融合词性的维吾尔语文本分类研究
2019-07-25李高鹏艾山吾买尔
李高鹏,艾山·吾买尔
(新疆大学信息科学与工程学院,乌鲁木齐830046)
0 引言
文本分类技术是指利用计算机编写程序,实现把某一文本按照一定的标准规范,划分到给定的类别中的技术。文本分类技术被广泛应用于信息检索、数字化图书馆、有害信息过滤、搜索引擎等领域[1]。研究维吾尔语(以下简称维语)文本分类有助于管理和筛选互联网上海量的信息。目前维语文本分类的研究主要采用基于机器学习的方法[2-5],基于深度学习的维吾尔文文本分类研究较少,文本分类实验的结果仍有待提高。目前的维语文本分类在特征提取时采用的是信息增益(IG)、期望交叉熵(ECE)等方法,向量表示方法采用的是向量空间模型(VSM)主要存在三个问题:①特征空间存在高纬度的问题;②向量表示存在高稀疏性的问题;③在以往的研究中很少考虑词性特征对维语文本分类实验的影响。
基于以上问题,为了降低特征空间的维度,和向量表示稀疏性的问题,本文根据将训练语料花费为以下三组,第一组训练文本为仅仅对待训练文本进行去停用词等处理,用来作为基线与其他组实验进行对比;第二组训练语料是根据词性特征从第一组训练语料中筛选出名词、动词、形容词,过滤掉其他词汇(如:副词、连词、代词等);第三组训练语料是根据词性特征从第一组训练语料中只挑选出文本中词性为名词的词汇作为文本特征。本文通过对这三组训练语料,采用机器学习的方法,以及深度学习的方法进行实验,研究了解维语词性特征对分类结果的影响,通过将这训练三组语料,在传统机器学习方法SVM、KNN、DTree 以及深度学习方法CNN、RNN、CNN-BLSTM 上进行实验,对比实验结果发现在机器学习方法上,通过改变特征选择的方法,提高了文本分类的准确率,并且大大降低了训练时间;在基于神经网络的算法上,第三组训练语料较第一组训练语料及第二组训练语料,准确率有所提高,训练时间也有所降低。
1 相关工作介绍
1.1 维语文本分类研究现状
2007 年胡燕等人[6]提出将类别特性强的名词、动词作为文本的一级词性提取出来,提高了特征提取的效率,降低了特征向量的维度,不失为一种简单高效特征提取方法。2015 年路永和等人[7]引入词性特征改进了特征权重的计算方法,提高了分类的准确率。贾会强等人[24]提取藏文中的名词动词作为一级词性再通过计算这些词的文本频数(TF)和文档频数(DF)来计算其权重;根据权重进行排序,筛选出前K 个词作为特征空间。2017 年黄贤英等人[8]在利用基于语义的短文本相似度进行文本分类时通过对提取到的关键词的词性不同赋予不同的权重系数,以此区别各种贡献度词项在短文本相似度计算中的重要程度,有效的提高了短文本分类的准确率。在这些方法中考虑了词性特征,不同的词性包含的信息不同,对于具有较强分类特性的词赋予较高的权重或者是直接将具有很强分类特性的词作为一级特征词进行特征选择,缺乏了更进一步的研究和对比,本文在考虑影响分类类别的重要因素时,通过人工观察及对比发现包含类别信息最多的词是名词,动词、形容词、代词、量词等包含较少的类别区分特征。
2012 年阿力木江·艾沙等人[3]提出了基于统计方法的维语短语抽取算法,采用支持向量机(SVM)算法进行了分类实验。买买提依明·哈斯木[4]提出了一种基于N 元模型的维语文本分类技术。2016 年阿力甫·阿不都克里木等人[9]提出一种基于TextRank 算法和互信息相似度的维文关键词提取方法,然后根据互信息相似度度量,计算输入文本关键词集和各类关键词集的相似度,实现了文本分类。2017 年吐尔地·托合提等人[5]研究了一种n元递增算法来抽取维吾尔文本中表达关键信息的语义串,提出了一种类似于Jaccard 相似度的文本和类主题相似度度量方法,实现了维语文分类算法。以上关于维语的文本分类研究大都还停留在传统的机器学习的方法,基于深度学习的维语文本分类研究较少,维语文本分类的研究仍有很大的提升空间。本文在研究词性对基于传统机器学习的文本分类结果的同时也研究词性对基于深度学习算法的文本分类结果的影响。
1.2 维语词性
维语构词和构形附加成分很丰富。关于维语词性的划分有不同的标准,表1 所示的是新疆大学多语种信息技术重点实验室独立创建了维语词性划分的标准[10]。

表1 维语一级词性划分标准

图1 词性分布表
图1 是对实验所用的语料进行统计得到的词性分布,可以看出名词词性在所有词中占据了54%的比例,动词占据了20%的比例,形容词占据了9%的比例。名词、动词、形容词加起来占据了所有词中83%的比例,其他词性的词汇合计占据17%。因此本文根据词性的比重设计的第二组训练语料为只保留文本中为名词、动词、形容词词性的特征与只去除停用词的第一组训练语料作对比,同时考虑到针对文本分类问题,动词和形容词似乎对分类的作用没有名词的影响大,于是在本文的第三组训练语料中,只保留了维语文本中名词词性的词汇。
1.3 支持向量机
支持向量机是建立在统计学习理论基础上的一种有监督的机器学习方法,主要思想是在线性可分的情况下,在文本空间中直接寻找最优超平面,在线性不可分的情况下,通过与高斯“核”函数的结合,将数据从低维映射到高维,构建一个最优超平面,使得超平面两边的样本点到超平面的距离最大。支持向量机的优点在于它将非线性问题转化为线性问题,并将求解的问题转化为一个凸优化问题,对应的局部最优解即为全局最优解,通过将分类间隔最大化,使得支持向量机具有较好的鲁棒性。支持向量机的方法在文本分类中能达到较好的效果。假设训练集为:T={(xi,yi),L,(xi,yi)}∈(X×Y)l,其中xi∈X=Rn为输入样本,yi∈Y={1,-1}代表分类类别,n 维空间中线性判别函数的一般形式为:

要使得f(xi)<-1 或f(xi)>1,并使得分类间隔最大,等式需满足以下条件:

1.4 循环神经网络
循环神经网络主要用于解决时序依赖等问题,循环神经网络可用于股票走势预测、语音识别等领域。通常神经网络模型在各个网络层之间都是全部连接在一起的,各层之间的各个节点之间是没有连接的,而循环神经网络则不同,循环神经网络同一层的输出会传递到同一层的下一个状态,参与运算,进行状态更新,循环神经网络基于上下文的内容是相关的这一假设的基础上,通过共享不同时间的参数,实现对序列数据的处理,学习到不同时间的信息之间的依赖关系。循环神经网络的网络结构如图2 所示。

图2 RNN网络结构
2 实验介绍及实验结果分析
实验的语料来源于天山网和人民网,本文挑选了以下7 个类别,共计26733 篇文本作为实验语料。为了得到可靠稳定的模型,采用交叉验证法,按照8:1:1的比例划分为训练集、验证集和测试集,划分结果如表2 所示。

表2 训练集、验证集和测试集的划分
为了进行对比和比较全面地评估文本分类的实验结果,本文采用准确率(Precision,P)、召回率(Recall,R)和F1值三个指标来衡量实验结果。本文首先对维语文本中的词汇进行词性标注,然后根据词性选择出特定词性的维语词汇特征,用作实验的语料。其中维语词性标注方法采用基于Bi-LSTM-CRF 的词性标注方法实现的[10],准确率达到了98.41%。针对三组训练语料,本文采用期望交叉熵方法进行特征选择,特征空间的维度为5000 维,用VSM 向量空间模型将文本向量化,然后利用KNN、SVM、决策树、逻辑回归、随机森林的方法,进行实验对比,实验结果如表3。

表3 基于机器学习分类算法的实验结果
其中T 表示的是训练耗时单位为时分秒格式,DTree 代表决策树算法、LR 代表逻辑回归算法、RFR代表随机森林算法下同,从表3 可以看出,第三组训练语料在KNN、SVM、逻辑回归和随机森林算法上,F1 的值比在其他两组语料上结果要好,在决策树算法上略低于第二组训练语料,在训练耗时的比较上第三组语料花费的时间也略低于其他两组。实验结果表明直接通过过滤词性提取特征,对文本分类实验结果影响不大,只筛选出名词词性的第三组语料实验结果在多数情况下比筛选名词、动词、形容词的第二组语料和只去除停用词的第一组语料相比分类效果较好,耗时较短,为了继续研究是哪些词汇在影响分类的结果,本文对三组实验的特征集(分别为5000 个词汇)取交集得到3078 个词汇作为特征空间,继续进行实验,实验结果如表4 所示。

表4 缩小特征空间后的基于机器学习分类算法的实验结果
从表4 可以看出利用三组实验特征集合的交集作为特征空间的方法在训练语料一上表现最好,将上面两表中的最好实验结果以及对应训练耗时进行对比,如表5、表6 所示。
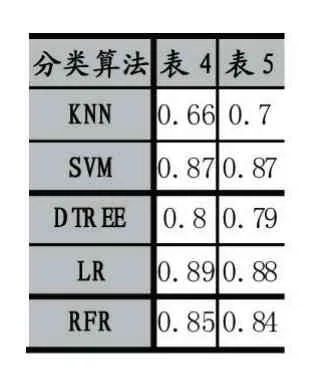
表5 两组最好分类结果对比

表6 两组实验训练耗时对比
由表5、表6 可以看出,通过取三组训练语料特征集合的交集得到的特征集合与三组语料分别进行特征提取再训练的实验结果没有太大的差别,但却大大缩短了文本分类实验的训练时间。
为了更好地对比词性因素对文本分类实验的影响,本文还采用了深度学习中的CNN、RNN、CNNBLSTM 方法进行比较,在文本向量化时,我们选择采用的是字符向量化的方法。

表7 基于深度学习分类算法的实验结果
由表7 可以看出在基于神经网络的文本分类中,第一组语料在CNN 上的实验结果略高于其他两组训练语料,但第三组语料的训练时间较短,并且第三组语料在RNN、CNN-BLSTM 上表现高于其他两组训练语料,训练时间也较短。以上实验表明根据词性过滤后的神经网络分类算法实验,在准确率相差无几的情况下,却可以较大程度上缩短训练时间。
3 结语
实验结果表明名词对维语文本分类的影响最大,动词、形容词等对文本分类的贡献较小。通过期望交叉熵的方法,进行特征提取,可以有效的提取出对分类贡献高的词汇,但通过词性筛选又可大大降低特征空间的维度,大幅缩短训练时间,并且在一些方法上提高了文本分类实验的效果。本文在研究过程中并未采用控制变量法逐一证明各个词性对文本分类的影响,只是通过词性为名词、动词、形容词的词汇包含更多的文本信息这一先验知识的基础上进行的实验对比。
