一种[lp]正则化改进的车辆轨迹学习算法
2019-09-10汪霜霜李春贵
汪霜霜 李春贵





摘 要:车辆轨迹学习可用于视频监控系统,以识别正常和异常车辆运动模式,用于交通运营、公共服务和执法管理.本文的目的是研究一种新的基于视频监控系统的车辆轨迹学习自适应稀疏重构方法.由于[l1]和[l2]最小化的解的稀疏性会受到范数中项的值的损害,在实践中不能保证得到足够稀疏的解,本文提出了一种改进的基于[lp][0<p<1]最小化的车辆轨迹学习方法,应用[lp]范数的下限理论获得更稀疏的重构系数向量,以获得比[l1]或[l2]最小化更稀疏的解.通过实验分析,所提出的方法可以解决过拟合问题,获得更稀疏的解.
关键词:稀疏重构;范数;正则化;最小化
中图分类号:TP277.2;U495 DOI:10.16375/j.cnki.cn45-1395/t.2019.02.008
0 引言
伴随着人们对实时交通的管理和安全上的需求逐步增长,视频监控系统被广泛用于交通道路.由于传输和存储视频数据的成本显著降低,大量交通视频被收集并应用于车辆运动模式、交通违规和车辆碰撞的研究.但是难以连续手动监控和分析如此大量的视频,致使研究人员开发智能方法,从存储的视频数据中自动识别交通事件和交通活动.OH Cheol等[1]提出了一种用于学习车辆行为的新型高速公路交通监控系统,通过检测车辆换道引起的潜在碰撞来进行监控跟踪,设置碰撞时间和停车距离指数这两个指标来学习车辆行为.然而,当前大多数的视频监控系统只能捕获交通量和车辆变道或超速行为,不能满足诸如车辆行为识别和异常行为检测的需求.因此,当务之急是需要研究一种有效的方法来进行关于交通运营、公共服务和执法的视频中监控的车辆轨迹的学习.
有研究学者声称,稀疏表示可以表现出对大量噪声和面部遮挡的鲁棒性[2].稀疏重建技术能很好地避免样本不足、特征描述不完整、额外的噪声和失真等问题[3].稀疏重建的核心是解决[l0]最小化问题.现有的研究成果通常是将[l0]最小化问题归结为[l1]或[l2]最小化问题,并应用凸优化求解器,如二阶核心规划求解器,甚至启发式算法,如正交匹配追踪算法等[4].ADU-GYAMFI等[5]应用稀疏表示技术来识别交通标志.CONG等[6]应用具有组约束的稀疏重建模型来检测基于视频数据的异常事件.然而,来自[l1]和[l2]最小化的解的稀疏性会受到范数中项的值的损害,导致不能保证得到足够稀疏的解,这将会损害基于[l1]和[l2]最小化的学习方法的辨别能力.
因此,在车辆轨迹学习的领域中,要找到一种更稀疏的解决方案来减少规范中的有害影响,從而增强稀疏重构的能力.为此,本文提出了一种改进的基于[lp][0<p<1]最小化的车辆轨迹学习的方法,应用[lp]范数的下限理论获得更稀疏的重构系数向量,通过实验作比较,获得比[l1]或[l2]最小化更稀疏的解,为后续利用基于轨迹的稀疏重建方法来检测车辆异常行为的研究做准备.
1 相关理论
1.1 稀疏规则化和最小化误差
稀疏正则化能被广泛应用在于它的一个关键优点——能够自动选择特征.通常,输入[xi]的大多数元素或特征与最终的输出[yi]无关.若在求解目标函数最小化的时候使用这些[7],虽然可以让结果的训练误差更小,但是在对新样本进行预测的时候,由于有了这些无关信息的干扰,从而影响了对正确[yi]的预测.稀疏正则化算子会学习怎样去删除这些无关紧要的特征,其做法就是将与这些特征对应的权重值设置为零,其引入的作用就是为了能够进行自动选择特征.
为了让模型更好地拟合训练数据,一般是将误差最小化,而使用正则化参数则是避免模型过分拟合训练数据.所谓过度拟合,就是在训练样本中,已建立好的学习模型表现过于优越,然而在验证数据集和测试数据集中表现出的性能却不如意.过度拟合的根本原因是模型学习过于精确,甚至将训练集中的样本噪声也进行了训练.参数越多,模型的复杂性就不断增加,并且易出现过度拟合现象,影响预测新样本的正确性.要在尽可能保证模型“简单”的基础上去训练误差达到最小化,这样所得的参数才具备好的泛化性能,即得到的测试误差小.正则函数的使用可以使模型“简单”化.把与模型相关的先验知识融入到模型的学习当中,让其具有所需要的特性,例如稀疏、低秩、平滑等.[l1]和[l2]正则化常被用来解决过拟合问题.
1.2 [l1]范数
[l1]范数被称为“稀疏规则算子”.因为[l0]范数很难进行优化求解,而[l1]范数是[l0]范数的最优凸近似,比较容易优化求解,更得研究者的喜爱和重视.
对于[l1]正则化,是指权值向量[w]中各个元素的绝对值之和,通常表示为[w1],数学表示如式(1)所示:
[Ωθ=12w1=12i=1nwi] (1)
用线性代数表示损失函数为:
[Jw;X,y=αw1+Jw;X,y] (2)
对权重求取梯度,得:
[∇wJw;X,y=αsignw+∇wJw;X,y] (3)
其中[signw]表示取[w]中各个元素的正负号.从上面的等式可以看出,正则化对梯度的影响并不是线性地缩放每个[wi],而是添加了一项与[wi]相同符号的常数.通过[l1]正则化,可以利用足够大的[α]实现稀疏.也就是说[l1]正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择机制[8].
1.3 [l2]范数
[l2]范数又称欧几里德距离之和.它是指权值向量[w]中各个元素的平方和然后再求平方根,通常表示为[w2], 数学表示为:
[Ωθ=12w22=12i=1nwi2] (4)
让[l2]范数的规则项[w2]最小,即让[w]的每个元素都很小,都接近于0.参数越小,模型越简单;模型越简单,过度拟合的可能性就越低.那么损失函数就变成了如式(5)所示:
[Jw;X,y=αwTw+Jw;X,y] (5)
求解梯度后,其梯度表示为:
[∇wJw;X,y=αw+∇wJw;X,y] (6)
因此在梯度下降过程中权重的更新如下式所示:
[w←w-βαw+∇wJw;X,y]
其中,[β]为梯度下降的步长,最终得到了:
[w←1-βαw-∇wJw;X,y]
可以看到,在梯度更新的每个步骤之前收缩权重向量,并让权重向量乘以常数因子,加入权重衰减量后导致学习规则被修改. 通过[l2]范数,既可以实现对模型空间的抑制[9],还可以实现正则化,在一定程度上避免过拟合,提升了模型的泛化能力.但是,[l2]范数不能够得出稀疏解.
1.4 残差
所谓残差,是指观测值与预测值(拟合值)之间的差,即是因变量的观测值[yi]与根据估计的回归方程求出的预测[yi]之差,用[e]表示.反映了用估计的回归方程去预测[yi]而引起的误差,第[i]个观察值的残差为:
[ei=yi-yi].
通过对残差及残差图的分析,以考察模型假设的合理性的方法,称为残差分析.可以利用残差所提供的信息分析出数据的可靠性、周期性以及其他干扰项,可用来判定分析模型的假定正确与否,运用残差分析的方法来检查回归线的异常点比较直观,效果也好.
2 车辆轨迹的稀疏重构
2.1 基于[l1]和[l2]范数的车辆轨迹的稀疏重构
通过训练车辆轨迹,可以近似线性组合任何一个新的车辆轨迹[10-11].对于给定的第[i]类足够训练的轨迹(总共有M个类),同一类的测试轨迹[yi∈Rm]可以通过训练轨迹的线性组合来表示,如下所示:
[yi=Aiσi=σi,1θi,1+σi,2θi,2+…+σi,nθi,n(σi∈Rn)] (7)
也可以用訓练字典来表达为:
[yi=Aiσi∈Rm] (8)
其中[σ=0,…,0, σTi, 0,…,0T∈Rn]是一个系数向量,其中大多数条目具有零元素,[θi,n]是[A]的特征值.
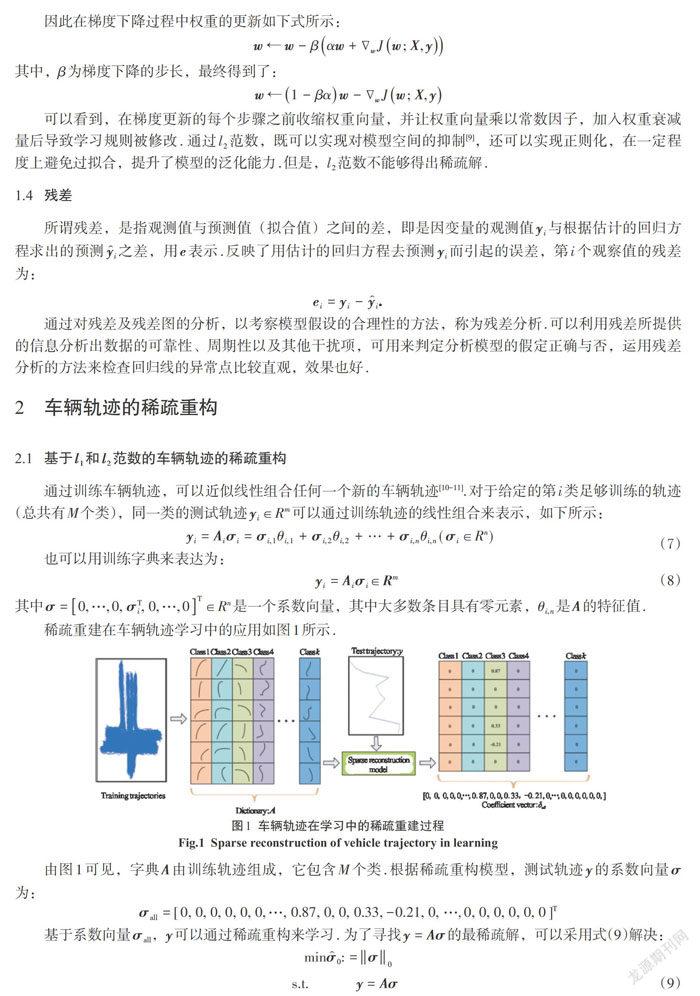
稀疏重建在车辆轨迹学习中的应用如图1所示.
由图1可见,字典[A]由训练轨迹组成,它包含M个类.根据稀疏重构模型,测试轨迹[y]的系数向量[σ]为:
[σall=[0, 0, 0, 0, 0, 0,…, 0.87, 0, 0, 0.33,-0.21, 0, …,0, 0, 0, 0, 0, 0]T]
基于系数向量[σall],[y]可以通过稀疏重构来学习. 为了寻找[y=Aσ]的最稀疏解,可以采用式(9)解决:
[minσ0:=σ0]
[s.t.] [y=Aσ] (9)
其中,[σ0]表示[σ]的[l0]范数,计算[σ]中非零项的数量.式(9)表示的是众所周知的非确定性多项式问题,由于其目标函数是非凸的,所涉及的问题是要找到最稀疏解.通常的解决方法是将[l0]范数放宽为如[l1]范数或[l2]范数这样的凸目标函数,就可使问题变得容易处理[12].[l1]范数或[l2]范数的数学公式如式(10)—式(11)所示:
[minσ1:=σ1]
[s.t.] [y=Aσ] (10)
[minσ2:=σ2]
[s.t.] [y=Aσ] (11)
式(10)所表达的具有[l1]范数的模型被认为是[l0]范数和[l2]范数之间的折衷,这是一个凸优化问题,可以通过二阶核心编程或者甚至标准线性编程求解器在多项式时间内求解来解决[13].式(11)的优点在于它的精确解(全局最小值)只需使用一些启发式算法就能很快找到,如正交匹配追踪(OMP)算法.
2.2 一种改进[lp]范数的车辆轨迹的稀疏重构
由于[l2]范数的稀疏性会被范数中元素的平方值显著削弱,造成式(11)的解与稀疏性相去甚远.根据稀疏表示和压缩感知理论可知,如果[σ0]的解足够稀疏,[l0]极小化问题的解就等于下一个[l1]极小化问题的解,但是实现这样的条件很难,在實践中的大多数情况下也是没用的.因此对于一些对稀疏性要求很高的地方,式(10)同样不适用.
对此应该引入较小的[lp][0<p<1]范数来保证稀疏解.然而,[lp]范数[0<p<1]的目标函数是非凸的,它的精确解(全局极小)同样是非确定性多项式问题.由于等式约束在实践中过于严格,因此通常是通过引入一个有效的小误差[ε]转换为不等式形式[14],即[Aσ-y≤ε].通过引入正则项[γσpp]将约束最小化问题转化为无约束最小化问题,如式(12)所示:
[minfσ:=Aσ-y22+γσpp] (12)
其中[p]= 0和1分别对应于式(9)和式(10)的[l0]正则化和[l1]正则化.
根据式(12),在正则化项中使用[lp][0<p<1]范数通常可以找到比使用[l1]范数更稀疏的解,可以建立更强的学习模型,但是它的求解过程有很强的不确定性,其计算复杂度、时间和空间复杂度都难以控制.为了解决这个问题,引入了[lp]正则化的下限定理[15],以保证在比[l1]正则化更弱的条件下得到更稀疏的解.[lp]正则化的下限定理的内容如式(13)所示:
[L=γp2Afσ01/(1-p)][0<p<1] (13)
对于式(12),大多数最小化算法本质上都是下降迭代,它们生成一系列点[σv],[v=0, 1, …],这样目标函数值[fσv]就沿序列严格递减.因此,在水平集[σ: fσ≤fσ0]中,下降算法可以找到局部极小值,包括全局极小值(其中,[σ0]是任意给定的初始点).令[Li=γp1-p2ai21/(2-p),i∈N],对于任意的[σ*∈δ*p],有任意的[i∈N],[σ*i∈-L, L⇒σ*i=0]. 对于有限大的[γ],[σ*0]减小到0就意味着[σ*=0]是唯一的全局极小值.但[σ*]中的非零条目数有如下限制:
[σ*0≤minm, fσ0γLp]
该定理揭示了:如果在[lp][0<p<1]极小化的局部极小化器[σ*i]中获得的[σ*i]项满足条件,即[σ*i∈(-L, L)],那么就可以知道全局极小化器中的相应项是0.因此,该定理可用于使获得的解更稀疏,并且更接近全局最小值的[θ=I⋅+θ=I⋅+γμα⋅1/21/2-1]
记[H1/2,γ=I⋅+γα⋅1/21/2-1].利用[l1/2]正则化求稀疏解的算法有两种:Reweighted-[l1]算法和Half算法.在数据集[D=θ,c],利用Reweighted-[l1]算法[17],来学习[mingθ-c22+γθ1/21/2]的解[θ]的基本思想是:用[θ01/2+12θ1/2θ-θ0]近似[σ1/2],并取分母部分作为当前值;利用[l1]中交叉验证的方法设置正则化参数.
一般情况下采用Half算法进行求解,本文所采用的算法也是Half算法.该算法的基本思想是对[l1/2]解的解析形式[θ=I·+γμα·1/21/2-1Buθ]使用逐次逼近;假定稀疏度k已知,通过下述迭代过程求解问题的k-稀疏解:
[θn+1=Hγnμn,1/2Bμnθn , θ0∈RNγn=969μBμnθn3/2(k+1) , μ=μ0∈0,1/L]
采用逐次近似取[γt=4/3μBtk+13/2]来逼近[γ*],利用该算法,对于足够小的[μ],可得到[θt+1-θt2→0].将原问题分解成若干个k-稀疏解的问题,通过不断迭代获得一组[k]-稀疏解,比较得出最优解.其算法步骤如下:
Step 1 随机选取[θ0∈R],设[B0=θ0+ATc-Aθ0],[γ0=μ4/3B0k+13/2],其中[k]為问题稀疏度的预估值,[θ0k+1]为[θ0]的第[k+1]大的分量,取定[0<μ<1]和误差容限[ε].置[t=0];
Step 2 计算[θt+1=H1/2,γtθt+ATc-Aθt];
Step 3 令[Bt=θt+ATc-Aθt,γt+1=4/3μBtk+13/2];
Step 4 若[θt+1-θt2<ε],算法终止;否则,置[t=t+1]并转Step 2继续进行.
综上,Reweighted-[l1]算法和Half算法这两种算法常用于[l1/2]正则化和稀疏解的求解,并且得到广泛应用[18-19].
4 实验分析
为了检测所提出方法的性能,实验环境为Win10系统,系统配置16 GB内存,3.60 GHz CPU,Visual Studio Community 2015,使用CROSS数据集,CROSS数据集由加州大学提供.它包含1 900条训练轨迹和 9 700条测试轨迹,其中9 500条为正常轨迹,200条为异常轨迹(如非法环路、越野驾驶、非法左转和其他异常行为).在数据集中选择第四类测试轨迹的其中之一,在当[p]= 2、1和0.5时分别显示其系数向量[σL2]、[σL1]和[σLp]([0<p<1]),实验结果如图3所示.其中,系数向量[σL1]和[σL2]都是式(10)和式(11)的全局极小值,而[σLp][0<p<1]是在[p]= 0.5时由定理修正的近似最优极小值.
以系数为纵坐标,字典为横坐标,图3(a)—图3(c)分别显示了[σL2]、[σL1]和[σLp]的结果;以残差为纵坐标,类别为横坐标,图3(d)—图3(f)分别显示了对应于这些解的残差,而对应于最小残差的类将被标记为测试轨迹的类.
从图3(a)—图3(c)中可以很明显地看出,[σLp]比[σL2]和[σL1]要稀疏得多;图3(d)和图3(e)显示,由于在分類过程中几十个非零条目的干扰,[σL2]和[σL1]的残差会根据不同的类别产生很大的变化.相比之下,图3(f)显示了除了第四和第七个残差(其中第四个残差是最小的)之外,[σLp]的大部分残差是相同的.更重要的是,来自[σLp]的最小残差对应于图3(c)中正确的类别(即第四类别),这就意味着测试轨迹可以通过[σLp]最小化的方法正确分类,而图3(d)和图3(e)分别显示的[σL2]和[σL1]的最小残差对应于 图3(a)和 图3(b),它们都不对应于正确的类别(它们都对应于第七类别).
实验表明,来自[σLp]最小化的改进的局部最小化器会获得比来自[σL1]和[σL2]最小化的全局最小化器更稀疏的解,能保证对于车辆轨迹的学习性能,且能够达到正确的分类,使得最终结果能够更准确,为后续利用基于轨迹的稀疏重建方法来检测车辆异常行为的研究做更精确的准备.
5 总结
本文研究了一种用于车辆轨迹学习的[lp][0<p<1]正则化稀疏重建的方法.由于[l1]和[l2]最小化的解的稀疏性会在求解过程中受到范数中项的值的损害,不能保证能够得到足够稀疏的解.本文主要的改进思路是应用[lp]范数的下限理论来解决NP-hard问题,得到更稀疏的重构系数向量,从而获得比[l1]或[l2]最小化更稀疏的解.通过与[l1]和[l2]正则化的实验分析比较,得知所提出的模型可以达到目标,获得更稀疏的解.
参考文献
[1] CHEOL O,JUTAEK O,JOONYOUNG M.Real-time detection of hazardous traffic events on freeways methodology and prototypical implementation[J].Transportation Research Record Journal of the Transportation Research Board,2009,2129:35-44.
[2] 秦胜君.基于稀疏自动编码器的微博情感分类应用研究[J].广西科技大学学报,2015,26(3):36-40.
[3] CHONG Y W,CHEN W,LI Z L,et al.Method for preceding vehicle type classification based on sparse representation[J].Transportation Research Record Journal of the Transportation Research Board,2011,2243:74-80.
[4] CHEOL O,EUNBI J,KYUNGPYO K.Hazardous driving event detection and analysis system in vehicular networks methodology and field implementation[J].Transportation Research Record Journal of the Transportation Research Board,2013,2381:9-19.
[5] ADU-GYAMFI Y,ATTOH-OKINE N.Traffic sign recognition using sparse representations and active contour models[J].Transportation Research Record Journal of the Transportation Research Board,2014,2463,35-45.
[6] CONG Y,YUAN J S,LIU J.Abnormal event detection in crowded scenes using sparse representation[J].Pattern Recognition,2013,46:1851-1864.
[7] 段淑玉,徐奕奕,李春贵,等.一种基于运动矢量时域递归的运动估计算法[J].广西科技大学学报,2015,26(2):36-40.
[8] 朱华,岳峻,李振波,等.基于l(2,1)范数原子选择的图像分块稀疏重构[J].计算机应用研究,2019,36(6):1-3.
[9] 陈鹏清,黄尉.基于l1-l2范数的块稀疏信号重构[J].应用数学和力学,2017,38(8):932-942.
[10] XU Y,ZHONG Z F,YANG J E,et al.A new discriminative sparse representation method for robust face recognition via l2 regularization[J].IEEE Transportation on Neural Networks and Learning Systems,2017,10:2233-2242.
[11] MO X,MONGA V,BALA R,et al.Adaptive sparse representations for video anomaly detection[J].IEEE Transportation on Circuits and Systems for Video Technology,2014,24(4):631-645.
[12] 周巍.L1范數最小化算法及应用[D].广州:华南理工大学,2013.
[13] DONOHO D L,MALEKI A,MONTANARI A.Message-passing algorithms for compressed sensing[J].Proceedings of the National Academy of Sciences of the United States of America,2009,45:18914-18919.
[14] STOJNIC M.l2/l1-optimization in block-sparse compressed sensing and its strong thresholds[J].IEEE Journal of Selected Topics in Signal Processing,2010,4(2):350-357.
[15] CHEN X J,XU F M,YE Y Y.Lower bound theory of nonzero entries in solutions of l2-lp minimization[J].Siam Journal on Scientific Computing,2010,5:2832-2852.
[16] 徐宗本,吴一戎,张冰尘,等.基于L(1/2)正则化理论的稀疏雷达成像[J].科学通报,2018,63(14):1306-1319.
[17] 董卫东,彭宏京.紧框架域重加权L1范数正则化图像恢复模型[J].小型微型计算机系统,2018,39(1):179-184.
[18] 叶丹,张成毅,罗双华.基于稀疏指数追踪模型的SOR-Half阈值算法[J].纺织高校基础科学学报,2015,28(4):457-462.
[19] 张亚飞,张成毅,罗双华.基于稀疏鲁棒M-投资选择模型的鲁棒Half算法[J].西安工程大学学报,2017,31(1):135-140.
An improved minimization of vehicle trajectory learning
WANG Shuangshuanga, LI Chungui*b
(a. School of Electrical and Information Engineering; b.School of Computer Science and Communication
Engineering, Guangxi University of Science and Technology, Liuzhou 545006, China)
Abstract: Vehicle trajectory learning can be used in video surveillance system to identify normal and abnormal vehicle movement patterns for traffic operation, public service and law enforcement management. The paper aims to study a new adaptive sparse reconstruction method for vehicle trajectory learning based on video surveillance system. Enough sparse solution cannot be guaranteed in practice because the sparsity of the minimized solution will be impaired by the value of the term in the norm. A new method of vehicle trajectory learning based on minimization is proposed in this paper. The lower bound theory of norm is applied to obtain more sparse reconstruction coefficient vectors in order to obtain more sparse solutions than or minimization. Through experimental analysis, the proposed method can solve the over-fitting problem and obtain more sparse solutions.
Key words: sparse reconstruction; norm; regularization; minimization
