针对多种处理痕迹的数字语音取证算法
2019-08-01向立严迪群王让定李孝文
向立 严迪群 王让定 李孝文
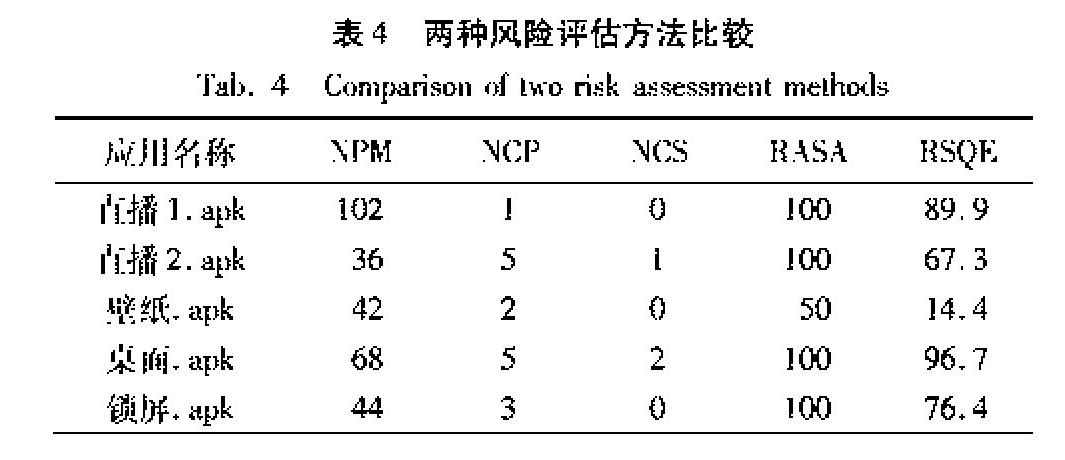

摘 要:现有的数字语音取证研究主要集中于对单一的某种操作进行检测,无法对不相关的操作进行判断。针对该问题,提出了一种能够同时检测经过变调、低通滤波、高通滤波和加噪这四种操作的数字语音取证方法。首先,计算语音的归一化梅尔频率倒谱系数(MFCC)统计矩特征;然后通过多个二分类器对特征进行训练,并组合投票得到多分类器;最后使用该多分类器对待测语音进行分类。在TIMIT以及UME语音库上的实验结果表明,归一化MFCC统计矩特征在库内实验中均达到了97%以上的检测率,且在对MP3压缩鲁棒性测试的实验中,检测率仍能保持在96%以上。
关键词:语音取证;梅尔频率倒谱系数;处理痕迹;多分类器
中图分类号: TP391.42; TN912.34
文献标志码:A
Abstract: Most existing forensic methods for digital speech aim at detecting a specific operation, which means that these methods can not identify various operations at a time. To solve the problem, a universal forensic algorithm for simultaneously detecting various operations, such as pitch modification, low-pass filtering, high-pass filtering, and noise adding was proposed. Firstly, the statistical moments of Mel-Frequency Cepstral Coefficients (MFCC) were calculated, and cepstrum mean and variance normalization were applied to the moments. Then, a multi-class classifier based on multiple two-class classifiers was constructed. Finally, the classifier was used to identify various types of speech operations. The experimental results on TIMIT and UME speech datasets show that the proposed universal features achieve detection accuracy over 97% for various speech operations. And the detection accuracy in the test of MP3 compression robustness is still above 96%.
Key words: speech forensics; Mel-Frequency Cepstral Coefficient (MFCC); operation trace; multi-class classifier
0 引言
隨着数字语音处理技术的快速发展,以及语音编辑工具功能越来越强大,使得数字语音可以轻易地被修改而不被察觉。数字语音伪造越来越频繁地出现在我们的日常生活中,如电子语音变调、加噪等,这些伪造操作会导致很多严重的法律、伦理和道德问题,因此,数字语音取证已经受起越来越多的关注。到目前为止,已经有许多针对不同操作的取证方法的研究[1-2],如变调语音检测[3-5]、设备来源取证[6-8]、翻录语音检测[9]等,而大多数的研究仅仅针对某一种特定的操作进行检测[10],即不考虑待测语音是否可能经过了其他操作;然而在现实场景中,这样显然不符合实际情况,例如,将加噪的语音放入变调分类器中进行分类,则其可能被分类为原始语音或变调语音,因为待测语音往往是经过了未知操作类型的,且通常可能经过了多种操作,从而对取证工作造成误导。在语音取证领域中还缺乏关于多种操作检测的算法,因此,有必要研究一种能够通过某一种特征检测出多种操作的算法。
电子语音变调通过修改语音的音调,使得该语音从听觉上发生变化,例如提高一个男生的音调,会使得该语音像一个女生的语音;在实际场景中,经常会使用各种滤波器对一段语音进行处理,达到特殊的效果,例如降噪等;一段语音的录制场景可能是不同的,而通过对语音进行加噪可以改变一段语音的录制场景,如一段安静的语音,通过向其加入学校环境的背景噪声,会让人以为该语音的录制场景是学校。以上几种操作都是在实际生活中几种较为常见的语音的操作,且都会对语音进行大量修改,从而对取证工作造成误导。
为了研究一种对多种操作都能够检测的技术,本文提出了一种利用归一化的梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient, MFCC)统计矩特征对变调、高通滤波器、低通滤波器、加噪四种操作进行分类检测的方法,利用TIMIT(the DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus)语音库以及UME(advanced Utilization of Multimedia to promote higher Education Reform speech database)语音库进行实验。结果证明,该方法能够对这四种操作进行鉴别。
1 归一化MFCC统计矩特征
MFCC特征是一种在语音识别中被广泛使用的特征。梅尔频率是基于人耳听觉特性提出来的,它与Hz频率成非线性对应关系,MFCC则是利用它们之间的这种关系,计算得到的Hz频谱特征。
