一种基于Top-K查询的加权频繁项集挖掘算法
2019-07-23赵学健熊肖肖张欣慧孙知信
赵学健,熊肖肖,张欣慧,孙知信
(1.南京邮电大学 现代邮政学院,江苏 南京 210003;2.南京邮电大学 物联网学院,江苏 南京 210023)
1 概 述
近年来,数据挖掘技术在各行各业的决策支持活动中扮演着越来越重要的角色。频繁项集挖掘作为数据挖掘最活跃的研究领域之一,是指发现事务数据中频繁出现的模式的过程,是发现大型事务数据集中关联规则的重要手段,在精准营销、个性化推荐、网络优化与管理、医疗诊断等领域均有广泛的应用[1]。当前,针对确定性数据的频繁模式挖掘理论日趋成熟,然而随着信息采集技术和数据处理技术的快速发展,各种形式复杂的数据逐渐出现在人们面前,不确定数据就是其中之一。
不确定数据是指每一条事务中项目的存在不再是百分百确定的,而是依据某种相似性度量或是概率形式存在。不确定数据主要是由于数据本身的特点或者数据在产生、收集、存储和传输过程中存在大量随机性导致的,比如说通过对购物篮分析从而预测商品需求量时,购物篮中的商品用户并不是肯定要购买的。目前,不确定数据广泛应用于传感器网络、RFID应用、Web应用、商业决策等诸多领域[2]。
数据的不确定性给频繁模式挖掘带来了极大挑战,一方面是相对于数据规模呈指数增长的可能世界实例的数量,另一方面是新出现的概率维度,这导致传统的针对确定性数据的频繁模式挖掘算法的准确性和时效性大大降低,不能满足具体的应用需求。因此,迫切需要提出新的理论模型和算法解决不确定数据的频繁模式挖掘问题。
但是,当前面向不确定数据的频繁项集挖掘研究尚处于研究的初始阶段,大多数研究都假设事务数据库中的项目具有相同的重要性。然而,现实应用中对于用户来讲,往往不同的项目其重要性和价值是有巨大差别的,比如在商品销售过程中价格昂贵的奢侈品和价格低廉的生活用品所带来的利润是不可同日而语的。
为了解决该问题,最有效的办法是给不同的项目赋予不同的权重值。权重值可以由用户根据专业领域知识或者特定应用需求进行设定,可以用来表示项目的利润、风险、代价等。这样一来,频繁项集的挖掘就能够兼顾项目的权重和存在概率,从而克服了传统频繁项集挖掘算法只考虑项目的存在概率,容易遗漏大量具有重要潜在价值的频繁项集的问题。然而,项目权重值的引入使得频繁项集不再满足向下闭包特性,也就是说即使某项集是非频繁项集,其超集仍有可能是频繁项集。这给频繁项集的挖掘带来了巨大挑战,因为不能再根据向下封闭特性对频繁项集的搜索空间进行压缩。
针对不确定数据的加权频繁项集挖掘问题,兼顾项目的权重和存在概率,文中提出一种Top-K加权频繁项集挖掘算法(Top-K Frequent Itemset Mining,TK-FIM),以提高算法的时间效率,有利于迅速找出对用户具有重要价值和意义的频繁项集。
2 相关工作
2.1 不确定数据频繁项集挖掘算法
面向不确定数据的频繁项集挖掘算法大致可分为基于Apriori算法[3]的频繁项集挖掘算法和基于FP-growth算法[4]的频繁项集挖掘算法两大类。
Chui等在传统Apriori算法的基础上提出了不确定数据的频繁模式挖掘算法U-Apriori[5],U-Apriori算法同样需要多次扫描数据库,并会产生大量的候选频繁模式。文献[6]对U-Apriori算法做了进一步改进,提出了MBP算法,实验结果表明MBP算法无论在时间上还是空间上都优于U-Apriori算法。文献[7]将不确定数据的概率频繁模式模型加入到MBP算法中,进而提出了IMBP算法,该算法能够得到比较准确的不确定数据频繁项集挖掘结果,而且数据挖掘效率得到了进一步提升。文献[8]将Apriori算法与启发式算法进行结合,提出了GA-Apriori算法和PSO-Apriori算法,大大提高了频繁项集的挖掘效率,但是这两种算法不能精确地挖掘出不确定数据集中的所有频繁项集。
Leung等提出了基于树的UF-growth算法[9],该算法大大加快了不确定数据频繁项集挖掘算法的运行速度。然而相对于FP-growth算法来说,UF-growth算法在建树过程中项目的合并条件更为苛刻,导致了UF-growth算法需要耗费大量的内存空间。文献[10]提出了基于树的不确定数据频繁项集挖掘算法UFP-growth,该算法在挖掘过程中会产生大量条件模式树,相应的计算量也会大大增加。Lin等提出了CUFP-Mine算法[11],该算法将所有事务项压缩到CUFP-tree上,在构建CUFP-tree树的过程中,如果插入项已在树中,将此项的期望支持度累加,并且计算此项超集的期望支持度;否则,创建新的节点并加入到相应路径尾端,存入此项的期望支持度及其超集的期望支持度。Length等提出了基于上界的不确定数据频繁模式增长算法CUF-Growth[12],以及基于前缀上界的不确定数据频繁模式增长算法PUF-Growth[13]。这两种算法虽然可以构建结构更加压缩的树结构,减少了对内存空间的占用,但是仍然需要通过探索、合并的方式发现概率频繁项集,导致发现概率频繁项集耗时较多。文献[14]提出的TPC-growth算法在PUF-growth算法的基础上进行了改进,采用过估计的方法使上界更加逼近期望支持度,但是该算法仍不能从给定的不确定数据库中提取出精确的频繁模式。文献[15]在分析当前基于树结构的频繁项集挖掘算法的基础上,提出一种基于列表的数据结构和修剪技术,该算法可以准确地挖掘不确定数据集中的频繁项集,并且具有较高的效率。文献[16]提出一种新的算法SRUF-mine用于挖掘流频繁项集,理论和实验结果表明SRUF-mine算法是一种有效的挖掘不确定性数据流频繁项集的算法,具有良好的时空效率和扩展性。
2.2 加权频繁项集挖掘算法
在频繁项集挖掘的过程中,引入权重的概念,有利于从海量数据中挖掘出对用户真正有意义,有价值的信息。因此,针对加权频繁项集挖掘算法的研究近年来引起了研究人员的广泛关注。
Abraham等基于频繁模式增长范式对加权事务数据库进行分析,并提出了用于加权频繁项集挖掘的FWIHT(frequent weighted itemset mining using homologous transaction)算法和用于稀有频繁项集挖掘的RWIHT(rare weighted itemset mining using homologous transaction)算法[17]。Baralis等将单样本基因的表达值作为权重,提取加权频繁项集,发现基因间的关联性,避免了对基因数据库分析的离散化过程,从而提高了基因分析的效率[18]。Lee等提出一种用于动态数据库的基于树的可删除项集挖掘算法,算法考虑了不同项目的权重因素,并采用树和列表数据结构辅助挖掘,有利于有效地执行挖掘操作[19]。
上述算法均是针对二元数据库的加权频繁项集挖掘问题提出的有效算法,但是针对不确定数据库的加权频繁项集挖掘问题研究尚未引起重视,研究成果极少。Lin等最近提出了用于不确定数据库加权频繁项集挖掘的HEWI-Uapriori算法[20],该算法使用带上限的期望加权向下闭包特性对非频繁项集进行缩减,以提高算法的时间效率。
3 相关定义与问题描述
3.1 相关定义
假设D是待挖掘的不确定数据库,数据库D中包含一组事务集合,即D={T1,T2,…,Tm},并且每个事务包含一个特定的事务号TID。数据库D中包含的项目集合为I={I1,I2,…,In},则有Tq⊆I,1≤q≤m。数据库D中,每个事务Tq中的项目Ij,1≤j≤n都对应一个确定的存在概率,记为p(Ij,Tq),表示项目Ij在事务Tq中出现的概率。此外,数据库D中的每个项目Ij都对应一个权重值wj,项目集合I中的所有项目对应的权重值构成权重向量w={w1,w2,…,wn}。如果项集X包含k个不同的项目,称项目X为k项集。如果X⊆Tq,称项集X出现在事务Tq中。为了进行加权频繁项集的挖掘,需要事先给出最小期望加权支持度阈值ε,为加权频繁项集的判定提供依据。文中给出的不确定数据库D包含10个事务,分别为T1-T10,包含4个项目为A-D。
定义1(项目权重):项目权重是用户根据喜好或专业知识设置的用于描述项目重要性的值,项目Ij的权重值记为w(Ij),w(Ij)∈(0,1]。
定义2(项集权重):项集X的权重为该项集所包含各项目权重的平均值,记为w(X):
(1)
其中,|k|为项集X所包含的项目数量。
定义3(项集在事务中的出现概率):项集X在事务Tq中的出现概率记为p(X,Tq),等于项集中各项目在事务Tq中出现概率的乘积。
即:
(2)
其中,Ij为项集X的第j个项目。
定义4(项集的期望支持度):项集X在不确定数据库D中的期望支持度记为expSup(X),等于项集X在包含该项集的所有事务中的出现概率之和。
即:

定义5(频繁项集):在不确定数据库D中,当项集X的期望支持度大于等于最小期望支持度时(最小期望支持度为最小期望支持度阈值δ与数据库D中所包含事务数的乘积),则项集X为频繁项集,记为FIS。即当expSup(X)≥δ×|D|时,项集X为频繁项集。
定义6(项集的期望加权支持度):项集X在不确定数据库D中的期望加权支持度记为expwSup(X),等于项集X的期望支持度与项集X的权重的乘积,即:
(4)
定义7(加权频繁项集):在不确定数据库D中,当项集X的加权期望支持度大于等于最小期望加权支持度时(最小期望加权支持度为最小期望加权支持度阈值ε与数据库D中所包含事务数的乘积),则项集X为加权频繁项集,记为加权频繁项集WFIS。即当expwSup(X)≥ε×|D|时,项集X为加权频繁项集。
3.2 问题描述
根据上述定义,对不确定数据库中加权频繁项集挖掘问题可进行如下形式化描述。在不确定数据库D中,若用户给定了数据库中各元素的权重w和最小期望加权支持度阈值ε,挖掘加权频繁项集即判断项集X是否满足expwSup(X)≥ε×|D|的过程。加权频繁项集的挖掘综合考虑了项目的权重和存在概率因素,因此得到的加权频繁项集对用户来说具有更好的价值和意义。
但是,通过分析,对于加权频繁项集的挖掘,向下闭包特性已经不再适用,这增大了加权频繁项集挖掘的难度和时空复杂度。
因此,提高挖掘算法的时空效率是加权频繁项集挖掘算法需要实现的首要目标。
4 TK-FIM算法
为了提高频繁项集挖掘算法的时空效率,文中提出了适用于加权频繁项集挖掘的TK-FIM算法,以对加权频繁项集的搜索空间进行压缩,提高挖掘效率。该算法的伪代码如下所示。
TK-FIM算法:
输入:不确定数据库D,权重表wT,用户指定的最小期望加权支持度阈值ε
输出:加权频繁项集集合WFIS
1.let CFIS1=I,TKWFIS1=Top-K(CFIS1)
2.for each itemIj∈CFIS1inDdo
3.scanDto calculate expwSup(Ij)
4.if expwSup(Ij)>ε×|D| then
5.WFIS1=WFIS1∪{Ij}
6.end if
7.end for
8.WFIS=WFIS1
9.setk=2
10.while WFISk-1≠null do
11.CWFISk=Connection(WFISk-1,TKWFIS1)
12.for each candidatek-itemsetXin CWFISkdo
13.if expwSup(X)>ε×|D| then
14.WFISk=WFISk∪{X}
15.end if
16.end for
17.WFIS=WFIS∪WFISk
18.k=k+1
19.end while
20.return WFIS
TK-FIM算法主要包括以下步骤:
(1)令候选1项集集合为不确定数据库D对应的项目集合I,令CFIS1中期望加权支持度Top-K的项集集合为TKWFIS1。扫描不确定数据库D,对候选1项集集合CFIS1中的1项集进行验证,根据定义7生成加权频繁1项集WFIS1,并将WFIS1加入加权频繁项集集合。
(2)设置k值为2,当频繁1项集WFIS1为非空集时,将频繁1项集WFIS1与CFIS1中期望加权支持度Top-K的1项集集合TKWFIS1进行连接,从而得到候选加权频繁2项集集合CWFIS2,扫描不确定数据库D,对候选加权频繁2项集集合CWFIS2中的2项集进行验证,根据定义7得到加权频繁2-项集WFIS2,并将WFIS2加入加权频繁项集集合,最后设置k=k+1。
(3)依此类推,可得到WFIS3,…,WFISk,直到WFISk是空集为止。
最终,运行TK-FIM算法得到的加权频繁项集为WFIS=WFIS1∪WFIS2∪…∪WFISk。
5 实验与结果分析
本小节将分别在合成数据集和真实数据集上对TK-FIM算法的性能进行分析,包括算法的时间效率分析和算法所生成频繁模式的数量及分布情况分析,并将TK-FIM算法的性能与Uapriori算法及HEWI-Uapriori算法的性能进行对比分析。
5.1 实验设置及相关说明
实验平台配置为:Intel Core i7-4510U 2.6 GHz处理器,8 G内存,Windows 7 64位操作系统。实验所采用的合成数据集T10I4D100K和真实数据集retail均来自http://fimi.ua.ac.be/data/。数据集特征如表1所示,其中|D|为数据集所包含的事务数,|I|为数据集所包含的项目数,AvgLen为平均每条事务包含的项目数。

表1 数据集特征
此外,还需要说明以下两点。第一,由于合成数据集T10I4D100K和真实数据集retail均为普通的确定数据集,不包含项目的权重信息和项目在事务中存在的概率信息,因此在分析TK-FIM算法性能之前需要首先为两个数据集生成项目权重信息和概率信息。为了避免权重和概率的取值对算法性能的影响,每一项实验均采用5组不同的权重值,5组不同的项目概率值进行实验分析,实验结果取25组结果的平均值。第二,Uapriori为适用于不确定数据集的频繁项集挖掘算法,运行Uapriori算法得到的频繁项集称为EFIs(expected support frequent itemsets);HEWI-Uapriori为适用于不确定数据集的加权频繁项集挖掘算法,运行HEWI-Uapriori算法得到的加权频繁项集称为HEWIs(high expected weighted itemsets);文中提出的TK-FIM算法同样为适用于不确定数据集的加权频繁项集挖掘算法,运行TK-FIM算法得到的加权频繁项集称为WFIs(weighted frequent itemsets)。在后续分析中,将EFIs、HEWIs和WFIs统一称为频繁模式。对于Uapriori算法采用的最小期望支持度阈值δ,可以看作最小期望加权支持度阈值ε的特例(所有项目权重值均为1),因此在后续分析中统称为最小期望加权支持度阈值ε。
5.2 时间效率分析
在第一组实验中,对TK-FIM算法的时间效率进行了分析。分别在retail数据集和T10I4D100K数据集上,分析了Uapriori算法、HEWI-Uapriori算法及TK-FIM算法运行时间随最小期望加权支持度的变化情况,如图1、图2所示。

图1 retail数据集算法运行时间对比
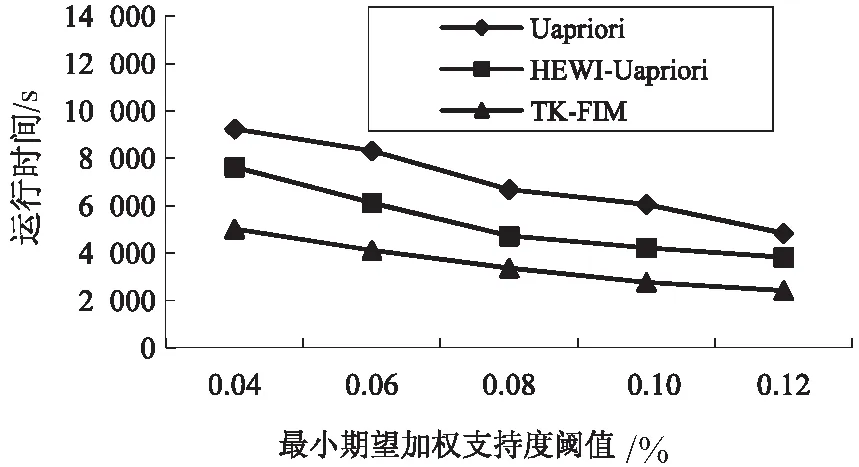
图2 T10I4D100K数据集算法运行时间对比
可以看出,三种算法的运行时间均随最小期望加权支持度的增大而减小,这是由于随着最小期望加权支持度的增大,生成的频繁项集和加权频繁项集数量逐渐减少,因此在算法运行过程中需要被验证的候选频繁项集数量也逐渐减少,算法的运行时间自然逐渐减小。
此外,由这两图还可以看出,在特定的最小期望加权支持度下,TK-FIM算法的运行时间小于HEWI-Uapriori算法的运行时间,而HEWI-Uapriori算法的运行时间小于Uapriori算法的运行时间。这是由于Uapriori算法中没有考虑项目的权重值,所以在相同的最小期望加权支持度下,Uapriori算法生成的候选频繁项集数量远大于TK-FIM算法生成的加权频繁项集数量。HEWI-Uapriori算法虽然也采用了向下闭包特性对候选频繁项集的数量进行压缩,但是该算法在得到HUBEWIs(high upper-bound expected weighted itemsets)后,还需要二次扫描数据集以得到HEWIs。对于HEWI-Uapriori算法与Uapriori算法的时间效率比较,需要视是否考虑项目的权重值和二次扫描数据集两种因素,哪个因素起主导作用决定。对于retail数据集和T10I4D100K数据集来说,是否考虑项目的权重值对于算法时间效率的影响较大,因此HEWI-Uapriori算法的时间效率优于Uapriori算法。
5.3 频繁模式数量分析
在第二组实验中,分析了Uapriori算法、HEWI-Uapriori算法及TK-FIM算法所生成频繁模式的数量情况。
图3和图4分别描述了retail数据集和T10I4 D100K数据集上,三种算法所生成的频繁项集数量随最小期望支持度阈值的变化情况。
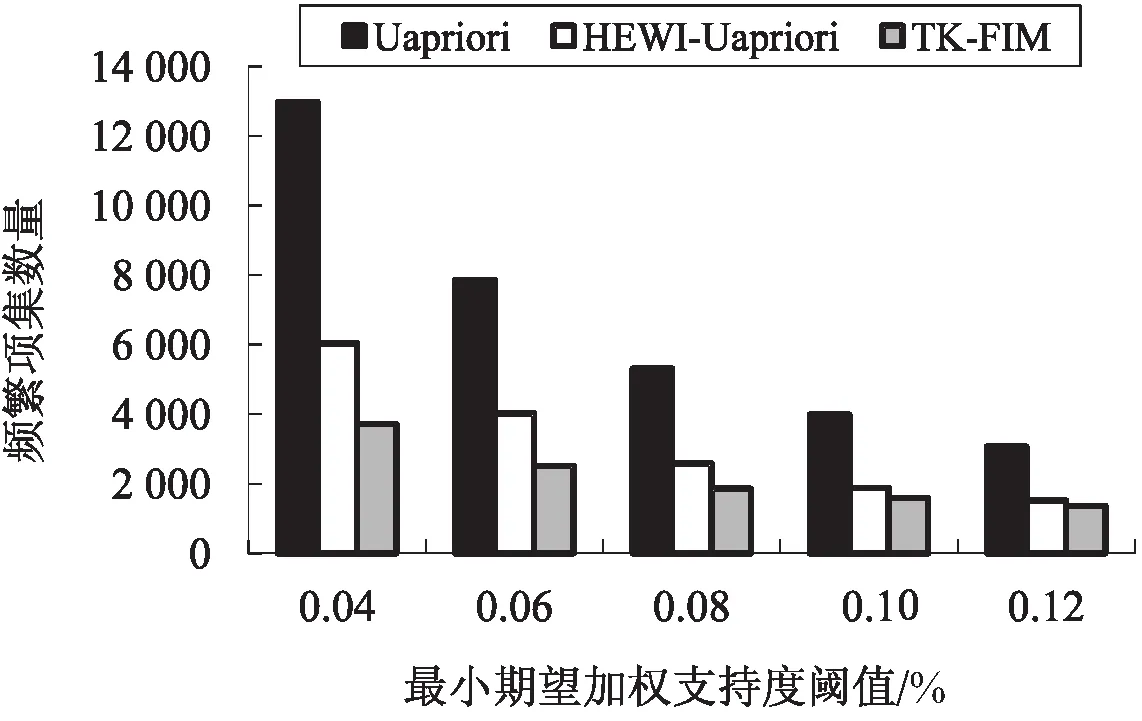
图3 retail数据集算法生成频繁模式数量对比
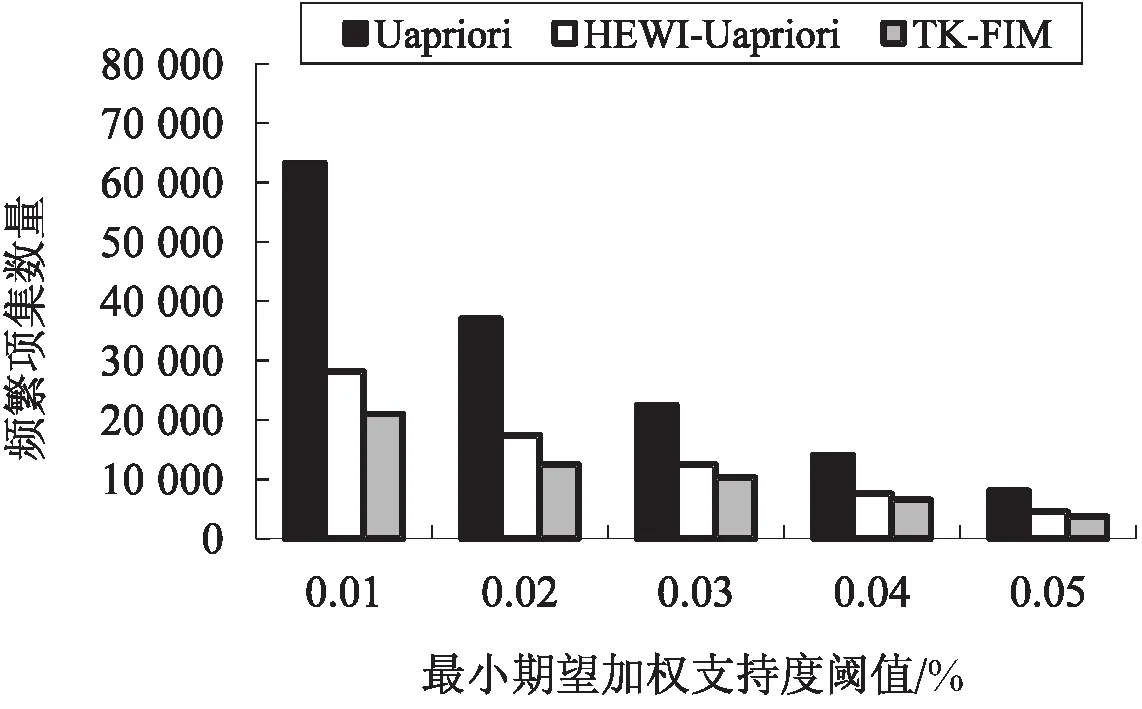
图4 T10I4D100K数据集算法生成 频繁模式数量对比
由图3和图4可以看出,无论是在retail数据集还是在T10I4D100K数据集上,随着最小期望加权支持度阈值的增大,三种算法所生成频繁模式的数量均呈现出逐渐减少的趋势。当最小期望加权支持度相同时,TK-FIM算法生成的频繁模式(WFIs)数量少于HEWI-Uapriori算法生成的频繁模式(HEWIs)数量,而HEWI-Uapriori算法生成的频繁模式数量又远少于Uapriori算法生成的频繁模式(EFIs)数量。WFIs数量小于HEWIs数量,是由于在HEWI-Uapriori算法中采用项集的概率加权上限值作为项集的期望加权支持度,这对项集的期望加权支持度进行了放大,显然使得更多的项集被当作加权频繁项集挖掘出来。HEWIs数量少于EFIs数量,这是因为Uapriori算法并未引入权重值,或者说所有项目的权重值均为1,所以会生成更多的频繁项集。
6 结束语
面向不确定数据的加权频繁项集挖掘,可以兼顾项目在事务中的存在概率和项目本身的重要性,有利于发现对用户具有重要价值和意义的频繁项集。为了提高面向不确定数据加权频繁项集挖掘算法的时间效率,提出了TK-FIM算法,该算法缩小了加权频繁项集的搜索空间,提高了算法的搜索效率。TK-FIM算法虽然在一定程度上提高了加权频繁项集的挖掘效率,但是仍然需要多次扫描数据库,对候选加权频繁项集进行验证,如何将TK-FIM算法与树存储结构相结合,避免频繁扫描数据库,进一步提高算法的时间效率,是下一步工作的研究重点。
