一种基于深度神经网络的水军识别模型
2019-07-30杨昊吴爱华屈青英
杨昊,吴爱华,屈青英
(上海海事大学信息工程学院,上海201306)
0 引言
随着互联网的发展迅速以及普及,直接带动了在线社交网络的急速发展,使得用户可以通过像新浪微博等这样的社交网络平台发布信息、传播信息、接受信息等,这使得网络平台聚集了大量的极具价值的用户信息,在重大新闻迅速传播、网民交流沟通便利等方面表现出了积极作用。但与此同时也衍生出了网络水军,网络水军是一群在特定时间发布特定内容被雇佣的网络写手,网络水军的出现导致了网络平台谣言盛行、引导舆论走向,诈骗恐吓猖獗,给国家政治经济文化活动带来不可估量的损失,并使得社会舆情不可控制,虚假信息泛滥,甚至引发了多个层次的社会事件,如百姓对抗政府,医患、警民、军民关系恶化。所以水军识别是一个非常有意义非常有价值也亟待解决的问题。
目前,国内一些学者针对微博水军事件进行分析。莫倩等人[1]总结了目前的水军识别研究现状,网络水军检测选取的特征属性主要包括:微博内容、用户行为和网络环境。相关研究多关注基于特定类型的网络水军的特征,例如基于内容、行为以及网络环境等单个类型,这些方法无法全面分析网络水军行为,因此其识别准确率具有瓶颈。在此基础上,综合多种特定类型的网络水军识别方法对于各个目标领域的网络水军都具有较高的识别准确率。本文提出一种基于Tensor-Flow 深度神经网络的水军检测模型,将内容特征、行为特征和网络特征于一体,获取相对应的特征目标作为模型的输入。
1 相关研究
对于如何快速识别网络水军的研究,相关科学家取得了不少结果.这些成果主要是从用户内容特征、用户静态特征以及网络特征三个方面进行网络水军的识别。
Gao 等人[4]提出了一种在脸书平台上通过分析照片墙帖子中包含的常见URL 和相似文本,从而识别水军活动。Yang 等人[6]分析了Twitter 中网络水军的隐藏方法,并提出基于邻节点特征去识别Twitter 中网络水军的方法。但此方法从网络水军的邻节点入手,可能会将非水军用户节点误判为水军用户,导致识别准确率不高。本文提出的模型避免了从单特征出发检测网络水军的片面性,降低错判的概率,本实验选取十四个对识别水军有影响的特征属性,同时利用TensorFlow框架[8],结合深度神经网络学习算法,大大提高了迭代的速度,提高了准确率,为网络水军识别研究提供了有力的技术支持。
2 水军识别算法模型设计
2.1 问题的定义
由于目标对象的不同,水军用户从本质上和正常用户有很大的区别,因此导致了其行为特征、发布内容以及用户关系等有很大差异。换言之,针对某用户而言,其行为表现为和水军用户相似或和正常用户相似两种形式。所以我们就将水军识别问题转化成一个二分类问题。

简化后的目标函数即为U →{ }0,1 的映射。其中0 表示正常用户,1 表示水军用户。
2.2 特征属性的选取和分析
(1)数据集的获取
实验数据集采集自中国最大的在线社交网站新浪微博。新浪微博的信息内容被限定在140 个汉字以内,对于博主的博文允许陌生人评论、转发以及点赞,其中博文内容以及评论转发内容可以包括图片和视频链接。
本文选取热门话题及博文万达地产债今天被砸得很惨,通过内部渠道获取了413 个水军用户以及2102个非水军用户,然后通过Python 的Scrapy 爬虫框架对用户特征信息进行爬取。同时利用Scrapyd 技术,定时将获得用户的所有特征信息存入到MongoDB 数据库中。
(2)特征选取
本文选取除了Regression[11]和NavieBayes[12]等其他论文选取的基本特征外(如粉丝数(followers_count)、关注数(follow_count)、微博总条数(statuses_count)、微博原创数(original_count)、微博转发数(forward_count)),还加了其他相关特征作为输入进行深度神经网络(DNN)的训练,具体全部特征选取如表1。

表1 输入特征
部分解释如下:
①粉丝数Nfollowers
粉丝数反映用户的受欢迎的程度,正常用户的粉丝数相对来说比较稳定,而水军用户为了伪装自己的身份,大都会关注大量正常用户,然而得到对方回粉的比例就很小,所有水军用户粉丝数占比就相对很少。
②关注数Nfollows
关注数,顾名思义为用户所关注的对象,一般反映的是直接的社交圈。正常用户大都只会对自己亲朋好友或者感兴趣的领域博主进行关注,因此用户的关注数的数量相对比较合理,而水军用户为了完成自己的任务,会关注大量不同领域的博主。由此可以得出,水军用户的关注数比正常用户的关注数要高很多。
③粉丝/关注比Rff

其中,Nfollowers 是关注数,Nfollows 是粉丝数。由于为了完成上级派发的任务,水军用户会大量关注正常用户,而获取对方回粉的机率较低,因此从图的状态特征来说,就会呈现出高出度和低入度。
④微博转发Nforward
水军用户为了完成任务,通常要转发大量微博,而正常用户通常转发量相对较少。
⑤原创/转发比Rof

其中,Norigin 为用户微博原创的数量,Nforward为用户微博转发的数量,水军通常会转发大量微博来完成任务,所以水军用户通常会呈现出高转发,低原创的状态。
⑥阳光信用Sun sh ine Credit
阳光信用是微博2016 年新加入的属性,分数是结合用户的注册时间、微博等级、违规与否、所发微博质量、活跃程度、实名与否以及微博互动等行为,分为极低、较低、一般、较高、极高共5 个不同的等级,在本实验进行预处理时将级别设置数值1~5 作为训练集的输入。
⑦账户注册时间Re gis tr ation Date
以往的相关工作,很少注意到注册时间的这一属性,其实在互联网平台尤其是新浪微博,可以通过其注册时间来判断是否是水军,非水军用户通常注册时间年限很久,大量的水军用户通常注册时间比较新,加上转发的微博数量,作为深度学习的输入,更能准确识别水军用户。
⑧微博等级Urank
微博等级是根据用户活跃天数确定的,是用户使用微博时间长短及活跃情况等综合体现,用户只需每天登录并使用微博,积累在线时长,就可以获得活跃天数,从而获取等级。等级越高。水军用户普遍等级不高。
2.3 模型的定义和表示
(1)模型总体框架
TDN 模型旨在利用TensorFlow 的深度神经网络的准确性,加上重要特征属性的选取,从而提高检测出网络谣言水军的准确率,其TensorFlow 模型运行流程框架如图1 所示。基本步骤大致分为四步:①初始化变量。②构建session 会话。③训练算法。④实现神经网络。其中包括ReLU 函数(激活函数)和Loss(损失函数)的选取。其中Identity 为激活函数设置为全等映射,目的是暂且不使用Softmax,会放在之后的损失函数中一起计算,并且identity 是返回一个一模一样新的tensor 的op,这会增加一个新节点到gragh 中。global_step 在滑动平均、优化器、指数衰减学习率等方面都有用到,代表着全局步数,类似于一个钟表,管理者全局迭代次数。其中图2 为图1 中DNN 的展开。里面包含了输入输出、隐层,以及各种函数之间的关系。

图1 TDN处理流程
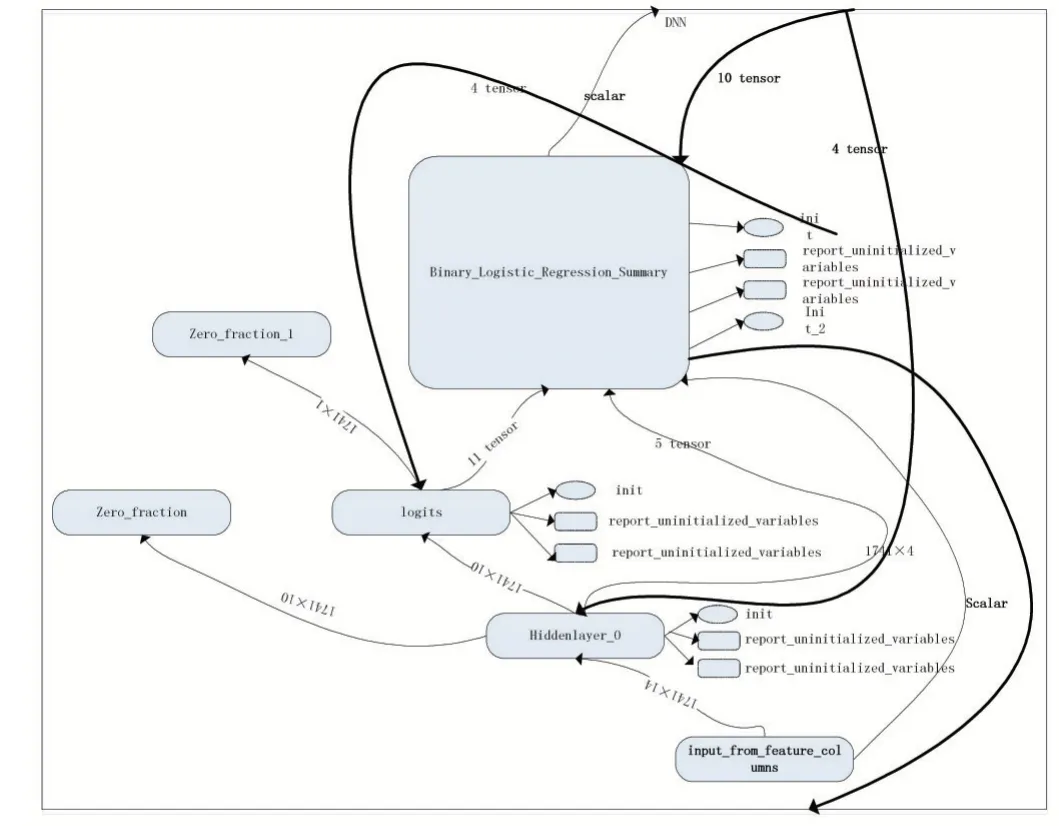
图2 DNN内部关系
(2)激活函数的选取
在深度神经网络中激活函数对实验结果有着直接的影响,本文使用的是一种叫修正线性单元(Rectified Linear Unit,ReLU)9]作为神经网络的激活函数。ReLU函数其实是一种简单的分段线性函数,把所有小于零的值都变为0,正值不变,这种操作被业界成为单侧抑制,单侧抑制有着它不可替代的优势,因为单侧抑制使得神经网络中的神经元具有稀疏激活性。对比其他的激活函数来说,ReLU 激活函数的不仅在深度神经网络中表达能力强,而且对于非线性的函数而言,ReLU 函数由于非负区间为常数,因此不存在梯度逐渐消失问题,使得算法模型的收敛速度维持在一个稳定状态。
3 实验
3.1 实验环境和配置
实验运行环境为:Windows 7 操作系统,1.80GHz 4核处理器,8GB 内存,模型的框架为TensorFlow,编写语言为Python。
实验数据:实验选取了五组数据,是通过特殊渠道购买来的真实数据,共包含413 个水军用户和2102 个正常用户,14 个特征属性,实验将这些用户等比例分成五组,在同一条件下,进行三种算法模型准确性的比较。
3.2 算法准确性
本文对比了以下3 种方法:基于逻辑回归的方法(简称Regression)[11]、基于朴素贝叶斯的方法(简称Naive Bayes)[12]以及本文算法TDN。其中Regression 由谢忠红等人提出,他选取了用户的行为特征、内容特征等,实现对网络水军的检测,NaiveBayes 则是张艳梅等人设计的微博水军识别分类器,它选取了6 个特征属性作为分类依据。本组实验比较各个模型之间的准确度,以及不同参数对本模型准确度的影响,如图4 所示,图中每一组实验中的左边为Regression 算法的准确率,中间为TDN 的准确度,右边为Naive Bayes 的准确度。由于深度神经网络的核心是利用了反向传播算法,加上梯度下降算法对神经网络做进一步优化,使得TDN 无论从准确性还是稳定性都由于其他两种算法。

图3 三组不同算法的准确度
3.3 确定隐层节点数的试凑法
TensorFlow 深度神经网络[13]主要分为三个层次,输入层、隐层以及输出层,其中隐层又可以分为不同的层数,不同层数又可以设置不同的结点数,得到的准确率会有很大的差异。一般来说,增加隐层的层数虽然可以使误差变小和提高结果的精度,但与此同时也使得深度神经网络变得很复杂,进而使网络的迭代训练时间增加,甚至会出现过拟合的现象。所以一般来说,设计神经网络应将3 层隐层网络作为首选。为了实验更加准确,本文采用试凑法来确定隐层的节点数,试凑法的核心思想是在得知隐层节点数的上界和下界的前提下,构造出三层深度神经网络并且对设置不同隐层节点数分别进行训练迭代,然后按照统一指标对每一个网络的性能进行评估,最后选择最满意的节点数。
设函数P 为性能函数,P(Mhid)代表隐层节点数为Phid时的网络性能,P(Mhid)值越大,代表网络性能越好。隐层节点数的上界为Mh,下界为M1,那么由试凑法得 到 的隐 层 节点 数 为Mhid=argmaxMl≤Mhid≤MhP(Mhid) 。利用试凑法以及仿真实验得到的结果如图5 所示,三层隐层的节点数分别为10,20,15 得到的准确率最高。
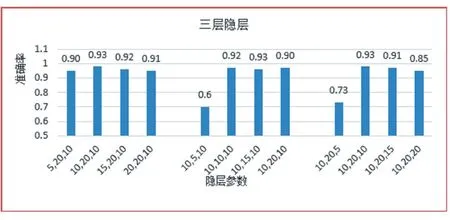
图4 三层隐层不同节点数对算法的影响
3.4 训练迭代次数对实验准确度的影响
不同的训练迭代次数对实验结果的准确率也有很大的影响,本实验在相同实验下,共包含413 个水军用户和2102 个正常用户,层数为3 层,每层节点分别为:10,20,10。分别测试了不同迭代次数对应的准确率,从图5 中可以看出,训练次数达到10000 次时到达一个峰值,随后准确率逐渐降低,次数小于10000 次,实验结果会出现欠拟合现象,也就是训练的不够,没有尽可能拟合数据,然而超过1 万次准确率出现下降的原因就是出现了过拟合的现象。

图5 迭代次数对算法的影响

图6 噪声对算法的影响
3.5 不同层数对时间和精确度影响
众所周知,神经网络的不同层数对实验准确度以及时间性能也有很大的影响[15],本实验对于隐层的1 到8 层分别做了5 组实验,实验数据集取3.2 节的数据集,为了统一变量,对每一层的节点取相同节点数10,对实验结果取其平均值,得到如图9 两组折线,其中系列一为准确度,系列二为时间。此图可以看出对于准确度来说三层隐层为最佳层数,而随着层数的增加,TensorFlow 的计算复杂度提高,进而导致需要更多的时间来对数据进行反向反馈。
4 结语
本文主要介绍了一种基于TensorFlow 的深度神经网络的水军检测模型,选取了三个维度的14 个特征参数,对每一维度选取的特征都进行了必要的分析,并且证明了基于这些特征的判定方法可行性。利用新浪微博API 以及Python 的Scrapy 框架对微博数据进行实时爬取和处理,得到实验所用数据集,对文章中提到的TDN 识别模型进行了准确度对比和性能测试。在同一条件下比较了TDN 和其他模型以及影响模型性能的因素都做了一一分析,TDN 模型具有准确度较高,迭代速度快,能够大规模处理数据等特性,特别适合应用于水军识别的二分类问题。但由于不均衡数据的输入,深度神经网络算法还是容易出现欠抽样,从正常用户训练的很充分,而水军用户就训练不足,从而导致精度下降,如何在正负样本不均衡情况下充分利用现有的正负样本,进一步提高准确度,是接下来我们继续深入研究的方向。与此同时,统计机器学习中很多其他的监督学习模型,如支持向量机,Xgboost 分类器等是值得我们进一步深入研究的识别方法。

图7 不同层数对时间和精确度的影响
