一种基于预写日志的SQLite快速数据恢复方法*
2019-09-03夏文菁
夏文菁,徐 明,吴 铤,郑 宁
(杭州电子科技大学,浙江 杭州 310018)
0 引 言
SQLite是一款轻量级的单文件关系型数据库,其使用时无需启动独立的进程用于提供数据库服务,而是通过解析处理数据库文件直接进行数据的CRUD操作。基于此特性,SQLite被广泛应用于手机系统及日志服务器等读写频率较高的场景。在设计初期,SQLite被用于处理小数据量存储的需求,但随着技术发展与版本迭代,其已经能够存储庞大的数据。在数据管理系统、日志系统等常见的软件系统中,系统日志、操作记录以及订单信息等数据往往会保存在SQLite数据库中。随着软件的运行,数据库的数据量会逐渐增加,最终会达到100GB至1TB。在传统数据库恢复方法中,由于未考虑大数据量的情况,恢复时会消耗大量的内存空间和时间。
预写日志作为一种用于替换回滚日志机制的新方案,在SQLite3.7版本被引入[1]。与回滚日志相比,其具有更快的检索速度和更新速度,并且对多线程操作有着良好的支持。在此方法中,对数据库的操作不会直接修改数据库文件,而是预先记录到日志文件,当事务进入检查点时,日志文件中记录的操作会被同步到数据库文件。基于预写日志的恢复方法主要对日志文件进行分析,由于日志文件在使用结束后会被删除,因此对日志数据进行数据恢复时,需要先从文件系统中恢复被删除的预写日志文件,并对其进行处理与拼接。由于文件镜像本身空间较大,检索被删除的预写日志文件会消耗大量时间。
综上所述,在SQLite数据库的恢复过程中,存在某些耗时很大的操作,这些操作会影响数据库的恢复效率[2]。因此,对传统数据库恢复技术进行改进更新以提升恢复效率,这具有重要的理论意义和实际价值。
1 SQLite数据快速恢复原理
1.1 MapReduce概述
常用的大规模并行计算技术使用谷歌提出的MapReduce架构,该架构可以充分利用多台计算机的性能来提升运行速度。MapReduce由Map(映射)与Reduce(归纳)两个过程组成,其中,Map过程主要用来过滤、排序、分段处理等操作,而Reduce过程则主要用于数据的聚合操作[3-7]。在MapReduce架构中,通常会通过对分布式的服务器进行自动编组,并行运行各种任务,并且会管理分布式服务器各个部分之间的通信以及数据的传输,在这个过程中还会提供部分的冗余和容错机制,最终保证结果的可靠性。
MapReduce模型的使用过程中,根据其特性,将数据分析的过程转换为拆分、应用、组合这三个操作。虽然MapReduce模型的实际使用中和最开始的形式则有比较大的不同,但是它的灵感最早来源于函数式编程中的Map和Reduce函数,在单线程的实现中,使用MapReduce进行操作不会比传统的实现更快,它在多处理器硬件上的多线程实现中应用才能获得尽可能大的执行速度增益。在进行分布式操作时,最重要的过程是优化通信效率,这个对算法的良好运行至关重要。
1.2 MapReduce的并行编程模型
由前文可知,MapReduce编程模型是Google最先提出的[8],并定义了两个抽象的编程接口:Map和Reduce。

式(1)处理的是k2、v2这样的一组数据,这个数据在Map方法中会作为键值对传入,在了Map方法计算完成后,会得到另一种形式的键值对,这个键值对的结果类似[(k2;v2)]。
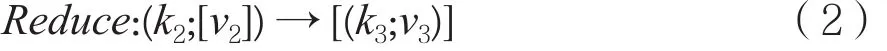
在式(2)中,传入的参数由Map方法生成,参数为一组键值对,其形式为k2;[v2]。其中,v2是一个集合,对于Reduce操作来说,相同的键可能会产生多个不同的值,因此在Reduce操作的过程中,会将所有相同键的数据整合到同一个集合中来进行统一的规划。在这里,Map方法得到的中间结果会进行类似整合的处理操作,最终的实际结果也会是一对键值对,其形式类似[(k3;v3)]。
经过上面对MapReduce的基本介绍后,Map Reduce操作可以对现有的逻辑结构进行划分,得到了图1中的并行计算模型。图1中表达了MapReduce模型的基本处理过程,该过程主要分成4步:
(1)对数据本身进行分片,并在Map操作中对每一片的数据分别并行进行处理,得到中间结果;
(2)Reduce操作会接收Map操作中给出的执行结果,并按照一定的逻辑进行数据处理;
(3)只有当所有的Map操作都完成任务,Reduce操作才实际处理Map产生的数据;
(4)在Reduce完成操作后,需要对其结果继续进行整合得到最终结果。
1.3 Hadoop系统构架
Hadoop是一款比较流行的MapReduce编程框架,其由Java语言完成,而且是一款开源的项目。其主要采用了谷歌公司提出的MapReduce方法[9-10]。Hadoop系统的基本构成如图2所示[11]。Hadoop系统的本质操作是基于分布式的存储和多个服务器的并行计算。Hadoop中主要包含两种节点,分别是NameNode和DataNode。其中NameNode的主要作用是保存分布式存储中整个文件存储系统的元数据,而DataNode则主要作为存储大数据的基本节点。Hadoop主要部署在Linux操作系统中,很多实现都依赖了Linux的一些功能,比如,在并行计算的主体架构中,Hadoop就使用了JobTracker,这是一个管理节点和计算时间的工具,Hadoop主要用这个工具来计算框架执行时间和不同任务的规划管理。
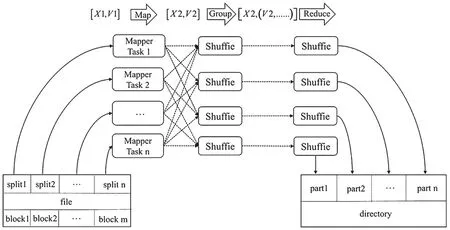
图1 MapReduce并行编程模型

图2 Hadoop系统的基本组成架构
在Hadoop的本地化计算中,DataNode和Task Tracker两个操作都会合并到同一个节点中,换句话说,每个节点都会同时完成DataNode与TaskTracker两个部分的操作,所以每个TaskTracker都可以计算当前DataNode中的数据。
NameNode和JobTracker分别作为数据存储节点和作业执行节点也可以配置到相同的节点中。而在大规模的集群中,由于主节点的负载可能会非常庞大,从而导致互相之间出现性能冲突,此时可以为两个节点各自配置相关的参数到不同的节点中。
2 预写日志结构分析
2.1 预写日志基本说明
在新版本的SQLite中,所有数据库的操作预先记录到日志文件中,当事务进入检查点时,日志文件中记录的操作会一次性同步到数据库文件。由此可见,在预写日志中包含了所有数据库相关的操作信息。
在大多数情况下,预写日志文件会在完成数据写入操作后被删除。因此,在数据库恢复过程中,需要对硬盘镜像文件进行预处理,从中恢复已经被删除的预写日志文件。在常见的硬盘镜像类型中,手机的硬盘镜像大小一般为16GB到128GB。而服务器的硬盘镜像则至少为50GB,甚至上TB级别。这些镜像文件进行文件恢复需要消耗大量时间,对恢复速度有很大的影响。因此,本文引入了MapReduce技术,使用MapReduce进行被删除预写日志文件的恢复操作。
2.2 预写日志格式解析
预写日志是一种二进制的存储结构,其主要包含了日志逻辑结构、日志头结构和Frame块结构。
一个日志文件由零到多个Frame块组成,前32个字节为日志头部。日志头部中主要记载了日志的版本、B树页的节点个数、校验码等信息,其主要描述如表1所示。日志头部还包含两组随机数值,其主要用于判断多个Frame是否属于同一条记录。图3是在二进制文件查看工具中得到的一个日志文件头部的基本构造。

表1 日志文件头部说明

图3 预写日志头结构
Frame块主要由头部和具体包含数据的B树结构组成,其中,头部为固定的24个字节,具体的字段说明见表2所示。其主要包含数据部分的逻辑页号和提交事务后数据库的理论大小。图4是在二进制文件查看工具中得到的一个Frame块头部的基本构造。

表2 Frame块头描述信息

图4 Frame 头结构
Frame块数据部分的大小通常为1 024个字节或者4 096个字节,这个大小主要和SQLite的默认配置有关,在我们采用EXT4文件格式中,一般会采用4 096个字节,也就是4KB的大小来限制Frame部分的体积。由于在数据库操作的过程中,数据往往会大于4 096字节,Frame数据文件会有多个,保存在文件系统不连续的数据空间上。因此,在恢复数据之前,还需要对这些Frame块进行拼接,然后才能进行基于预写日志的数据恢复。
3 基于预写日志的恢复算法
3.1 预写日志的文件提取方法
Android设备中默认会开启预写日志文件的功能,在预写日志中可能包含了被删除的SQLite数据信息,因此,基于SQLite预写日志的数据库恢复方法可以通过在系统镜像文件中搜索日志的Frame块并拼接,从中提取出被删除的数据来实现。数据恢复的总体架构如图5所示。在基于预写日志的SQLite数据恢复过程中,主要可以分成两个步骤:第一步,从硬盘镜像中恢复被删除的预写日志文件;第二步,从预写日志中恢复数据库信息。
本文恢复方法步骤说明如下:
(1)将手机连上电脑,或者直接在服务器上使用dd命令获取到镜像文件,作为恢复的基础数据文件;
(2)利用MapReduce方法扫描镜像文件,从中恢复出日志文件的数据,并利用这些数据拼接出有效的Frame块;
(3)利用MapReduce提取数据页中的记录,执行恢复操作后,将数据写入到用于恢复的数据库中;
(4)处理恢复数据库,并删除其中重复出现的数据。
(5)综上,该方法可以概述为,从镜像文件中提取出预写日志文件并将预写日志中保存的数据提取出来后,还原到原来的数据库中。

图5 方法总体框架
3.2 基于日志文件的的SQLite数据库快速恢复算法
在本文基于预写日志的SQLite数据库恢复过程中,Map操作主要用于对硬盘镜像文件的块结构进行分析,从中获取必要的信息,包括块类型、子块的偏移值,以及块中的文件信息等等。其中,对于头部块,需要从中获取到其他所有块的偏移值信息,对于数据块部分,则需要从中提取所有被删除以及未被删除的文件信息,如文件名、文件数据等等。块数据的Map操作具体的伪代码如算法1所示。
算法1 对块数据的Map操作:
Input:硬盘文件块偏移值
Output:恢复出来的预写日志文件
1.page ← 根据块偏移值获取页
2.blockType ← 从block中获取块的类型
3.if blockType == headerType then
4.offsets ←获取所有子块的偏移值
5.return offsets # 返回偏移值,对这些偏移值继续进行Map操作
6.else
7.fileData = []
8.while haveDeletedFile # 遍历当前块中所有被删除的文件节点
9.if checkFile # 检查文件的后缀以及文件中的魔法数
10.从dataPage中获取数据信息
11.fileData(data)
12.end if
13.end while
算法1主要用于获取每个数据块的内容,在第一次执行的时候,传入的镜像偏移值为0,用来提取B-tree结构中根节点的基本信息,完成了提取后会继续调用Map任务,将下面子块的偏移值作为参数来继续进行处理。当获取到了数据块后,对块中的文件名进行分析,提取后缀为wal的文件,并对数据进行初步分析,提取出头部信息来判断是否为预写日志文件。如果确定为需要的预写日志文件,则将该预写日志文件发送给Reduce任务进行后续处理。
在Reduce操作中,主要进行的工作是对Map生成的预写日志数据进行处理,并进行整合操作。在这里主要的任务是根据预写日志的魔法数和时间戳信息,对预写日志进行重组,并对其提取,然后得到需要的信息。Reduce的伪代码如算法2所示。
算法2 预写日志文件恢复的Reduce操作:
Define:恢复出来的数据recoveryData
存在预写日志中的魔法数,用来标志对应的数据库magicNumber1和magicNumber2
Input:恢复出来的预写日志文件数据data
Output:恢复出来的数据库
1.recoveryDatas = []
2.magicNumber1,magicNumber2 ← 从文件数据data中获取魔法数
3.if checkMagicNumber(magicNumber1,magicNumber2): # 检查魔法数是否为当前数据库的
4.recoveryData = recoveryByWSL(data) // 将相关的数据信息提取出来
5.recoveryDatas.add(recoveryData) # 将恢复结果添加到恢复数据集合中
6.end if
7.对recoveryData的数据去重
8.return recoveryData
算法2的操作中,核心部分是重组操作,并进行深度检查,抛弃不符合要求的预写日志文件。该方法中会先从文件中提取出魔法数,然后与当前数据库的魔法数进行比较,确定无误后,提取出文件中的历史操作记录,经过去重操作后,记录到数据库内。
4 实验及结果分析
4.1 实验准备
本文通过在物理机上搭建Hadoop集群实现,有4台独立的服务器用于实验的进行,其中1台用于运行单机的数据库恢复程序,另外3台则用于搭建集群服务,来运行本章基于集群的数据库恢复程序。这4台的服务器配置相同,均采用了4核2.6 GHz i7-6700 CPU,内存为8G,各拥有50GB的SSD硬盘空间。均安装了Ubuntu 16.04的操作系统,并更新到了最新版。3台集群服务器安装了Hadoop3.0.1。分别部署了3套测试环境,它们分别为:
(1)Android手机,使用Android8.0系统,硬盘容量为256GB;
(2)Linux服务器,使用Ubuntu16.04操作系统,其硬盘容量为256GB;
(3)Linux服务器,使用Ubuntu16.04操作系统,硬盘容量为512GB。
在这些测试环境中,分别利用了脚本,创建了1GB大小的数据库文件,并对数据库文件各自做了随机50次的插入删除操作,每次插入删除操作均会先删除30%的数据,再增加30%的数据。
4.2 实验设计
本节实验的目标是测试提出的基于MapReduce的数据恢复方法的有效性。实验步骤如下:
(1)获取256GB A(手机镜像)、256GB B(服务器镜像)、512GB三个不同大小的镜像文件;
(2)使用本章方法对三个不同大小的镜像文件,进行恢复;
(3)使用传统预写日志恢复方法对三个不同大小的镜像文件,进行恢复;
(4)对恢复结果进行统计和分析。
4.3 实验结果和分析
通过本文提出的方法进行恢复实验,实验的最终结果是从人工数据集(一共1 500万条记录)中恢复出了1 360万条有效数据记录(重复记录自动去除)。通过分析镜像发现,重复记录是因为修改的数据页还未同步到数据库中,几乎每个数据页都存在多个历史版本,表3展示了镜像中恢复出的部分数据记录。

表3 人工数据集恢复记录部分结果
本章使用恢复时间对实验方法进行评估。对于人工数据集的恢复,方法的准确率是0.907。结果(只展示时长)如图6所示。
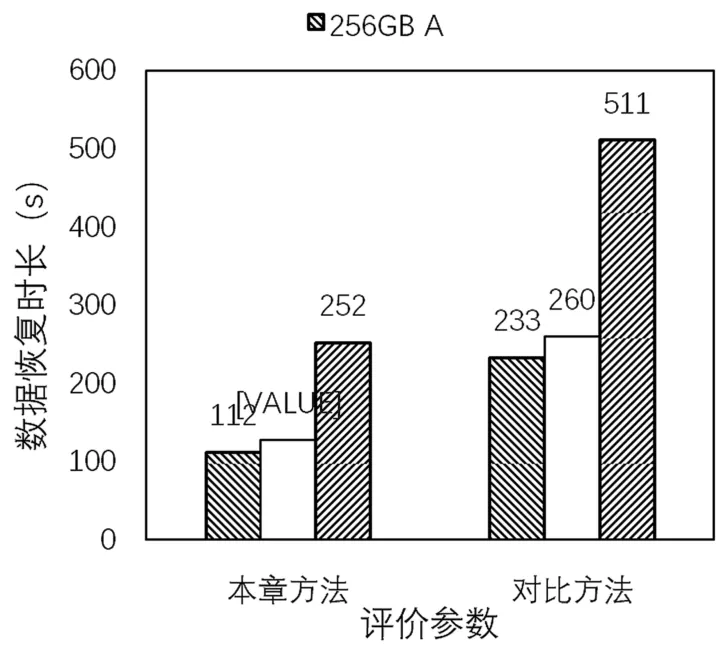
图6 人工数据集恢复结果对比
由图6可知,当恢复方法一定时,恢复时间基本和文件系统镜像的大小成正比关系,而对于相同大小的文件系统镜像,其操作系统的区别也会影响恢复时间;当文件系统镜像一定时,本章方法的恢复速度比原来的方法均要快2倍左右,因为此处采用的镜像文件体积较大,集群服务器之间的操作交互不会对数据恢复带来更大的影响。
使用对比方法(单服务器)也是以人工数据库作为恢复样本,对比方法恢复1 360万条有效数据记录,准确率为0.907。与本章方法的恢复效果对比如图7所示。从图7可以得到,文件大小在256 GB以上的时候,文件大小本身对SQLite数据的恢复速度影响是恒定的,通过实验结果分析可知,本文方法相对于传统恢复方法,速度提升了2倍,进一步证明了本方法的有效性。

图7 人工数据集恢复速度比值
5 结 语
本文提出了一个利用MapReduce来提升基于预写日志的SQLite数据恢复速度的方法。在利用SQLite预写日志恢复数据的过程中,需要从文件系统中检索出所有被删除的日志文件,这个操作的耗时非常庞大,并且由于预写日志的数据量会非常多,在拼接处理的过程中,也需要消耗较多的计算量。在本章中使用了MapReduce技术提升了这些过程的速度。通过研究现有的恢复方法,将恢复过程划分为检索镜像文件提取被删除的日志信息、利用头部特征定位符合条件的日志首页、根据头部结构的随机数继续从镜像中提取目标数据库的数据页并拼接这几个操作,其中第一步和最后一步的检索操作可以使用MapReduce来提升运行速度。通过比较使用了MapReduce技术的恢复方法和未使用该技术的恢复方法的运行速度,验证速度的提升效果。通过人工数据集的实验,验证方法的可行性和有效性。但是,在利用本文方法进行数据恢复时,发现Hadoop中网络延时对计算时间有一定影响,那么针对这种时间影响在后续研究中找出一定的规律性,也会对该类研究问题做出一定的贡献。
