一种低复杂度SCMA多用户检测算法
2019-08-20朱翠涛
朱翠涛,吴 蓓
(中南民族大学 智能无线通信湖北省重点实验室,湖北 武汉 430074)
稀疏码多址接入(Sparse Code Multiple Access,SCMA),是应5G需求设计产生的一种非正交多址技术。其非正交叠加的码字个数可以成几倍大于使用的资源块个数,从而大大提高了频谱利用率。为了使稀疏码多址接入成为更具竞争力的空口技术,需要解决的关键问题是性能优良的码本设计及低复杂度的多用户检测算法。笔者研究的重点在于多用户检测算法。
利用稀疏码多址接入码字的稀疏结构[1],基站能够通过低复杂度的消息传递算法(Message Passing Algorithm,MPA)实现接近最大后验概率检测和最大似然检测。然而,在多用户情况下,各用户的发送信号在接收端叠加[2],随着用户数的增加,消息传递算法译码的复杂度将呈指数增长。为了减少复杂度,文献[3]提出了线性滤波高斯近似置信传播算法,迭代地消除干扰。文献[4-5]提出了边选择高斯近似算法,将信道质量作为边选择的标准,对部分边使用高斯近似。文献[6]基于天线和子载波,结合了最大似然和高斯近似两种检测方法。文献[7]基于滑行窗口,选择活跃用户参与信号检测和信道译码,而部分不活跃用户将干扰近似为高斯随机变量。文献[8]中提出了一种低复杂度的高斯近似算法,将不连续消息近似为连续高斯分布消息,使复杂度从指数增长降为线性增长。文献[9]基于最小化相对熵,通过在非正交多址接入系统中使用高斯近似的方法降低复杂度,该方法同样适用于稀疏码多址接入系统。
综上所述,在上行稀疏码多址接入系统中,为了进一步降低多用户检测算法的复杂度,提出了一种基于部分资源块高斯近似的多用户检测算法。此算法中,稀疏码多址接入因子图将变成动态且更为稀疏的因子图,通过合理选择资源块个数n来降低检测的复杂度。
1 系统与信号模型
在上行稀疏码多址接入系统中,假设有J个用户,K个时频资源块,过载因子可以表示为λ=J/K。每个用户都有不同的码本,Xj为第j个用户的码本,M是码本中码字个数(即码本大小),bj是二进制信息。对于每一个用户j(j=1,2,…,J),编码比特流bj通过编码器映射为码本中的码字xj。稀疏码多址接入码字的稀疏性,可以通过两类码字非零位置的集合表示。Rj为第j个用户占用资源块的集合,Fk为第k个资源块上分布用户的集合,对应每列和每行非零元素的数量分别为dJ和dR。
不同用户信号非正交叠加,经过信道传输后,基站在第k个时频资源块上的接收信号可以表示为
(1)
式中,hk,j表示时频资源块k上用户j的信道系数,nk表示在时频资源块k上所叠加的加性高斯白噪声。
2 消息传递算法性能分析
由于稀疏码多址接入码字具有稀疏性,因此可以利用消息传递算法[10]对稀疏码多址接入系统中多用户进行检测,从而降低检测算法的复杂度。稀疏码多址接入的结构可以用指示矩阵和因子图来表示,如图1所示。一般地,在因子图中有两类节点,方形代表资源节点rk,也表示时频资源块k,圆形代表用户节点uj,也表示用户j。而在指示矩阵中,行代表时频资源块,列代表用户。fk,j=1,表示第k个资源块和第j个用户相连。
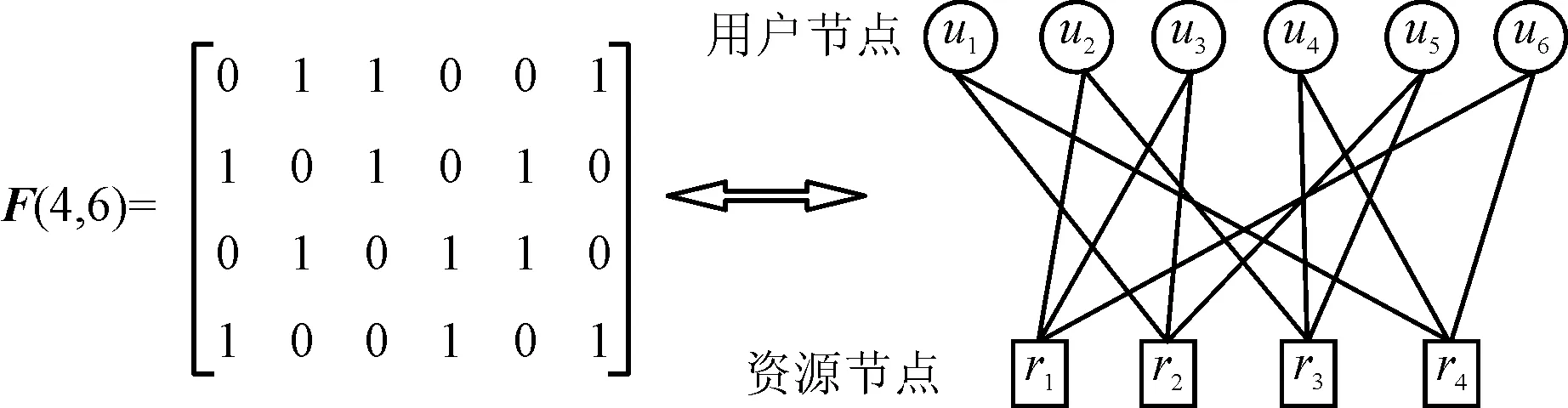
图1 稀疏码多址接入指示矩阵和因子图关系
消息传递算法的检测过程可以分为3步:
(1)计算初始概率,即
(2)
(2)消息迭代更新,更新资源节点和用户节点,即
(3)
(4)
式中,~xj表示符号xj的边缘概率;l∈Fk/j,表示在第k个资源块上分布的用户集合Fk中除去用户j以外的其余用户;m∈Rj/k,表示第j个用户所占用的资源块集合Rj中除去资源块k以外的其余资源块。
(3)在达到最大迭代次数tmax后,计算用户各码字输出概率,即
(5)
基于并行调度策略的消息传递算法,对所有消息以并行的方式进行更新[11],导致收敛速度慢。因此可以串行更新消息,已更新的消息在同一次迭代过程中及时参与其他节点的消息更新,从而有效地提高收敛速度。串行消息传递算法(Serial Message Passing Algorithm,SMPA)中资源节点更新可以表示为
(6)
虽然串行消息传递能加快收敛速度,但是消息传递算法的复杂度问题并未得到解决。从原始消息传递算法检测过程来看,复杂度主要来自于资源节点更新[12],其总的乘法计算量约为tmaxKMdR。为了降低复杂度,最有效的方法就是减小参数tmax以及dR。而从因子图的结构来看,如果只有部分边参与到资源节点给用户节点更新中,其余边传递的消息近似为高斯分布,那么通过合理选择,就可以在复杂度和性能之间进行灵活调节,从而应用到多种场合中。基于此,笔者提出了基于部分资源块高斯近似的消息传递算法(Partially Gaussian Approximation-Message Passing Algorithm,PGA-MPA)。
3 基于部分资源块高斯近似的消息传递算法
PGA-MPA算法的基本思想是对部分资源块使用加权消息传递算法,而剩下的资源块使用高斯近似消息传递算法。另外,每次迭代后剔除1个用户,这样不但能保证误码率(Symbol Error Rate,SER)性能,还能有效降低多用户检测复杂度。此算法需要解决三个关键问题:一是选择哪部分消息近似为高斯变量,二是如何进行高斯近似,三是选择怎样的用户进行剔除。
下面将进行具体介绍。
3.1 资源块优势等级分析
通过大量实验发现,在稀疏码多址接入系统中,基于消息传递算法对部分资源块进行高斯近似时,资源块存在译码优势等级。按照时频资源块被处理的先后顺序,给每个时频资源块分配一个优势等级,例如给时频资源块k分配的优势等级依次为1,2,3,…,K。优势等级越高,表示译码优势越大,译码的可靠性越高。于是,选择译码优势等级较高的n个资源块进行消息加权,剩下的译码优势等级较低的资源块进行高斯近似。
假设有6个用户,4个时频资源块。当n=4时,所有资源块在资源节点更新时进行消息加权;当n=0时,相当于在资源节点更新时对所有外部消息进行高斯近似。基于部分资源块的高斯近似则介于两者之中。当n=3时,表示有3个优势等级较高的资源块进行消息加权,剩下的一个资源块进行高斯近似。同理可得,当n取值为2和1时,表示分别有优势等级较高的两个资源块和一个资源块进行消息加权,剩下的资源块进行高斯近似。
3.2 基于高斯近似的消息传递算法

图2 高斯近似的资源节点更新示意图
在一次迭代过程中,当资源节点进行更新时,资源节点利用用户节点传来的消息更新对应的用户节点。若将这些外部消息视作干扰,则干扰和噪声项[13]可以近似为高斯分布。
图2所示是高斯近似的资源节点更新过程,其中同一资源块上叠加的用户数dR=3。在因子图中,当资源块k对用户j传递消息时,在连接到同一资源块的所有用户边中,只有一条边ek,j传递消息,而对其余边传递的消息近似为高斯分布,因此用户有效边数d=1。式(1)可以改写为
(7)
假设信道系数hk,j服从独立同分布的高斯分布,均值为0,方差为1;噪声nk为加性高斯噪声,均值为0,方差为σ2。将干扰噪声项近似为高斯分布,其中Zk,j~Ν(μΖk,j,σZk,j)。
为了提高性能,可以使均值参与迭代。将当前迭代中更新的均值作为反馈信息用在下一次迭代中,并且参与资源节点的更新过程,方差则保持初始值不变,不进行迭代更新。因此,在第t次迭代过程中,均值和方差分别为
(8)
(9)
于是,基于均值迭代的资源节点更新为
(10)
由于接收信号与叠加码字组合之间的关系,可以用欧氏距离表示。距离越短,代表叠加码字组合越靠近接收信号,正确解的概率越大。因此,通过加权因子改变初始概率[14],越靠近接收信号,获得的初始概率越大,从而提高正确译码率。
首先,将初始概率按照从大到小的顺序进行排序,划分为Q个集合,相同集合分配相同的加权因子,不同集合分配不同的加权因子。叠加码字的概率值越大,就会获得越大的加权因子,其满足下式:
(11)
然后,将初始概率与相应的加权因子αq相乘,使得越靠近接收信号,获得越大的初始值。根据式(2),初始概率的计算为
Φk=αq·Φk。
(12)
3.3 联合资源块和用户优势等级
为了进一步降低算法的复杂度,联合资源块和用户优势等级,根据资源块优势等级排序以及用户码字结构,可以得到用户优势等级。将译码优势用户进行降序排列,在每次迭代后对译码优势等级较高的用户直接译码并剔除[15]。

图3 每次迭代剔除1个用户
如图3所示,有6个用户,4个时频资源块。根据图1中稀疏码多址接入因子矩阵的结构,从上至下,依次给每行时频资源块分配1,2,3,4,总共4个优势等级,那么根据每列中用户占用资源块的集合,即非零元素的位置,就可以计算出每个用户的优势等级。例如用户1的非零元素集合R1={2,4},则用户优势等级为资源块优势等级2和4相加,结果为6;用户2的非零元素集合R2={1,3},则用户优势等级为资源块优势等级1和3相加,结果为4。同样的方法,计算出其余4个用户的优势等级分别为3,7,5,5。于是,按照优势等级的降序排序,第1次迭代剔除的是用户4,第2次迭代剔除的是用户1,后面依次剔除用户5、用户6、用户2以及用户3。在6次迭代后所有用户都被译码。
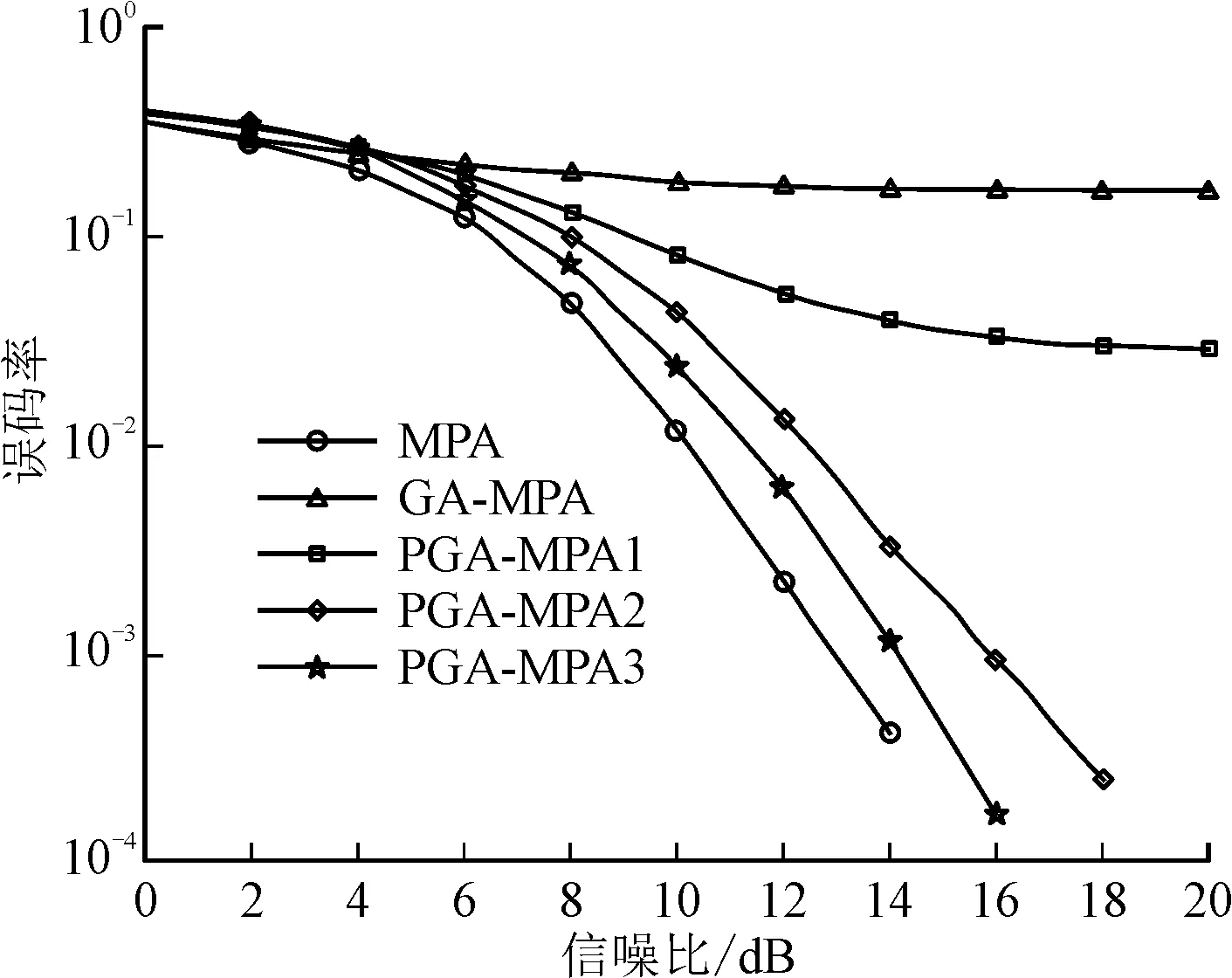
原始消息传递算法的复杂度主要在于资源节点更新,且主要与tmaxKMdR有关。基于部分资源块高斯近似的消息传递算法降低了与复杂度相关的重要参数dR,即单个资源块上所叠加的用户数,进行消息加权的资源块个数n(1≤n 表1为两种算法的复杂度比较,其中Οt=f(t,n,M,dR,K)。在每次迭代过程中,资源节点进行更新时,连接到同一资源块的用户有效边数1≤d≤dR,并且随着每次迭代剔除一位用户,复杂度将越来越小。与此同时,改变消息调度策略以及引入加权因子能提升收敛速度,从而进一步减少迭代所需次数tmax。 表1 复杂度比较 笔者提出算法的主要改进在于降低了最大迭代次数tmax以及参数dR。由于限制了这两个关键因素,因此有效地降低了复杂度。针对5G海量连接的需求,当承载用户数量越大时,基于部分资源块高斯近似的消息传递算法在降低计算复杂度上的优势将更为明显。 对提出算法的误码率性能和收敛速度进行仿真分析。仿真中所用码本为华为公司给出的6×4码本,以及文献[16]中提出的基于网格编码调制的子集分割码本。参数设置为:码本大小M=4,时频资源块数K=4,用户数J=6,每个用户占用时频资源块数dJ=2,每个时频资源块上叠加用户数dR=3。 图4 不同算法的误码率性能比较 图5 未改变码本时误码率性能比较 图4为在3次迭代下,原始消息传递算法、串行消息传递算法以及全部高斯近似消息传递算法(Gaussian Approximation-Message Passing Algorithm,GA-MPA)的译码性能情况。从图4中可以看出,在迭代次数相同时,串行消息传递算法的误码率性能优于原始消息传递算法,说明基于串行消息传递机制要比基于并行消息传递机制更有优势。串行消息传递算法并不能降低复杂度,所以在串行消息传递机制的基础上,可以结合高斯近似的方法,进一步降低复杂度。另外,由于全部高斯近似不能充分利用外部消息,误码率性能较差,因此采用部分高斯近似方法。 图5为在3次迭代下,原始消息传递算法、全部高斯近似消息传递算法以及部分高斯近似消息传递算法的译码性能情况。从图5中可以看出,采用部分高斯近似算法时误码率性能得到了改善,但是曲线的收敛情况仍然不是很好。为了进一步改善检测性能,改变华为公司提出的码本,采用基于网格编码调制的子集分割码本,在不增加功率和频带利用率的条件下,降低系统的误码率。 图6 改变码本时误码率性能比较 图7 收敛速率比较 图6为在改变码本情况下的译码性能情况。从图6中可以看出,误码率性能得到了明显的提升,尤其是当信噪比升高时,性能提升更为明显。原始消息传递算法因为在资源节点更新时有效利用了所有节点的消息,所以性能最好。部分高斯近似比全部高斯近似性能好,并且随着进行消息加权的资源块个数n的增加,误码率性能越来越好,越接近原始消息传递算法。 图7为在采用子集分割码本情况下不同算法的收敛速率比较,其中信噪比为12dB。由于每次迭代后将剔除一位优势等级较高的用户,而6次迭代后所有用户都被译码,因此只给出部分高斯近似前6次迭代的收敛曲线。从图7中可以看出,原始消息传递算法在迭代次数达到5次后误码率才趋于稳定,全部高斯近似算法也需要迭代5次。随着n的不同,部分高斯近似算法需要的迭代次数也不同。当n=1时,需要3次迭代;当n=2时,同样需要3次迭代;当n=3时,只需要2次迭代。n越大,达到收敛时迭代次数越低,并且都小于其他两种算法所需迭代次数。另外,在迭代次数为1时,部分高斯近似算法在n=3的情况下要比原始消息传递算法的误码率小。随着迭代次数的增加,原始消息传递算法的误码率减小,性能更好。降低计算复杂度会在一定程度上带来性能损失,但是笔者提出的算法能够在误码率性能损失不大的情况下,极大程度地降低检测复杂度,并且能根据实际需要,通过改变参数n选择算法的误码率性能与计算复杂度。 针对多用户检测算法复杂度高的问题,笔者提出一种基于部分资源块高斯近似的多用户检测算法。此算法在资源节点更新时对部分译码优势等级较低的资源块使用高斯近似,并且联合资源块和用户优势等级,在每次迭代后剔除译码优势等级较高的用户,通过合理设置资源块个数,能够保证译码性能,降低译码复杂度。高斯近似尤其适用于承载大量用户的系统中,因此如何在多天线稀疏码多址接入系统中使用高斯近似来降低多用户检测的复杂度,将是下一步研究的主要内容。
4 仿真与分析



5 结束语
