面向中文的修辞结构关系分类体系及无歧义标注方法
2019-08-05侯圣峦费超群张书涵
侯圣峦,费超群,张书涵
(1. 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100190)
0 引言
篇章结构理论认为: 一篇完整、连贯的文章中,其篇章内容并不是孤立存在的,而是存在关系的,这些关系将篇章内容组织在一起,构成一篇内容具有衔接性、结构上存在起承转合的完整语篇。篇章结构分析作为篇章理解的基础,已广泛应用在文本自动摘要[1]、机器翻译[2]、信息抽取[3]等自然语言处理任务中。研究高精度的篇章结构分析方法不仅有利于对篇章的理解,更有利于基于此技术的自然语言处理应用的性能提升。
在众多篇章结构理论中,Mann和Thomspon的修辞结构理论(rhetorical structure theory, RST)[4]是被应用最多且影响最深远的。修辞结构理论最初被提出时是应用于英文的文章组织结构描述,目前已被广泛应用到各种自然语言处理任务中,用于篇章内容的结构分析。修辞结构理论将篇章描述为由文本片段根据修辞结构关系逐层次组织而成的一棵树形结构。其中树结构的叶子节点是基本篇章单元(elementary discourse unit, EDU),叶子节点根据功能关系连接成高一层次节点,再由更大的语言单位之间的关系组成更高层次节点,以此类推,直至组成完整的修辞结构关系树[5]。
图1是一棵面向英文的修辞结构关系树的示例,相邻节点间通过修辞结构关系连接。
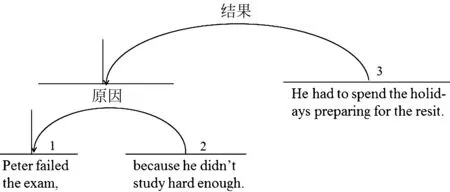
图1 面向英文的修辞结构关系树示例
根据修辞结构理论,修辞结构关系具有如下特点:
(1)修辞结构关系存在于不同粒度的篇章单元中,描述它们之间的修辞关系。例如,图1中“节点1”和“节点2”通过“原因”关系连接,它们的组合与“节点3”通过“结果”关系连接。
(2)组成篇章的文本单元都是不重复并且具有独立语义的文本片段。文本片段的最小单位是基本篇章单元,可以是句子或者子句。长度较长的文本单元则是由相邻的短文本组成的。
(3)就作者的写作意图而言,一些文本片段比其他片段发挥着更重要的作用。大部分修辞结构关系是不对称关系,重要部分称为“核心(nucleus)”,辅助部分称为“卫星(satellite)”。“核心”相较于“卫星”在语篇中发挥更重要的作用。部分修辞结构关系则是多核关系,即关系中只有“核心”成分。图1中,弧线的箭头指向的是“核心”,另一端是“卫星”。
修辞结构关系存在于相邻片段之间,并能体现作者的写作意图,进而反映作者的写作目的。已有工作中,基于修辞结构理论的英文篇章结构分析方法较多,目前已有面向英文的修辞结构关系分类体系及修辞结构篇章树库RST-DT[6]。但是,当我们将面向英文的修辞结构理论体系用于中文文本标注时,发现存在歧义和不准确的问题。鉴于中英文的语言结构特点,无法直接将面向英文的方法应用到中文中。
经过分析发现,造成这些问题的原因主要有两个方面: 一是标注者本身未正确理解修辞结构关系的定义,导致标注过程中无法确定选择何种关系,标注出不正确的结果,我们称之为理解问题;二是由于中文语言的复杂性和表达多样性,标注者对同一段文本从不同的角度去理解,导致标注出不同的结果,我们称之为标注歧义问题。本文基于修辞结构理论,根据中文文本的特点,结合复句等中文文本结构理论,提出面向中文的修辞结构关系分类体系和标注方法。对于理解问题,我们提出层次化的修辞结构关系分类体系及多元定义方法,便于标注者去理解关系定义;对于标注歧义问题,我们采取约定的方法,约定一种在某种语法规则情况下应选择何种关系的原则。在此原则下,我们提出无歧义标注方法,标注者根据该方法可以标注出无歧义或者歧义相对较小的修辞结构关系树。同时,为了便于标注,我们设计并实现了基于Java图形界面的标注工具RSTTagger,RSTTagger采用一种自底向上的逐级标注策略,最终标注成一棵完整的修辞结构关系树。为了解决自然语言文本到修辞结构关系的语义鸿沟,我们采用全息词法链[7]的思想,以句子的主谓结构关键词构成的元组作为基本标注单位,其对应的文本称为基本篇章单元。
本文其他部分内容组织结构如下: 第1节介绍相关工作;第2节详细描述面向中文的修辞结构关系分类体系及关系的多元定义;第3节描述标注工具RSTTagger和无歧义标注方法;第4节是标注结果及其评价;最后一节对全文进行总结,并提出未来研究工作方向。
1 相关工作
面向英文的修辞结构关系根据连接的文本片段的重要程度将关系分为单核关系和多核关系两种,单核关系是指关系连接的两个文本片段具有核心性,即两个文本片段根据语义功能分别作为“核心”和“卫星”,“卫星”部分作为“核心”部分的辅助;多核关系是指关系连接的文本片段都是“核心”,即它们就语义功能而言同等重要。单核关系都是二元关系,多核关系可以是二元关系,也可以是多元关系。
在修辞结构理论中,根据作者的意图目的,单核关系又分为“主题—素材关系(subject-matter relations)”和“表象关系(presentational relations)”[8]。其中,“主题—素材关系”是指读者能识别的文字表达内容本身的关系,即描述对象的几个方面。而“表象关系”是指由表层的语句实现深层次的意义,是为了增加读者的某种倾向,如可信度、积极倾向、对文字描述事物的接受度等。图2是面向英文的修辞结构分类。

图2 面向英文的修辞结构关系分类
随着对面向英文的修辞结构理论的研究不断深入,修辞结构关系种类及数量也在不断调整,从最初修辞结构理论文献[4]中定义的23种到当前最新的32种[注]http://www.sfu.ca/rst/01intro/definitions.html。在这32种最新的关系分类体系中,共有25种单核关系和7种多核关系,对每种关系,关系定义都包括关系名称(relation name)、对“卫星”或“核心”分别的约束(constraints on either S or N individually)、对“卫星”和“核心”同时的约束(constraints on N + S)、作者的意图(Intention of writer)等。表1是一个面向英文的修辞结构关系示例。

表1 一个面向英文的修辞结构关系示例
目前已有面向英文的基于修辞结构关系的标注数据集。RST-DT(RST Discourse TreeBank)是由美国南加州大学等多单位联合标注并由LDC[注]https://catalog.ldc.upenn.edu/LDC2002T07公开发布的英文RST标注语料库[6],目前已经成为基于修辞结构理论的篇章结构分析方法[9-10]的实验语料库。RST-DT以修辞结构理论为理论支撑,共标注了385篇英文《华尔街日报》的文章,文章题材包括财经报道、商业新闻等,文章包含的平均词数为458。
RST-DT将标注粒度定义为从句,规定主语从句、宾语从句及充当主要动词补语的从句都不属于基本篇章单元,状语从句和起状语作用的非谓语动词词组都属于基本篇章单元。同时,RST-DT将英文修辞结构关系进行了细化与扩充,关系包括16个大类共78种关系。标注者由有经验的专业语言学家组成,通过标注工具RSTTool[11]人工对文章进行基本篇章单元划分,并逐层次标注修辞结构关系,直至每篇文章生成一棵完整修辞结构关系树。标注一致性达到较高水平。在385篇已标注完成的语料库中,共包括21 789个基本篇章单元,基本篇章单元的平均词数为8.1。
除了基于修辞结构理论的篇章语料库之外,还有宾州篇章树库(Penn Discourse TreeBank, PDTB)[12-13]。PDTB是一种在篇章词汇化树型连接语法(lexicalized tree adjoining grammar for discourse, D-LTAG)理论[14]框架下,以词法为基础,标注了篇章谓词和论元关系来表示篇章结构。但其只是标注了底层篇章文本之间的关系,并没有完整的篇章层次结构信息。
汉语篇章修辞结构标注项目CJPL[15]是由浙江大学乐明等人根据修辞结构理论,采用大陆主要媒体的财经评论文章作为标注语料,是迄今为止较完整的中文篇章语料库,已完成了对97篇中文文章的标注。CJPL将基本篇章单元定义为由句号、问号、叹号、分号、冒号、破折号、省略号及段落结束标记所分隔的文字串,并由程序完成自动切分。CJPL共定义了12个大类47种关系,在定义和数量上与面向英文的修辞结构关系基本一致。CJPL首先根据标点符号完成对基本篇章单元的自动切分,然后使用RSTTool软件手工标注关系,自底向上构建中文修辞结构关系树。
CJPL的问题在于仅仅是根据标点符号将文章进行自然切分,生成基本篇章单元,未考虑实际的语义特征。例如,切分的标点符号基本是句号、问号等划分句子的标点,无法将复句中的各个分句切分出来,会导致切分的基本篇章单元粒度过大。其标注结果初步说明了现代汉语可以在修辞结构理论框架下用树结构表示其篇章结构。CJPL在无歧义问题上没有针对性工作,标注一致性尚不理想。
面向中文的相关工作还包括哈工大中文篇章关系树库(HIT-CDTB)[16-17],类似于面向英文的PDTB,HIT-CDTB的规模较大,但其主要标注了相邻段落、句群、句子或子句间的关系,并没有完整的篇章层次结构信息。对于标注歧义问题,他们进行了多种情况分析,并给出了尝试性解决方案。王荀、李素建等提出了内容标签和关系标签相结合的汉语篇章标注体系[18],他们提出了篇章语义关系的同时也对一些重要内容进行单独标注,同时兼顾了对文本的语义把握和对细节的分析理解。该方法的问题在于他们提出的关系标签缺少了文本单元的“核心”和“卫星”的内容,同时,根据他们提供的示例,他们只是对篇章进行“分段分句”,即切分的基本篇章单元粒度过大。该工作并没有解决标注歧义的问题。
综上所述,目前对面向英文的修辞结构理论及基于该理论的修辞结构标注语料库研究较为完善。已有工作对中文修辞结构篇章标注工作进行了尝试,并初步说明了修辞结构理论框架下标注中文篇章结构的可行性。针对普遍存在的标注歧义性问题,已有工作并没有给出较好的解决方案。
2 面向中文的修辞结构关系分类体系及关系的多元定义
现代汉语语法中,句群理论和复句理论是两种最常用于分析汉语篇章的理论体系[19]。句群是指在结构上前后连贯、具有一个明晰中心意思的一群句子的组合,句群具有如下特点:
(1) 句群是由句子组合而成的,是介于句子和段落之间的语法单位,同时也是汉语语法中最大的一级语法单位。
(2) 每个句群都表达一个相对完整、明晰而又复杂的中心意思,句群中的所有句子都要围绕着这个中心意思来表述,不能横生枝节。
(3) 构成句群的句子通过语法手段相互结合,在意义上前后连贯、互相照应,句与句之间存在着严密的逻辑关系。
不同于句群理论,复句理论描述的是句子内部各个分句之间的关系。复句是指由两个或几个意义上相关、结构上互不作句子成分的分句组成的句子。所谓分句是指结构上类似单句而没有完整句调的语法单位。构成复句的各个分句之间有着一定的逻辑关系,通常通过连词、副词等关联词语连接在一起。
修辞结构理论与句群理论及复句理论的根本假设、主要性质是一致的,即: 处理的篇章单元都是具有独立语义的并大于从句的文本片段;都认为文本片段之间并不是孤立存在的,而是存在着语义关系的;都有一定的标记和图示来表示其层次关系。
在句群理论和复句理论中,最重要的是文本单元之间的逻辑关系,句群中的句子之间及复句中的子句之间都存在着逻辑关系,并且关系种类基本一致,包括并列、选择、承接、递进、转折、假设、因果、条件、解说、目的等。这些逻辑关系与修辞结构关系的对应关系如图3所示。

图3 复句和句群理论中的语义关系与面向英文的修辞结构关系的对应关系
根据图3可以发现,对于复句理论和句群理论中的每一种关系,基本上都有修辞结构关系与之对应,并且有些修辞结构关系更加细化。同时,经过我们的前期标注实践,我们发现面向英文的修辞结构关系基本能覆盖中文中出现的语义关系,只需要将英文修辞结构理论中的某些关系定义进行扩展和更新,就能满足处理中文篇章结构的需求。
为此,我们基于面向英文的修辞结构关系定义及分类体系,结合句群理论和复句理论,提出面向中文的修辞结构关系分类体系。在本文中,我们结合中文文本特点及面向英文的修辞结构关系的命名,对面向中文的修辞结构关系进行重新定义。因此,面向中文的修辞结构关系虽然与面向英文的修辞结构关系同名,其定义可能有所不同。
如图4所示,我们将面向中文的修辞结构关系定义为3层体系结构,第一层分为6个大类,第二层共19类关系,每类关系中包含一种或多种详细的修辞结构关系,第三层共有29种关系。其中,并列大类中所有关系、对比类关系及因果类中的“原因—结果”关系为多核关系,其余都为单核关系。

图4 面向中文的修辞结构关系分类体系
对于一些修辞结构关系,仅仅通过自然语言描述关系定义可能导致标注者不能正确理解关系定义,或者标注过程中不同标注者对同一段从不同的角度去理解,导致标注结果存在歧义。我们通过语法规则及例句的方式对关系进行了多元定义。
2.1 解证
2.1.1 解说类
包括三种关系,其中详述关系的“卫星”为核心提供额外细节,包括集合的元素、抽象的具体、整体的部分、事物的例子等。总结关系的核心是描述事物的多个方面,“卫星”为核心提供简短总结或综述。重述关系的“卫星”是对核心的重述,“卫星”与“核心”文本长度相当,并且在语义上信息量相同。
语法规则:
N [其中|例如|具体来看]S (详述关系)
N [综上所述|总之]S (总结关系)
N [换言之]S (重述关系)
其中,“N”表示“核心”,“S”表示“卫星”,下同。
例1今年上半年全省对外贸易进出口总额392.5亿元人民币,其中,出口109.8亿元、下降4.9%。 (详述关系)
2.1.2 背景类
包括两种关系,其中背景关系的“卫星”是“核心”描述事件发生的背景,用于增加读者对“核心”的理解能力。环境关系的“卫星”是具体时间或是与“核心”同一时间发生的事件,用于解释“核心”发生时的情况。背景关系与环境关系的区别在于背景关系中“卫星”描述事件发生在“核心”之前,而环境关系中“卫星”是具体时间或是与“核心”同时发生的事件。
语法规则:
随着S N (环境关系)
例2随着“一带一路”战略的发布,我国外贸面临大好时机。 (环境关系)
2.1.3 评论解释类
此处评论解释类关系是对面向英文的修辞结构关系的扩充。面向英文的修辞结构关系中,两种评论解释关系只是表示作者的评价,此处扩充为作者或文中第三者的评价。评论关系与解释关系的区别在于,评论关系是作者对“核心”描述内容的评论,解释关系是通过引述或数据事实对“核心”描述内容的解释。
语法规则:
N [数据显示|据了解|据分析]S (解释关系)
例3我国外贸出口累计降幅已连续4个月收窄。数据显示,大型成套和高附加值产品的出口保证正增长,通信设备、集成电路等高附加值产品的出现增长较快。 (解释关系)
2.1.4 证实类
证实关系表示“卫星”是“核心”的证据,“核心”所述内容是一个事实或观点,“卫星”给出具体数字或其他证据来使读者相信“核心”内容是正确的。证明关系是“卫星”给出一个陈述但留下了未说明的问题,“卫星”则是读者想知道的答案或结果。
例4但今年1月份,机电产品出口乏力,共出口11.3亿美元,同比下降4.1%。 (证实关系)
张五是一个毒枭,应该把他绳之以法。 (证明关系)
2.2 因果
因果类关系分为3种: 原因关系(cause)、结果关系(result)和原因—结果关系(cause-result),若“卫星”导致“核心”,则是原因关系;反之若“卫星”是由“核心”引起的,则是结果关系;若原因与结果同等重要,则是原因—结果关系。
2.3 条件
条件关系的“卫星”是一个假设、未来或未实现的场景,“核心”的实现依赖于“卫星”的实现,如“只要……就……”、“只有……才……”。无条件关系的“卫星”能影响“核心”实现,但“核心”的实现并不完全依赖于“卫星”。除非关系的“核心”实现的前提是“卫星”未实现,否则关系的“核心”的实现会阻止“卫星”的实现。
语法规则:
如果S N (条件关系)
N除非S (除非关系)
例5如果全球经济继续保持基本稳定,下半年四川外贸进出口降幅将继续收窄。 (条件关系)
毒枭否认贩毒,但是警察用铁证证明了他贩毒。
(无条件关系)
2.4 对比转折
2.4.1 对比类
对比关系表示两个“核心”之间的对比,两“核心”在多方面都相同,在某几个方面不同,并比较这种不同。
例6大陆自香港进口同比暴增108.1%,而对香港出口同比则下降2.6%。 (对比关系)
2.4.2 转折类
对立关系和让步关系都表示转折,都是通过对比“卫星”与“核心”中的内容来映衬对“核心”中内容的积极倾向,二者的区别在于让步关系中作者不赞成但不否认“卫星”所描述内容,而对立关系中作者否认“卫星”所述内容。
例7今年的政府工作报告中,对2016年外贸发展没有提出具体数字指标,而是强调要推进新一轮高水平对外开放。 (让步关系)
但我并不认为少花钱是一种攒钱的好方式,多赚钱才是攒钱的王道。 (对立关系)
2.5目的方式
目的关系的“卫星”是一个未实现的场景,“核心”是一个动作或活动,“卫星”是“核心”的目的。方式关系的“卫星”通过“核心”部分来实现。解决关系的“卫星”是一个问题,“核心”是该问题的解决方案。动机关系,即“卫星”是“核心”的动机。铺垫关系的“卫星”是“核心”的铺垫。当前情况下,能使关系的“核心”未实现,“卫星”会增加“核心”实现的可能性。
语法规则:
为了S 应当N (目的关系)
S 将有助于N (能使关系)
例8上海自贸试验区作为我国参与新一轮自由贸易区网络构建重要的突破点,要借助“一带一路”战略,积极探寻与“一带一路”沿线的65个国家进行双边投资合作。 (方式关系)
政府实施“一带一路”政策,将有利于外贸的发展。 (能使关系)
张三撬开了李四的房门,偷偷溜了进去。 (铺垫关系)
2.6 并列
连接关系是一种多核关系,包括合取的连接和复句理论中的递进关系。选择关系的关系各元素分别描述事件,并且从中选择一个事件。并列关系的各元素分别是几种事物或观点,元素之间是平行并列关系。承接关系的各元素是接连发生的几个事件,存在时间或逻辑上的顺序。接合关系是一种伪关系,其他关系都不合适的时候利用该关系。
语法规则:
N [并且|同时|此外] N (连接关系)
N [或者|要么] N (选择关系)
N [一是|二是|三是] N (并列关系)
N [首先|其次|再次|第一|第二|第三] N (承接关系)
例9进口4亿元,下降32%;贸易顺差38.9亿元,扩大40.3%。 (连接关系)
我们将某些面向英文的修辞结构关系的定义进行了扩充,例如,评论关系原来表示作者对所描述事物的评价,此处扩充为作者或文中第三者的评价;面向英文的修辞结构关系中将因果关系分为非意志性原因、非意志性结果、意志性原因和意志性结果4种关系,但就中文篇章结构处理任务来说,计算机很难自动区分意志性还是非意志性,因此将上述4种关系合并成原因和结果两种关系,同时加入新的多核关系: “原因—结果”关系表示原因和结果同等重要的情况;面向英文的修辞结构关系中能使关系定义为读者理解“卫星”所描述内容后增加了读者执行“核心”描述动作的潜在能力,常用语、广告语中,此处将其意思扩展为能使关系。
例10政府实施“一带一路”政策,将有利于外贸的发展。
3 标注工具及无歧义标注方法
3.1 标注工具RSTTagger
为了便于标注,我们设计并实现了基于Java GUI的标注工具RSTTagger。RSTTagger既可用于修辞结构关系标注,也可用于浏览和检索标注结果。图5是RSTTagger的全面板视图,共包括4个面板,分别是Article面板、RS Tree面板、HLC面板和KeyWords面板。

图5 RSTTagger全面板视图
Article面板用于浏览文章内容,可以显示待标注、已标注文档目录及当前文章内容。当单击文档目录中的文件名时,对应的文章就会显示在文章窗口中。
RS Tree面板用于标注当前文章的RST树结构,包括两个窗口。上窗口用于添加树节点或浏览选中文章的修辞结构关系树,当单击树结构的某个节点时,Article面板的文章窗口会跳转并高亮显示该节点所对应的文本片段。下窗口用于检索已标注文章中的修辞结构关系。
HLC面板显示及检索所有全息词法链及其名称,可以将全息词法链进行层次化命名,例如,“外贸进出口状况—出口状况—出口增长”。面板底部窗口用于搜索。
KeyWords面板是所有句子主谓结构关键词组成的词串列表,此面板可以实现词串列表的增删改查。
利用RSTTagger进行修辞结构标注的具体步骤如下:
① 配置参数文件,包括待标注文档的位置、标注文件的存放位置等;
② 以命令行或者批处理方式启动RSTTagger;
③ 单击Article面板中的文件名,其他面板会显示相应的信息,可以在RS Tree面板中进行拖动,标注修辞结构关系,直至标注完成一棵完整的修辞结构关系树。
3.2 无歧义标注方法
现代汉语语法中,根据句子结构,可以把句子分为主谓句和非主谓句两类[19]。主谓句是由主语和谓语两部分构成的句子,是在中文语言表达中最常用的句式。由于自然语言结构的复杂性及表达方式的灵活性,我们在标注的时候以句子的主谓结构组成的全息词法链作为标注基础,并假设任意领域语料的基本篇章单元都可以由有限条词法链来覆盖。
修辞结构关系树的叶子节点对应子句或者简单句,中间节点对应由下一级相邻节点组成的中间篇章片段,包括句子、段落、整篇文章。在面向中文的修辞结构关系中,大部分是二元关系,只有多核关系可以是多元关系。为了便于处理,我们统一标注成二叉树结构,对于连接关系或并列关系等多核关系,可通过如图6所示的方式转化成二元结构[20]。

图6 多元关系转化成二元关系
由于中文语言的复杂性和表达多样性,标注者对同一段文本从不同的角度去理解,标注出的结果是不同的,我们通过总结语法结构特点并约定准则的方式,统一标注成某种关系,可以消除歧义。例如,表2中给出的是中文外贸领域文本的语法结构对应的关系类型。

表2 语法结构对应的关系类型
结合上节给出的面向中文的修辞结构关系多元定义以及标注原则,具体的无歧义标注算法如算法1所示。

算法1 面向中文的篇章修辞结构无歧义标注方法
注: 对于过程3中关系的标注,首先确定应标注成单核关系还是多核关系,若是单核关系,通过删除测试的方式来确定“核心”与“卫星”部分。即当去掉某一部分后,若剩余部分仍然能够充当文本中的角色,则去掉部分为“卫星”,剩余部分为“核心”;若去掉某一部分后,文本变得不够连贯,则去掉部分为“核心”,剩余部分为“卫星”。具体关系的名称则根据关系定义和约定准则来确定。
4 标注结果及评价
我们从互联网上选择中文外贸领域语料作为此次标注的实验语料,从网上爬取该领域文章网页后,程序自动解析网页得到文章的正文,共得到261篇外贸评论性文章。鉴于标注工作量较大,基于上述面向中文的修辞结构关系分类体系,我们随机选取其中的160篇进行标注。表3是标注语料库的属性。

表3 160篇标注语料属性
通过上述对面向中文的修辞结构关系多元定义及无歧义标注方法对该160篇文章进行了标注。统计已标注文章的修辞结构关系数量发现,处于前5位的高频关系及其频度占比如表4所示,这恰恰符合所选领域语料的特点,连接关系居首说明语料中含有大量并列连接类的文本,例如,“出口9.2亿元,同比增长60.4%;进口0.5亿元,同比下降10.2%;贸易顺差8.7亿元,扩大67.8%。”;详述关系次之也符合该类文章“先总括,后详述”的特点;评论和证实关系的高频次出现也同样验证了该领域文本评估性文字及举证文字较多。

表4 前5位高频关系
为了验证标注一致性,我们从160篇文本语料库中随机选取50篇文本,两人同时对该50篇文章进行独立标注。标注过程分为两个部分,一部分是在未定义面向中文的修辞结构关系及无歧义方法时,直接利用面向英文的修辞结构关系进行中文外贸领域语料的标注;另一部分是根据本文定义的关系及设计的标注方法进行标注。标注对比结果如图7所示。此处我们采用通用的修辞结构关系树衡量标准[5,18],将整棵树拆分成高度为1的子树形式,其中,“结构”表示具有相同结构的子树占所有子树的比例;“核心”表示在“结构”相同的基础上,“核心”也相同(即都标注成“核心”或者都标注成“卫星”)的子树所占比例;“关系”表示在“核心”相同的基础上,关系名称也标注一致的子树所占比例。由于我们利用RSTTagger自动标注基本篇章单元,所以我们计算得到的准确率和召回率相同。

图7 标注结果对比
实验结果表明,在我们提出的标注框架下,标注一致性达到理想结果,“关系”一致性结果为76.63%。相比较于直接利用面向英文的修辞结构理论进行标注,在“关系”层面,我们的方法标注一致性提升了25.54%。
从上述实验结果中可以看出我们方法的可行性,并且比直接利用面向英文的修辞结构理论进行标注有了大幅提升。解决歧义问题是篇章标注的一个重要问题,标注得到数据的质量将直接影响基于该数据的自然语言处理应用的性能。结合我们的标注结果分析,我们已标注的语料可以作为篇章结构分析的实验语料库。
5 结论
本文研究了面向中文的修辞结构关系分类体系及无歧义标注方法,通过分析已有的篇章语料库中的关系分类、基于面向英文的修辞结构关系定义,结合中文句群理论和复句理论,提出了面向中文的修辞结构关系分类体系。为了便于标注,设计并实现了标注工具RSTTagger。同时,针对标注过程中遇到的歧义问题,我们首先通过对面向中文的修辞结构关系进行关系的多元定义,如增加语法结构特征的方式,帮助标注者理解关系定义。然后通过总结语法结构特征,根据语法准则来判定其关系,消除歧义。
选择外贸领域语料作为测试语料,最终标注了160篇修辞结构关系树,两位标注者同时标注其中的50篇来验证标注一致性。同时,标注工具RSTTagger及标注方法可应用到其他领域文本的修辞结构标注上。已标注的树库可以作为篇章结构分析的实验语料库。
下一步的工作重点是利用已标注语料作为实验语料库进行篇章结构分析,将基于修辞结构理论的篇章结构分析应用到文本摘要、文本生成等自然语言处理应用中。
