基于机器学习的NIR光谱柑橘产地鉴别框架
2019-07-25但松健
但松健
(重庆第二师范学院 继续教育学院, 重庆 400067)
近红外光谱分析技术作为一种快速、准确、便捷且非破坏性的分析技术,在农产品品质检测和产地鉴别方面得到了广泛应用,被认为是有望替代传统化学分析的无损检测方法[1-4]。目前,基于近红外光谱分析的柑橘产地鉴别技术还较为耗时费力且不够精确,其完整性、系统性和操作性还与实际应用有很大差距,建立一套能对柑橘产地进行快速鉴别的有效技术体系,对于柑橘产业在我国的健康发展有着重要的作用[5-6]。
一、基于机器学习的NIR光谱柑橘产地鉴别框架
本文通过基于机器学习的光谱分析技术建立了一种快速无损的柑橘产地鉴别通用框架,具体流程如图1所示。首先,采用预处理算法对光谱进行整形降噪,从而降低原始数据中的噪声对分类器的干扰;其次,采用PCA方法对降噪后的NIR光谱进行特征抽取,从而将高维数据降维到适当的维度;然后,利用特征选择算法对降维后的光谱数据进行适当的特征选择以利于分类器更快更精确地学习;最后,选择不同的分类器,在统一的训练框架和性能评价指标下,选出最优的分类器建立光谱识别模型[7-12]。
二、实验结果及分析
在实验中,选取了常见的朴素贝叶斯、最近邻分类(KNN)以及决策树算法作为测试分类器[13-14],对采集的6个省市16个不同地区的柑橘进行产地鉴别。原始近红外光谱的范围为1000~2499 nm,原始特征维度为1500维。每个地区约采集100个柑橘样本,总的样本数量为1558个。根据鉴别框架对原始光谱数据进行预处理、特征抽取、特征选择以及模型交叉验证,以得到最后的性能评价。所有的模拟实验都在Windows 7平台使用Matlab 2008b实现,使用了统计工具箱和数据挖掘工具箱。
(一)原始光谱及预处理结果
考虑到近红外光谱仪器、实验环境和操作误差带来的不可避免的噪声,对原始数据进行预处理以去除噪声干扰是非常必要的。采用SG平滑法对光谱进行整形,SG平滑在121大小的窗口下进行,并用到了原始SG平滑及在此基础上衍生出的一阶和二阶导数。这三种去噪方法以及原始光谱的信息如图2所示。
由图2可以看出,经过SG平滑,原始光谱图变得平滑。在进行一阶导数运算后,光谱范围从[0,1]压缩到[-0.002,0.006],光谱信号进一步平滑。从二阶导数的结果看,平滑效果跟一阶导数接近,但数据得到进一步压缩,范围缩小到[-0.00009,0.00007]。虽然导数操作可以进一步平滑数据,但也可能会丢失部分具有区分度的细节。因此,去噪预处理操作需要进行合适的选择。通过图2可以看出,16个地区柑橘样本的光谱具有很大的重叠性,如果直接使用这些数据(1500维)进行识别具有很大的挑战性。
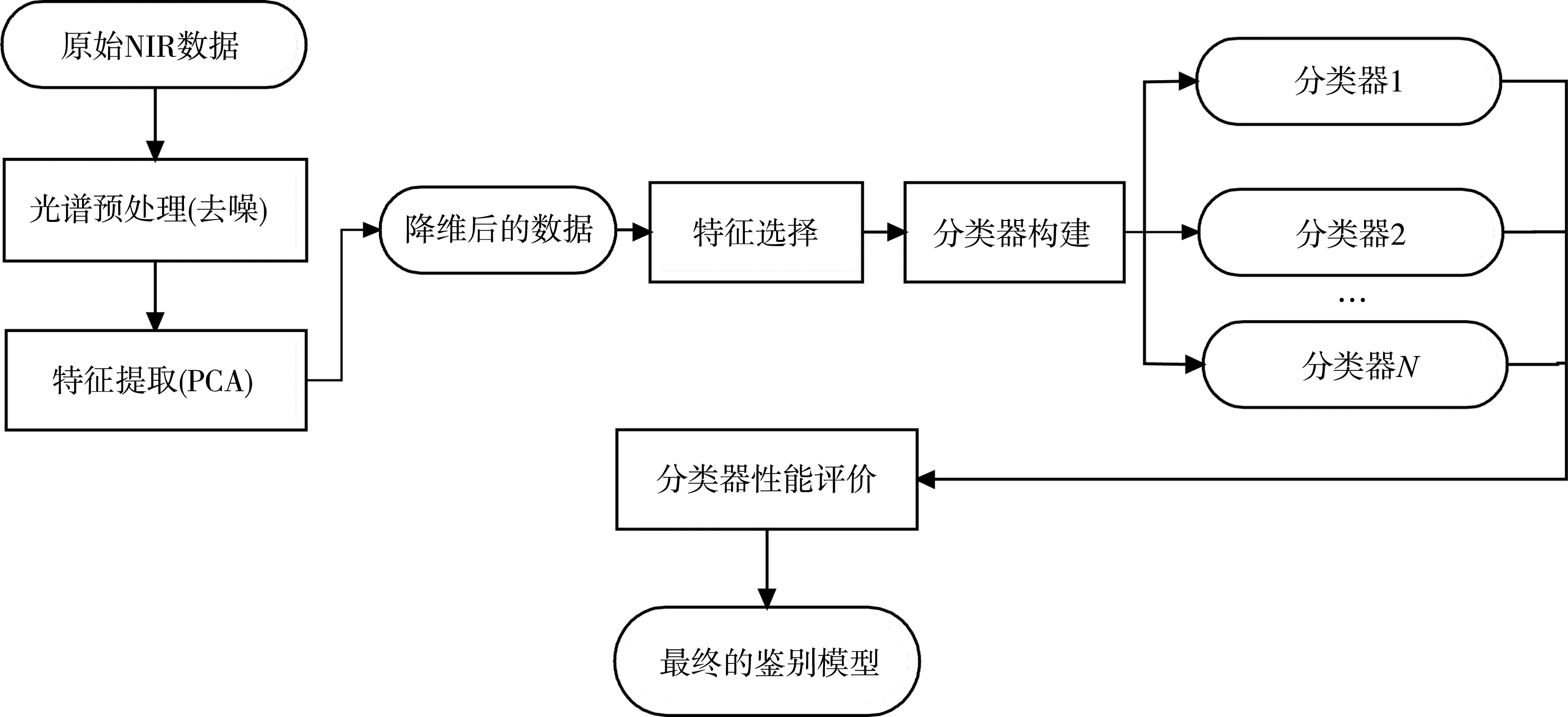
图1 基于机器学习的NIR光谱产地鉴别框架

图2 柑橘原始光谱及去噪后效果
(二)特征抽取结果
从上一小节的实验中可以看出,经过去噪的数据并不适合用分类器进行直接训练,需要进行适当的特征抽取,以便提取主要信息,去除不必要的冗余信息,在识别框架下采用PCA方法来提取光谱的主成分。因为没有足够的证据表明某一段光谱具有很强的区分度,因此对整个光谱段(1000~2499 nm)进行主成分提取以得到最具代表性的光谱信息,以主成分的贡献度排序得到的结果如图3所示。

图3 柑橘NIR光谱数据进行PCA特征抽取之后的主成分贡献度
一般来说,建立模型所需要的主成分个数往往由前几个最有代表性的主成分所占光谱信息的比重来决定。如图3所示,柱状图代表该主成分的贡献度(即所含信息在整个数据集中的比重),红色的点代表其前N个主成分累积贡献度。从图3中可以看出,前3个主成分占据了很大的比重,例如在图3(a)中,对原始的光谱数据进行PCA降维,前3个主成分占据了98.98%的信息量。对SG平滑后的数据提取主成分,前3个主成分占据了99.11%的信息量,而对一阶和二阶导数后的平滑数据,前3个主成分分别占据了95.17%和97.16%。
虽然前3个主成分能有效表示之前的原始数据集,但对于分类器来说,其代表的信息或许并不具有区分度。例如,对原始数据和采用不同平滑算法的前两个主成分的联合分布情况,用散点图来表示,如图4所示。为了更好地显示其分布特性,这里只画出了20个来自5个不同地区的柑橘光谱样本,包括四川武胜,浙江临海,重庆巫山、奉节和北碚。
从图4可以看出,在原始光谱和SG平滑后的光谱数据上进行PCA降维后,不同省市之间的PC分布具有一定的区分度,而位于重庆的3个不同产地的样本由于采集区域较近,柑橘生长环境较为类似,因此出现了一定程度的重叠。使用SG平滑结合一阶和二阶导数法后,样本的分布空间被扩展,从而加大了样本间的分散度,但也进一步增加了样本重叠的区域。无论采用哪种方法,柑橘样本的前两个PC直接进行识别都存在着一定的难度。因此,可以适当加入更多的PC特征增加其辨识度,我们取前20个PC作为训练特征输入分类器中。
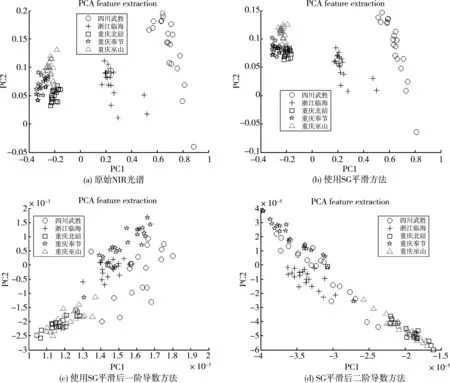
图4 5个地区的柑橘NIR做PCA特征抽取后,贡献度第一和第二的主成分分布
(三)特征选择及分类器性能结果
通过数据平滑和主成分提取后,主要采用了机器学习算法中的常见分类器,包括了决策树算法(DT)、贝叶斯分类器(NB)、K近邻分类器(KNN)和线性判别分类器(LDA),对6个省市共计16个地区的柑橘样本进行了产地鉴别模型的建立。根据提出的产地鉴别框架,所有的分类器都进行了5×10次交叉验证,并将50次运行后的平均识别率作为输出结果,各个分类器性能如表1所示。
首先,在没有进行特征选择的情况下,表1统计了测试的4个分类器平均准确率Pa。
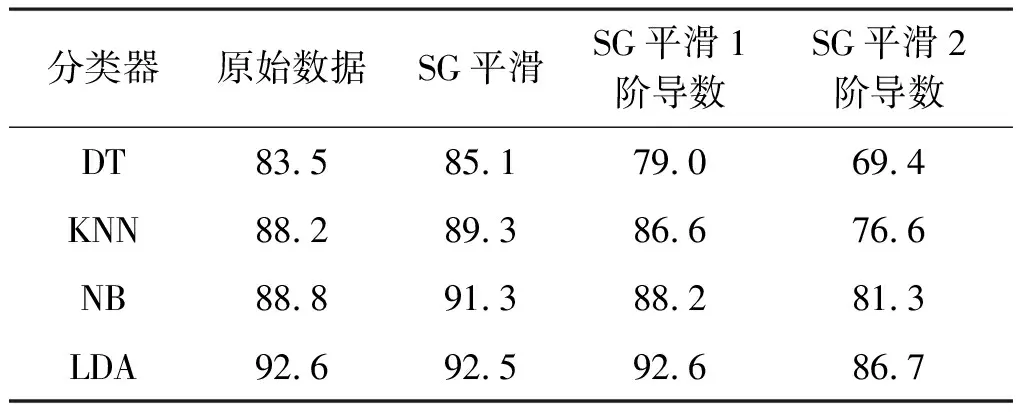
表1 无特征选择时,测试的4个分类器的产地鉴别平均准确率Pa %
注:DT为决策树,NB为贝叶斯,KNN为最近邻,LDA为线性判别
从表1可以看出,LDA分类器在各个数据集上的表现最优,最高达到了92.6%的平均准确率,其次是KNN和NB分类器。在数据平滑算法方面,相比原始数据集,在采用SG平滑的数据集上,DT、NB和KNN分类器的性能都得到了明显提高,而LDA算法变化不大,但SG平滑后结合导数的方法反而降低了识别精度,特别是导数阶数越多、效果越差,其原因可能是过多的平滑导致了具有区分度的特征的丢失。
为了进一步显示交叉验证中50次测试的分类器的性能及其稳定性,通过4个分类器在不同平滑算法下的盒图[14]发现,使用SG平滑后大部分分类器的预测准确率达到了最高(除LDA与采用原始数据持平),并且最为稳定,而采用一阶和二阶导数后,由于数据被过度平滑,影响了其稳定性。
除了准确率,本文还统计了其他性能指标,如敏感度(TPR)、特异性(FPR)和综合指标F1,结果如表2所示。
表2结果与表1类似,在各项性能指标上,LDA仍然得到了最高的识别率,DT、KNN和NB分类器在SG平滑的数据集上识别结果较好。

表2 无特征选择时,测试的4个分类器的产地鉴别平均敏感度、特异性和综合指标F1值
注:DT为决策树,NB为贝叶斯器,KNN为最近邻,LDA为线性判别
对PCA降维后的特征进行进一步的选择,对同样的分类器和数据集进行了交叉验证,结果如表3所示。经过特征选择后,LDA模型依旧获得了最高的识别准确度,但相比特征选择前的提高并不明显,原因在于LDA在寻求最佳的投影方向时已经考虑具有最大区分度的特征投影方向,而其他模型相比特征选择前的性能都有了明显的提高,KNN和NB都达到了较高的识别度(≥90%),特别是在采用二阶导数法平滑的数据集上,测试的4个分类器都有了较大的提升。提高最多的为DT和KNN模型,平均准确率分别从69.4%和76.6%提高到了80.4%和88.0%。

表3 进行特征选择后,测试的4个分类器的产地鉴别平均准确率Pa
注:右侧数据为对比未进行特征选择的分类器的结果差异,“+”号表示较之前有所提升,“-”表示识别率下降
最后,表4给出了进行特征选择后,基于敏感度(TPR)、特异性(FPR)和综合指标F1的结果。可以看出,在进行特征选择后,KNN和NB达到了与LDA相近的性能,DT模型的识别效果也有显著提升,而LDA提升不大,并且各个数据集的性能差异并不明显。

表4 进行特征选择后,测试的4个分类器的产地鉴别平均敏感度、特异性和综合指标F1值
注:DT为决策树,NB为贝叶斯,KNN为最近邻,LDA为线性判别
三、结语
本文针对柑橘光谱产地识别问题,提出了一个通用识别框架并在该框架下对柑橘样本进行了产地鉴别。首先,采用SG平滑法以及SG平滑结合一阶和二阶导数法对数据进行平滑,并采用PCA对数据降维以抽取最有代表性的特征,之后利用特征选择算法对抽取后的特征进行最有区分度的选择,最后采用决策树、最近邻、朴素贝叶斯和线性判别分析模型,对16个地区的柑橘数据建立产地鉴别模型。实验结果表明,SG平滑算法能增强大部分分类器的识别能力,特征选择算法也对柑橘产地的鉴别有积极作用。在测试的分类器中,LDA的性能最为稳定,并获得了最优的产地鉴别准确率92.8%。
