基于卷积神经网络的弱光照图像增强算法
2019-08-01程宇邓德祥颜佳范赐恩
程宇 邓德祥 颜佳 范赐恩

摘 要:针对现有的弱光照图像增强算法强烈依赖于Retinex理论、需人工调整参数等问题,提出一种基于卷积神经网络(CNN)的弱光照图像增强算法。首先,利用四种图像增强手段处理弱光照图像得到四张派生图,分别为:限制对比度自适应直方图均衡派生图、伽马变换派生图、对数变换派生图、亮通道增强派生图;然后,将弱光照图像及其四张派生图输入到CNN中;最后经过CNN的激活,输出增强图像。所提算法直接端到端地实现弱光照图像到正常光照图像的映射,不需要按照Retinex模型先估计光照图像或反射率图像,也无需调整任何参数。所提算法与NPEA(Naturalness Preserved Enhancement Algorithm for non-uniform illumination images)、LIME(Low-light image enhancement via Illumination Map Estimation)、LNET(LightenNet)等算法进行了对比。在合成弱光照图像的实验中,所提算法的均方误差(MSE)、峰值信噪比(PSNR)、结构相似度(SSIM)指标均优于对比算法。在真实弱光照图像实验中,所提算法的平均自然图像质量评价度量(NIQE)、熵指标为所有对比方法中最优,平均对比度增益指标在所有方法中排名第二。实验结果表明:相对于对比算法,所提算法的鲁棒性较好;经所提算法增强后,图像的细节更丰富,对比度更高,拥有更好的视觉效果和图像质量。
关键词:弱光照图像增强;Retinex模型;派生图;卷积神经网络;自然图像质量评价
中图分类号:TP391.4
文献标志码:A
文章编号:1001-9081(2019)04-1162-08
0 引言
在很多计算机视觉任务中,如目标检测、图像检索、图像分割等,都要求输入图像亮度合适、细节清晰。然而,在弱光照或者曝光不足的情况下,采集到的图像存在亮度低、色彩不饱和、细节模糊等缺点,这些缺点将影响到后续的计算机视觉任务。因此,研究弱光照图像的增强很有必要。为了改善这类图像的视觉效果,需要对其进行增强处理,基本增强手段主要包括:1)通过调整对比度来增强图像边缘和细节;
2)通过调节动态范围抑制噪声等手段来改善图像清晰度;
3)通过提高较暗区域的亮度,使图像亮度保持均匀;
4)通过调整图像的颜色饱和度使其获得良好的视觉效果等。
近年来,深度学习发展迅速,在高层次视觉任务中应用非常广泛,如图像识别[1]、语义分割[2]等。
与此同时,也有一些研究人员尝试用深度学习算法去解决低层次图像领域问题,如图像去噪[3]、图像去雾[4-5]、图像超分辨率[6]等,这些算法也取得了较好的成绩。相对于传统算法,深度学习算法具有不需要人工设计特征提取方法,可直接端到端地训练和输出结果等优势。
因此,在深度学习广泛应用的背景下,本文尝试用卷积神经网络(Convolutional Neural Network, CNN)算法对传统的弱光照图像增强问题进行改进。
1 Retinex理论和相关工作
1.1 Retinex理论
弱光照图像增强是图像处理领域的一个经典问题。该问题旨在从亮度偏暗、细节模糊、质量较低的图像中恢复出亮度适中、细节明显、有良好视觉效果的图像。
Retinex理论模型[7]是弱光照图像增强领域的一个基础理论模型。模型的基本假设是原始图像是光照图像和反射率图像的乘积,可表示为下式形式:
其中:x表示像素点;I(x)表示采集到的原始图像;L(x)表示光照图像;R(x)表示反射率图像。基于Retinex模型的图像增强算法的一般处理顺序是先从原始图像中估计出光照图像L(x),进而算出反射率图像R(x),消除L(x)中弱光照的影响后得到亮度适中的增强光照图像Len(x),Len(x)与R(x)相乘得到增强图像。目前大多数弱光照增强算法的研究都是基于Retinex理论模型,这类算法的主要难点在于利用人工提取的图像特征和统计先验估计光照图像。
1.2 相关工作
弱光照图像增强算法的相关研究一直在进行,从中发展出了许多不同类型的算法。例如,文献[8-9]根据直方图调整图像的灰度动态范围来增强图像,此类算法计算简单易于实现,但在图像较暗区域的增强效果不足,较亮区域又容易过度增强,导致颜色失真。后来,很多研究者提出基于Retinex模型的算法,這类算法的一般步骤都是先从弱光照图像中估计出光照图像,然后根据式(1)得到反射率图像,通过一定的增强手段增强光照图像,最后与反射率图像相乘得到增强图像。Guo等[10]提出了LIME(Low-light image enhancement via Illumination Map Estimation)算法,该算法通过优化弱光照图像的亮通道图得到全局平滑且边缘清晰的光照图像,光照图像经伽马变换后得到增强的光照图像。文献[11-12]中均用高斯分布和拉普拉斯分布来拟合光照图像和反射率图像的分布规律,以弱光照图像的V通道图像为初始光照图像,经ADMM(Alternating Direction Method of Multipliers)算法迭代求得光照图像和反射率图像的最优解;然后与文献[10]一样,使用伽马变换得到增强的光照图像。文献[13]中提出了NPEA(Naturalness Preserved Enhancement Algorithm for non-uniform illumination images)算法,该算法设计了一个光照敏感的滤波器,使用该滤波器对弱光照图像滤波得到光照图像,然后用改进的对数变换对光照图像进行调节得到增强的光照图像。然而,根据式(1)可知,在反射率图像R(x)未知的条件下,根据原始图像I(x)估计光照图像L(x)是一个病态问题,估计的光照图像并不完全准确,光照图像估计错误会导致增强图像中出现亮度不自然的问题,这也是所有基于Retinex模型的算法的固有缺陷。
图1是个典型例子,文献[11]算法因为光照图像估计错误导致增强失败,本文算法则能得到视觉效果良好的增强图像。
Fu等[14]提出了基于多派生光照图像融合的算法MF(Multi-scale derived images Fusion)。首先根据亮通道方法得到光照图像和反射率图像,使用引导滤波优化光照图像;然后用三种增强手段处理光照图像得到三个派生光照图像;最后根据人工设计的权重参数,融合三个派生光照图像得到增强的光照图像,反射率图像和增强的光照图像相乘得到增强图像。该算法能有效改善图像较暗区域的视觉效果,同时保持明亮区域不出现失真现象;但是该算法的融合权重参数需要人工设计,且融合权重参数不是基于学习的方法得到的,不具有统计规律,因而鲁棒性不佳。
此外,有研究者发现弱光照图像取反的结果类似于有雾图片。
Dong等[15]提出的快速有效低光照视频增强算法,将弱光照图像取反后,用暗通道去雾算法对其进行处理,然后将结果再次取反得到增强图像。这类算法的增强效果取决于去雾处理中透射率图估计的准确程度。而由雾形成的物理模型可知,直接根据雾图像估计透射率图也是一个病态问题[4],所以基于Retinex模型的算法的缺陷同样也存在于这类方法中。
有别于传统增强算法,近年来发展出了一些基于学习的增强算法。Fotiadou等[16]提出一种基于稀疏表示的增强算法。首先,分别在暗光条件下和正常光照条件对相同场景采集图像,将暗光图像集和正常图像集用于联合字典学习,得到两个图像集的联合字典及具有匹配关系的暗光条件编码与正常光照条件编码;然后,用联合字典对输入的弱光照图像编码,得到暗光条件编码,根据匹配关系找到对应正常光照条件下的编码;最后,再由正常光照条件下的编码和联合字典恢复出增强图像。在深度学习广泛运用于计算机视觉的各个领域的情况下,也有研究人员尝试用深度学习来解决弱光照图像增强问题。Li等[17]提出了卷积神经网络弱光照图像增强算法LNET(LightenNet),该算法使用卷积神经网络来估计光照图像,然后使用引导滤波优化光照图像,最后根据Retinex模型得到增强图像。Lore等[18] 受到深度学习在图像去噪中应用的启发,将一个经典的图像去噪自编码器SSDA(Stack Sparse Denoising Autoencoder)运用在弱光照图像增强上。文献[17-18]的尝试表明深度学习算法在弱光照图像增强问题上同样适用,因此本文结合传统图像增强手段和卷积神经网络,提出了基于卷积神经网络的弱光照图像增强算法。本文算法摆脱了Retinex模型的限制,不需要估计光照图像或反射率图像,直接端到端地实现弱光照图像增强。
2 本文算法
本文提出的卷积神经网络简称为MDIIN(Multiple Derived Image Inputs Network)。MDIIN的作用是激活原始弱光照图像和由其生成的四张派生图,输出增强图像。通过在合成数据集上的训练,MDIIN成功学习到了映射规律,有效地实现了弱光照图像的增强。
2.1 派生图
弱光照条件下采集到的图像存在以下问题:图像的对比度低,整体亮度偏低,暗处区域的细节不清晰。针对以上的问题,本文算法首先采用传统增强手段生成四种派生图,这四种派生图在对比度、亮度、颜色饱和度上均优于原图。
1)限制对比度自适应直方图均衡派生图:直方图均衡可提升图像的对比度,提高图像中弱光照区域的亮度。直方图均衡的方法有很多种,简单的直方图均衡计算复杂度低、耗时短;但是由于这种方法是全局均衡,对于整体亮度偏低的图像的增强效果有限,而且可能导致颜色失真。为了克服简单直方图均衡的缺点,文献[9]中提出了限制对比度自适应直方图均衡算法CLAHE(Contrast Limited Adaptive Histogram Equalization),CLAHE的分块操作使图像的整体亮度得到提升,亮度分布也更加均匀。CLAHE算法中带阈值限制的图像子块直方图均衡可适当地增强图像的对比度。因此,本文选取CLAHE算法生成第一张派生图Ich:Ich=CLAHE(I)(2)
2)伽马变换派生图:伽马变换是一种非线性地改变图像亮度的方法。本文选用伽马变换生成第二张派生图Igm:Igm=αIγ(3)
当γ<1时,伽马变换可提升图像的亮度,增强图像暗处的细节。本文中α=1,γ=0.4。如图2(c)所示,伽马变换可有效提高图像的整体亮度。
3)对数变换派生图:与伽马变换一样,对数变换也是一种非线性地改变图像亮度的方法。两者的区别是伽马变换对低亮度区域的亮度提升作用更大,对数变换对高亮度区域的亮度提升作用更大。本文算法中,两种变换互为补充,能够更合理地提升图像亮度。对数变换公式如下:Ilog=c·log(1+v)(1+I·v)(4)
本文中c=1,v=10。
4)亮通道增强派生图:首先将原始弱光照图像的亮通道图像当作光照图像L[10],由式(1)可得到反射率图像R。对原始图像做α=1,γ=0.5的伽马变换得到增强的光照图像Len,Len和R相乘得到亮通道增强派生图Ile:
如图2(e)所示,相对于原图,亮通道增强派生图的颜色饱和度、亮度都有提升。
2.2 网络结构
MDIIN是一个基于Encoder-Decoder结构的网络。在图像去噪[19]、颜色校正[20]、图像去雾[21]、延时摄影视频生成[22]等领域中,Encoder-Decoder结构得到了广泛的应用,这说明Encoder-Decoder结构非常适用于图像生成网络。
MDIIN在Encoder-Decoder結构中增加了跳跃连接,将Encoder的特征图和浅层Decoder的特征图输入到Decoder的最后一层。跳跃连接在网络浅层和深层之间增加了通路,可以大幅加快网络训练的收敛速度[19],而且跳跃连接让每一层的特征图得到了更充分的利用,有助于生成细节更清晰的增强图像。
图3为MDIIN的结构。MDIIN包含15个卷积层和3个反卷积层,卷积操作的步长都为1,每个卷积层和反卷积层后面都连接着一个Leaky ReLU(Leaky Rectified Linear Unit)激活层,Leaky ReLU激活函数的负半区的斜率为0.1。MDIIN中的所有卷积操作都是空洞卷积,空洞卷积未增加网络的计算量,却能增大局部感受野的大小,利用更多的图像信息。
MDIIN的网络参数设置如表1所示,其中:Block表示卷积块类型,Layer表示层类型,conv表示卷积层,deconv表示反卷积层,Weight Dimension表示卷积核参数维度,Dilation表示空洞卷积的间隔像素点个数,Padding表示卷积时边缘补充像素的数量。网络输入为弱光照圖像及其四张派生图,因此Encoder1的输入通道数为15,输出为增强图像,因此Decoder3输出通道数为3。将Encoder1、Encoder2、Encoder3、Decoder1、Decoder2的输出和Decoder3中第二个卷积层的输出聚合,然后全部输入到Decoder3的最后一个卷积层,因此Decoder3的最后一个卷积层的输入通道数为192。
2.3 损失函数
本文采用均方误差(Mean Square Error, MSE)和L1范数损失作为MDIIN的损失函数。在图像生成类任务中,MSE是最常用的损失函数。近期有研究显示,训练中使用复合形式的损失函数比使用单一的MSE损失函数能得到表现更好的网络[23]。因此,除MSE外,本文还加入L1范数损失以提高增强结果的图像质量。最终的损失函数公式如下:L(w)=
3 实验与结果分析
3.1 实验环境与参数设置
MDIIN训练时,输入图像块大小设置为128×128,优化算法为ADAM(Adaptive Moment Estimation)[24],批处理图像块数量为10,初始学习率为0.00001,每20000次迭代学习率衰减75%,总迭代次数为60000。训练使用的GPU型号为Nvidia K80,在该环境下,训练一次耗时12h。
3.2 训练数据
训练数据直接决定了卷积神经网络能学习到什么映射规律。在弱光照图像增强领域,目前还没有既包含弱光照图像又包含其对应正常光照图像的数据集,因此,本文利用正常清晰光照的图像合成弱光照图像。
图4是一个合成弱光照图像的例子。首先,在互联网和其他图像数据集上找到600张光照正常对比度高的图像;然后,将图像转换到HSV(Hue Saturation Value)空间,对V通道图像V做伽马变换得到合成弱光照图像的V通道图像Vdark:Vdark=αVγ,其中α∈(0.8,1),γ∈(1.8,3.4);然后用Vdark替换V,其他两个通道不变,转换回RGB(Red Green Blue)空间得到合成弱光照图像。对每一张正常光照图像,随机选取7组参数,生成7张弱光照图像,最终一共得到4200张训练图像。从中选取由100张正常光照图像合成的700张合成图像作为测试集,剩余的作为训练集。
3.3 实验结果分析
为了验证本文算法的有效性,本文在真实弱光照图像和合成弱光照图像上均进行了对比实验。对比的算法有:Dong算法[15]、LIME算法[10]、MF算法[14]、NPEA[13]、LNET算法[17]。各算法的参数值均为原文献中的推荐值。
3.3.1 合成弱光照图像增强对比实验
首先,在合成弱光照图像上将本文算法与其他算法对比。合成弱光照图像的方法和3.2节中网络训练集的合成方法相同,总共选取50张合成图片。为了保证实验的公正性,这50张图片都未在训练集中出现过。为了说明本文算法在不同光照条件下的鲁棒性,本文选取的合成图像中场景包括室内、野外、图像的光照条件有整体光照偏弱、光照不均匀等。
图5是部分实验结果。观察图5可看出,Dong算法对图像的亮度有一定提升,但是提升能力不足,图像整体亮度仍然很低,细节仍然不清晰。LIME算法的增强效果非常明显,增强后图像的平均亮度也是所有算法中最高的,但是这也带来了增强过度的问题,图像中出现过曝和失真现象,如图5的station中火车头左上角的光晕和ride中的石子路。LNET算法在station上增强效果较好,在owl上不明显,owl增强后亮度仍然偏暗,在room中出现了过曝现象,如地板和窗帘的亮度。MF算法和NPEA的增强图像的亮度介于Dong算法和LIME算法之间。由station的增强结果可看出,这两种算法对光照不均匀但平均亮度较高的图像的增强效果不错,但是当图像整体亮度都偏暗时,如owl和ride,增强后图像亮度仍偏暗、视觉效果欠佳。这也说明MF,NPEA的鲁棒性不够好,需要针对不同场景和光照情况调整参数才能得到较为理想的结果。而本文算法是基于学习的算法,在训练中学习了不同的场景和光照条件,对于光照各异的输入图片,无需调整任何参数就能输出较理想的增强结果。图5中也能看出,本文算法的增强结果最接近正常光照图像,增强后的图像亮度适中、颜色自然、细节清晰、具有最好的视觉效果。所以,从主观视觉感受上来说,本文算法比其他算法更有优势。
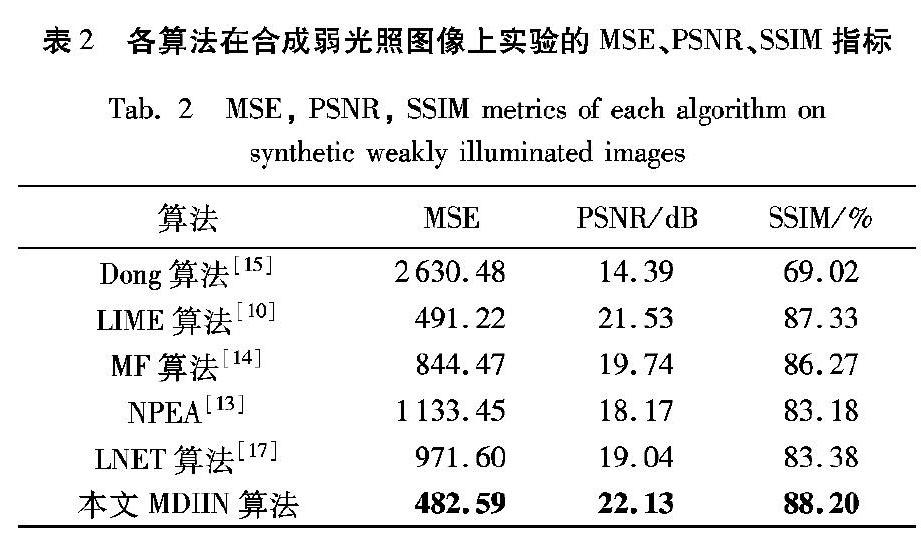
除了主观评判外,本文还在MSE、峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)、结构相似度(Structural SIMilarity index, SSIM)三项客观指标上对几种算法进行对比。表2是几种算法在50张合成样本上实验结果的平均指标。表2可看出,本文算法的平均MSE、PSNR指标是所有算法中最优的。而且,尽管本文算法在训练时使用的损失函数是MSE和L1范数,但在SSIM指标对比中,本文算法仍然是所有算法中最优。在合成图像上实验结果表明,无论是从主观视觉感受还是客观评价指标来说,本文算法对弱光照图像的增强能力均优于其他几种算法。
3.3.2 真实弱光照图像增强对比实验
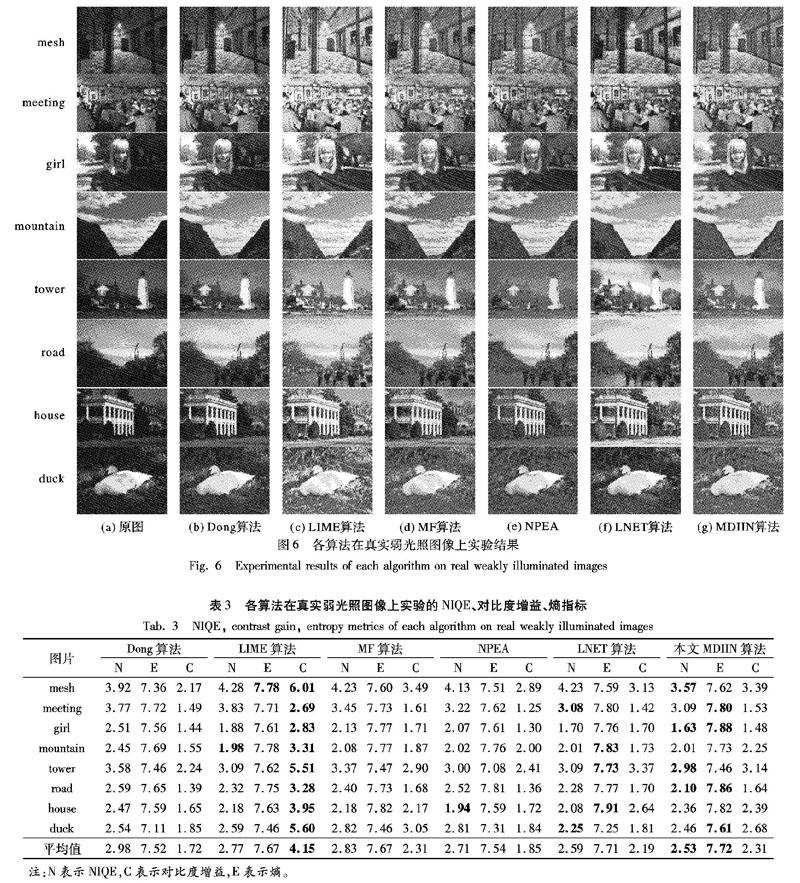
为了进一步说明本文算法的优势,本文也在真实弱光照图像上进行了对比实验,图6是实验结果。从图6可看出,各算法在真实图像上的增强表现跟合成图像上的表现基本一致:Dong算法增强后图像亮度整体偏暗,细节处的视觉效果提升不明显,如girl中的车窗和mountain中的山体部分;MF算法的鲁棒性一般,部分图片增强后亮度较好,如girl、house、duck,其他剩余图片仍然偏暗;NPEA的增强结果整体偏暗,且出现失真,如tower中右侧树枝的亮度不自然;从meeting和girl的增强结果可看出,LIME算法依然存在增强过度的问题,增强后图像的光照不自然;LNET中增强过度的现象更明显,如tower、house中的天空与road中的马路,都出现了过曝问题;本文算法的增强结果较为自然,在提升原图暗处的同时,很好地保持了原图亮度区域不过曝,增强后的图像有良好的视觉观感。
为了更客观地对比各算法的增强表现,还需要测试实验结果的客观评价指标。不同于合成图像,真实弱光照图像无对应的正常光照图像,无法测试MSE、PSNR等指标。本文以图像的自然图像质量评价度量(Natural Image Quality Evaluator, NIQE)、熵(Entropy)、对比度增益(Contrast Gain)三项指标来对比各算法。NIQE是一个根据图像的自然统计特征得到的图像质量参考值,数值越小表示图像质量越高;熵是度量图像中信息量多少的指标,可以反映图像细节丰富程度,熵越大,说明图像包含信息越多,细节越丰富;对比度增益反映了图像增强前后对比度提升的程度,值越大表示对比度提升越明显。
表3中记录了图6实验结果的三项指标。具体分析如下:1)在NIQE的对比中,本文算法在其中的四张图片上排名第一,在其中三张图片上排名第二,在其中一张图片上排名第四,平均排名第一。排名第四的图片名为house,观察图6可知,本文算法增强后,house中整体亮度过于平均,未形成较高的对比度,这可能是影响该图片NIQE指标的因素。综合比较NIQE指标可以说明,相对于其他方法,本文算法增强后图像的有更高的图像质量。
2)在熵的对比中,本文算法在其中的四张图片上排名第一,在其中的两张图片上排名第二,另外两张图片mountain和tower分别排名第三和第四,平均排名第一。理论上熵最大的情况为图像中每个像素的灰度值都不一样,本文算法增强结果在图片mountain中的山体部分和tower中的地面部分的灰度值分布变化很少,因此这两张图片的熵指标相对较低。但是,在八张图片上熵指标的综合比较中,本文算法仍然是最优的。这说明相对于其他方法,经本文算法增强后图像的细节更丰富。
3)在对比度增益的对比中,本文算法的平均对比度增益排名第二,排名第一的为LIME算法。前文的主观视觉感受对比中可以发现,LIME有过度增强的倾向,因此LIME算法的高对比度增益是建立在过度增强的基础之上。
通过对比NIQE、熵、对比度增益三项指标,可以说明本文算法在真实弱光照图像上的增强表现更好,本文算法增强后的图像有较高的图像质量与较丰富的细节;而且,本文算法在保持增强效果自然性的前提下,能较好地提升图像对比度。
3.3.3 派生图对增强结果的影响
本文针对各派生图对增强结果的影响进行了分析。卷积神经网络的映射作用不可用解析表达式表示,因此无法直接通过公式分析各派生图的作用。最终,本文选择使用替换方法对此进行分析。具体实施过程为:保持MDIIN的其他输入不变,将其中一张派生图用原始弱光照图像代替,得到增强结果。
图7中显示了将四张派生图依次用原始弱光照图像代替后的增强结果:由图7(a)~(b)中球面的纹路及衣服上的褶皱可看出,限制对比度自适应直方图均衡派生图影响到增强结果的局部对比度,将限制对比度自适应直方图均衡派生图用原图代替后,图像的局部对比度降低;图7(c)与图7(a)相比,图像的整体亮度降低,这说明伽马校正派生图对增强结果的全局亮度有较大提升作用;图7(d)与图7(a)相比,颜色饱和度严重下降,这表明亮通道增强派生图起到了提升增强结果颜色饱和度的作用,也间接影响到图像的主观视觉感受。图7(e)是将对数变换派生图用原图替换后的增强结果,替换后,图像出现过曝的现象,这说明在MDIIN的映射中,对数变换派生图与最终增强结果的亮度为负相关关系。
3.3.4 时间复杂度分析
此外,本文也对各算法的时间复杂度进行了比较。表4中记录了各算法分别处理mesh、meeting、girl、mountain四张图片的时间。Dong算法、LIME、MF、NPEA、LNET算法均在Matlab2017中运行,本文算法在深度学习框架Pytorch中运行,代码中使用GPU加速。电脑的CPU型号为Intel Core i7-7700HQ,GPU型号为Nvidia 1080TI。
从表4可看出:NPEA的处理时间最长;LNET算法由于未使用GPU加速,因此时间也较长;Dong算法、LIME、MF算法的处理时间较短,均在1s以内;本文算法的處理时间最短,只需0.1s左右。因此,在算法处理速度上本文算法也具有优势。
5 结语
本文提出一种将传统图像增强手段与深度学习算法结合的弱光照图像增强算法。与原始图像相比,四种传统增强手段生成的派生图在对比度、亮度、颜色饱和度上均有提升。卷积神经网络可充分激活各派生图的优点从而输出光照明亮视觉效果良好的增强图像。本文算法不受Retinex模型约束,无需估计光照图像和反射率图像,直接端到端生成增强图像。由于训练数据集中包含丰富的场景和光照条件,因此本文算法也无需调整任何参数,在光照较弱和光照不均匀的情况下均表现突出。本文在合成弱光照图像和真实弱光照图像上均进行了对比实验,实验结果从主观感受和客观评价指标两方面都验证了本文算法的有效性。与对比算法相比,本文算法的增强图像在图像质量、图像细节丰富程度、图像对比度上均具有优势。
在分析各派生图作用时,本文算法中对数变换派生图与最终增强结果的亮度之间为负相关关系,这有可能是伽马变换派生图与对数变换派生图作用重叠导致的。因此,在下一步研究中,尝试保留伽马变换派生图和对数变换派生图中的一个进行实验。
參考文献(References)
[1] 康晓东, 王昊, 郭军, 等.无监督深度学习彩色图像识别方法[J]. 计算机应用, 2015, 35(9): 2636-2639. (TANG X D, WANG H, GUO J, et al. Unsupervised deep learning method for color image recognition[J]. Journal of Computer Applications, 2015, 35(9): 2636-2639.)
[2] 杨朔, 陈丽芳, 石瑀, 等.基于深度生成式对抗网络的蓝藻语义分割[J]. 计算机应用, 2018, 38(6): 1554-1561. (YANG S, CHEN L F, SHI Y, et al. Semantic segmentation of blue-green algae based on deep generative adversarial net[J]. Journal of Computer Applications, 2018, 38(6): 1554-1561.)
[3] LI H M. Deep learning for image denoising[J]. International Journal of Signal Processing, Image Processing and Pattern Recognition, 2014, 7(3): 171-180.
[4] CAI B, XU X, JIA K, et al. DehazeNet: an end-to-end system for single image haze removal[J]. IEEE Transactions on Image Processing, 2016, 25(11): 5187-5198.
[5] REN W, LIU S, ZHANG H, et al. Single image dehazing via multi-scale convolutional neural networks[C]// ECCV 2016: Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 154-169.
[6] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE, 2017: 136-144.
[7] LAND E H. The Retinex[J]. American Scientist, 1964, 52(2): 247-264.
[8] LEE C, LEE C, KIM C S. Contrast enhancement based on layered difference representation of 2D histograms[J]. IEEE Transactions on Image Processing, 2013, 22(12): 5372-5384.
[9] PISANO E D, ZONG S, HEMMINGER B M, et al. Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms[J]. Journal of Digital Imaging, 1998, 11(4): 193-200.
[10] GUO X, LI Y, LING H. LIME: low-light image enhancement via illumination map estimation[J]. IEEE Transactions on Image Processing, 2017, 26(2): 982-993.
[11] FU X, LIAO Y, ZENG D, et al. A probabilistic method for image enhancement with simultaneous illumination and reflectance estimation[J]. IEEE Transactions on Image Processing, 2015, 24(12): 4965-4977.
[12] FU X, ZENG D, HUANG Y, et al. A weighted variational model for simultaneous reflectance and illumination estimation[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 2782-2790.
[13] WANG S, ZHENG J, HU H M, et al. Naturalness preserved enhancement algorithm for non-uniform illumination images[J]. IEEE Transactions on Image Processing, 2013, 22(9): 3538-3548.
[14] FU X, ZENG D, HUANG Y, et al. A fusion-based enhancing method for weakly illuminated images[J]. Signal Processing, 2016, 129: 82-96.
[15] DONG X, WANG G, PANG Y, et al. Fast efficient algorithm for enhancement of low lighting video[C]// Proceedings of the 2011 IEEE International Conference on Multimedia and Expo. Piscataway, NJ: IEEE, 2011: 1-6.
[16] FOTIADOU K, TSAGKATAKIS G, TSAKALIDES P. Low light image enhancement via sparse representations[C]// ICIAR 2014: Proceedings of the 2014 International Conference on Image Analysis and Recognition. Berlin: Springer, 2014: 84-93.
[17] LI C, GUO J, PORIKLI F, et al. LightenNet: a convolutional neural network for weakly illuminated image enhancement[J]. Pattern Recognition Letters, 2018, 104: 15-22.
[18] LORE K G, AKINTAYO A, SARKAR S. LLNet: a deep autoencoder approach to natural low-light image enhancement[J]. Pattern Recognition, 2017, 61: 650-662.
[19] MAO X J, SHEN C, YANG Y B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: Curran Associates, 2016: 2810-2818.
[20] TSAI Y H, SHEN X, LIN Z, et al. Deep image harmonization[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 2799-2807.
[21] REN W, MA L, ZHANG J, et al. Gated fusion network for single image dehazing[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 3253-3261.
[22] XIONG W, LUO W, MA L, et al. Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 2364-2373.
[23] LIU Y, ZHAO G, GONG B, et al. Improved techniques for learning to dehaze and beyond: a collective study [EB/OL]. [2018-07-26]. https://arxiv.org/pdf/1807.00202.
[24] KINGMA D P, BA J L. ADAM: a method for stochastic optimization [EB/OL]. [2018-05-10]. https://simplecore.intel.com/nervana/wp-content/uploads/sites/53/2017/06/1412.6980.pdf.
[25] 王一宁, 秦品乐, 李传朋, 等.基于残差神经网络的图像超分辨率改进算法[J]. 计算机应用, 2018, 38(1): 246-254. (WANG Y N, QIN P L, LI C P, et al. Improved algorithm of image super resolution based on residual neural network[J]. Journal of Computer Applications, 2018, 38(1): 246-254.)
[26] 梁中豪, 彭德巍, 金彥旭, 等.基于交通场景区域增强的单幅图像去雾方法[J]. 计算机应用, 2018, 38(5): 1420-1426. (LIANG Z H, PENG D W, JIN Y X, et al. Single image dehazing algorithm based on traffic scene region enhancement[J]. Journal of Computer Applications, 2018, 38(5): 1420-1426.)
