基于服务机器人听觉的个体膳食构成自主感知算法
2019-08-21苏志东杨观赐王怀豹
苏志东,杨观赐,李 杨,王怀豹
(贵州大学现代制造技术教育部重点实验室,贵州贵阳550025)
随着人口老龄化问题的日益严重,越来越多的独居老人需要照顾[1],护老、助老等家庭服务机器人深受国内外学者关注。为了识别老年人摔倒,Do等人提出了RiSH服务机器人平台,集成了服务机器人、智能家居设备和可穿戴设备,能对跌倒老人及时实施救助[2]。为了给老年人提供一种更便捷的人机交互方式,刘策等人提出了一种集成语音识别、远程控制、人脸识别、手势识别等交互模式的人机交互方法,并提高了交互速度,消除了对网络的依赖性[3]。为了应对年龄增长后记忆力衰退的情况,文献[4]提出了一种基于家庭服务机器人的大脑训练方法。通过调查老年人的生理特征和心理特征,有研究从马斯洛需求理论出发,提出了一种侧重于符合用户感情需要的服务机器人系统,让机器人提供服务更加人性化[5]。为了增强老年人的体质,降低老年人摔倒的风险,文献[6]提出了利用机器人视觉系统识别和跟踪用户行为的方法,通过提供相关的练习和反馈来激励用户的训练。Zhou等人提出了一种基于服务机器人的远程医疗系统,该系统将家庭成员和医生建立连接,利用自动健康数据采集技术和目标检测算法实现远程护理[7]。Fernandes等人构建了老年人认知评估服务机器人平台,通过分析使用者的答案,了解他们的认知状态,为医生诊断使用者的健康状况提供依据[8]。
有研究表明[9]:科学合理的饮食不仅有利于保持身体健康,也对疾病的治疗有着非常重要的作用。文献[10,11]提供了一种方法来获取用户的饮食信息,该方法通过监听进食的声音判断当前用户是否吃食物以及所吃食物类别。但是在家庭环境下,进食声音通常较小,麦克风较难捕获大多数的进食声音,并且多数进食声音较难分辨,例如喝水的声音、喝牛奶的声音、饮啤酒的声音等。
整体上,当前的服务机器人虽然能够借助可穿戴设备等传感器采集用户的部分健康数据,但通过机器人听觉或者视觉自主感知用户饮食信息的研究有待深入研究。本文研究基于服务机器人听觉的个体膳食构成自主感知算法,当机器人听到用户表达时,自主对其表达内容进行处理,最终获取相应的饮食信息,从而实现对用户膳食构成的智能感知,为用户医疗诊断、饮食干预和机器人的主动服务等提供决策依据。
1 基于梅尔频率倒谱系数与矢量量化算法的声纹识别方法
考虑到家庭成员不止一个,准确地识别说话人的身份是实现饮食信息准确感知的前提。为了利用声纹辨识说话人的身份,本文采用39维的梅尔频率倒谱系数[12](Mel Frequency Cepstrum Coefficient,MFCC)作为声纹识别算法的特征向量,选取计算量较小、运行速度快且识别效果较好的矢量量化模型[13](Vector Quantization,VQ)作为声纹分类模型(MFCC-VQ)。
2 基于服务机器人听觉的个体膳食构成自主感知算法
2.1 文本语言特征获取与词库构建
当机器人通过听觉系统获得听觉信息后,即可运用语音识别方法获得所听到内容的文本信息。为了理解文本信息所表达的内容,本文通过采用哈工大LTP[14]系统的中文分词、词性标注和依存句法分析工具对文本数据进行处理,获取文本语言特征(最小语言单位、词性、语言单位间的依存关系)作为下文个体膳食构成自主感知算法的输入特征。
考虑到用户表达的饮食文本中存在着大量的水果、蔬菜、成品菜、奶类、肉类等专业词汇,仅仅依靠分词系统LTP中的通用词典难以对食物名称准确识别。因此本文参考《中华人民共和国国家标准GB 2760-2014》[15]中附录E的食物分类系统以及利用网络爬虫技术,构建了具有1563个日常生活中常见的食物名词库。
之后,将新建的食物名词库与所用的中文分词工具中的默认词典进行融合并去除重复的名词,构成食物名词相对完善的新分词词典Lexicon。
2.2 个体膳食构成获取方法
对于机器人监听获取的语音信息中关于膳食信息的描述主要分为两个方面。一个方面,说话者的表达内容可能与“吃”相关但实际上并未摄入该食物,例如“我爱吃超市买的苹果”、“喜欢吃苹果”、“现在非常想吃苹果”等,虽然这些表达都包含进食动作与相对应的食物名称,但是实际上说话人只是表达了一种喜好或偏爱,并没有摄入该食物。另一个方面,说话者表达的内容是饮食信息之外的其它信息却能间接反映食物摄入记录。为了确定饮食组成,确定进食行为是否真的发生是一个关键因素,因此首先需要确定进食动作是否真正发生,然后基于所发生的进食动作进行食物信息抽取,从而获得用户的饮食信息。为了描述的直观性和方便,我们引入一阶谓词逻辑理论描述推理计算逻辑。
2.2.1 面向谓词逻辑推理的语言单元定义
令sentence={word1,word2, …,wordi, …,wordN}表示语言单元集合,该集合是单个用户的饮食表达内容的中文分词结果,其中wordi为分词后的语言单位,N为饮食表达内容中语言单位的个数。
记Veat={“吃”,“喝”,“享用”,“品尝”,“尝”,“品”,“来”,“试”}为表示动作特征词单元集,其元素能够表达进食的含义。
记Vnegative={“想”,“喜欢”,“爱”,“喜爱”,“没有”,“没”,“不”,“讨厌”,“厌恶”,“反感”}为进食动作否定词集合,其元素表达喜欢、意愿、好恶等含义。当一段句子中出现Veat中的元素,并且在该元素前出现Vnegative中的元素时,根据语言表达习惯可以判定进食动作未发生。
记Venhance={“了”,”的”}为表达动作已经完成的语言单元集合。
记Vcuisine={“炒”, “爆炒”, “蒸”, “清蒸”,“煮”,“炸”,“油炸”,“炖”, “煎”, “油煎”,“醋溜”,“烤”, “烧”, “凉拌”,“拌”, “焖”}为表示烹饪方式的语言单元集合。
记Wcomment={“味道”,“好吃”,”难吃”, ”有味”}为表示暗含进食行为的语言单元集合。
记Wjump={“闭门羹”,“亏”,“哑巴亏”}为表达可以与“吃”相配合出现的欺骗性语言单元集合。
同时,假设Tword-1,Tword和Tword+1∈sentence为相邻的语言单元。基于中文语言表达模式,当Tword∈Veat时,可以判断用户的表达内容可能具有吃了某种食物的含义。因此,通过判断Tword-1与Vnegative之间的关系和Tword+1与Venhance之间的关系,我们可以判断说话人“吃”这个动作是否真正发生,进而判断说话人真实的进食构成。如果Tword∈sentence且Tword-1∈Vnegative,则可以判断Tword并未表达真实吃这个动作;如果Tword∈sentence,Tword-1∩Vnegative=且Tword+1∈Venhance,则可以判断Tword真实表达了吃这个动作。
2.2.2 基于一阶谓词逻辑理论的逻辑推理
根据上述定义和分析,利用一阶谓词逻辑理论,建立公式(1)所示的谓词逻辑推理公式判断“吃”这个动作是否发生。

其中Contains(A,a)用于判断集合A是否包含元素a,RealEat(Tword)是谓词逻辑推理的逻辑结果,若该值为真,则判断说话人已经吃了与Tword相关联的食物;若该值为假则判断Tword并未表达真实吃这个动作。
当RealEat(Tword)的值为真时,则对Tword的上下文语言单元进行分析,获取进食信息。
(1)对于Tword之前的语言单元,如果Tword与下一个动词Tword+m或者最后的那个语言单元Tend之间不存在食物名词,并且存在Tword-n∈Wcomment,其中Tword-n出现在Tword之前,则可以判断Tword之前存在目标食物名词,谓词逻辑推理公式(2)可以用来判断Tword之前是否存在目标食物名词。

其中Tword+m是Tword之后的名词,Tword+m∩Vcuisine=∅,Tword-n是Tword之前的语言单元,NoFoodNames(a,b)用于判断a与b之间是否存在食物名称,该值为真则说明a与b之间存在食物名称;ExistBefore(Tword)用于判断Tword之前是否具有目标食物名词,该值为真则说明Tword之前具有目标食物名词。
(2)当ExistBefore(Tword)为真,如果Tword-n-i为一个动词且Tword-n-i∩Vcuisine=∅,则停止遍历;如果Tword-n-i为一个名词且存在于词典中,则Tword-n-i为目标饮食信息。利用谓词逻辑公式(3)和(4)即可遍历获得食物名词。

其中Tword-n-i为Tword-N之前的语言单元,用于Verb(Tword-n-i)判断Tword-n-i的词性是否为动词,Stop(Tword-n-i)用于判断遍历是否结束,Lexicon为所构建的分词词典,EatFood(B)为谓词逻辑推理的逻辑结果,当其值为真时,表明说话人已经吃了食物B。
(3)对于Tword之后的名词,如果Tword之后的一个名词属于Lexicon,或者Tword之后的下一个动词属于Vcuisine,则从Tword开始向后遍历;否则对Tword之后的语言单元进行依存句法分析。谓词推理公式(5)可以用来判断利用何种模式来对Tword之后的语言单元进行处理进而获取目标食物名词。

其中nextnoun(Tword)为Tword之后的下一个名词,nextverb(Tword)为Tword之后的下一个动词,Traverse(Tword)为真时,采用遍历法获取食物信息;为假时,采用依存句法分析的方式抽取食物信息。
(4)如果Traverse(Tword)为真,则利用公式(3)和公式(4)遍历Tword之后的语言单元。
(5)如果Traverse(Tword)为假,对及其之后的语言单元进行依存句法分析,并利用以下规则抽取食物名称。
①如果Tword+1=“了”,则令起始词Tstart=Tword;
②如果Tword+1=“的”,则令起始词Tstart=Tword+j,其中Tword+j为与Tword+1构成主谓关系(SBV)的语言单元;
③若wordk与Tstart构成动宾关系(VOB)且wordk∩Wjump=∅,wordm与wordk构成并列关系(COO)且wordm∩Wjump=∅,则可判定wordm与wordk为目标食物名词。基于上述推理构造谓词推理公式(6)与(7):

其中RelationVOB(A,B)和RelationCOO(A,B)用来判断A与B之间的动宾关系和并列关系。
④若wordN∈Veat,且与Tstart构成并列关系,则与wordN构成动宾关系的wordkn且wordkn∩Wjump=∅,与wordkn构成并列关系(COO)的wordmn且wordmn∩Wjump=∅,为目标食物名词。上述描述可用谓词逻辑公式(8)与公式(9)表示。


⑤若Tafter∈Vcuisine且与Tword构成并列关系(COO),则输出前一个与下一个名词作为饮食信息。

其中Near(wordk,wordnear)用于判断wordk的前一个语言单元的词性与后一个语言单元的词性是否为名词。
⑥若VCOO(Tafter,Tword)为真,且Tafter∩Vcuisine=∅,Tafter∩Veat=∅,则停止抽取由Tword触发的饮食信息。

2.2.3 饮食组成获取的推理算法
基于上述的定义和描述,本文设计了如算法1所示的获取饮食组成的推理算法。
算法1:获取饮食组成的推理算法
输入:Sentence={word1,word2, … ,wordi, …,wordN}
输出:目标饮食信息集合Food;
1)初始化Food=∅;
2)For each wordiin Sentence:
(1)利用公式(1)计算RealEat(wordi)的逻辑值;
(2)If RealEat(wordi)==TRUE,Then
a)利用公式(2)计算ExistBefore(wordi)的逻辑值;
b)If ExistBefore(wordi)==TRUE,Then
SubSentence={wordi,wordi-1,…,word1};
For Twordin SubSentence
利用公式(3)计算Stop(Tword-n-i)的逻辑值;
利用公式(4)计算EatFood(Tword-n-i)的逻辑值;
If Stop(Tword-n-i)==TRUE,Then Break
If EatFood(Tword-n-i),Then Food=Food∪Tword-n-i;
c)利用公式(5)计算Traverse(wordi)的逻辑值;
d)If Traverse(wordi)==TRUE,Then
SubSentence={wordi,wordi+1,…,wordN};
For Twordin SubSentence
利用公式(3)计算Stop(Tword-n-i)的逻辑值;
利用公式(4)计算EatFood(Tword-n-i)的逻辑值;
If Stop(Tword-n-i)==TRUE,Then Break;
If EatFood(Tword-n-i),Then Food=Food∪Tword-n-i;
e)OTHERWISE
(a)令SubSentence={wordi,wordi+1,…,wordn};
(b)对SubSentence进行依存句法分析;
(c)For Twordin SubSentence
①利用公式(6)计算EatFood(wordk)的逻辑值;
②If EatFood(wordk)==TRUE,Then
Food=Food∪wordk;
利用公式(7)计算EatFood(wordm)的逻辑值;
If EatFood(wordm)==TRUE,Then Food=Food∪wordm;
③利用公式(8)计算EatFood(wordkm)的逻辑值;
④If EatFood(wordkn),Then
Food=Food∪wordkn;
利用公式(9)计算EatFood(wordkm)的逻辑值;
If EatFood(wordkm),Then Food=Food∪wordkm;
⑤利用公式(10)计算EatFood(wordafter)的逻辑
值;
⑥If EatFood(wordafter),Then Food=Food∪wordafter;
⑦利用公式(11)计算EatFood(wordafter)的逻辑值;
⑧If EatFood(wordafter),Then Break;Return Food.
2.3 基于服务机器人听觉的个体膳食构成自主感知算法
当机器人的听觉系统获取用户语音数据以后,首先通过声纹识别算法确认用户的身份信息,然后利用语音识别技术将语音信息转换为文本信息,最后对文本信息进行预处理,并依据本文所设计的个体膳食构成自主感知推理规则算法获取目标饮食信息。因此,可得算法2所示的基于服务机器人听觉的个体膳食构成自主感知算法。
算法2:基于服务机器人听觉的个体膳食构成自主感知算法
输入:用户输入的语音数据A与分词词库Lexicon;
输出:Fooda={Food1,Food2, …,Foodi,Foodm},其中Foodi为第i个用户的膳食构成集合,m为用户数目;
1)载入用户输入的语音数据A与分词词库Lexicon;
2)利用MFCC-VQ方法的识别过程进行声纹识别,获取语音数据A所对应的身份i;
3)利用语音识别方法将A转化为文本数据T;
4)对T进行中文分词、词性标注和依存句法分析处理,获取T的语言特征F;
5)将F输入算法1中,获取饮食信息Food;
6)匹配身份i与Food,输出Fooda={Food1,Food2,..,Foodm};
算法2中,语音识别技术利用科大讯飞的在线语音识别框架,中文分词、词性标注和依存句法分析借助哈工大LTP提供的算法实现。
3 性能测试分析
3.1 服务机器人平台
图1为课题组搭建的服务机器人平台(MAT)[16],包括Intel NUC主机、数据采集设备和机械支架等部分组成。用于显示数据和图像的显示屏是7.9寸IPad mini 4显示屏;听觉系统采用科大讯飞六麦环形麦克风阵列板,其具有声源定位、回声消除、噪声过滤等功能,用以实现对音频信号的采集;视觉系统采用的是Microsoft Kinect V2深度摄像头,用于采集RGB彩色图像;服务机器人主机为Intel NUC mini主机,配置i7-6770HQ处理器和Intel IRIS Pro显卡;移动底盘为EAI DashGO B1。服务机器人主机采用Ubuntu16.04操作系统,并在系统中安装了Kinect版本ROS(Robot Operation System)系统、TensorFlow CPU版本深度学习框架和OpenCV3.3.0。采用DELL TOWER 5810工作站降低服务机器人的运算负荷,主要用于模型训练和数据分析。工作站采用Ubuntu16.04操作系统,并在系统中安装了Kinect版本ROS(Robot Operation System)系统、TensorFlow GPU版本深度学习框架和OpenCV3.3.0。服务机器人与工作站均具有无线通信模块,用于端到端的通信。课题组运用Python语言在此机器人平台上实现了AIDCPA算法。

图1 服务机器人平台Fig.1 The used social robot platform
3.2 训练与测试数据集
3.2.1 声纹识别系统的训练数据
为了使训练完成的声纹识别模型在真实应用场景下具有较好的表现,本文直接利用MAT服务机器人的六麦环形麦克风阵列收集训练语音数据。该训练数据集涉及20人,每人通过朗读给定的文本信息,录制收集30条语音数据,每一条语音数据持续10 s。
3.2.2 膳食构成感知算法的测试数据
为了测试算法的性能,建立了测试语音数据集。此数据集的文本内容包括以下两种类型:
1)类别a:依据中文语言表达习惯而设计的文本。此类数据共100条样本数据,涉及六种情境,具体为:(a)直接说明进食内容;(b)表达出想吃/打算吃/渴望吃某些食物;(c)混合了(a)与(b)的表达方式;(d)具有暗示性的进食内容表达;(e)具有较多冗余表达的进食表达;(f)欺骗性的语言表达方式。
2)类别b:在线收集的文本。30名参与者根据自己的说话习惯,在线提交了表述用餐情况的数据,共收集样本120个。经删除无效数据,保留了100条样本数据。该类数据体现了真实生活场景的表达情况,表达方式多样,具有较大随意性,主要用于考查算法的鲁棒性。
之后,为了便于测试,从3.2.1节声纹识别系统的20人中随机选取3人,分别用普通话按平时说话的方式说出a和b两类数据的文本信息,从而录制获得测试语音数据。测试语音数据的总长度为32 min 23 s,包括200个句子和1035个食物实体名词。后文测试时,模拟人说话的方式播放测试数据。
3.3 评价标准
当所获取的食物名词与人工标注的标签相匹配,同时与相应的身份信息相匹配时,则判定该食物名词被正确识别。本系统的识别结果中存在样本中标签数目为零或者识别出来的食物名词数目为零的情况,记Nt为一个样本中手工标注的标签食物数目,Nr为系统所识别出的食物构成数目,Nc为系统所识别出的食物与手工标注样本的食物所匹配的食物数目。召回率R、精确度P与F1评价指标[17]用于评价系统的性能。
1)精确度P值。正确识别出的食物数目占系统所识别出的食物数目的比例,计算方式为

其中Nbase为具有歧义或者意愿性表达的样本中所包含的食物名词数目的最大值。在本文中,将其设置为10。
2)召回率R。正确识别出的食物数目占所标注的食物数目的比例,计算方式为
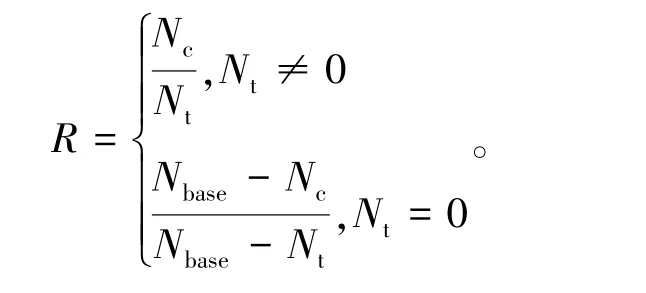
3)F1评价指标值。精确度P与召回率R的综合衡量值,计算方式为

3.4 测试结果与分析
利用两类测试数据集对所提出的AIDCPA算法进行测试,对测试结果进行统计,其中表1为不同类型测试数据F1、精确率P和召回率R的统计结果,图2为F1、P和R指标的统计盒图。
观察表1可知:1)a类数据F1值均值为0.9505,方差为0.0118,具有较高的F1值均值,并且方差较小,说明系统对本文所考虑的语言表达模式能够以较大的概率正确识别出饮食信息;2)由于b类测试数据收集于30名不同的大学生,具有较大的随意性和不确定性,使得b类测试数据对应的测试结果比a类测试数据稍微差一些,F1值均值下降了0.0028,F1值的方差值上升了0.0215,这表明不同的语言表达方式对系统的识别性能有一定的影响。但F1值均值与方差值变化幅度不大,这表明系统具有良好的鲁棒性,在模拟真实生活场景的测试数据中仍然具有较好的识别效果;3)a、b两类测试数据的平均F1值、精确率P和召回率R分别为0.9491,0.9679和0.9407,精确度P值比召回率R值高出0.0272,根据精确度和召回率的定义可以看出,系统所识别出的食物数目略少于所标注的食物数目。由于不同说话人口音、语音识别系统准确率、中文分词以及推理算法等因素的影响,会导致系统所识别出的食物数目少于所标注的食物数目,进而使得精确度P值高于召回率R值。

图2 F 1、P和R指标统计盒图Fig.2 Boxplot of F 1,P and R
观察图2可知:1)图2(a)中F1值的统计盒图中位线均处于1.0位置,a类数据矩形面积较小,b类数据矩形面积为零,说明系统对这两类数据均具有较好的识别效果。同时两类数据的异常值的分布较为分散,大部分均分布在0.7以上,且b类数据比a类数据具有更多且更分散的异常值,这表明虽然系统在整体上具有良好的识别效果,但是由于语言表达的随意性等特点,对于少部分测试数据,系统需要进一步完善。2)从图2(b)和图2(c)可以看出,两类数据的P值和R值均存在少量的离群点,但是大部分离群点处于0.6以上,其中a类数据的大部分离群点处于0.8以上,b类数据离群点分布比a类数据具有更大的离散性,b类数据来源的多样性导致了这种离散性。但是这并未影响系统整体性能,两类数据的中位线均处于1.0位置,且矩形面积非常小,这表明即使测试数据存在较大的随意性,系统仍然具有较好的识别性能。
综上可知,对于所考虑的语言表达模式以及模拟真实场景随机收集的语言表达,AIDCPA算法的F1值、精确度与召回率的均值分别为0.9491,0.9679和0.9407,能以较高的准确率感知用户的饮食信息,具有良好的识别效果和鲁棒性。
4 结束语
机器人智能的感知用户膳食构成,可为居家养老提供智能装备支持。本文正是针对机器人所监听到的语音信息,提出了基于服务机器人听觉的个体膳食构成自主感知算法。通过运用声纹识别方法获取说话人身份后,可以利用所设计的食物获取推理算法,就可以建立用户的饮食信息数据库,这可为医疗诊断、饮食干预和机器人的主动服务等提供决策依据,有利于服务老年人生活。下一步工作将考虑环境以及说话人口音等因素对算法性能的影响,进一步提高算法的鲁棒性和识别的准确率。
