基于Python的Web数据挖掘应用
2019-08-30韦建国王建勇
韦建国,王建勇
(阜阳职业技术学院,安徽 阜阳 236000)
近年来,大数据与云计算等技术迅猛发展,各行各业积累出来的大量数据也由此引起了人们的高度重视,如何从这些积累的数据中挖掘出有价值的信息,成为了人们研究的热点,数据挖掘技术也由此兴盛起来,Python在数据挖掘领域中的地位也逐渐突显出来,成为较热门的数据挖掘工具之一。Python是一种面向对象的开源程序设计语言,它的语法结构较为简单,它是由Guido van Rossum开发的,它具有丰富的库和丰富的API。运用其中的sklearn、pandas以及numpy等工具库,将会有效地提高数据挖掘效率。[1]本文主要是基于Python对网络学习平台积累的数据进行挖掘分析,以期挖掘出有参考意义的数据信息。
1 Web数据挖掘概述
Web数据挖掘(web data mining)最早起源于1996年,是数据挖掘技术与Web技术相结合的产物,又称知识发现。此技术主要通过从网页中积累的大量数据信息中抽取出有意义的信息,然后通过数据挖掘处理,挖掘出其中隐藏的数据信息,分析现有的数据,根据数据呈现出来的结果进行预测性判断。随着大数据技术和Web技术的大力发展,Web数据挖掘已成为数据挖掘领域中使用较为广泛的应用之一,通过Web挖掘可以实现用户行为的分析,通过分析挖掘出有参考价值的规则。从长远来看,具有较大的商业和科研价值。[2]Web数据挖掘的流程(见图1)。
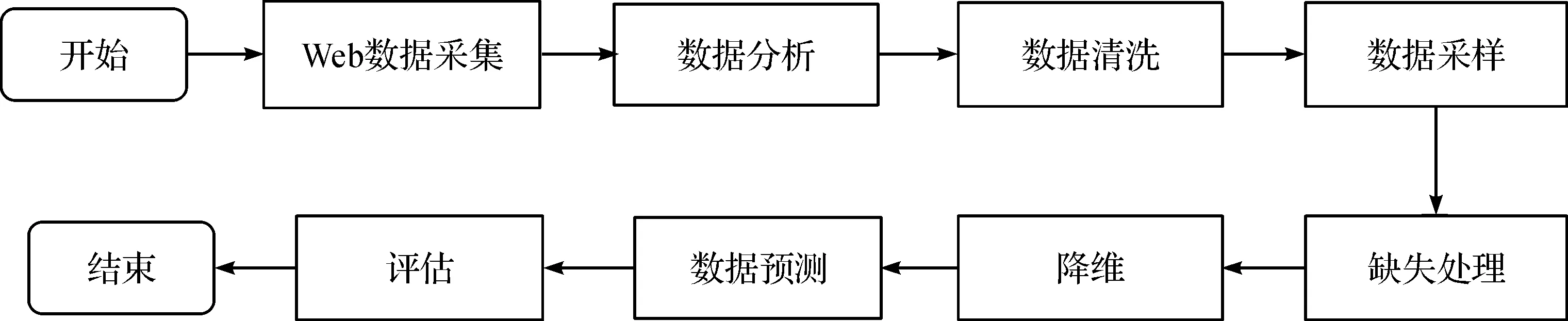
图1 Web数据挖掘流程
2 数据挖掘常用的Python库
(1)Sklearn
Sklearn库是数据挖掘中的核心工具库之一,是基于Python语言编写的,该库中提供了数据挖掘中的大量算法,如分类算法、回归算法、降维算法等,同时还有这些算法的使用接口和调试工具,是一种简单有效的数据挖掘工具。[3]
(2)Pandas与Numpy
Pandas和Numpy也是Python数据挖掘技术中的核心工具库成员,其中Numpy是基于Python开发的,支持多种运算的开源工具库,具有较高的运算性能,同时还提供了多种数学计算工具;而Pandas库是在Numpy基础上开发的数据分析工具包,根据统计结果进行数据清洗、缺失处理、降噪等操作,实现对数据的有效处理。[4]
(3)Openpyxl库
Openpyxl是一个用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库,其功能非常强大。Excel表格可以理解为一个二维矩阵,行用1,2,3,4,5……等表示,在Openpyxl可以用来作为行索引。列用A,B,C,D,E,……表示,在Openpyxl中可以用来当作列索引,描述一个单元格的位置需要一个行标、一个列标。
(4)Pymongo库
Pymongo是一个通过Mongo DB操作的封装库来实现对Mongo DB的使用,Pymongo是Mongo DB Driver的Python实现版本。此库将Mongo DB数据库的驱动环境与Python版本进行了有效的连接。使用pymongo可以对本地或者远程服务器的Mongo DB数据库进行链接,获取到数据资源之后,再将有用的信息以文档的形式导入数据库。[5]
3 基于Python的Web数据挖掘
Python语言是一种面向对象的具有良好的解释性和交互性能的程序设计脚本语言,目前应用较为广泛,运用Python语言编写的程序具有以下优点:
(1)具有高效的程序开发与维护性能;
(2)可读性强;
(3)使用此脚本语言所编写的结构化代码较为简洁易懂,适合于初学者。
Python脚本语言所具有的以上优点使其一跃成为当前主流的程序设计语言。[6]其主要的功能主要体现在以下方面:
(1)网络爬虫
随着计算机网络技术的迅猛发展,网络上积累了大量的数据信息。日益增长的大量自定向数据获取需要和大量的数据搜索需求推动了爬虫技术的兴起,同时也带动了搜索引擎技术的不断发展。网络爬虫(Spider)又称为网页蜘蛛,是通过预定义的一组规则获取信息的脚本或程序。Python脚本语言在网络爬虫设计方面具有自己的优势。[7]
(2)Scraping
Scraping自动网络爬虫框架是基于Python语言开发的,它可以实现数据的定向爬取。首先设计好爬虫规则,然后在实际运行中,输入规则,就可以快速获取到所需数据。Scraping程序主要是靠TCP传输控制协议与Web服务器实现数据传递,数据交互主要是依靠HTTP超文本传输协议与Web服务器实现。爬取首先由HTTP的交互模块向Web端口发起TCP的请求,再向Web服务器发出HTTP的报文请求,HTTP得到Web服务器的应答后进行包拆封,从拆封的包中提出数据并进行解析,最后将提取出来的数据进行存储。由于网络上的信息资源大多是无结构化的文本,这就增加了网络信息资源进行分类的难度。[8]
4 网络学习平台数据采集及分析
根据Web数据挖掘的流程,首先进行数据采集,实验所需数据来源于2018—2019学年度第1学期使用的《HTML5前端开发》这门课程的网络学习平台,通过一段时间的使用生成的日志数据,将其导出并保存为Excel的格式是最简洁的,然后利用Python程序中的openpyxl库,读取其中的日志信息,同时进行数据转换,转换后的文档格式另存为Excel文件,导出的部分日志数据(见表1)。
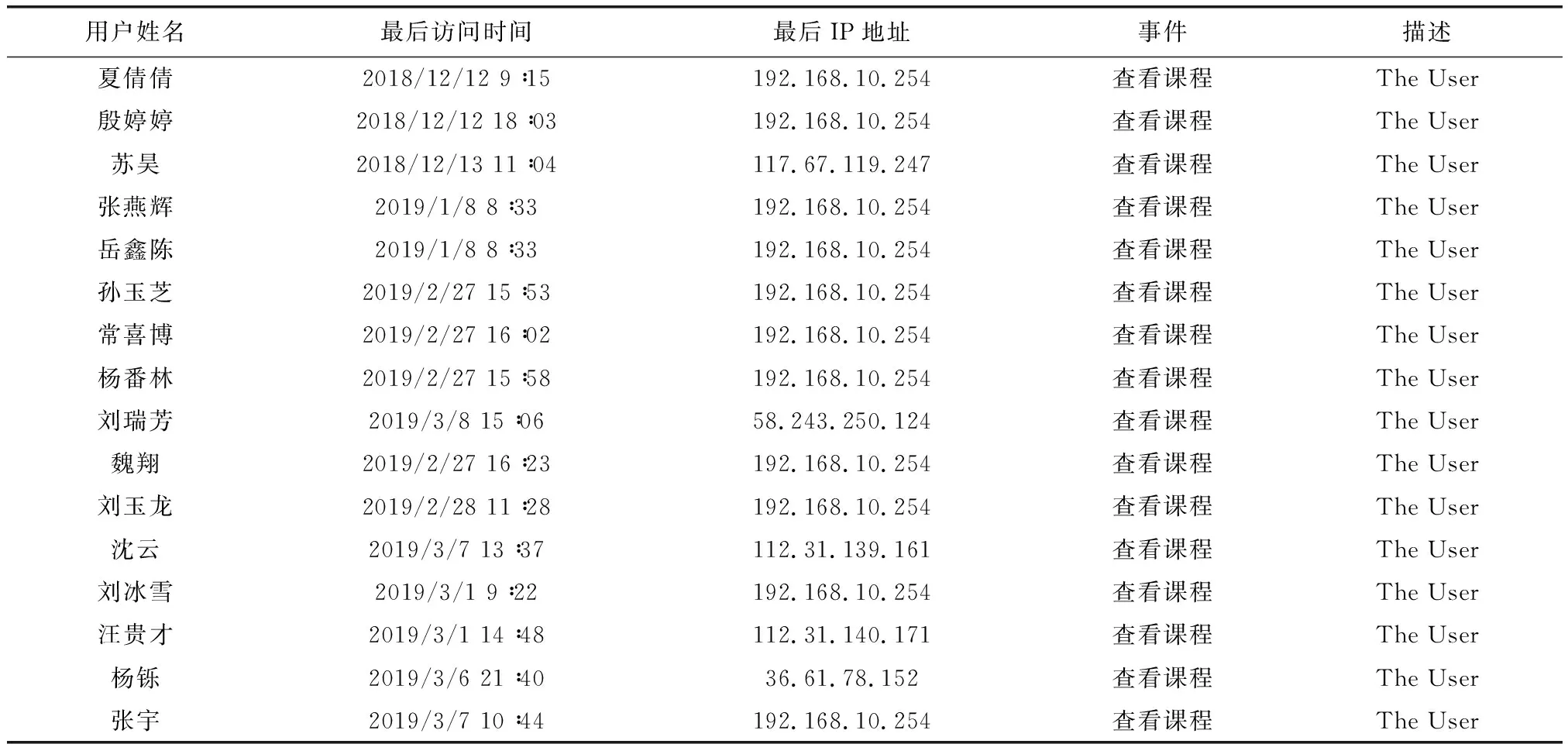
表1 导出的部分日志数据
(1)数据预处理
数据预处理(data preprocessing)是指在主要的处理以前对数据进行的一些处理,因为初始收集的数据可能不是来源于同一个数据源,格式也有可能存在差异,也存在缺失、重复、不一致等问题的可能,在此种情况下数据分析出现偏差的可能性较大,所以数据预处理是非常关键的一步。
数据预处理一般没有标准规范的步骤,针对不同的任务、不同的数据集属性,其数据预处理的步骤也不会相同。但大多数情况下,数据预处理都要经过数据清理、数据集成、数据规约及数据变换的操作。数据清理主要负责处理缺失值、噪声平滑、识别处理离群点等操作任务,并纠正数据中的不一致等技术来进行;数据集成主要指集成多种数据源,数据集成需要考虑许多因素,例如多个不同来源信息的实体识别、数据的冗余等问题因素。数据规约主要指数据的简化表示,随着大数据的出现,基于传统无监督学习的数据分析变得非常耗时和复杂,往往使得分析不可行。数据归约主要是数据集的规约表示,在尽量保持数据完整性的同时大大减小数据集的规模。对规约后的数据集分析将更有效;数据变换主要是针对数据的规范化、离散化及概念分层等的处理。[9]
由于本文收集的数据来源于同一个数据源,数据源较为单一,不存在数据缺失等问题,所以数据预处理相对简单。
(2)数据分析
本文选择阜阳职业技术学院工程科技学院的2017、2018级计算机应用、计算机网络班所使用的网络学习平台课程《HTML5前端开发》生成的日志数据作为数据源,数据选择使用Excel格式进行导出,读取日志数据利用Python编写程序来实现,同时对日志数据进行数据预处理,将预处理后的日志数据进行保存。从导出的数据中分析出平台学习人数随时间的变化规律,然后利用Matplotlib绘制分析结果图,绘制出的图形(见图2)。
Matplotlib是一个2D绘图库,利用Matplotlib库,可以绘制出直方图、折线图、饼图、散点图等,以Matplotlib可实现数据的可视化,直观展示数据的分析结果,本文就是通过调用Matplotlib绘图库实现对网络学习平台的日志数据进行分析生成可视化图形。
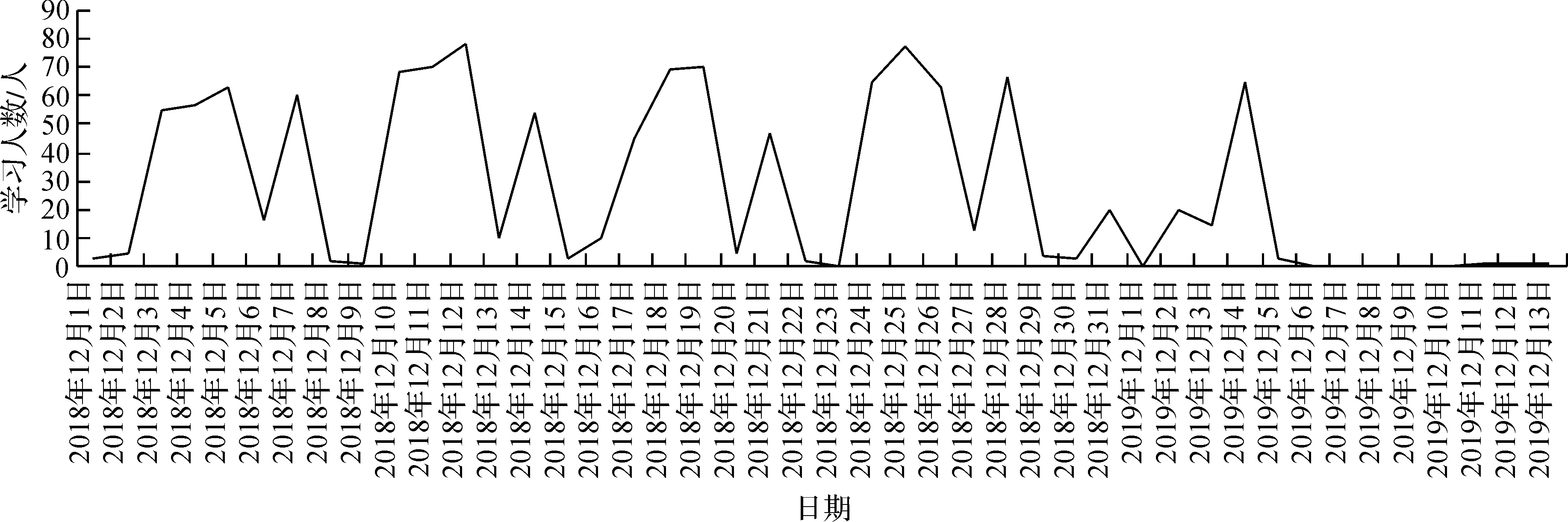
图2 学习平台人数随日期的变化图
由图2看出,网络学习平台的学习人数随日期有一定的变化规律,2018—2019学年度第1学期,该们课程在每周1、周2、周3、周5均有开设,学生在课堂上使用网络学习平台学习、做作业的人数最多,这点与图示所显示的变化规律是相一致的。教师可以根据这一规律在课外时间完善平台学习资源,设置课程内容,布置作业等,以期在课堂上有更丰富的内容教学,优化教学过程,提升教学效果。
5 结语
随着网络的逐步普及,大数据时代的推进,Web数据挖掘已成为研究的热门趋势领域。Python作为Web数据挖掘领域中比较热门的语言,已成为数据挖掘过程中不可替代的工具,它具有丰富的各种库和强大的计算能力。本文主要基于Python语言对网络学习平台积累的日志数据进行Web数据挖掘和分析,进而挖掘出一些有规律的信息,以辅助于教师的教学,提升教学效果。
