基于深度卷积神经网络和条件随机场模型的PolSAR图像地物分类方法
2019-08-07李卫华秦先祥余旺盛
胡 涛 李卫华 秦先祥* 王 鹏 余旺盛 李 军
①(空军工程大学信息与导航学院 西安 710077)
②(国防科技大学电子对抗学院 合肥 230037)
1 引言
极化合成孔径雷达(Polarimetric Synthetic Aperture Radar, PolSAR)是一种先进的遥感信息获取手段[1]。与单极化相比,它通过测量每个分辨单元在不同收发极化组合下的散射特性,更完整地记录了目标后向散射信息,为详尽分析目标散射特性提供了良好的数据支持[2]。PolSAR图像地物分类的目的在于将图像划分成一系列具有特定语义信息的图像区域,是PolSAR图像理解和解译过程中的重要内容[3]。
传统的PolSAR图像地物分类方法主要通过目标分解和统计分布来实现。极化数据的目标分解方法有很多,如Cloude分解[4]和Freeman分解等[5]。统计分布模型主要有Wishart分布[6]和K分布[7]等。Lee等人[6]将目标分解和分布模型结合,提出了-Wishart方法,有效提高了地物分类精度。然而,这类方法没有考虑图像的上下文信息,易受相干斑噪声影响,因此很多研究者开始关注利用上下文信息的地物分类方法[3,8]。文献[3]在融合极化特征的基础上通过条件随机场(Conditional Random Field, CRF)模型利用上下文信息,能够得到区域一致性好的结果。上述方法利用的特征主要包括基于极化矩阵的组合变换、基于目标分解理论的特征参数和纹理特征等[9]。这些特征通常是针对具体问题进行设计,对先验知识的依赖程度较高,在很多情况下其表征能力往往不尽人意。解决该问题的一种常用思路是从PolSAR图像中提取多种特征向量堆叠成一个高维特征向量用于地物分类,但提取的高维特征往往包含大量冗余不相关信息,将导致部分特征向量的分类能力减弱或丧失[10]。因此,如何提取更具表达性的特征是当前提高图像地物分类方法性能的关键途径。
目前,深度学习技术在PolSAR图像处理任务上的应用受到普遍关注,自编码器[11](Auto Encoders,AE)、深度信念网络[12](Deep Belief Network, DBN)和卷积神经网络[13](Convolutional Neural Network,CNN)等多种深度神经网络模型相继用于PolSAR图像处理,其中CNN在图像处理中应用最为广泛。近年来有很多学者将CNN用于PolSAR图像地物分类[14-16]。由于CNN网络输入一般为实数,在考虑相干矩阵各元素的基础上,文献[14]将PolSAR图像的复数相干矩阵转换为6维实向量来作为CNN模型的输入,提升了地物分类精度。文献[15]将CNN推广到复数域,有效利用了PolSAR图像通道间相干相位差蕴含的丰富信息。尽管上述基于深度学习的方法在地物分类精度上取得了显著提升,但与基于传统人工特征的方法相比,这些方法实现地物分类的速度普遍较慢。
针对图像地物分类问题,一些学者设计了直接实现光学图像地物分类的CNN模型,并展现出优异的性能[17-19]。考虑到不同类型图像之间往往存在共性,可认为,一个经过大型数据量训练好的CNN的前端网络可以作为图像特征提取的有效模型[20]。基于此并考虑到CRF的多特征和上下文信息利用优势,本文提出一种结合预训练CNN和CRF模型的图像地物分类方法。首先利用经典的CNN模型-VGGNet-16来提取图像深层次特征,再通过CRF对多特征及上下文信息有效利用来完成图像的地物分类。
2 深度CRF模型
针对传统图像地物分类方法受限于人工特征表征能力不强的问题,本文提出一种基于深度CRF模型的图像地物分类方法,采用VGG-Net-16提取图像深度特征,将提取到的特征用于训练CRF模型,实现图像地物分类。具体流程如图1所示,主要包含图像预处理、深度特征提取和分类3个阶段。
2.1 极化SAR图像预处理
对于PolSAR数据, 每个像素点用T矩阵的9维向量来表示如式(1)
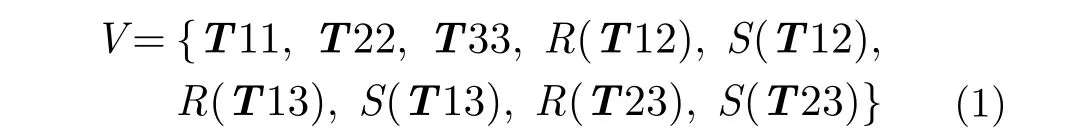

图1 深度CRF模型流程图Fig. 1 The flow chart of deep CRF model
2.2 深度特征提取
VGG-Net-16[19]是一种用于实现图像分类任务的卷积神经网络。其中的“16”表示该模型需要学习参数的层数。VGG-Net-16主要由5个卷积层(conv)(共13层)和3个连接层组成。其中,从conv1到conv5每组卷积层分别包含2, 2, 3, 3, 3层卷积,每个卷积层都使用尺寸为3×3的卷积核。在ImageNet数据集上训练后,VGG-Net-16中每个卷积层都可以作为一个特征提取器,提取目标不同层级的特征表达。
VGG-Net-16模型要求输入图像尺寸为224×224,因此,需要将其分割为多个不重叠的尺寸为224×224的小图像,再将这些图像输入到VGGNet-16中提取深度特征,其中,VGG-Net-16是在ImageNet数据集上已经完成预训练的网络。当输入图像尺寸小于224×224时,需要在输入数据的边界进行补0操作。将所有小图像利用VGG-Net-16提取完特征后,由于VGG-Net-16模型中的池化(pooling)操作,会使得提取到的深度特征的尺寸小于输入图像。采用的CRF模型需将提取到的特征与输入图像每个像素点逐一对应,因此将VGG-Net-16模型中提取到的特征图采用双线性插值方法上采样到原图像大小,然后将这些特征图重新拼接,最终得到与实验图像同尺寸的多维特征图,即可认为,为实验图像中的每个像素点提取到多维深度特征。在VGG-Net-16前5层提取的特征都是由多张特征图组成,故前5层都可作为特征提取层。VGG-Net-16后3层为全连接层,提取到的特征都是1维列向量,不适合作为训练本文CRF模型的特征。
2.3 CRF模型建立

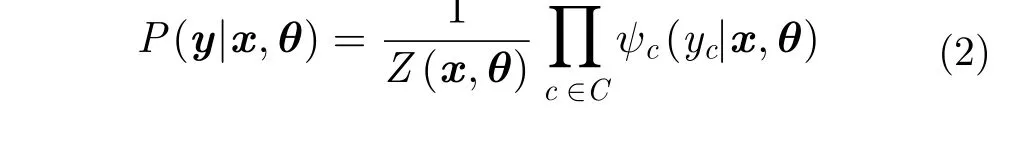
势函数阶数的确定与实验需求紧密相关,阶数越高,可表征越大范围节点间的相关性,但模型复杂度也会随之提升。常用做法是仅定义单位置和双位置势函数[3,24],既可兼顾性能,模型复杂度也不会过高。因此,式(2)可改写为


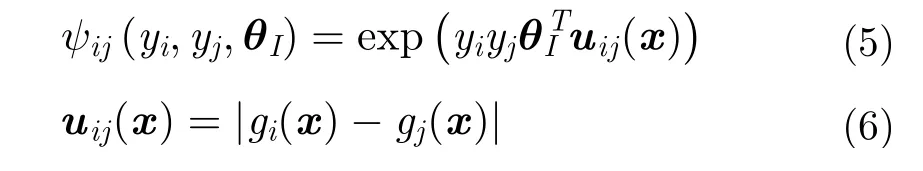
3 实验设计与结果分析
为验证本算法有效性,在实验中主要选取以下与文中方法进行对比:基于Cloude分解和Freeman分解所得特征的CRF分类(简称方法1);基于Freeman分解和协方差矩阵对角线元素所得特征的CRF分类(简称方法2);将上述两种方法中的特征串联融合所得特征的CRF分类(简称方法3);基于Freeman分解和协方差矩阵对角线元素所得特征的SVM分类[24](简称方法4);一种基于CNN的方法[14](简称方法5)。
表1给出了实验中传统方法用到的特征类型。本文方法选择提取VGG-Net-16模型conv5-3层特征进行对比实验。有关不同卷积层特征对算法性能的影响将在第3.3节进行分析。本文方法的特征提取在MatConvNet[26]深度学习平台上完成。参数估计过程中的最大迭代次数设置为1000次。分类性能综合评估指标为总体分类精度(Overall Accuracy,OA)、Kappa系数[9]、训练时间和测试时间。为减少相干斑噪声的影响,本文实验数据经过Lee滤波处理[27]。所有实验在配置为Intel Core i7 2.80 GHz处理器和8 GB内存的计算机上完成。
3.1 基于Flevoland数据的实验结果
第1个实验数据是1989年NASA/JP实验AIRSAR系统获得的L波段完整PolSAR图像的一部分,该数据被广泛用于评估PolSAR图像地物分类算法性能。图2(a)为其Pauli RGB合成图,其尺寸为750×1024像素。包括11类作物,分别为:豆类、森林、油菜籽、裸地、土豆、甜菜、小麦、豌豆、苜蓿、草地和水域。真实地物分布参考图如图2(b)所示,空白区域为未标记类别,选取10%的有标记数据用于训练,所有带标记的数据作为测试数据。实验结果如图2所示。

表1 传统方法中用到的特征Tab. 1 The features used in the traditional methods
从图2可见,本文所提方法相对其他4种基于传统特征方法明显错分较少。方法1对油菜籽和豌豆分类效果较差,方法3对油菜籽和水体的分类效果较差。方法4对土豆的分类效果较差。方法2相较于方法1、方法3和方法4取得了更好的分割效果,其中方法2和方法4采用相同的特征,而利用CRF分类的方法2精度要高于利用SVM分类的方法4,说明CRF模型对多特征和上下文信息的利用有助于提高分类精度。而从目视效果上看,本文方法要优于方法2,方法5的分类效果最好。
表2给出了定量评估数据,可见本文所提方法取得了高于传统方法的总体分类精度0.905和Kappa系数0.890,所有类别的分类精度都在0.8以上,大部分在0.9以上。并且在苜蓿、小麦、甜菜、油菜籽、豌豆和草地均取得了高于传统方法的分类精度。此外,从表2可见,与方法5相比,本文所提方法的总体分类精度稍低,这可能是由于本方法所用的特征提取模型是预训练模型,对总体分类精度存在一定程度的影响,但本方法需训练的参数少于方法5,训练时间和测试时间都远比方法5短,说明本文所提方法具有更高的实时性。

图2 Flevoland数据分类结果对比图Fig. 2 Comparison of Flevoland data classification results
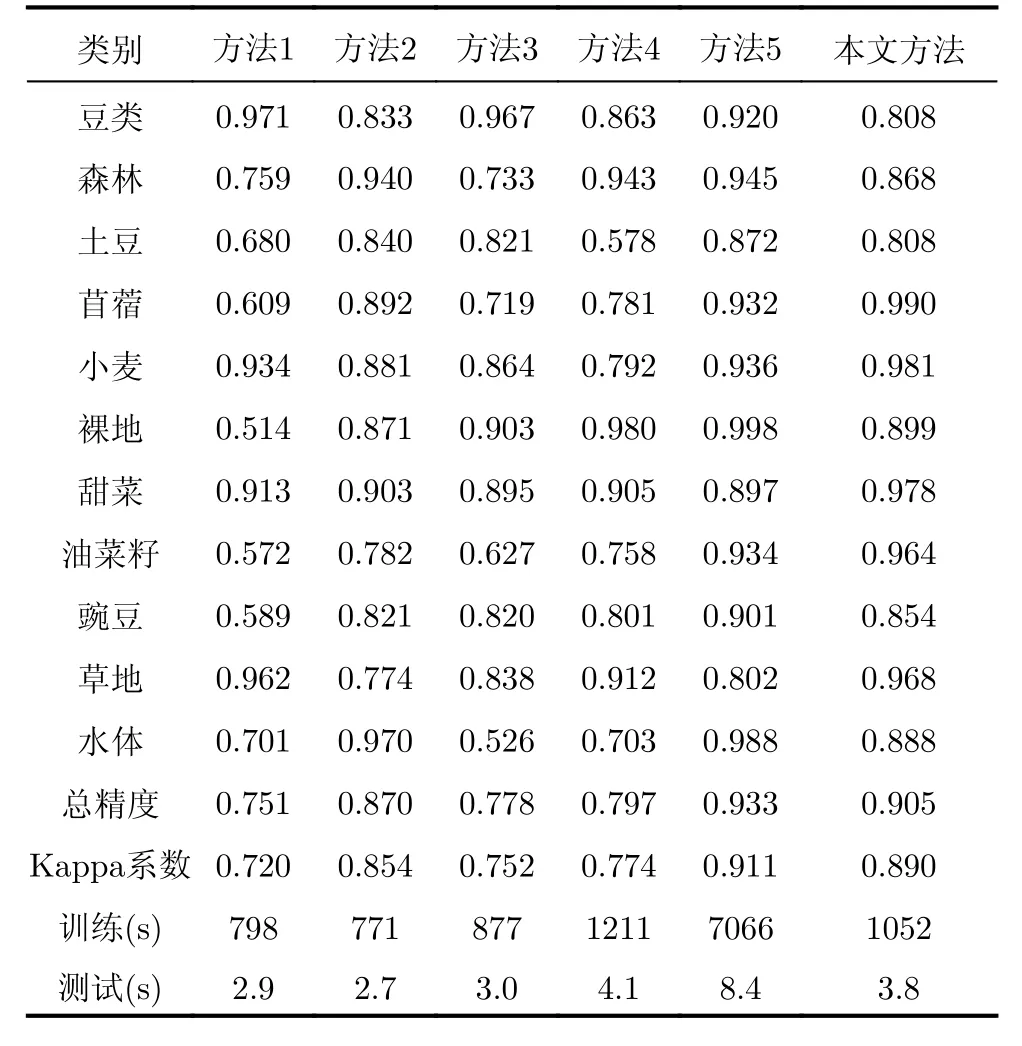
表2 Flevoland数据分类精度Tab. 2 The classification accuracy of Flevoland data
3.2 基于Oberpfaffenhofen数据的实验结果
为进一步验证本文所提方法提取深度特征的有效性,在Oberpfaffenhofen数据下将本文方法与3种基于传统特征和CRF模型的方法进行对比。图3(a)为Oberpfaffenhofen数据Pauli RGB合成图,图像的大小为1300×1200像素。真实地物分布参考图如图3(b)所示。包括3类语义类别:建筑区域、林地和开放区域。空白区域为未标记类别,实验中选取10%的有标记数据用于训练,所有带标记的数据作为测试数据。实验结果如图3所示。
从图3可见,本文所提方法整体效果优于其他3种对比方法。对于开放区域,本文方法最好,由于开放区域的散射机制与建筑区域相对接近,其余3种方法一定程度上都将其错分为建筑区域,如图中三角形区域所示。本文方法由于提取的是图像不同层次的抽象特征,有效地避免了这种现象。对于建筑区域,本文同样得到最好的分割效果,其余3种方法均不同程度将该区域错分为林地或开放区域,如图中椭圆区域所示。对于林地区域,3种方法均取得较好结果,其中方法3的效果最差,可能是由于融合的高维特征存在一定冗余,对该类别的区分性低于其他特征。
本文计算了各个方法中每类地物分类的准确率,并用总体分类精度和Kappa系数进行综合评估,如表3所示。从表中可见,本文方法取得了最高的分类精度0.903和Kappa系数0.834,并且在建筑和开放区域上的分类精度均为最高。
从上面两个实验结果可见,将多组特征串联所得高维特征的表征能力可能低于低维特征的表征能力。例如,在第1个实验中,方法3的性能要低于方法1,在第2个实验中,方法3的性能要低于方法2。说明提取的高维特征包含了冗余信息,导致了部分特征向量的分类能力减弱。而本文所提方法在两组实验中均取得了最优的分类结果,说明CNN特征相对于传统特征具有更强的表征能力,利用CNN特征可以有效提升分类性能。

图3 Oberpfaffenhofen数据分类结果对比图Fig. 3 Comparison of Oberpfaffenhofendata classification results

表3 Oberpfaffenhofen数据分类精度Tab. 3 The classification accuracy of Oberpfaffenhofen data
3.3 VGG模型特征层选择
为了比较VGG-Net-16模型中哪一层特征更具表达力,以便选择合适的特征提取层,提取conv5-3,conv4-3, conv3-3, conv2-2和conv1-2层特征进行实验并做精度评价,在Oberpfaffenhofen数据集下进行测试的结果如图4所示。实验中,采取同样的方式将实验数据分割成多个尺寸为224×224的不重叠的图像,再输入到VGG-Net-16模型中提取特征。特征提取在MatConvNet深度学习平台上完成。VGG-Net-16前5层中,每层提取的特征都是由多张特征图组成,如conv2-2层的特征为128张尺寸为112×112的特征图,插值到输入图像大小后,得到128张尺寸为224×224的特征图,相当于对输入图像的每一个像素点提取一个128维的特征向量。

图4 不同层特征分类精度对比图Fig. 4 Accuracy comparison results of different layer classification results
从图4的分类结果精度对比图可见:在Oberpfaffenhofen数据下,随着卷积层层数深度增加,分类精度呈上升趋势,在conv5-3层达到最高。这是因为VGG-Net-16模型中更深层特征更抽象,具有更高层次的语义信息。此外,conv1层特征对应的分类精度远低于其他几层特征对应的分类精度,甚至低于一些利用传统特征的方法,这是因为第1层提取的特征都是些低级特征,如边缘、角点等。因此,在本文所提方法中,VGG-Net-16模型特征提取层选择conv5-3层。由于Oberpfaffenhofen数据与Flevoland数据中的图像存在一定共性,因此不再针对Flevoland数据进行不同层特征精度比较,同样选择conv5-3层作为特征提取层。
4 结论
本文提出一种基于深度卷积神经网络和条件随机场的PolSAR图像地物分类方法。本方法利用卷积神经网络提取深度特征,再通过条件随机场对多特征及上下文信息有效利用来实现PolSAR图像地物分类。实验结果表明,在利用VGG-Net-16模型提取特征进行图像地物分类时,conv5-3层为最有效的特征提取层。此外,与3种利用传统经典特征的方法相比,本文得到了精度最高的分割结果,说明了本文所提方法的有效性。
