基于容器技术的天文应用软件自动部署方法*
2019-07-16杨秋萍石聪明
姚 坤,戴 伟,杨秋萍,梅 盈,石聪明,王 锋,
(1. 昆明理工大学云南省计算机技术应用重点实验室,云南 昆明 650500;2. 中国科学院云南天文台,云南 昆明 650011;3. 广州大学天体物理中心,广东 广州 510006)
平方千米阵列(The Square Kilometre Array, SKA)是目前待建的全世界最大口径天文射电望远镜,其中科学数据处理器(Science Data Processor, SDP)是重要的工作包之一。为了解决超大规模数据处理中面临的问题,近几年科学家在多个领域开展了一系列研究,包括硬件加速器、计算框架[1]、系统框架[2]等,取得了一系列的成果[3]。
在诸多平台技术选型中,云计算以节省成本、资源动态整合、动态可扩展、简化管理维护和灾难恢复等特性成为平方千米阵列天文数据处理的一种选择。与一般的基于互联网的应用部署不同,天文软件一般在部署运行时需要非常多的第三方库支持,运行时也有诸多参数以满足不同的要求。天文领域对容器技术的使用还停留在天文应用软件的封装层面,特别是在天文应用软件有专人管理的情况下,用户面临等待系统管理员部署特定软件的交付延迟问题[4]。如何在云环境下快速部署,大幅度降低使用成本和提高整体系统的可用性迫切需要进一步实验与研究。同时,如何使用Docker[5]配合OpenStack[6],Mesos和Kubernates等容器编排软件对复杂的天文应用软件进行封装,从而加快部署速度[7]成为当前天文应用软件的热点。
子空间交替泛期望最大化校准算法(Space Alternating Generalized Expectation Maximization Calibration, SAGECaL)[8]是一种执行速度快、内存效率高的射电干涉校准程序。它支持点源、高斯和时间序列等多种模型。SAGECal支持通用天文学软件应用包(Common Astronomy Software Application, CASA)的测量数据集(Measurement Set, MS)数据,在分布式应用中实现了交替方向乘子法(Alternating Direction Method of Multipliers, ADMM)参数的自适应更新[9]。SAGECaL使用期望最大化(Expectation-Maximization, EM)算法获得对观测仪器和天空模型的最大似然估计参数技术。普通的期望最大化算法应用非线性叠加信号的参数估计,SAGECaL采用一种被称为子空间交替泛期望最大化算法,它与普通期望最大化算法相比提高了收敛速度,与最小二乘估计法相比减少了计算复杂度,与剥离校准方法相比提高了校准质量。为了应对新一代射电干涉望远镜的海量数据计算需求,SAGECaL支持在频率上分布式并行校准,代码实现时可以支持单中央处理器、硬件图形处理器或消息传递接口(Message-Passing-Interface, MPI)并行计算等多种部署环境。
在平方千米阵列科学数据处理器的方案设计阶段,为给出较为可信的计算资源需求分析以及能耗设计,项目组和国外团队在合作中,拟通过在不同环境下SAGECal的部署与实际运行,给出不同配置、不同节点数、不同参数和输出精度情况下的系统开销分析结果,根据能源与计算开销最终给出数据处理的较优设计。显然,采用传统的手工安装与环境配置的方法远远不能满足工作开展的要求。本文在云环境下快速部署SAGECal软件开展了深入研究,获得了较好的解决方法,有效推动了科学数据处理器相关工作的开展。
1 基于容器技术的自动部署
1.1 基本需求分析
为了有效地给出测试数据,重点研究了如何快速部署一个基于SAGECaL/MPI的分布式集群(以下简称集群),部署过程中的关键点:
• 根据节点情况编辑集群列表
• 设置集群节点处于同一网段
• 配置网络文件系统(Network File System, NFS)
• 配置各节点安全外壳协议(Secure Shell, SSH)免秘钥登录
• 配置MPI集群环境
• 各节点的CASACORE,SAGECaL和OpenMPI使用同一版本编译
在部署和使用过程中还面临以下问题:(1)由于用户硬件环境和使用偏好的差异,用户所选Linux操作系统发行版本呈现多样化,SAGECaL的编译和部署需要专有设置;(2)SAGECaL的编译需要人工解决组件依赖关系,特别是SAGECaL-MPI和SAGECaL-GPU的编译,还需根据实际情况人工编辑配置文件才能编译成功。这对非专业人员来说,极大地增加了部署的难度。
针对上述关键点,拟通过一套配置脚本自动配置部署过程中的每一个环节。在实际部署和使用过程中面临的问题可以通过Docker对SAGECaL进行封装解决,配合使用交互式友好的用户接口,进一步降低使用难度。
1.2 部署的整体思路
集群的自动部署通过Docker构造SAGECal镜像(以下简称镜像),并通过部署服务启动镜像生成多个SAGECaL容器(以下简称容器),然后各容器通过覆盖网络(Overlay Network)进行跨容器通讯实现自动配置。其中,构造镜像时不仅封装了SAGECal软件,还封装了自动部署的配置脚本用以启动节点时根据节点角色的不同产生不同的配置行为。Docker Swarm(以下简称Swarm)是Docker自带的集群管理工具,主要作用是在若干台主机上建立容器云并通过统一入口管理容器云上的各种资源[10]。
如图1,用户首先对可用机器进行初始化,包括创建集群管理的容器云、配置网络文件系统和创建私有镜像仓库。构建服务和销毁服务分别用于构建镜像和集群销毁。部署服务会调用构建服务和销毁服务并实现服务编排、弹性伸缩、集群节点发现与维护和用户接口等功能。在集群运算结束后用户可以从网络文件系统指定目录获取处理结果。
1.3 镜像的构建与组成
如图2,镜像是基于Linux主流发行版基础镜像构建的。本文选用Debian8.6基础镜像通过Dockerfile方式构建镜像,镜像中的主要软件包括SSH, CASACORE, Glib, OpenBLAS, Gcc, Make, OpenMPI和SAGECal。
作为通用镜像,为了让节点容器在启动后能够根据自身在集群中的不同角色自动进行不同的操作,在制作镜像时需要将定义了不同操作的脚本以及自动维护集群列表的相关脚本一同打包进镜像[11]。同样,为了实现集群内部节点间及裸机操作系统与集群主节点间的SSH免秘钥登录,裸机操作系统的公匙也需写入镜像并配置SSH登录免提示等相关配置工作。
1.4 自动部署
1.4.1 初始化
首先,对可用物理机进行初始化。提前选取一台物理机作为物理机机群的主节点,其余物理机作为物理机机群的子节点。通过人工配置的方式在各台物理机操作系统中配置SSH免秘钥登录和设置开机启动的自动化脚本,使得各台物理机开机后主动向物理机机群的主节点发起并保持SSH连接,从而让主节点感知到其余物理机的存在并一直监控和维护物理机机群列表的变化。
其次,配置网络文件系统用于容器间共享数据。本文中所有机器都将各自的网络文件系统共享目录挂载进容器,这样用户就可以通过裸机操作系统直接和容器进行数据交换。
然后,创建私有镜像仓库并配置负载均衡服务用于镜像分发。如图1,基于对镜像分发容错的考虑,私有镜像仓库采用横向扩展的形式分布在多台物理机上,构建好镜像后将同时推送镜像至各私有镜像仓库。通过配置Nginx负载均衡服务以提供统一的镜像拉取地址供自动部署服务从私有镜像仓库下载所需镜像并启动容器进入工作状态。
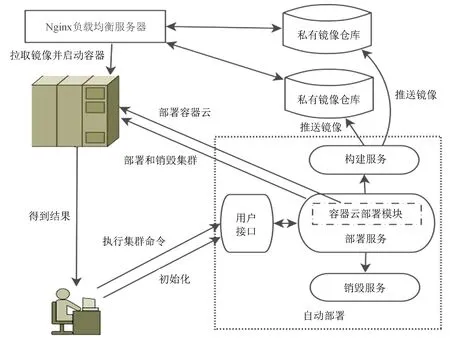
图1 自动部署流程图
Fig.1 Diagram of automatic deployment
最后,自动部署容器云。容器云部署模块封装了直接在物理机机群主节点执行命令的脚本、按照IP列表批量执行命令的脚本和物理机机群列表对比监控等功能的脚本。如图1和图3,通过用户接口调用容器云部署模块对容器云进行自动部署。具体部署流程如下:
(1)容器云部署模块通过封装集群主节点初始化命令对集群主节点进行初始化并将获得的加入命令写入一个临时文件以备后期调用。

图2 自动部署脚本封装示意图
Fig.2 Diagram of automatic deployment script encapsulation
(2)容器云部署模块从物理机机群列表第2行开始依次读取IP地址并配合批量执行命令的脚本对目标物理机远程执行第(1)步中获得的加入集群的命令。
(3)物理机机群列表对比监控功能持续通过封装了集群节点查看命令的功能模块维护集群IP列表,同时不断地将集群IP列表与物理机机群列表进行比对。当两个列表的行数一致、内容一致和集群节点的状态为活动态时,认为所有物理机加入了集群,然后启动初始界面等待用户输入集群自动部署命令。
(4)当有新的物理机开机时,物理机机群列表会自动更新,同时触发容器云部署模块对新加入的物理机执行第(1)步中获得的加入命令,使其自动加入集群。
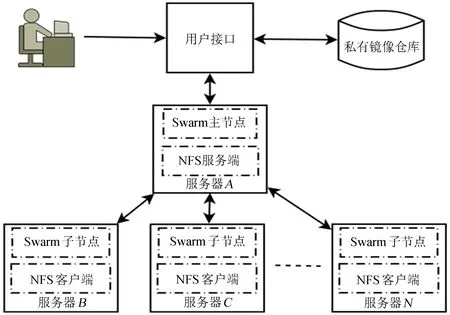
图3 容器云创建示意图
Fig.3 Block diagram of container cloud creation
通过物理机机群列表对比监控功能的持续监控,不但实现了物理机数量动态变化的容器云自动维护,还对容器云的自动部署具备一定的容错功能。后期的集群自动部署都在容器云上实现。
1.4.2 创建Overlay网络和集群节点
在启动集群节点前,需要准备好Overlay网络以供节点容器在私有逻辑网上进行跨主机通讯。在自动部署过程中创建Overlay网络通过封装如下命令实现网络配置和指定网络名称。

自动部署还封装了集群服务声明性模型的相关命令来定义服务的期望状态,并依赖Docker维持该状态和编排相关的服务。本文集群的节点分别由主服务编排主节点、工作服务编排子节点。具体命令如下:

按照角色的不同,集群的节点起初都是每组服务启动一个容器,但子节点数会按照工作服务的配置进行弹性扩容。两组服务都绑定了同一个Overlay网络和一致的NFS目录。mpi_bootstrap文件定义了一组操作命令,它会根据role参数决定这个节点容器在启动后执行何种操作。其中,主节点还传递了host_number参数作为集群规模的预设值。集群服务虽然可以设置容器数量,但运行集群还需要通过在容器内自动维护集群列表并确保达到集群规模预设值后才执行用户输入的集群计算命令。
1.4.3 集群节点的发现与维护
集群节点的发现采用节点主动暴露IP的方式实现。主节点最先启动,启动后开启对地址解析协议(Address Resolution Protocol, ARP)缓存的持续监控。各子节点启动后主动向主节点发起SSH连接并访问主节点dev目录下的null文件。通过持续保持与null文件的连接,主节点便通过地址解析协议缓存感知子节点的IP变化以达到集群列表动态维护。SSH连接命令如下:

由于预设了集群规模,所以还需要一个变量作为标识来通知集群维护模块创建的集群是否达到既定规模。本文设置了CLUSTER_GET_READY变量并默认0为集群未准备就绪,1为集群准备完毕。主节点通过不断监控集群列表的变化情况发现集群达到既定规模时,变量值被修改为1并告知主节点停止对集群列表的监控,然后启动图4所示初始界面等待用户输入集群计算命令。
1.4.4 用户接口
集群的自动部署由图4中例2所示命令启动。用户根据实际需要设置集群规模,待自动部署完成后用户界面会停留在初始界面并等待用户输入集群计算命令或其他命令。通过提供交互友好的用户接口,用户只需提供较少的必要参数即可完成集群计算、终止并删除集群和进入集群节点查看运行情况等多种操作。
1.4.5 容错处理
集群自动部署过程中会出现硬件资源不足、主节点没有启动或崩溃和网络中断等因素导致部署过程出错。如果集群长时间没有准备就绪,自动部署模块会进行回退处理释放资源。如果回退失败,可以手工运行图4中例5所示命令强制销毁已创建的服务并将所占资源全部释放。经过检查资源申请参数和网络可达性后可再次执行集群自动部署命令进行自动部署。
总的来说,对于自动部署的全过程,如果各个部分的容错机制失效,采取的默认策略是回退并释放资源。
2 实验设计
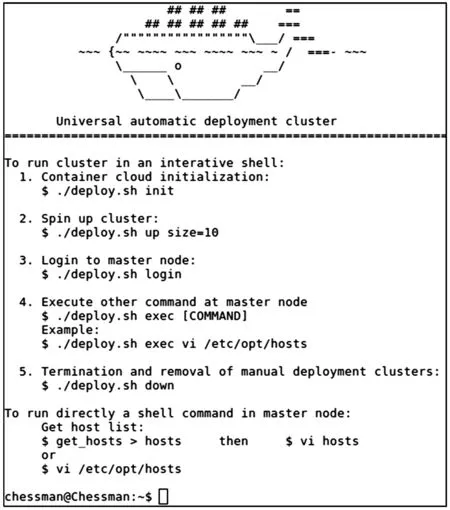
图4 初始界面
Fig.4 Initial interface
通过实验,测试并比较在不同服务器数量和不同集群规模情况下集群部署和集群计算的时效性以及选用分布式部署进行集群计算的合理性。
2.1 实验环境
实验所用服务器型号均为曙光天阔620R,使用Debian9.4 stable作为物理机操作系统并安装Docker18.03.1-ce和NFS组件。基础服务节点安装了Docker,NFS服务端和部署Docker私有镜像仓库,其他节点安装了Docker和NFS客户端。基于Debian8.6基础镜像采用Dockerfile构建镜像的方式进行构建。
本次实验使用十二台服务器,其中基础服务节点作为主节点,其余机器作为子节点。服务器之间使用千兆以太网相互连接且在同一个网段内可以相互连通,集群运行在私有Overlay网络中。为了尽可能地还原真实的部署情形,每次进行实验之前都会清除服务器上所有镜像,以确保每次自动部署都从头执行。为了防止集群计算的时间被缓存影响,每次实验完成后均对所有服务器进行重启操作,确保清空所有计算过程中产生的缓存内容。实验所用MS数据来源于SAGECaL自带的测试数据。
2.2 时效性和合理性
实验在容器云环境下通过在不同数量服务器上部署不同规模的集群观察集群部署和集群计算的时间变化情况。每组部署共进行5次并记录完成时间,取平均数作为最终部署完成时间。集群计算命令如下:

为了降低计算量,各组实验只计算一个MS数据,交替方向乘子法迭代次数设置为20次。进程数依据容器数设定,每一个节点就是一个容器,一个进程对应一个容器。命令执行时间存放在/root/project/ResultOutput/目录下的TimeProcessOutput文件中。集群的缓存文件存放在/tmp文件夹下。待处理的MS数据存放在/root/data/MS/文件夹下。集群计算选择使用3c196模式,最终计算结果存放在/root/project/ResultOutput/目录下的sm.ms.solutions文件中。
曙光天阔620R服务器配备两颗4核中央处理器和4 G内存,总共有12台可用服务器。每一个集群节点在计算时启动一个进程,也就是在96个集群节点以内的规模,一个进程对应一个中央处理器内核。集群计算时间指集群部署好以后从启动命令开始到得到计算结果的时间。整体部署时间指从私有镜像仓库下载镜像到集群部署完毕的时间。集群创建时间指服务器在已经下载好镜像的情况下部署一定规模的集群花费的时间。

表1 实验结果统计表Table 1 Statistical table of experimental results
从表1可以看出,集群的创建时间很短,加上SAGECaL镜像的传输时间,1 000个节点的集群在一分钟内部署完毕是传统人工部署不能比拟的。随着服务器数量的增加,计算能力得以提升,集群计算时间逐渐缩短。但随着计算进程数超过可用中央处理器内核数后,由于存在大量进程切换,计算时间有小幅增长。
如图5,整个部署过程中镜像的网络传输时间所占比例仍然很大,在镜像分发过程中集群的网络传输时间损耗依旧明显。但从图6可以看出,在1 000个节点的规模下,整体自动部署时间与集群计算时间相比,整体自动部署时间所占比例仅为10%。由此可知,部署过程的时间损耗并不是主要因素,性能瓶颈仍然在硬件的计算能力上。通过分布式整合额外的计算资源并通过自动部署方法提高部署效率,在容器云下部署SAGECaL这类计算密集型的应用是合理的。
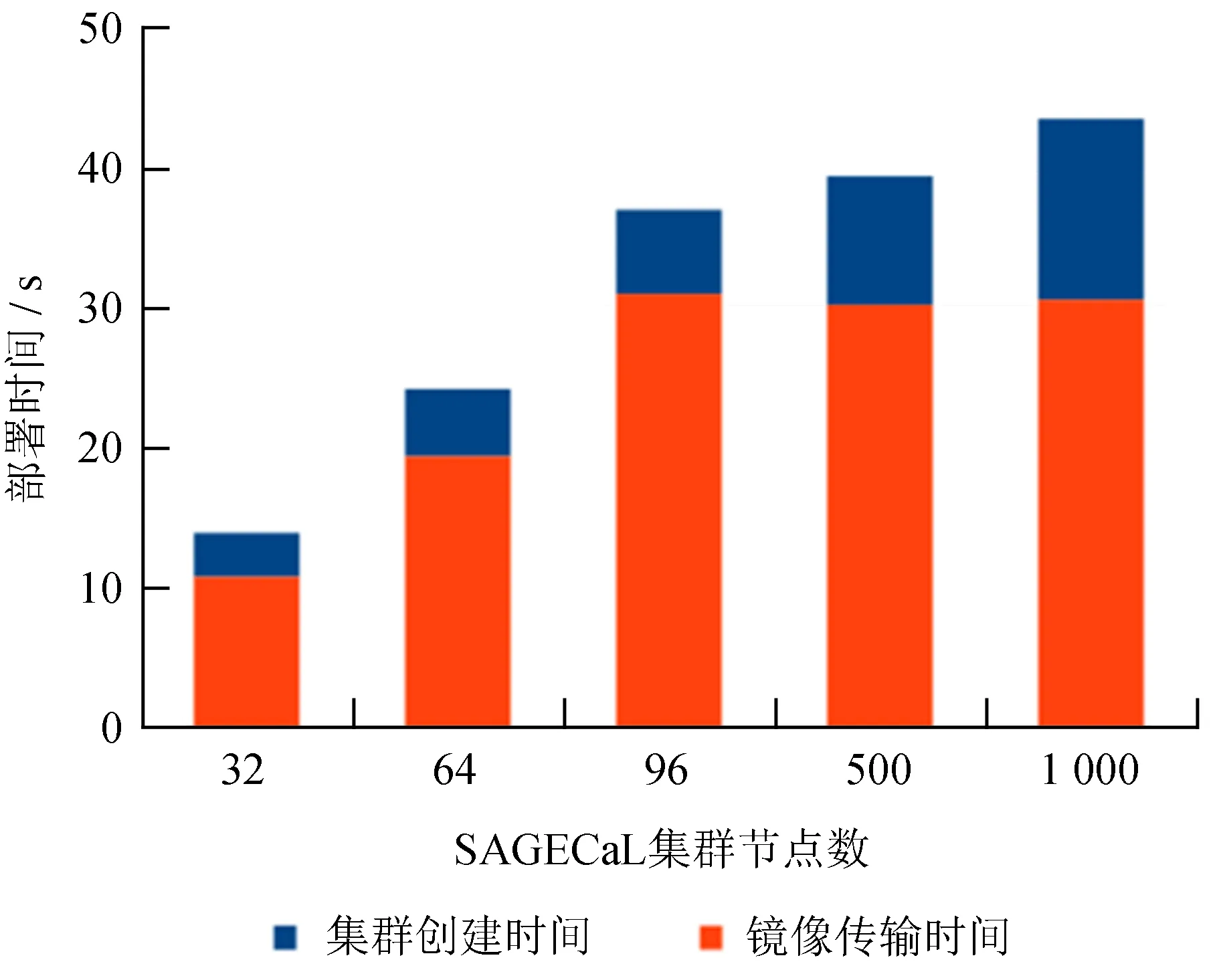
图5 集群部署时间
Fig.5 Cluster delployment time

图6 部署时间与计算时间
Fig.6 Deployment time & calculation time
3 结论与展望
云环境下使用基于容器技术的自动部署方法,在提高部署效率的同时便捷地整合了更多的计算资源,使得天文应用软件一次编译后可以方便地运行在不同的硬件资源上。实验结果表明,本文给出的自动部署方法极大地提高了集群的部署效率,方便用户把主要精力集中在天文数据处理层面。
为了应对海量数据处理的需求,在当前并行化发展的趋势下,部分天文应用软件已经对基于消息传递接口分布式并行计算的并行方式提供了支持。基于容器技术的自动部署方法可以对所有基于消息传递接口分布式并行计算的天文应用软件提供良好的支持,是一种通用的自动部署方法。
当下的消息传递接口集群自动部署方法存在主节点一旦没有最先启动或是崩溃后整个部署过程将完全失败的问题。部署过程中虽然可以使用资源调度算法分配节点所在位置,但这样的资源调度方式仅适用于平等地位的节点调度,对于消息传递接口集群这样有主次之分的节点调度还需要进一步完善调度机制。下一步尝试使用Zookeeper或是P2P算法结合对物理机的实时性能动态采集与对比,探寻一种同时具备节点容错和自我演化功能的自动部署方法,让各节点在初始状态下进行平等地位的部署,然后根据自身所在的环境性能情况和部署状况自我演化出合适的角色并进行动态自动部署。
致谢:感谢国家天文台-阿里云天文大数据联合研究中心对本文工作的支持。
