深层卷积神经网络的目标检测算法综述
2019-09-09张泽苗赵逢禹
张泽苗,霍 欢,2,赵逢禹
1(上海理工大学 光电信息与计算机工程学院,上海 200093)2(复旦大学 上海市数据科学重点实验室,上海 201203) E-mail:zhangzemiao@126.com
1 引 言
信息技术和硬件的快速发展,极大地提高了计算机的计算能力,依托于巨大计算能力的深度学习[1]也由此引起了广泛的研究.卷积神经网络(Convolutional Neural Networks,CNN)在机器视觉领域得到广泛的应用并取得了巨大成功[2].目标检测[3]是图像语义分割[4]、实例分割[5]、图像标注[6]和视频理解[7]的基础,是进行图像场景识别、内容理解等高级视觉任务的前提,对于构建图像检索系统[8],人脸识别[9],物体识别,行人检测[10],视频监控以及实现无人自动驾驶[11]等领域具有重大意义.广义上的目标检测任务是指识别图片中是否存在事先定义的类别目标物体,如果存在,返回该类别目标物体的空间位置以及空间范围,一般使用矩形边框进行标定[12],例如自然界中超过 1000个类别的目标检测.狭义上的目标检测是特指某个类别的目标物体的检测,如:人脸识别,行人检测,车辆检测等.目标检测算法最初利用人为构造的人工几何特征(如:尺度不变特征变换[13](Scale-invariant Feature Transform,SIFT)、方向梯直方图[14](Histogram of Oriented Gradients,HOG)、哈尔特征[15](Haar)等,先提取图像特征,然后使用分类器(如:支持向量机,Support Vector Machine,SVM)进行分类,训练完成分类之后进行边框修正,实现物体的检测.视觉词袋模型[16](Bags-of-Visual-Words,BoVW)和形变部件模型[17](Deformable Part Model,DPM)等充分利用上述人工几何特征,效果得到提升.其中DPM模型是在深度学习模型出现之前最成功的模型,它将目标对象建模成几个部件的组合,先计算梯度直方图,然后使用SVM训练得到物体的梯度模型,最后利用梯度模型完成检测,连续多年赢得The Pascal Visual Object Classes Challenge(2008-2012)的比赛[18].然而使用人工构造特征进行检测存在费时,鲁棒性差,检测效果不理想的问题.2012年,Hinton[19]等人首次提出将深层卷积神经网络(Deep Convolutional Neural Networks,DCNN)应用在大规模图像分类上,奠定了DCNN在机器视觉方面的应用基础.2013年,DetectorNet[20]首次将DCNN应用在目标检测上.同年,Girshick[21]等提出了基于候选区域的卷积神经网络(Region based CNN,R-CNN)目标检测模型,解决了人工特征构造的问题,使用神经网络自动抽取特征,R-CNN首先产生目标候选区域,然后再使用候选区域图片完成后续检测,在VOC 2012数据集上取得了53.3% mAP的成绩,算法效果提升了30%的mAP.2014年,VGGNet[22]、GoogLeNet[23]分别取得了ILSVRC[12]2014 比赛亚军和冠军,进一步促进了DCNN在大规模图像分类上的应用.2015年,文献[24]在R-CNN的基 础上提出了Fast R-CNN模型,改善R-CNN的特征提取流程,利用RoI Pooling层实现了从先前所有候选区域的CNN特征提取到整张图片的单次CNN特征提取,加快了检测速度.同年,文献[30]又在Fast R-CNN的基础上提出了Faster R-CNN,使用区域候选网络(Region Proposal Network,RPN)代替Selective Search[31]的方法,首次实现了包括区域提取在内的端到端的目标检测网络,检测速度达到了5fps,提升至原来的5倍,在VOC 2012数据集上检测效果提升了10%.尽管Faster R-CNN进一步提升了检测速度和检测效果,但是Faster R-CNN的速度仍然无法达到实时检测.Redmon等人认识到Faster R-CNN的RPN网络需要进行大量运算,于是提出了YOLO[32]框架,首次提出了将目标定位归为回归问题的框架,虽然检测准确率无法达到Faster R-CNN的检测效果,但是检测速度达到50fps.图1按照时间顺序给出了目标检测的发展历程,包括特征表达(SIFT[13],Bag of Visual Words[16],HOG[14])、检测框架(DPM[17]、OverFeat[25]、R-CNN[21]、VGGNet[22]、GoogLeNet[23]、 ResNet[27]等)以及公共数据集(The PASCAL VOC[33]、MS COCO[34]、ImageNet[12]).
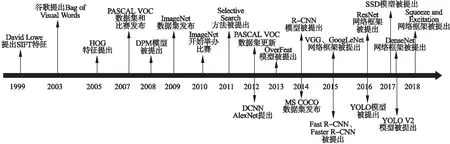
图1 目标检测主要发展历程Fig.1 Key development of object detection
2 图像分类
图像分类是目标检测的基础,目标检测是在分类基础上,实现图像中的目标定位,给出目标的具体空间位置和边界,因此图像分类的发展也推动着目标检测的进步.目标检测框架中需要对图像进行特征提取,图像分类为目标检测框架提供了基本的特征提取卷积网络骨架.在ILSVRC[12]比赛中,大量的优秀的卷积神经网络框架相继被提出,包括:AlexNet[19]、OverFeat[25]、VGGNet[22]、Inception v3[26]、ResNet[27]、DenseNet[28]以及SENet[29].深层卷积网络的发展过程中,错误率逐步降低,从AlexNet的15.31%逐步降到SENet的2.3%,其中网络层数总体趋势为越来越多.由于网络层数的增加,网络参数相对应增加,因此网络参数压缩的研究也相继被提出,包括GoogLeNet的inception模块,ResNet的残差连接结构等.Hinton等人提出的AlexNet首次将深层卷积神经网络应用于大规模的图像分类问题中,并在ILSVRC2012的测试集中实现了将15.315%的错误率,比第二名26.172%低11%左右,奠定了深层卷积神经网络应用在图像分类的基础.Sermanet等人提出的OverFeat与AlexNet网络结构类似,使用了更小的滑动窗口步长和不同大小、数量的卷积核,首次将图像分类与目标定位、检测结合起来实现效果的提升.Matthew D.Zeiler和Rob Fergus提出的ZFNet,调整了AlexNet的网络结构,在第一层卷积层中使用了更小的卷积核以及在第一、二层卷积层中使用了更小的窗口滑动步长,通过卷积可视化进行调整,探索了不同网络结构的分类效果.Karen Simonyan等人使用了3×3的卷积核加深了网络深度,取得了更好的结果,改进过后的网络称为VGGNet.Christian Szegedy等人前后相继提出了GoogleNet,Inception v2和Inception v3使用了inception模块去拼接不同大小卷积核产生的特征图,使得网络结构变宽,而且参数急剧减小,引入批规范化(Batch Normalization,BN)加速网络收敛,增加inception模块数量从而加深网络深度.2016年,Kaiming He等人发现在加深网络层数的时候,网络训练损失并不会下降,于是提出了残差连接结构,在加深网络深度的同时减少网络参数,提高了网络的学习和拟合能力.2017年,Gao Huang等人通过设计稠密模块(dense block)使得前向传播中网络层与其他网络层都有连接,有效缓解了由于网络深度过深导致的梯度消失问题,同时减少了网络参数.2018年,Jie Hu等人设计了提出Squeeze and Excitation模块充分利用了图像不同通道之间的关系,能够通过额外很小的计算代价,改进卷积神经网络.
3 目标检测算法评价指标
目标检测算法的涉及的评价指标如下:
·检测速度,帧每秒(Frames per second,fps):每秒钟所能检测的图片的数量;
·IOU,intersection over union,实际边框与边框重叠部分与两个边框并集的比率.
(1)
其中,Bp为预测的位置边框,Bg为物体实际的位置边框,Bp∩Bg为Bp和Bg的交集的面积,Bp∪Bg为Bp和Bg的并集的面积.
·精确率,Precision,P
(2)
其中,TP为true positive,即正样本中被预测正确的数量,FP为false positive,即负样本被预测为正样本的数量,一般IOU为0.5
·召回率,Recall,R
(3)
其中,FN为false negative,即正样本被错分为负样本的数量.
·平均精确率,average precision,AP

(4)
其中,t为不同的IOU阈值下AOC曲线的召回率,如t=0.5时,只有当预测的边框与实际的边框的IOU ≥ 0.5时,预测边框才为正样本.
·平均精确率均值,mean average precision,mAP,指的是所有类别的AP的均值
(5)
其中N为类别的数量.
4 目标检测框架
目标检测的框架可分为以下两类:
·基于候选区域(R-CNN)的深层卷积神经网络两步骤框架
基于候选区域的深层卷积神经网络的目标检测框架将目标检测分为两步,先提取图片中目标可能存在的子区域,然后再将所有的子区域作为输入,使用卷积神经网络进行特征提取,最后再进行检测分类和边框回归修正,其中包括R-CNN[21],SPPNet[35],Fast R-CNN[24],Faster R-CNN[30]、R-FCN[36]和Mask R-CNN[37]等.
·基于边框回归的单步骤单网络框架
基于边框回归的单步骤单网络框架是直接将边框预测视为回归预测,不再提前提取候选区域,原始图像作为输入,然后直接输出预测结果,是一种真正意义上的端到端的单网络框架,包括OverFeat[25],YOLO[32]以及SSD[38]等.
4.1 基于候选区域的深层卷积神经网络两步骤框架
4.1.1 R-CNN
2014年,Grishick等人使用Selective Search[31]产生候选区域,然后将所有候选区域输入到CNN中提取出特征图,最后使用SVM对特征图进行分类,并使用线性回归器对边框预测进行修正,在数据集VOC 2012上该方法比之前应用DMP模型的方法提升了近30%的mAP,达到了53.5%的mAP.
如图2所示,算法首先使用selective search算法,每张图片产生2000个候选区域,然后缩放图片到固定尺寸,输入到CNN中进行特征提取,接着使用SVM进行分类判断,最后再用线性回归去修正所预测的边框.
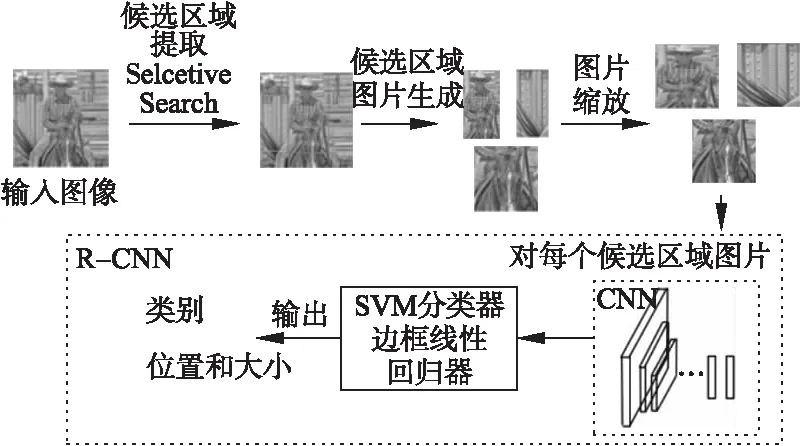
图2 R-CNN流程Fig.2 Process of Fast R-CNN
R-CNN相对于之前的算法,在准确率方面得到了明显了提升,但是R-CNN中候选区域提取、卷积网络特征提取,SVM分类以及回归器边框修正都是分开进行操作,既耗时也无法共享参数和统一网络损失.
4.1.2 Fast-CNN
R-CNN相对于传统的DPM模型,检测效果提升明显,但是R-CNN需要对所有的候选区域都进行特征提取,同时还需单独保存到磁盘,且候选区域提取、卷积网络特征提取、SVM分类以及回归器边框修正都是分开进行操作,不仅费时还浪费存储空间.2015年,Grishick等人对R-CNN进行了改进,提出Fast R-CNN[24],Fast R-CNN参考了SPPNet[35]的做法,使用RoI pooling层对候选区域进行映射,因此目标检测框架只需对整张图片进行单次CNN特征提取即可,CNN特征提取次数从之前的2000次优化为一次,极大提高了检测速度,使用了金字塔池化的做法实现了处理不同大小的图像,同时Fast R-CNN还使用softmax层以及线性回归层代替R-CNN的SVM和单独的线性回归器,在忽略候选区域提取的步骤下,首次实现了端到端的目标检测框架.相比于R-CNN和SPPNet,Faste R-CNN检测速度提升了10倍,图3给出了Fast R-CNN的算法示意图.
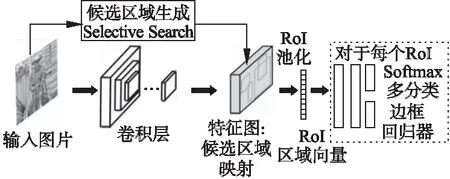
图3 Fast R-CNN流程Fig.3 Process of Fast R-CNN
4.1.3 Faster R-CNN
2015年,Ren等人提出的Faster R-CNN[30]解决了候选区域提取的瓶颈问题,提出了用候选区域生成网络(Region Proposal Network,RPN)替代R-CNN和SPPNet所使用的Selective Search,实现了RPN和CNN的损失值统一,降低训练难度,进一步提升了检测效率.同时提出的anchor box概念,解决了同个位置多个目标检测的问题,图4给出了Faster R-CNN的流程.
4.1.4 RFCN
基于候选区域的深层卷积神经网络的目标检测框架包括候选区域提取网络和特征提取的卷积网络,尽管Faster R-CNN 相对于Fast R-CNN在检测速度上提高一个数量级,Faster R-CNN的网络中仍然需要对图像中每个子区域进行处
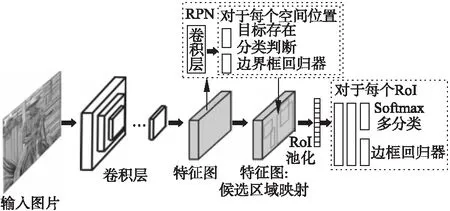
图4 Faster R-CNN流程Fig.4 Process of Faster R-CNN
理,无法实现候选区域提取网络和特征提取的卷积网络的权值共享.文献[36]提出了基于区域的全卷积神经网络(Region based Fully Convolutional Network,R-FCN),利用位置感知得分图(position-sensitive score maps)来解决图像变形在图像分类任务中属于一致而在目标检测任务中不一致的问题,如图5所示.R-FCN使用卷积网络替代池化和全连接层,实现几乎所有网络层的计算共享,最终实现每张图耗时170ms,比faster r-cnn快2.5~20倍.
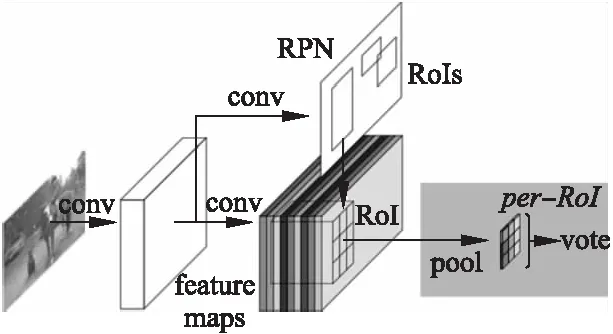
图5 R-FCN流程Fig.5 Process of R-FCN
4.1.5 Mask R-CNN
实例分割跟目标检测密不可分,实例分割不仅要求能准确识别所有目标,还需要分割出单个实例,这两个任务通常被认为是独立的,因此容易因为实例重叠而产生虚假边缘和系统误差.文献[37]提出了Mask R-CNN,在Faster R-CNN的基础上增加了像素级别的实例分割遮罩分支,在进行目标检测的同时实现实例分割,统一网络损失.Mask R-CNN相对于Faster R-CNN而言只增加了很小的计算代价利用实例分割遮罩能为目标检测任务提供补充信息.Mask R-CNN易于实现,具有很好的实例分割和对象检测结果,只需要极小的修改便可应用到其他相关任务,图6展示了Mask R-CNN的框架结构.
4.2 基于边框回归的单步骤单网络框架
4.2.1 YOLO
YOLO(You Only Look Once)[32]重新定义目标检测为图像空间边框回归以及类别概率预测问题.如图7所示,YOLO框架中只有单个网络,输入整张图片,每张图片分为N个方格,经过CNN的特征提取,然后使用softmax分类器以及线性回归器,输出目标检测结果.由于YOLO框架中只有单个网络,不需要提取候选区域,YOLO框架的计算量极大减少.相对于Faster R-CNN,YOLO牺牲了较小的准确率,但是检测速度却得到了极大的提升.实时检测速度达到50fps,而Faster R-CNN只有5fps.
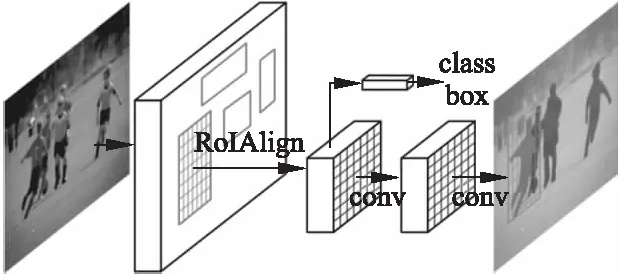
图6 Mask R-CNN流程Fig.6 Process of Mask R-CNN
4.2.2 SSD
为了达到实时检测的速度同时又不过于损失检测准确率,Liu等人提出了SSD[38](Single Shot MultiBox Detector)模型,该模型比YOLO更加快速,同时检测准确率也有所提升,
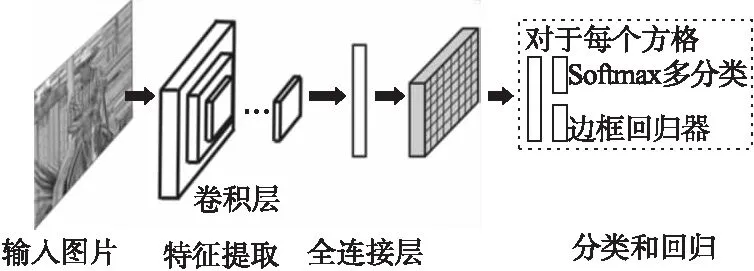
图7 YOLO算法流程Fig.7 Process of YOLO
解决了YOLO中对于小物体检测精度过低的问题.如图8所示,SSD结合了YOLO和Faster R-CNN anchor box机制,SSD中使用了不同大小的多个卷积核,综合利用了不同卷积层输出的特征图.与YOLO不同的是,SSD为每个类别都提前规定了不同比例的边框模板,输出的时候每个目标都输出多个比例的边框以及置信度.
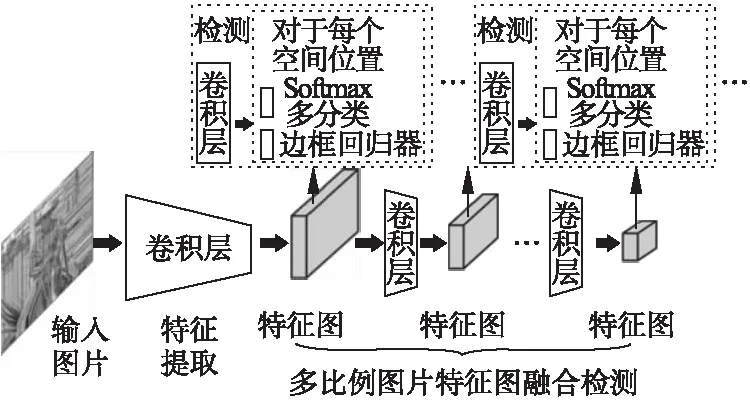
图8 SSD算法流程Fig.8 Process of SSD
4.3 近几年目标检测的发展
近几年来,目标检测在基于候选区域的深层卷积神经网络两步骤框架和基于边框回归的单步骤单网络框架都有研究进展,其中特征表达和抽取增强[39]、网络结构改进(如:Dilated Residual Networks[40],Xception[41],DetNet[42]以及Dual Path Networks(DPN)[43])以及语境信息[44-46]的结合是研究发展的重点,训练过程的处理优化也影响着目标检测的性能[47,48].基于SSD改进的目标检测算法有DSOD[49],RFB Net[50],STDN[51],而基于Faster R-CNN改进的目标检测算法有Mask-RCNN[37],HyperNet[52],FPN[53],ZIP[54],RefineNet[55],ORN[56],Megdet[47].
在基于Faster R-CNN的改进框架中,目标特征的构造和使用对于检测效果影响显著,2016年,Tao Kong[52]等人提出了HyperNet,该网络结构使用VGG16作为DCNN的骨架,结合前层,中层以及深层的特征构造混合特征图,将混合特征图同时用于候选区域提取以及目标检测,在VOC12上实现了71.4%的mAP(IoU=0.5).2017年,Liu Tsung-Yi[53]等人利用DCNN不同尺寸的不同层的特征图构建特征金字塔,该方法对于检测效果提升十分明显,表明特征金字塔对于通用目标检测具有重大作用,在COCO上实现了59.1的mAP(IoU=0.5).同年,Liu Hongyang[54]等提出了特征图权值注意力判别单元,利用单元产生候选区域,使得检测更加高效.2018年,Zhang Shifeng[55]等人提出了RefineDet,提出了anchor优化模块以及目标检测模块,并将两个模块互连,anchor优化模块为目标检测模块提供更少以及更准确的anchor,实现了准确率和效率同时提升,在COCO数据集上达到了62.9%的mAP(Iou=0.5).
在基于SSD的改进网络框架中,检测性能高效是SSD框架的优点,如何进一步提升效率以及在不影响效率的情况下提升检测效果是研究的热点.2017年,Shen Zhiqiang[49]等人结合了SSD和DenseNet的优点,在没有进行预训练的基础上也能达到比较好的结果,且网络参数少于SSD以及Faster R-CNN,解决了目标检测重度依赖于预训练以及迁移学习的问题.DSOD以DenseNet为骨架,在IoU=0.5的情况下,实现了VOC12的mAP为72.2%,COCO的mAP为47.3%的检测效果.2018年,Liu Songtao[50]等人提出了RFB(Receptive Field Block)模块增强轻量化网络的特征表达,实现了又快又准的检测效果,在同样是以VGG16为骨架的情况下,VOC12数据集的mAP达到81.2%,COCO数据集的mAP则为55.7%(IoU=0.5).同年,Zhou Peng等[51]在DenseNet169的结构上加入了尺寸变化模块,扩展了特征图的宽带和高度,实验表明修改过后的特征图能够使检测器不受目标比例的影响,改善检测效果.
5 数据集
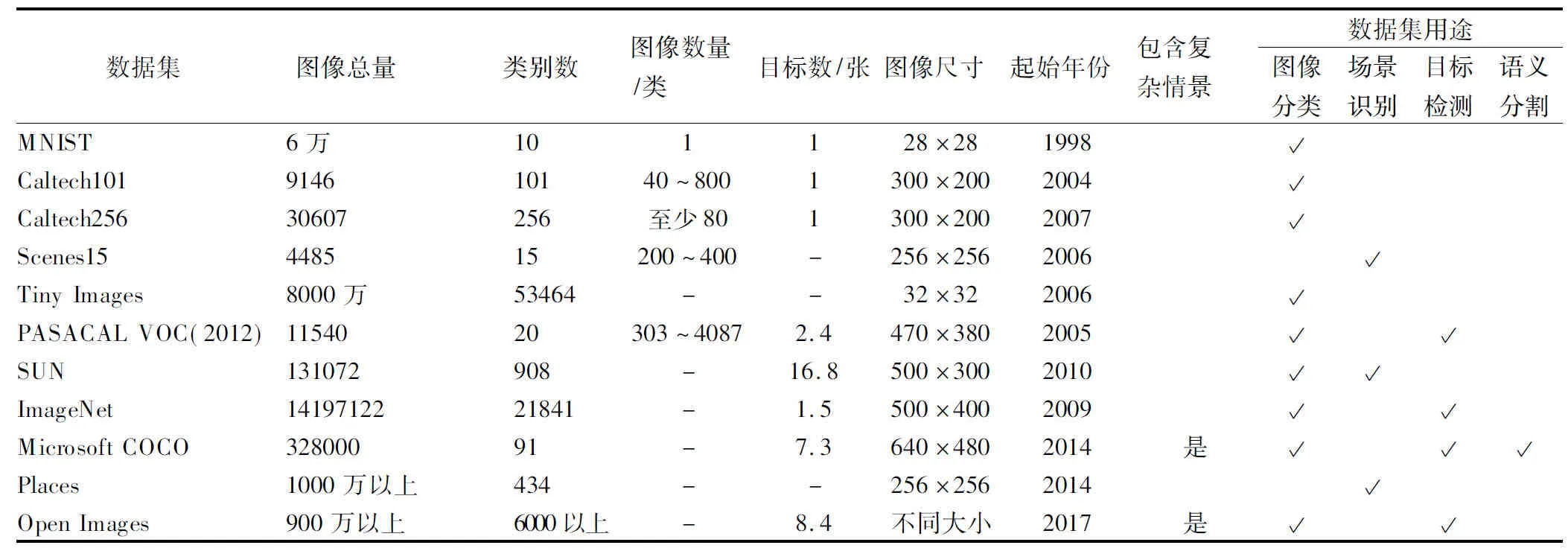
数据集对于有监督学习算法十分重要,对于目标检测而言,适用性强的数据集不仅能为算法提供性能测试和算法评估,同时也推动着目标检测研究领域的发展.目前与目标检测以及图像分类相关的典型数据集有:MNIST,ImageNet[12],Caltech101,Caltech256,PASCAL VOC(2007,2012)[18],Tiny Images,SUN[57],Microsoft COCO[34]以及Open Images(1)Karin I, Duerig T, Alldrin N, et al. Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github.ocm/openimages, 2017.,其中Microsoft COCO和Open Images为目标检测中最重要的数据集.表1给出了不同数据集的概况.由于人工标注成本高昂,目标检测数据库更新缓慢且大部分数据集规模较小,无法反映现实生活中复杂的情景和物体之间的关系.Microsoft COCO是2014年微软为更好地反映现实生活中物体与物体、环境相互之间情景关系理解所发布的数据集,该数据不仅提供了更为复杂的情景图片,单张图片包含更多物体,同时也提供了语义分割的数据集,极大推动了目标检测的研究.但是随着目标检测算法的发展,该数据集规模已无法满足通用目标检测的算法的需求.Open Images包含900万张标注图片和边框信息,是现存最大的数据集,图像大小不一,且单张图像为包含多个目标的复杂场景,相比于Microsoft COCO,Open Images规模更大,图片中情景情况更为复杂.总体上,数据集的发展逐步趋向于大规模,图像质量也越来越好,更加注重来自自然生活的复杂情景,包含更多的语境和情景信息,为监督学习提供大量优质训练数据集,提升模型泛化能力,为未来研究方向奠定基础.
6 发展趋势展望
目标检测是机器视觉领域的一个重要组成部分,应用在多个方面,如:自动驾驶,人脸识别等,与人们的生活息息相关.从传统的人工特征构造应用DPM模型到基于深层卷积神经网络的目标检测框架,目标检测取得了极大的发展.自深层卷积网络应用于目标检测以来,目标检测主要致力于提升目标检测的效果以及效率,在图像特征表示以及网络结构优化方面都有发展,基于R-CNN的框架相对于基于边框回归的单步骤框架而言,前者准确率更高,但更加耗时,而后者由于不需要提前对候选边框进行提取,因此效率更高,但是准确率比基于R-CNN的框架低.近年来目标检测的研究主要集中在特征表达增强上,相继提出了混合特征图、特征金字塔以及特征注意力单元等,取得了较好的研究成果.目标检测算法准确率和效率之间的平衡[58]、语境信息的结合等也是研究的重点.
尽管近年来目标检测研究领域取得了极大的进步,目标检测距离实现达到人类检测识别水平仍然需要开展大量研究工作,未来的研究方向可以考虑以下几个方面:
·减少数据依赖性:目前目标检测算法均为有监督学习,无法检测未训练过的目标,极大依赖训练数据.训练数据集的多样性和大小影响着目标检测的效果.减少数据依赖性,通过将有监督学习转化为半监督或无监督学习,增强算法的泛化能力,提升模型应用能力,减少数据依赖性是目标检测算法的重要发展方向.
·结合知识图谱:知识图谱是用来描述真实世界中存在的各种实体和概念,以及他们之间的强、弱关系,对于数据实体具有强大的描述能力.对于图像而言,图像中的多个目标之间也会存在依存关系,如:人包括头、手、脚和身体等,目标检测结合知识图谱,能够提升多目标检测之间依存关系,增加检测的语境信息,能更好地描述图像中的目标实体关系,提升检测效果,文献[59]提出了知识感知的目标检测框架,提出并定义了知识图谱中的语义一致性,并将其应用到现有目标检测算法当中.实验表明,基于知识感知的目标检测框架能够改善目标检测的效果.
·结合语境信息:图像中的物体相互之间并非独立,存在着相互依存关系,且物体与场景类别也相互依存,如书架与书,书房与书架之间的关系,综合利用物体与物体和场景相互之间的具体语境信息,有利于提升物体的特征表达能力,对于提升检测效果和检测速度有重大意义.
表1 数据集比较
Table 1 Comparison of datasets
数据集图像总量类别数图像数量/类目标数/张图像尺寸起始年份包含复杂情景数据集用途图像分类场景识别目标检测语义分割MNIST6万101128×281998Caltech101914610140~8001300×2002004Caltech25630607256至少801300×2002007Scenes15448515200~400-256×2562006Tiny Images8000万53464--32×322006PASACAL VOC(2012)1154020303~40872.4470×3802005SUN131072908-16.8500×3002010ImageNet1419712221841-1.5500×4002009Microsoft COCO32800091-7.3640×4802014是Places1000万以上434--256×2562014Open Images900万以上6000以上-8.4不同大小2017是
7 结束语
本文在对目标检测算法广泛研究的基础上,旨在介绍自深层卷积神经网络应用以来目标检测的研究发展情况.首先介绍了目标检测算法中基础任务图像分类的进展,目标检测评测指标,然后详细介绍了目前两大类框架,基于候选区域的深层卷积神经网络两步骤框架和基于边框回归的单步骤单网络框架.然后阐述了近年来目标检测算法的发展,结合数据集介绍了目标检测算法的研究趋势,最后展望了目标检测未来的发展和研究方向.
