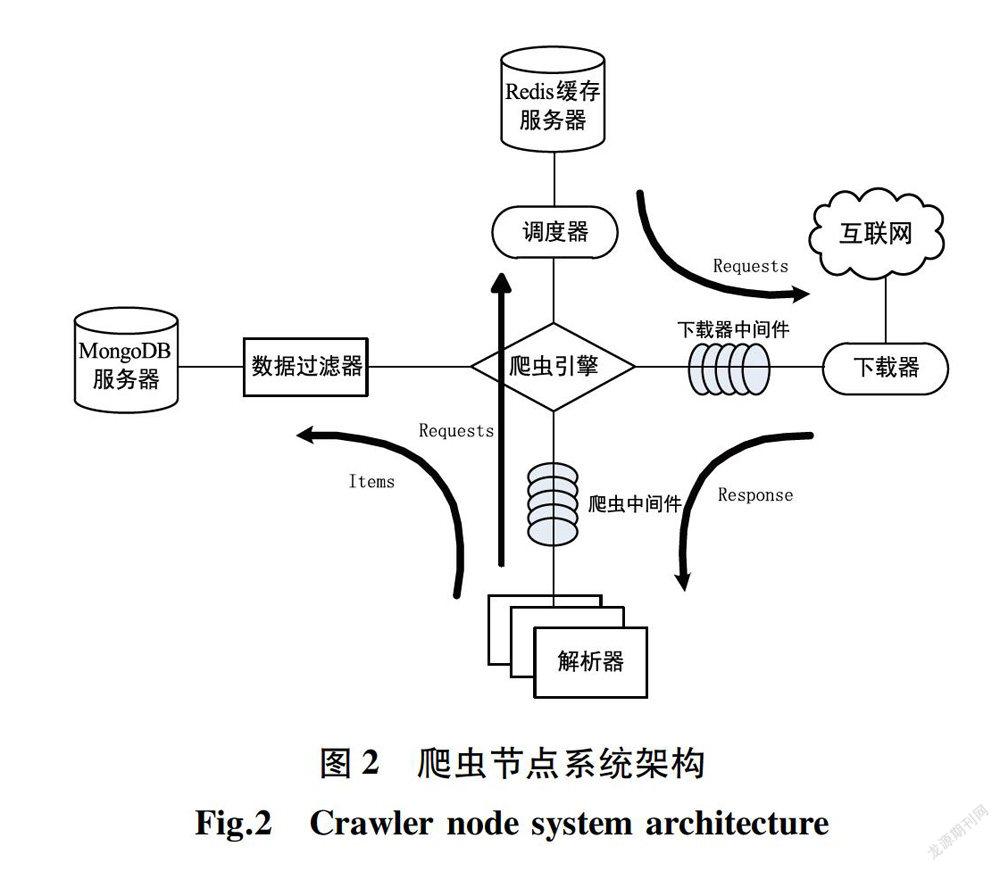
基于分布式网络爬虫的Web空间数据获取方法不是通过增加单个爬虫系统的负荷而是通过增加更多的爬虫系统成员来提高数据获取性能和效率,即采用多台性能一般的机器来做数据抓取,同时在每台机器上部署多个爬虫,增加数据抓取的并发性。具体的实现方式是采用不同的机器承担不同的角色分工,选取一台性能较好的机器专门负责URL(Uniform Resoure Locator,统一资源定位器)的统一调度和去重,将这台机器称为主节点,主要用来管理和维护待爬取URL队列和已爬取URL队列。采用多台性能一般的机器进行实际的网页下载和数据解析,把这些机器称为爬虫节点。
本文提出的分布式网络爬虫的运行原理如图1所示,爬虫节点从主节点请求URL进行数据抓取,在抓取数据的同时生成新的URL,并将此URL发送给主节点,主节点负责对爬虫节点提交的URL进行去重,并将其加入待爬取URL队列。爬虫节点之间没有通信联系,每个爬虫节点只和主节点进行通信,主节点通过一个地址列表来保存系统中所有爬虫节点的信息。因此,当分布式网络爬虫系统中的节点有变化的时候(新增爬虫节点,删除某爬虫节点,或爬虫节点地址发生变化),主节点只需调整地址列表中数据,爬虫节点只需要负责抓取数据。同时,主节点负责对分布式网络爬虫系统中各爬虫节点进行负载均衡。
4 结束语
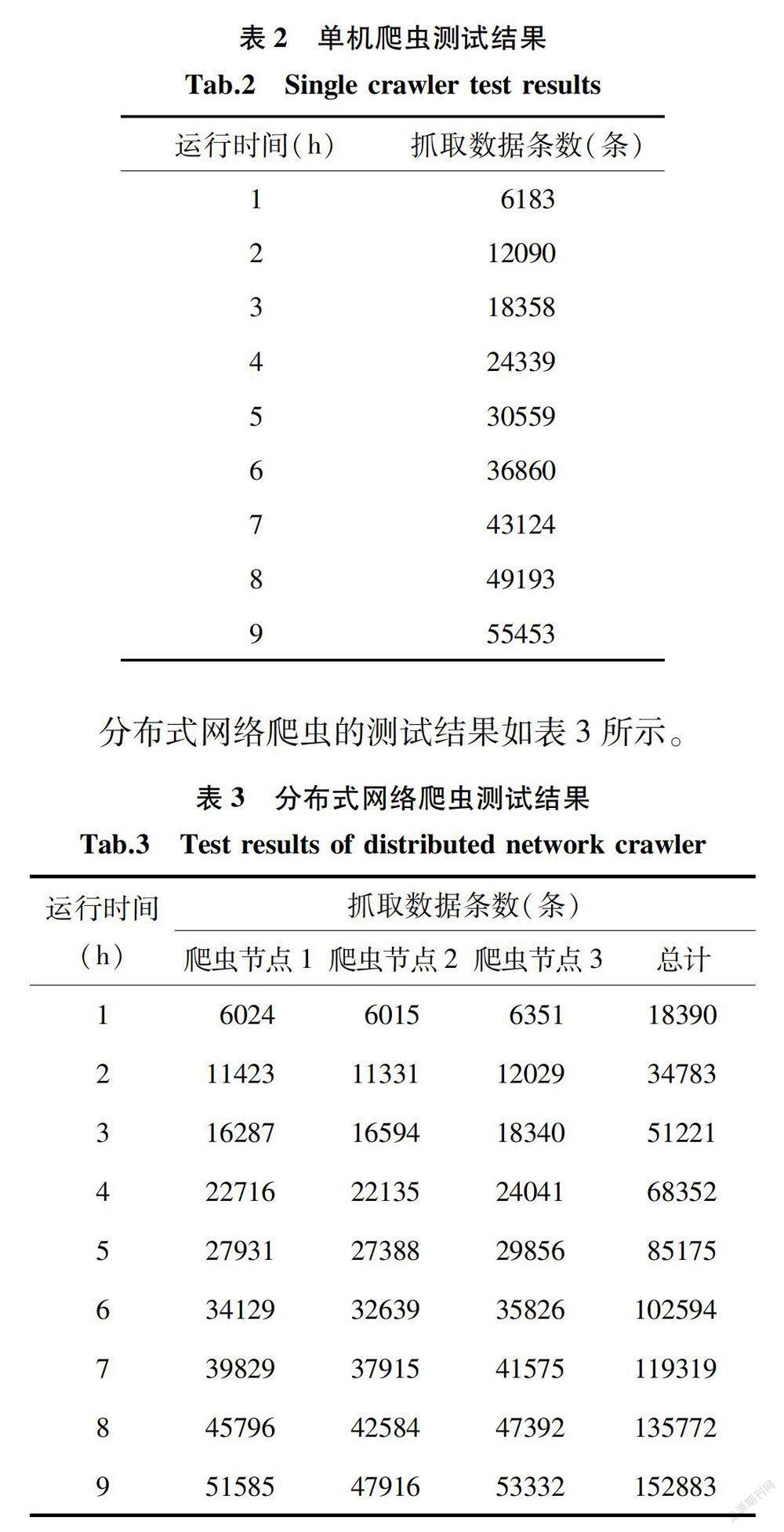
本文针对单机网络爬虫获取Web空间数据在抓取覆盖率和抓取效率上受到限制,难以保证抓取数据的及时性和全面性的问题,研究了基于分布式网络爬虫的Web空间数据获取方法。通过实验分析对比证明,本文提出的基于分布式网络爬虫的Web空间数据获取方法能够提高Web空间数据获取效率,设计和实现的Web空间数据获取原型系统能够稳定运行,并且系统具有良好的扩展性,系统各个节点之间能够实现负载均衡。
参考文献:
[1]Leasure D R. Geodata Crawler:A centralized national geodatabase and automated multi-scale data crawler to overcome GIS bottlenecks in data analysis workflows[C].Dresden,Germany:Esa Convention, 2013.
[2]Tezuka T,Kurashima T,Tanaka K. Toward tighter integration of web search with a Geographic information system[C]//Proceedings of the 15th international conference on World Wide Web.Edinburgh: ACM,2006:277-286.
[3]Zhang C J,Zhang X Y,ZhuS N,et al. Method of Toponym Database Updating Based on Web Crawler[J]. J.Geo ̄Inf. SCI,2011,13:492-499.
[4]Hua ̄Ping Zhang,Qian Mo.Structured POI data Extraction from Internet News[C].Beijing: The 4th International Universal Communication Symposium (IUCS),2010.
[5]Li W,Yang C. An active crawler for discovering geospatial web services and their distribution pattern ̄a case of study of OGC web map service [J].International Journal Geographical Information Science,2010,24(8):1127-1147.
[6]CHEN X,CHEN R,WEI W. Design and Realization of Web Service Snatch and Parse Engine Based on Web Crawler [J].Geomatics World,2010,3:016.
[7]Jiang J,Yang C,Ren Y .A spatial information crawler for opengis wfs [C]//The 6th International Conference on Advanced Optical Materials and Devices. Guangzhou: International Society for Optics and Photonics,2008:71432C-9.
[8]王明军.基于Web的空间数据爬取与度量研究[D].武汉: 武汉大学,2013.
[9]蔡地.互联网多源矢量空间数据自动获取与管理方法研究[D].北京:中国测绘科学研究院,2015.
[10]Ager A,Schrader ̄Patton C,Bunzel K,et al. Internet Map Services:New portal for global ecological monitoring,or geodata junkyard?[C]//Proceedings of the 1st International Conference and Exhibition on Computing for Geospatial Research & Application. Washington, DC, USA: ACM,2010:37.
[11]Ryan Mitchell. Web Scraping with Python[M].Sebastopol:O’Reilly Media,Inc, 2015:7-24.
[12]Scrapy developers. Scrapy Documentation Release 1.0.3[EB/OL].(2015-8-15)https://pypi.org/project/Scrapy/1.0.3/.
[13]阮正杰.基于Twisted架構的GPS协议转换软网关的设计与实现[D].杭州:浙江工业大学,2013.
(责任编辑:曾 晶)
