基于机器学习的全参考图像质量评价模型泛化能力分析
2019-08-15马小雨姜秀华
马小雨,姜秀华
(中国传媒大学 信息与通信工程学院,北京100024)
1 引言
为了提高图像质量评价模型的预测准确率,近年来越来越多的研究人员尝试将机器学习及深度学习技术应用到图像质量评价领域中并取得了非常好的效果[1-5]。但是这些质量评价模型的准确性仅在有限的几个图像数据库中得到验证,如TID2013[6],CSIQ[7],LIVE[8]等。考虑到在实际应用场景中,图像质量评价模型需要估计大量具有不同内容、不同失真类型、不同失真程度的图像的感知质量,而由于机器学习中存在的过拟合,数据集效应等问题,这些基于机器学习的全参考图像质量评价模型(Full Reference Machine Learning based Image Quality Assessment,FRML-IQA)的准确性必然会有一定程度下降。就我们所知,目前还没有相关文献阐述FRML-IQA模型在实际应用场景中的准确性具体降低了多少、是否显著等问题。
本文通过大量主观实验,建立一个包含多达60幅原始图像的图像数据库CUC2018,由于其图像内容丰富程度远高于目前主流的图像数据库(TID2013包含25幅原始图像,LIVE包含29幅原始图像,CSIQ包含30幅原始图像),CUC2018被用来模拟实际应用场景中可能出现的图像内容。通过TID2013或CISQ训练得到的FRML-IQA模型,将在CUC2018图像数据库中进一步测试其预测准确性,从而估计各FRML-IQA模型的泛化能力。
后文的实验结果表明FRML-IQA模型的泛化能力较差,在CUC2018中的预测准确性和传统的图像质量评价模型(如MAD[6],FSIM[9]等)相比并没有显著性差别,并没有被用于实际的图像质量评价场景中的价值。
本文的主要结构如下,第一节主要介绍图像数据库CUC2018的建立方法;第二节主要对现存的FRML-IQA模型进行总结,设计了3种不同的FRML-IQA模型框架以及相应的27种FRML-IQA方法;第三节则利用CUC2018来测试这27种FRML-IQA模型的泛化能力,并和传统的全参考图像质量评价算法进行比较;第四节为分析和结论。
2 CUC2018图像数据库的建立方法
为了分析基于机器学习的图像质量评价模型(ML-IQA)的泛化能力,探究ML-IQA在实际应用场景中的预测准确度,本文建立了CUC2018数据库来模拟实际应用场景中可能出现的各种各样的图片内容。为了模拟实际应用场景的特点,CUC2018满足以下要求:
(1)真实应用场景中需要对大量不同内容的图像进行质量评价,因此CUC2018数据库包含的原始图像数量要远大于目前主流图像数据库。
(2)CUC2018应包含尽可能多的图像类型,如人物,风景,建筑,高/低饱和度图像,高/低空间复杂度图像等;尽可能多的拍摄方式,如特写、中景等。
因此本文利用相机拍摄、互联网下载等方式采集了60幅高清晰度原始图像,这些图像的部分缩略图如图1所示:

图1 CUC2018数据库中部分图像内容
我们用颜色饱和度均值(Saturation Mean)和空间复杂度(Spatial Information)两个指标来衡量数据库所包含图像的丰富程度,其中颜色饱和度均值通过将图像转换至HSV空间并计算S分量的均值得出;空间复杂度通过对图像亮度分量进行索贝尔滤波并计算滤波后图像的平方和得到。CUC2018数据库和TID2018数据库各原始图像的SM-SI分布情况如图2所示,可以看到新建立的CUC2018数据库的图像内容要比TID2013更加丰富。

图2 CUC2018数据库和TID2013数据库的图像内容丰富程度比较
对采集的60幅原始图像分别进行四种失真程度,四种失真类型(JPEG压缩、JPEG2000压缩、高斯模糊、白噪声)的失真处理,将得到960幅失真图像。在符合ITU-R BT500[10]的主观评价实验室中,我们组织20名打分人员利用单刺激质量标度法[10]对各失真图像的质量进行估计,最后利用文献[11]设计的数据处理方法得到各失真图像的主观质量分数(Mean Opinion Score,MOS)。
3 基于机器学习的全参考图像质量评价方法
由于目前并没有一种全参考图像质量评价算法(Full Reference Image Quality Assessment,FR-IQA)能够对所有失真类型的质量评价准确度都优于其它FR-IQA,因此研究人员尝试利用机器学习的方法将若干预测性能较好的FR-IQA算法的输出进行综合,从而得到更加准确的质量估计分数。
我们对目前的基于机器学习的全参考图像质量评价方法(FRML-IQA)进行总结,设计了三种FRML-IQA框架,其中框架1(FRML1)类似文献[2]设计的架构,利用机器学习将若干全参考算法的得分直接进行综合;框架2(FRML2)类似文献[3]设计的架构,将原始图像和失真图像进行多通道分解,在各个通道上分别利用某种全参考算法(如SSIM[12]或FSIM等)计算各通道的质量差异,最后将各通道的质量差异利用机器学习的方法综合成最终得分;框架3(FRML3)则是FRML1和FRML2的综合,即原始图像和失真图像进行多通道分解后,对每个通道都利用若干个全参考质量评价算法对其进行多维度的质量预测,再将各通道的多维度质量估计值综合,最后得到质量分数。
由于每一个框架可以利用不同的机器学习方法和多通道分解方法,因此各FRML-IQA框架可以有不同的实现方式,本文对27种ML-IQA算法进行测试,他们的具体实现方式如表1所示:其中机器学习方法可以有支持向量回归[13](Support Vector Regression,SVR)、神经网络[14](Neural Network,NN)、随机森林[15](Random Forest,RF)三种不同选择;多通道分解方法可以有小波变换[16](Digital Wavelet Transform,DWT)、高斯差分[17](Difference of Gaussian,DoG)、Log-Gabor(LG)[18]、可控金字塔分解[19](steerable Pyramid,Pyr)四种不同选择。
表1中的命名规则如下,以(18)FRML3-DoG-RF为例,其中FRML3表示采用框架3的整体结构,以高斯差分(DoG)作为多通道分解方法,并以随机森林(RF)作为回归工具。
4 实验设计及实验结果
为了定量地探究各FRML-IQA算法的泛化能力,本文设计了如图3所示的泛化能力验证流程。
我们分两个阶段对各FRML-IQA模型的泛化能力进行探究。在第一阶段,被测试的FRML-IQA模型在现存的数据集(TID2013或CSIQ)中进行训练和测试,数据集(TID2013或CSIQ)被分成训练集(80%)和测试集(20%),各FRML-IQA模型首先在测试集进行多次训练,由于支持向量回归和神经网络等机器学习算法的性能对一些参数的取值较为敏感(如支持向量回归中的惩罚参数C和核函数参数g,以及神经网络权重的初始值),各FRML-IQA模型在第一阶段中被重复多次进行训练和测试,从中取测试性能最好的模型参数作为最终参数。具体的说,对于SVR模型,采用网格搜索的方法选择最优的惩罚参数C和核函数参数g;神经网络模型分别采用大小为10,15,20,25的隐藏层并分别重复训练25 次;随机森林模型分别采用100,150,200,250个决策树并分别重复训练25次。
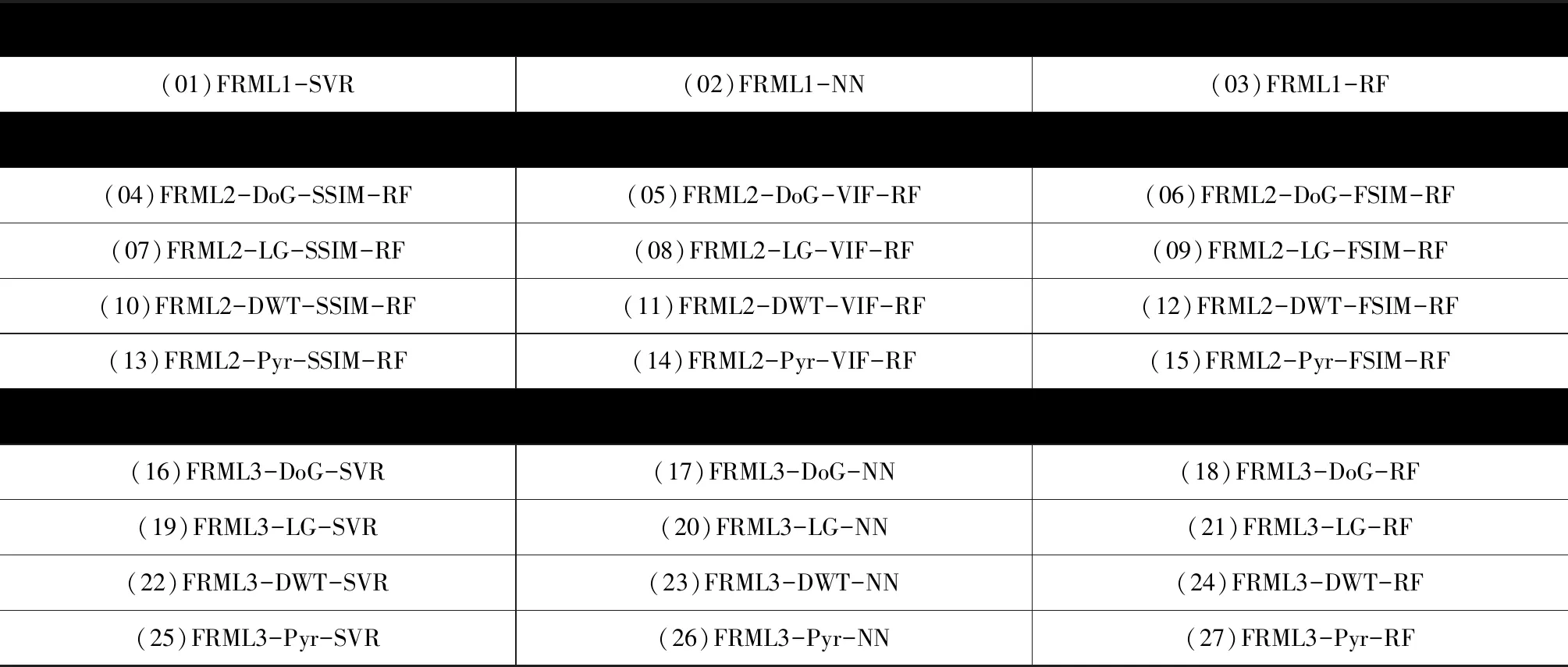
表1 3种FRML-IQA框架的不同实现方法

图3 FRML-IQA模型的训练-测试-验证流程
在第二阶段,各FRML-IQA选取在第一阶段中测试性能最好的模型参数,对CUC2018中的失真图像质量进行预测打分,并同CUC2018的主观数据对比得到预测性能。
各FRML-IQA模型在训练-测试数据库中的测试性能以及在CUC2018中的验证性能如图4所示。本文共采用皮尔逊线性相关系数(Pearson Linear Correlation Coefficient,PLCC)、斯皮尔曼等级相关系数(Spearman Rand order Coefficient Correlation Coefficient,SRCC)、肯德尔等级相关系数(Kendall Rand order Coefficient Correlation Coefficient,KRCC)、均方误差(Root Mean Square Error,RMSE)四种指标来衡量各模型的预测性能。图4中横坐标为各FRML-IQA模型(横坐标数字对应于表1中各FRML-IQA模型的序号),左上,右上,左下、右下四图分别反应各模型同主观数据的SRCC,KRCC,PLCC,RMSE。蓝色带加号线条表示各FRML-IQA模型在TID2013数据集中测试-训练时取得的最优测试性能;红色带圆圈线条表示各FRML-IQA模型在TID2013数据库中训练-测试并选取到最优模型参数后,在CUC2018数据库中的验证性能;黄色带圆点线条表示各FRML-IQA模型在CSIQ数据库中训练-测试时取得的最优测试性能;紫色带星号线条表示各FRML-IQA模型在CSIQ数据库中训练-测试并选取到最优模型参数后,在CUC2018数据库中的验证性能。

图4 各FRML-IQA模型的测试性能和验证性能
由图4可以看到,无论采用何种FRML-IQA模型结构,FRML-IQA模型在验证集CUC2018中的预测准确度要远远低于其在训练-测试集TID2013或CSIQ中的表现。进一步地,我们选取这27个算法中表现最好的算法FRML3-DoG-SVR,将其性能和未采用机器学习的全参考算法(如SSIM,VIF等)进行比较。其性能比较结果如表2所示。

表2FRML3-DoG-SVR和其它全参考算法的性能比较

续表
由表2可以得知,从数据上看FRML3_DoG_SVR的预测性能要略由于传统不采用机器学习的全参考图像质量评价算法。但进一步分析表明,这种轻微的预测准确度提升是没有统计显著性的。
我们对各算法同主观分数的RMSE为样本进行显著性分析,根据文献[10],构建如(1)所示的统计量,如果ξij的绝对值大于F(0.05,n1,n2)即1.124,则两个算法的RMSE值的差别具有统计显著性。
(1)
表2所示的16种算法相互间的显著性差别如图5所示。
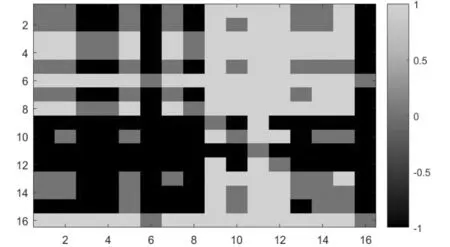
图5 各算法的RMSE显著性分析,其中横、纵坐标的1~16分别表示PSNR,VIF,SSIM,GMSD,FSIM,MAD,VSI,PSNR-HVS,UQI,SR-SSIM,VSNR,IFC,IW-SSIM,MS-SSIM,SFF,FRML3_DoG_SVR
由图5可以看到,尽管基于机器学习的全参考图像评价模型FRML3_DoG_SVR的RMSE要低于其它算法,但是其RMSE值同MAD算法的RMSE值并没有显著性差别。也就是说,尽管基于机器学习模型的将多种现存算法(包括MAD)进行非线性综合后可以在训练集取得非常好的性能提升,但这种性能提升在验证集中并不明显,其预测结果和主观值的RMSE甚至同MAD相比没有显著性差别。
5 结语
通过以上实验可以发现,基于机器学习的全参考图像质量评价模型确实可以在训练集和测试集上取得很高的预测准确性,但如果利用在给定数据库(TID2013或CSIQ)中训练好的FRML-IQA模型去预测新的数据库(如CUC2018)中失真图像的质量分数,FRML-IQA模型的预测准确度明显下降,甚至同MAD算法没有显著性差别。
也就是说,现有的FRML-IQA模型的泛化能力有限,很难被应用于实际的图像质量评价场景中。因为在真实的图像质量评价场景中,质量评价模型需要对大量没有出现在训练集中的失真图像进行质量估计,而从实验结果来看,同MAD,FSIM相比,FRML-IQA模型显然不具有明显的优势。
因此研究人员在设计图像质量评价模型时,可以将机器学习技术用于质量相关特征的提取等方面,而应尽量避免将带有主观分数的图像数据库直接作为训练集。另外,如果必须将图像数据库直接作为训练集,也可采用弱监督或有噪学习的训练方法来保证模型的泛化能力,我们将在后续工作中对其进行详细介绍。
