被遗忘权的制度缺失、发展困境与中国构建路径
2019-07-11刘学涛张翱鹏
刘学涛 张翱鹏

摘 要:数据时代面临的个人信息受到侵害、个人隐私泄露、算法歧视等一系列重大问题,应将以保护信息主体权利为目的的被遗忘权确立下来。欧美被遗忘权在隐私与自由之间存在的冲突背后所体现的是被遗忘权对于各国需求的重要性,我国现有法律制度中规定的删除权与欧盟所确立的被遗忘权是不能等同的。现行被遗忘权面临着调整对象的设定缺陷、权利内容的设定偏差、责任主体的设定不足三方面的发展困境。学者热议与实践需求在一定程度上表明我国应当引入被遗忘权,并应从调整对象的优化构建、权利内容的改造构建、责任承担的明确构建搭建起中国的路径选择,以解决网络信息社会的发展带给我们的新挑战。
关键词:被遗忘权;删除权;情景脉络完整性;删除算法
中图分类号:D923 文献标识码:A
文章编号:1673-8268(2019)03-0045-12
“被遗忘权”也被称为“删除的权利”(the right to erasure),有学者将“被遗忘权”定义为:“数据主体可以在数据控制者没有合法理由掌握信息的情况下,要求其永久删除该主体的个人数据的权利。”[1]有史以来,对我们人类而言,遗忘一直是常态,记忆才是例外。然而,由于数字技术与全球网络的发展,这种平衡已经被改变。在此种情形下,作为一项新兴权利的被遗忘权应运而生,成为保障个人信息安全之利器而受到人们的关注[2]。在网络技术的帮助下,遗忘已经变为例外,而记忆却成了常态。完善的数字记忆在带给人们极大便利的同时,也造成了新的困扰。过去,人们犯错不用担心未来会受此羁绊,因为尴尬的信息通常只存在于特定的社区并会随着时间的流逝而被遗忘。但现在,互联网记住了你的一切,我们的过去正像刺青一样刻在我们的“数字皮肤”上,遗忘成为奢侈品,一个“永久记忆”的时代已经到来。完善的数字化记忆,可能会令人失去一项重要的能力——坚定地生活在当下的能力[3]。大数据时代,现代信息技术构建的庞大数据库储藏着海量信息[4],遗忘作为人类与生俱来的能力,在互联网以及廉价存储器的作用下成为过去,传播和取得不良信息包括传播和取得未经数据主体同意的隐私资料更为方便,人们私生活的不安宁因素随之增加[5]。本文以被遗忘权的价值争议为逻辑起点,结合我国关于删除权的规定,审视被遗忘权的发展困境,试图将被遗忘权引入中国并为在引入之后如何具体应对提供构建路径。
一、欧美被遗忘权的价值基础:个人尊严和自由
自2012年欧盟提出被遗忘权以来,各方争议不断。这种分歧在欧盟与美国之间尤为明显。美国与欧盟在被遗忘权问题上的巨大分歧,背后体现的是两者对待个人隐私保护的差异。总的来说,欧盟国家更注重个人隐私保护,认为隐私权关系人格尊严,是一项“基本权利”,政府应给予高度重视;而美国通常认为隐私是一项“基本价值”,相较于隐私,他们更倾向于保护言论自由。
(一)欧盟的价值基础:个人尊严
欧盟明确将被遗忘权纳入“新草案”,并在积极寻求草案的通过。“谷歌西班牙公司案”证实了欧盟的这一立场,雷丁女士更是称该判决是“欧洲个人数据保护的一次显著胜利”,欧盟成员国也多持肯定态度。早在欧盟《通用数据保护法则》出台前,一些成员国就已经在尝试确立被遗忘权。例如,在法国,2010年10月13日,包括搜索引擎在内的部分互联网企业在国务秘书的召集下签署了一项关于被遗忘权方面的宣言。而欧盟民众对被遗忘权更是热情高涨。据民调显示,欧盟有75%的民众希望享有被遗忘权,以便能按照自己的意愿删除网络个人信息。“谷歌西班牙公司案”后,谷歌出台了在线申请程序,欧盟每天都有上千人申请行使被遗忘权。
欧洲对于个人信息的保护核心源于对个人尊严权利的保护。隐私保护的核心是个人的肖像权、姓名权和名誉权,这几项权利互相联系,其目的是为了控制个人的公众形象,使自己在公众面前免于不当暴露和公开带来的尴尬。保护隐私是保护尊严和荣誉的内容之一,避免隐私泄露导致的尊严被伤害和荣誉受损才是有关欧洲法律的目的\[6\]。欧洲的尊严文明其实就是隐私文明。欧洲法律学者将隐私作为对一个人肖像、姓名和名声的控制以及对个人信息的公开披露等相关的权利时,实际上是在说社会大众对于这些权利的敏感性。Robert Post认为,隐私保护的是一种尊严的标准,这种标准表现为礼仪规范,当缺乏这种规范时社会将无法形成共同的意识。欧洲的隐私法从名誉法(the law of insult)发展而来。名誉法涉及的惩罚对象是不尊重的表现,例如表达不尊重的文字手势等。其所存在的国度,名誉法被认为是关于保护个人荣誉或尊严的法律\[7\]。隐私受损而造成的尊严或荣誉的损失是由名誉法保护的,名誉法并不要求法律上可认知的侮辱已经传播到任何第三方。无论是否有任何第三方目睹了该事件,都可以认定为以不尊重或輕蔑的态度对人的尊严进行攻击的行为。
(二)美国的价值基础:自由
美国的个人信息保护涵盖于隐私保护中,其来源于对自由的追求,彰显了个人信息自由的价值。在美国,尽管被遗忘权一直受到宪法第四修正案的反驳,加州仍然通过了《儿童在线隐私保护法案》,该法案规定了儿童的被遗忘权,指出儿童有权擦除其在线记录。美国的被遗忘权来源于其追求自由的理念,美国隐私权的发展历程便是追求自由的过程。比如:1965年,在格里斯沃尔德诉康涅狄格州案中,最高法院通过利用第一、第三、第四、第五和第九修正案创造新的隐私权;在Hanlon诉Berger案中,法院认为政府侵犯了公民的隐私自由。
Eric Posner指出,美国法律试图在第一修正案和隐私权之间维持平衡。例如,在美国的信用报告中,未支付的抵押贷款,即使此类信息为真,十年之后这类信息也会消失[8]。此外,各州对于某些类型的犯罪记录也会从公共记录中删除,即使这些记录并不存在任何错误。Eric Posner因此认为,虽然美国并没有明确地承认被遗忘权,但这种法律权利其实深藏于美国的历史传统中。美国公众舆论也支持被遗忘权。Pew 研究中心的一项研究显示,68%的美国互联网用户“认为现行法律在保护人们的在线隐私方面不够好”。此外,一项软件咨询调查显示,500名美国成年人中61%的人都赞成被遗忘权。
虽然欧美被遗忘权的价值基础不同,但都认为被遗忘权是大数据时代必备的权利。不论从理论基础还是现实需要,都指明了被遗忘权的重要性。然而,我国并没有建立被遗忘权,而且类似于被遗忘权的删除权立法只知其形而未得其神。
二、我国被遗忘权的制度分析:删除权≠被遗忘权
我国现有的相关法律已经规定了“删除权”。2005年6月,《中华人民共和国个人信息保护法示范法草案学者建议稿》最早将“删除”上升为一种权利,规定在个人信息被非法储存以及当信息处理主体执行职责已无知悉该个人信息的必要时,该个人信息应当被删除。2011年1月,工信部就个人信息保护颁发了《信息安全技术公共及商用服务信息系统个人信息保护指南》(以下简称《指南》),该《指南》第5.5.1条《信息安全技术公共及商用服务信息系统个人信息保护指南》第5.5.1条:个人信息主体有正当理由要求删除其个人信息时,及时删除个人信息。删除个人信息可能会影响执法机构调查取证时,采取适当的存储和屏蔽措施。对有关个人信息删除权的规定,是目前我国相关法律、法规、规章中最系统、最全面的,也最接近欧盟被遗忘权的规定。但是,《指南》中规定的删除权与欧盟所确立的被遗忘权并不相同。陈昶屹法官认为,其一,《指南》是从个人信息保护法的领域这个角度规定的,而欧盟所确立的被遗忘权是从民事权利的角度提出的。由于《指南》是工信部颁发的一种指南性的规定,属于行政指导的范畴,不具有强制力,所以这其中规定的删除权严格来说很难被认为是一种法定意义上的民事权利或者在行政法上行政相对人个人享有的一项权利。而被遗忘权更多地是一种私权利,如果归到中国权利体系里面应该属于民事权利。其二,删除权从主体上说有这项权利,但并没有从民事权利或私人主体权利的角度来说。西方有个人信息保护机构,还有对应的投诉机构和管理机构。工信部从信息产业的角度代行了类似的这种权利,但并不是专门保护个人信息、接受个人信息投诉的机构。被遗忘权这一权利最后行使的方式也是信息被抹掉,从这一意义上来说,中国的删除权和欧盟的被遗忘权的规定很相似。但截止到现在,《指南》中规定的删除权并没有成为法定权利和上升到一种被遗忘的权利,这个规定还只是一个指令或者指导。在封存或消除罪犯犯罪记录的相关规定方面,我国2012年修改的《中华人民共和国刑事诉讼法》专章规定了“未成年人犯罪案件诉讼程序”,其中第275条作出了相关规定《中华人民共和国刑事诉讼法》第275条:犯罪的时候不满十八周岁,被判处五年以下有期徒刑,应当对相关犯罪记录予以封存。。最高人民法院《关于审理利用信息网络侵害人身权益民事纠纷案件适用法律若干问题的规定》第12条也就犯罪记录能否适用被遗忘权予以删除作了区分:当犯罪记录的公开者是网络用户或网络服务提供者等国家机关之外的主体时,能够行使被遗忘权对该犯罪记录进行删除;当犯罪记录的公开者是国家机关时,该犯罪记录属于适用被遗忘权的例外。2012年12月28日通过的《全国人大常委会关于加强网络信息保护的决定》第8条也做出了规定《全国人大常委会关于加强网络信息保护的决定》第8条:个人发现网络运营者违反法律、行政法规的规定或者双方的约定收集、使用其个人信息的,有权要求网络运营者删除其个人信息;发现网络运营者收集、存储的其个人信息有错误的,有权要求网络运营者予以更正。网络运营者应当采取措施予以删除或者更正。。我国《中华人民共和国侵权责任法》(以下简称《侵权责任法》)第36条有关网络侵权责任的规定,首次明确了针对网络用户利用网络服务实施的侵权行为,被侵权人有权通知网络服务提供者采取删除、屏蔽、断开链接等必要措施,即赋予了被侵权人对网络上针对自身的侵权信息予以删除的权利。
但是,我们发现,以上关于“删除权”的规定,无论是对未成年人犯罪记录的封存,还是基于《侵权责任法》的通知删除义务,都是基于一个前提:存在违法行为或者侵权行为。然而,被遗忘权并不以存在违法行为为基础,即便是合法存在于网络的信息,没有任何人利用该数据做出对数据主体不利的举动,数据主体仅仅是由于数据的存在问题就可以通过被遗忘权来主张权利。这也是被遗忘权与我国规定的删除权最大的不同。从上文可以看出,我国现有法律中规定的删除权虽然从形式上、内容上和被遗忘权相似、接近,但由于中国的立法环境、立法条件、适用情况和欧洲都有完全不一样的体系和保护方式,所以很难说上述法律文件中规定的删除权与欧盟所确立的被遗忘权是一致的,具体分析如下。
一方面,从个人信息治理手段的角度看,欧盟被遗忘权的规定侧重于源头治理,而我国的规定则属于结果治理。《中华人民共和国网络安全法》第43条《中华人民共和国网络安全法》第43条:个人发现网络运营者违反法律、行政法规的规定或者双方的约定收集、使用其个人信息的,有权要求网络运营者删除其个人信息;发现网络运营者收集、存储的其个人信息有错误的,有权要求网络运营者予以更正。网络运营者应当采取措施予以删除或者更正。只规定了个人对于个人信息收集和使用违法、违规以及违约状况下请求删除的权利,与欧盟《通用数据保护法则》相比缺乏“个人信息過时不必要、撤回同意以及拒绝信息控制者收集三种情况”。这使得我国立法层面丧失了事前的个人信息侵害救济,只规定事后的惩罚和处理,对个人信息的保护未免过于迟钝与滞后。
另一方面,《侵权责任法》第36条的规定也并不能起到替代被遗忘权的作用,二者存在巨大差异,具体对比如表1所示。
表1中,从权利主体的角度看,前者要求利用“网络”,这也符合我国《侵权责任法》第36条“网络侵权专门条文”的称谓。而被遗忘权不要求其主体利用网络,即便是非网络状态下收集的个人信息也适用被遗忘权的规定。当然,实践中也确实大量存在非云端的个人信息收集、储存和分析等行为,《侵权责任法》要求的网络前提未免会令调整范围更狭窄。
从权利客体的角度看,前者的构成要件要求侵权损害事实的发生,而被遗忘权并不强求符合《侵权责任法》规定的侵权行为构成要件,即便没有损害事实发生,只要符合法律对被遗忘权的规定,个人信息主体即可请求信息控制者删除其个人信息。信息自决的理念体现了个人对大数据时代产生的个人信息问题进行的回应,具有时代特色。传统互联网阶段,个人信息量较少,互联网电商尚不发达,搜索引擎与门户网站对个人信息的处理需求并不是很大,互联网社区相对较少,线下的信息储存和处理行业尚未兴起,这一阶段适用《侵权责任法》第36条尚可。但大数据时代背景下,算法甚至比使用者更了解其自身,要求侵害结果并进行事后救济未免效率过低。
因此,我国的相关立法对个人信息的保护缺乏效率,并不能体现被遗忘权信息自决的特点,也无法回应时代对个人信息保护的需求。对被遗忘权进行更精准的分析与改造引进可能会成为更好的选择。
三、现行被遗忘权的发展困境:规范和实践的审视
(一)调整对象的设定缺陷:个人信息范围的狭隘性
针对个人信息,学理界已存在大量讨论。齐爱民教授认为,个人信息(information relating to individuals)是一切可以识别本人信息的总和。识别是个人信息的实质要素,得以固定和可以处理是个人信息的形式要素[9]。王利明教授也认为,可识别性是界定个人信息的重要标准,其认为个人信息是指与特定个人相关联的、反映个体特征的具有可识别性的符号系统,包括个人身份、工作、家庭、财产、健康等各方面的信息[10]。也有学者认为,对于个人信息的界定不应单纯考虑与个人的关系,同样也需要思考个人信息与社会的关系,将个人信息界定得过于宽泛不利于社会公共利益的实现,因此,其认为个人信息是指那些据此能够直接或者间接推断出特定自然人身份而又与公共利益没有直接关系的私有信息[11]。尽管当前个人信息的具体外延仍然是一个争论不休的问题,但随着关于个人信息本身讨论的不断深入,可识别性逐渐成为判断是否属于个人信息的核心元素。围绕可识别性界定个人信息也逐渐被广泛接受[12]。
被遗忘权的权利客体指个人信息,传统“识别说”定义下的个人信息具有范围狭隘的缺陷。“识别说”指信息能否成为个人信息,要看该信息能否识别信息主体,能够识别则为个人信息,不能则相反。欧盟《通用数据保护法则》、我国《网络安全法》和《个人信息保护法》(草案)均采用“识别说”定义个人信息。然而,技术的发展对“识别说”定义模式的个人信息定义提出了挑战。一些非个人信息在一定条件下可以转变为个人信息,个人信息的类型也突破了传统的规定。实践操作中,争议较多的IP地址、cookies、人群位置、地理位置信息以及个人信息衍生产品等是否构成个人信息无法单靠立法的字面规定所解释,甚至连姓名、电话号码等是否构成个人信息也颇具争议[13]70。即便是“匿名化”的信息也可能被重新识别。信息的这种动态化特征使得依靠“识别”来划分个人信息与非个人信息的静态立法模式呈现疲态。
“识别说”的个人信息定义方法,会使得被遗忘权的保护产生滞后性。信息的利用很大程度上指的是信息的二次利用和后期挖掘。当收集时,该信息无法识别个体,但海量数据的叠加使得当初无法识别个体的信息转换成为可识别个体的信息。此时,再认定其为个人信息,利用被遗忘权进行删除时,该信息已经被非法利用。对被遗忘权的调整对象进行改造便提上了日程。
(二)权利内容的设定偏差:知情同意保护方法的低效
个人信息保护的传统机制建立在“知情同意”架构之上,要求机构在收集用户个人信息前告知用户信息的处理状况,在网络服务的语境中通常表现为发布隐私声明,用户在阅读声明后作出同意的表示,作为对个人信息收集和利用的合法授权[14]。依照前文的分析,作为被遗忘权触发条件的“知情同意”框架弊端突出。按照“知情同意”框架的保护方式,事前信息采集时设定“知情同意”的架构,使得对于信息的收集不知情和不同意均可行使被遗忘权,这都是重复低效的设定。不论是日常生活的经验还是实验数据都证明了这一观点。
日常生活经验表明,数据服务需要数据的提供。允许软件的访问权限,是使用软件的前提。如果用户不同意这一要求,那么软件将无法使用。在这种情况下,消费者对软件获取权限的事实知情,也被迫同意了该访问请求,这使得如何判断用户内心是否真正同意成为难题。如果仅仅按照形式上格式合同的同意,那么人人都可以在接受服务结束后行使被遗忘权。
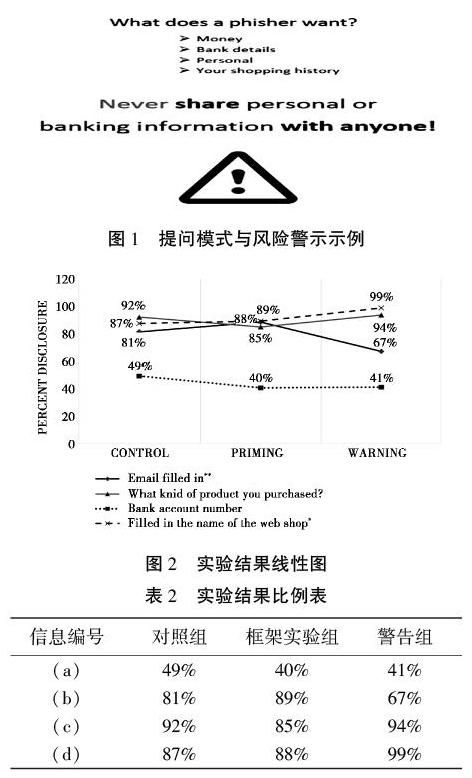
实验数据也表明了“知情同意”在数据收集阶段的功能丧失。2017年,美国学者Junger,Marianne和Lorena Montoya在荷兰的商场进行了实验。实验以商业推广为名对300多名商场顾客进行了分组询问,询问内容包括銀行账号(a)、邮箱地址(b)、购物记录信息(c)和浏览网店的名称(d)。分组包括三组:对照组、框架实验组和警告实验组。对照组指实验者直接询问顾客的如上内容。框架实验组则设置了一些问题引导顾客注意到披露信息可能导致网络钓鱼,然后才询问上述内容。警告实验组则直接采用大的警告标志警示顾客披露信息的风险,然后询问顾客三项内容,问题和警告如图1所示[15]80,结果如图2所示[15]80。
实验结果是三组中消费者被商家获取信息的比例(见表2)。
与对照组相比,除“邮箱账号(b)”之外,各种引导消费者“知情”的方式所能引起消费者谨慎的效果并不明显。意图通过令消费者知情,从而使其作出真实意思表示的方式在大多数情况下并没有明显效果[15]81。
(三)责任主体的设定不足:收集者、控制者和处理者的混淆
数据责任承担者的划分过于机械。《一般数据保护条例》(GDPR)对数据收集者、数据控制者和数据处理者进行了准确划分,貌似严密而不疏漏,实则不然。上述责任者也可能是同一企业在有关个人信息行为的不同阶段扮演了不同的角色。比如,某一企业是个人信息的收集者,也可能后续参与个人信息的处理。数据收集、处理和控制的阶段转变也往往在极短时间内完成。科技的进步会使得有关数据的行为超出收集、处理和控制的范畴,从而跳出法律的规制。因此,精确划分数据责任的承担者,会导致三者对责任的推诿,也为裁判者留下了如何区分责任承担者的难题。
就删除方式而言,“谷歌诉冈萨雷斯被遗忘权案(Google Spain SL, Google Inc. V Agencia Espaola de Protección de Datos (AEPD), Mario Costeja González, C-131/12, 13 May 2014)”在被遗忘权的发展过程中有着如同里程碑一般的重要意义。在该案判决中,最终确立起被遗忘权的概念和内涵,即有关数据主体的“不好的、不相关的、过分的(inadequate, irrelevant or no longer relevant, or excessive)”信息应当从搜索结果中删除,这使得被遗忘权最终成为信息主体的一项民事权利而得到保护。但是该案仅仅确立了数据主体有权请求搜索引擎删除链接。删除方法不仅低效,而且留下了搜索引擎掌握个人数据审查权力的诟病。判例中所表现的删除方法,要经历个人申请、企业审查和删除三个阶段,费时费力。删除方式的改进也应当获得关注。
四、被遗忘权的中国应对:引入及其构建路径
(一)被遗忘权引入中国的考量
有学者说道:互联网的全球化意味着完整的数字化记忆以及“记忆成为常态”所带来的诸多挑战,不仅存在于伦敦和旧金山,在北京和上海也同样令人关注,跨越了地理上的界限,完整的数字化记忆正在挑战着我们所有人。被遗忘权绝不仅仅是欧盟与美国需要讨论的话题。实践中,阿根廷、日本等都在积极应对被遗忘权问题。我国已经进入互联网时代,2019年2月28日,中国互联网络信息中心(CNNIC)发布第43次《中国互联网络发展状况统计报告》,截至2018年12月,我国网民规模达8.29亿,普及率达59.6%,较2017年底提升3.8个百分点,全年新增网民5 653万。在此背景下,数字化永久记忆带来的遗忘难题将不可避免。此外,欧盟将被遗忘权规则适用于所有在欧盟境内经营的自然人和企业,这意味着任何想要进入欧盟市场的企业都需要应对被遗忘权问题。在“谷歌西班牙公司案”后,谷歌、雅虎、微软等美国互联网巨头都在积极出台相关在线申请程序,以便应对欧盟对被遗忘权的规定。我国百度、阿里巴巴、腾讯等互联网巨头要想实现“走出去”战略,进入欧盟等确立被遗忘权的国际市场,必须积极应对。
我国现行法律规定中并不存在被遗忘权,但在信息保护方面有相关的法律基础。有学者认为现有的信息保护法条中,无论是权利主体还是义务主体的界定都显得较为狭隘,从而降低了法律实施的有效性[16]。从我国现行的实际规定来看,如2015年的任甲玉与北京百度网讯科技有限公司人格权纠纷一案(“中国被遗忘权第一案”)[17],将被遗忘权引入我国规定之中很有必要。有学者就当下我国引入“被遗忘权”的现实要求进行分析认为:就当前我国的法律体系而言,个人信息保护相关法规有所欠缺,“被遗忘权”的引入有望进一步完善我国的法律体系;当前我国个人信息泄露问题较为严重,人们的私人生活受到影响,“被遗忘权”的引入有望改善这一现状;在我国,“删帖”行为已成为灰色产业链,“被遗忘权”的引入一定程度上能抑制此类现象的猖獗[18]。同样,学者余筱兰认为,无论是在理论还是实践层面,信息删除权在大数据时代的信息保护立法中都有其必要性。这不仅是人权保障的需求,也是市场经营得以正常维系的需要[19]。同时,被遗忘权对公民来说,一方面,可以正确塑造个人形象:每个人或许多少都有着一些不愿意再被人知晓的过去,当过去已然不符合现在的情况,我们有权利让他人遗忘,网络空间也应该还原当下的个人情况,这也更有利于他人接收到更新、更准确的个人信息。另一方面,有利于保护个人权利:人们在使用互联网的时候总会或多或少地泄露一部分自己的信息,而当这些信息数据对信息主体产生负面影响的时候,个人有权将其删除,维护个人合法利益。因此,无论是从学界的广泛热议还是现实的考量,我国都应该引入被遗忘权。
(二)被遗忘权在中国的构建路径
被遗忘权的引入应当考虑该制度的缺陷,在结合中国实际的基础上对其调整对象、权利内容以及责任承担方式进行改良。在被遗忘权的权利主体方面,个人对有关自身的信息行使权利毋庸置疑。在调整对象方面,需要更新信息概念的定义方法,扩大被遗忘权的客体范围。在权利内容方面,克服知情同意框架带来的弊端,对权利内容进行风险评估的改良。当然,被遗忘权的责任主体应当得到明确、责任承担方式也应当进行改造。
1.被遗忘权调整对象的优化构建
正如前文所述,“识别说”模式下的个人信息定义具有狭隘性,应当被改造。
(1)个人信息的重新定义
个人信息应当包括与个人有关联的信息和数据,凡是与个人有关联的信息都应當纳入个人信息的范畴。当然,个人信息的列举式立法可以继续保留,但应当作为参考,而不能赋予其全有或者全无的效力。个人信息不应当局限于事前的预先设置,而应当以结果为导向,摒弃“识别说”的禁锢,确立新的动态定义方式。
(2)个人信息重新定义的原理及意义
遗忘权客体的改造参考了“关联性”学说的定义方式。个人信息的定义重点应当从“识别”转向“关联性”。“关联性”信息的定义方式来源于美国。美国联邦贸易委员会(FTC)在回复电子基金会(EFF)的消费者隐私框架报告中指出:该隐私框架可以适用于“与特定消费者、计算机或其他设备合理关联(link)”的数据[20]。美国《消费者信息隐私保护法》也规定了个人信息“关联性”的定义方式。
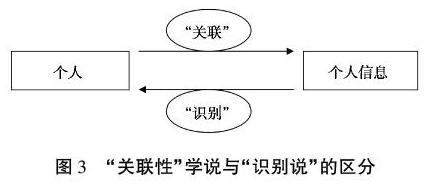
“关联性”学说的路径是指先确定某一具体的个人,再以此个人为原点,关联与该个人有关的信息。能够关联到特定个人的信息,并不以特殊性为前提,其作用是丰富给定个体的画像(profile)[13]72。例如,传统意义上“性别,男”并不能构成对个人的识别,但如果将“性别,男”与“李某某”相关联则形成了有关李某某的个人信息。“关联性”学说与“识别说”的区分如图3所示。
个人信息的“关联性”学说可以扩大个人信息的范围,克服“识别”定义方式的滞后性。“关联性”定义方式的做法将个人信息保护的重点从关注信息本身转向关注个人,不要求该信息能够辨别某一个体。一旦某信息与个人有关,即可认定为个人信息。这使得大数据背景下,某些看似无法识别个人的琐碎信息也被纳入个人信息的保护范畴,避免了信息再次识别对人的侵害。另外,只要有关联,个人即可行使被遗忘权,哪怕该信息未被利用,也可以提前防范个人信息的侵害,这也使得“识别说”定义方法的滞后弊端得以解决。
2.被遗忘权权利内容的改造构建
被遗忘权权利内容的改造分为以下三档。
第一档:个人信息的删除请求以具体情景的风险评估为准,达到风险标准的敏感信息,数据控制者、利用者和处理者应当着重披露和告知,数据主体可以直接请求将信息删除。
第二档:个人信息应当有具体行业规定配套的存储期限,存储期限届满的个人信息应当自动删除。例如,规定学前教育行业收集新生儿信息,应当在9个月内删除。
第三档:超过信息存储期限未自动删除的个人信息,可以由信息主体、信息处理者、控制者和收集者协商付费使用,未达成使用协议的可以由信息主体请求删除或请求公权力机关责令删除,或者公权力机关主动责令删除。当然,还可以在被遗忘权之外的规定中制定配套措施,如对达到风险标准的信息还应当进行备案管理,备案机关可以就“知情同意”的情况进行调查。
(1)情景划分与风险评估的设立
“情景脉络完整性”理论的情景划分为个人信息保护提供了蓝本。该理论基于两个准则的假设[21]:人类行为可以归于不同的场景中;具体的情景可以为发生于该情景中的行为提供规范。尼森鲍姆认为:“人们的现实生活,它们不仅跨越了二分法,而且在多个不同的领域中来回穿梭。求医、拜访朋友、咨询精神科医生、与律师交谈、去银行、参加宗教仪式、投票以及购物等,每一个领域都涉及到一个独特的规范,用来规范其各个方面。”敏感度的分级可以参考尼森鲍姆提出的四个要素:具体的情景脉络,如报纸的头版;不同情景中的行为人,如行为者在该情景中的特定身份;信息的属性,例如信息主体的外观;信息的传播方式,例如记者的新闻采访和传播。这四则要素为具体情景的划分提供了基础。
“情景脉络完整性”理论对“知情同意”框架的部分替代可以提高被遗忘权的效率。一方面,降低了被遗忘权低效保护的成本。对于敏感度不高的信息而言,收集时的知情与同意并不重要,重要的是该信息的利用方式、利用目的和利用场景。另一方面,“情景脉络完整性理论”解除了被遗忘权可能阻碍人工智能产业的忧虑。当下人工智能产业的发展需要大量的数据和信息支持,新数据和信息的收集、过往数据和信息的利用是该产业必不可少的环节。2017年,国务院印发了《新一代人工智能发展规划》,将人工智能发展上升到国家战略高度,构筑我国人工智能发展的先发优势,加快把建设创新型国家和世界科技强国提升到国家战略高度[22]。“情景脉络完整性”理论剔除了一般个人信息的“知情同意”的框架,将个人信息的保护重点由收集转向利用,为个人信息的收集降低了难度和成本。
尽管敏感等级评估无法避免,但人工智能产业的发展本身是对信息的合理利用,而非无限利用,解决好信息隐私与信息开发利用之间的矛盾是人工智能产业发展的重大课题。在以往考虑被遗忘权时,其是建立在“知情同意”的前提下,收集信息要求信息主体的同意,在不同意或“假同意”的情形下,信息主体还要承担被遗忘权的请求。“情景脉络完整性”理论使得被遗忘权影响产业发展的顾虑得以消除。风险评估的一般标准和具体标准为不同情景下的个人信息风险提供了评估方法。美国学者提出的信息隐私侵害的判断方法可以为风险评估提供一般标准。对于每个侵犯信息隐私权的案件而言,都可以按顺序对以下三个问题进行回答。
第一步:算法分析结果是否超出了信息主体的预期?如果超出预期,则进入第二步;如果没有超出预期,则视为该分析结果风险可接受。
第二步:该算法分析的结果是否比原信息的敏感度更大?如果更敏感,则进入第三步;如果不敏感,则该分析结果风险可接受。
第三步:该算法分析的结果是否符合具体的情景脉络?如果符合,则风险评估可接受;如果不符合,风险评估不可接受[23]。
具体情景下的风险评估标准依赖于信息敏感度分级制度的建立。在信息敏感度分级的制度中,敏感度越高对公民的伤害可能越大,反之,则越小[24]17。国内有学者针对公共部门的服务门类,为具体的个人信息评估划分了敏感等级[24]95,例如,体育、教育和卫生等公用部门的个人信息敏感度划分,各种商业服务情景下的个人信息也应当进行敏感度评估。
(2)个人信息付费使用机制的建设
尽管弱人工智能的兴起并没有取代人类,但大量失业的焦虑却并不能令人释怀,收入分配的差距也令底层大众焦躁不安。当数据被视为资本时,资本为公司提供利润,并激励公司的创新和发展;当数据被视为劳动时,则有助于数据的高质量产出。高质量的数据才是人工智能发展的优秀能源。虽然数据的性质为何仍然在探索中,但为数据付费完全可以作为可选择的方案。信息的付费使用也有助于筛选真正的信息需求者。经济学的研究表明,人们“为权利而斗争”并不是为了真善美,而是为了各自的利益[25]。成本的比较和核算是人的本性,信息的付费使用,要求信息利用者负担成本,这有助于将粗放经营者排除于市场之外,提高信息服务的质量。
(3)个人信息存储期限的确立
被遗忘权诞生之时,本身便自带“遗忘”属性。舍恩伯格认为遗忘期限为9个月。但对于该期限而言,应当结合民众意愿和技术需要进行分类规定。增添信息存储期限的原因如下:一方面,人会遗忘的天性与存储器永久“记忆”具有必然的矛盾,个体永远无法保障敏感的信息完全被清理,规定数据存储期限由数据主体进行选择是一项事前防范的良好措施,既为数据收集者提供了收集时间,也为数据主体提供了事前防范;另一方面,与个体请求删除相比,按照到达存储期限的方式删除个人数据效率更高,覆盖面更大。前者是个别链接和遗漏信息的删除,后者则是批量化操作。此外,规定存储期限还具有“兜底性”的特征。为信息设定存储期限,既可以为企业提供信息利用的期限,也可以倒逼企业提高效率改良算法,从而提高竞争力。这样,既为个人信息的保护提供了屏障,也为企业个人信息的利用留下了空间。
3.被遗忘权责任承担的明确构建
(1)被遗忘权责任主体的明确
被遗忘权的责任主体包括信息控制者、信息利用者、信息处理者以及敏感度等级较高的信息收集者。
首先,冈萨雷斯诉西班牙数据保护局案的判例表明,搜索引擎是被遗忘权的责任承担者,但并非责任承担者仅局限于搜索引擎。按照GDPR的规定,被遗忘权的行使对象包括部分收集者以及其余阶段的数据责任主体。数据控制者、处理者和数据利用者三者可以互相轉化,也有不同的表现形式。搜索引擎既可以是数据利用者,进行信息的传达和呈现,也可以是数据收集和控制者,收集和控制信息以分析市场和优化服务。
其次,认为被遗忘权的责任主体仅仅包括搜索引擎的观点,是对信息流转的静态看待,也是对互联网企业业务的孤立分析。对责任主体名称进行划分,并非静态区别责任主体的种类,某种程度上说,信息控制者、信息利用者和信息处理者的角色可以由同一责任主体在信息加工过程中的不同阶段分别扮演。因此,如果过度地将精力投入于明确信息控制者、信息利用者和信息处理者的界限之上,便会有本末倒置的嫌疑。
最后,“情景脉络完整性”理论并非要完全排除“知情同意”框架。针对高度敏感的个人信息,就“知情同意”的架构进行着重设计,对个人进行科学的提醒,使得其知情并同意个人信息的利用,也具有一定的可实行性。“知情同意”架构的失灵很大程度上来源于信息隐私的模糊、复杂和应用广泛的特点[26]。如果将隐私协议的数量缩减在高度敏感个人信息的收集范畴中,可以期待更高效的隐私协议设计。前述Junger,Marianne和Lorena Montoya的实验结果中,邮箱账号(b)也证明了这一点。
对被遗忘权权利内容的改造,最主要的是运用“情景脉络完整性”理论对“知情同意”的改造。当然,被遗忘权中删除为儿童社会信息服务而收集的信息以及删除不同意收集之外的非法信息也应当得到保留。
(2)删除责任的承担原则
明确谁利用谁删除、谁获益谁删除的删除原则,还要与信息行为发生的时间阶段相联系。这是由信息收集者同时又可能是信息处理者和控制者的特征决定的。在信息删除纠纷中,不必过于精准划分信息责任主体的过错,转而运用谁受益谁担责的方式,既可以节约判断成本,也能够起到信息保护的作用。这实际上是利用市场的淘汰机制进行信息保护。如果信息收集者违规操作获得信息但并未被发现,这一信息流通后,信息利用者在不知情的情形下进行了利用,此时不必确认过错的归属,而应当按照谁受益谁负责的直接标准进行责任划分,由信息利用者承担责任。信息利用者可以根据违约责任向信息收集者追究損失的补偿。在市场环境中,违约而被追究责任的企业往往不能在竞争中胜出,这便会倒逼信息收集者寻找更优秀的信息资源,也会倒逼信息利用者和控制者寻找具有更高信用度的商业伙伴,遵循对信息的合规要求,从而减少损害的发生,节约争议解决成本。
(3)明确删除内容的限度
被遗忘权引起争执的一大缘故在于,互联网环境中不论是链接、数据还是个人信息,要彻底将其删除存在很大的技术难度并需要一定的成本。除此之外,本地化的数据还可能导致已经删除的内容再度被上传网络并造成一定影响。这一观点看似很有道理,但并未深窥个人信息保护的内核。对于个人信息的保护,其本质上是先对个人信息形成控制,再以控制手段保护其背后的个人尊严等。在美国,信息隐私的主导范式是隐私控制论 ( Privacy-control),即对个人数据使用的控制权[27]。控制不等于删除,就被遗忘权而言,其删除是手段而遗忘是目的。对于整个人类而言,遗忘也并非一瞬间可以达成,而需要时间的消磨。
因此,被遗忘权并不是任意删除,也不是对个人信息、人生痕迹的任意涂改或掩过饰非,而是通过纠正网络时代的信息泛滥、过度便利和价值背离,保障每个人的人格得以自由发展,而不是生活在过往的阴影之中[28]。删除手段只是对个人信息形成控制的手段,控制的结果可以是完全控制、部分控制和控制失败。在整个人类的信息体系中,彻底删除一条信息固然无法想象,但法律或法规明确在恰当场景中不允许或暂时性删除某类信息却确实可以实现。比如,可以规定基因信息不允许出现在日访客流量500万以上的网页中。这便对个人信息的曝光度形成了控制,删除的目标也便有了更精准的检索范围。
(4)删除算法应用的必要性和可行性
允许信息主体使用删除算法或允许其委托第三方使用删除算法有如下理由。
首先,删除算法的应用具有现实必要性。个人信息隐私在大数据时代面临两种威胁:其一,个人无力阻止未经授权的信息传播;其二,个人被排除在个人信息商业流转的进程之外。换言之,依靠个人时刻监督和警惕其个人信息被收集和利用的方法成本过高。但算法可以做到为个人提供信息保护的服务,删除算法只是手段之一。相对于个人与科技巨头的信息隐私保护斗争而言,运用删除算法的助力使得信息隐私保护成为可能,既降低了隐私保护的成本,也有助于培育新时代的信息隐私观念。
其次,删除算法的利用具有法学可行性。算法并非一种价值中立的科学活动,它总是蕴含着价值判断,与特定的立场相关[29]。删除算法的背后是被遗忘权的价值选择,是达成被遗忘权目的的工具。删除算法可以达到符合人类价值观、个人隐私、隐私与自由等阿西洛马原则所强调的要求。Lawrence Lessig提出法律与代码之间的三种关系:法律驯服代码、代码代替法律、法律规制代码。应用删除算法既是被遗忘权之法律规定对代码的驯服,也是代码对法律的规制。赋予个人对信息的删除权和信息的自动删除义务,便改变了代码的分布。删除算法的应用也改变了法律的运行,在个体无法使用算法之前,删除的权力掌握在信息控制者和利用者手中,删除成本高且难度大。删除算法作为代码运行的另一种方法,使得删除的效率得以提高而成本却有所下降,使被遗忘权真正发挥保障信息的功效。
最后,删除算法的利用具有技术可行性。当下,互联网市场已经出现成熟的反个人信息收集的混淆算法,通过在搜索引擎键入的关键词里插入无关字符,以达到混淆关键词的目的。混淆算法是事前防备个人信息被不当收集的技术,删除算法则相反,是事后擦除个人信息的技术。借助技术手段达到权利目的可能更有效。
被遗忘权的提出代表了进一步扩张个人数据权利的倾向,这一倾向是在互联网尤其是社交网络急剧发展的背景下出现的[30]。被遗忘权的权利改造要关注被遗忘权本身,它涉及个人信息的其他制度,是牵一发而动全身的工作。其制度改造与技术利用需要同步进行,以合理制度搭载技术之翼可能更易于提高制度的社会效果。
五、结 语
在信息时代,“记忆”已经取代“遗忘”成为网络空间的规范与常态,网络空间的“雁过留声”使人们很难逃离自己的过去[31]。在对待被遗忘权的态度上,欧美因不同的信息隐私和历史观念而截然不同。欧盟选择了被遗忘权,而美国选择了言论自由。欧美差异选择的理由启示我国在引入被遗忘权时,应当结合具体的价值观念、经济成本、信息保护需求和法律体系,改造被遗忘权成为必要。通过“关联性”学说对个人信息进行优化构建,利用“情景脉络完整性”理论对“知情同意”框架的部分变革可以为被遗忘权的引入打好理论基础。被遗忘权的删除责任以及违规责任应当在法条中予以明确。同时,被遗忘权还可以借助算法的技术力量,并在删除之外扩展其遗忘功效。当然,依照“情景脉络完整性”理论需要制定各行业不同的信息规范,以满足动态评估信息收集和利用风险的大小,并制定具体行业存储期限的长短,这些需要大量的数据支持和行业实践,并非一日之寒。当个人信息的隐私行将远去,被遗忘权之探索仍然任重道远,前路蹉跎,砥砺前行。
参考文献:
[1] 伍艳.论网络信息时代的“被遗忘权”——以欧盟个人数据保护改革为视角[J].图书馆理论与实践,2013(11):4.
[2] 郑曦.个人信息保护视角下的刑事被遗忘权对应义务研究[J].浙江工商大学学报,2019(1):46.
[3] 维克托·迈尔-舍恩伯格.删除:大数据取舍之道[M].袁杰,译.杭州:浙江人民出版社,2013:19.
[4] 刘学涛.大数据时代个人信息的行政法保护分析:内涵、困境与路径选择[J].南京邮电大学学报(社会科学版),2018(6):27.
[5] 张新宝.隐私权的法律保护[M].北京:群众出版社,1998:157.
[6] WHITMAN J Q. The Two Western Cultures of Privacy: Dignity Versus Liberty[J].Yale Law Journal,2004(6):1161.
[7] WHITMAN J Q. Enforcing Civility and Respect:Three Societies Enforcing Civility and Respect[J].Yale Law Journal,2000(6):1297.
[8] DOWNWELL J W.An American Right to be Forgotten[J].Tulsa Law Review,2017(2):331.
[9] 齊爱民.个人信息保护法研究[J].河北法学,2008(4):15.
[10]王利明.论个人信息权的法律保护——以个人信息权与隐私权的界分为中心[J].现代法学,2013(7):64.
[11]刘德良.个人信息的财产权保护[J].法学研究,2007(3):80.
[12]刘学涛.个人数据保护的法治难题与治理路径探析[J].科技与法律,2019(2):21.
[13]范为.大数据时代个人信息定义再审视[J].信息安全与通信保密,2016(10).
[14]范为.大数据时代个人信息保护的路径重构[J].环球法律评论,2016(5):94.
[15]MARIANNE J, MONTOYA L, OVERINK F-J. Priming and warnings are not effective to prevent social engineering attacks[J].Computers in Human Behavior, 2017(66).
[16]何治乐,黄道丽.大数据环境下我国被遗忘权之立法构建——欧盟《一般数据保护条例》被遗忘权之借鉴[J].网络安全技术与应用,2014(5):173.
[17]杨杰.被遗忘权的明晰及本土化探究[J].重庆邮电大学学报(社会科学版),2018(4):73.
[18]郭小安,雷闪闪.“数据被遗忘权”实施困境与我国的应对策略[J].理论探索,2016(6):111-112.
[19]余筱兰.民法典编纂视角下信息删除权建构[J].政治与法律,2018(4):27.
[20]Protecting Consumer Privacy In An Era Of Rapid Chan-
ge: A Propesed Frame Work For Business And Policymakers (Preliminary Staff Report) Response Of The Electronic FrontierFoundation[EB/OL].[2018-12-22].https://www.eff.org/files/ftccommentseff.pdf.
[21]NISSENBAUM H. Privacy as Contextual Integrity[J]. Wshington Law Review,2004(6):102.
[22]新一代人工智能发展规划[EB/OL].(2017-07-20)[2019-01-15].http://www.gov.cn/zhengce/content/2017-07/20/content_52116.htm.
[23]Pan S B. Get to Know Me: Protecting Privacy and Autonomy under Big Datas Penetrating Gaze[J]. Harvard Journal of Law & Technology,2016(30):259.
[24]刘雅琦.基于敏感度分级的个人信息开发利用保障体系研究[M].武汉:武汉大学出版社,2015.
[25]冯玉军.法律与经济推理——寻求中国问题的解决[M].北京:经济科学出版社,2008:32.
[26]BEN-SHAHAR O, CHILTON A. Simplification of Privacy Disclosures: An Experimental Test[J].Journal of Legal Studies,2016(45):45.
[27]高富平.个人信息保护:从个人控制到社会控制[J].法学研究,2018(3):91.
[28]滿洪杰.被遗忘权的解析与构建:作为网络时代信息价值纠偏机制的研究[J].法制与社会发展,2018(2):217.
[29]丁晓东.算法与歧视——从美国教育平权案看算法伦理与法律解释[J].中外法学,2017(6):1622.
[30]刘文杰.被遗忘权:传统元素、新语境与利益衡量[J].法学研究,2018(2):40.
[31]范为.由Google Spain案论“被遗忘权”的法律适用——以欧盟数据保护指令(95/46/EC)为中心[J].网络法律评论,2013(2):267.
Abstract:China in the data age faces a series of major problems such as personal information infringement, personal privacy disclosure, and algorithmic discrimination. The right to be forgotten should be established with the aim of protecting the rights of information subjects. The right to be forgotten in Europe and the United States is reflected in the conflict between privacy and freedom. The importance of this theory to the needs of countries is that the right to be deleted in Chinas existing legal system cannot be equated with the forgotten right established by the EU. The current right to be forgotten faces the development dilemma of setting defects of adjustment objects, setting deviations of rights content, and insufficient setting of responsible subjects. The heated discussion and practical needs of scholars indicate to a certain extent that China should introduce the right to be forgotten, and that chinas path choice should be set up from the optimization construction of adjustment objects, the reconstruction of rights content, and the construction of responsibility, so as to solve the new challenges brought by the development of network information society.
Keywords:forgotten right; deletion right; contextual integrity; deletion algorithm
(编辑:刘仲秋)
