基于半监督的SVM多标签图数据分类算法研究
2019-07-08宋文广李程文谭建平
宋文广 李程文 谭建平

摘 要:传统的图数据分类研究主要集中在单标签集,然而在很多应用中,每个图数据都会同时具有多个标签集。文章研究关于多标签图数据分类问题,并提出基于半监督的SVM多标签图数据分类算法。算法首先通过一对多二元分解将多标签图数据分解成多个单标签图数据。然后对分解后的图数据,运用半监督SVM进行分类。通过实验证明,该方法在已标注图数据较少情况下具有较高的分类精度。
关键词:图数据;多标签;半监督;自训练
單标签分类(二分类)是传统分类方法的主要研究方向,它是基于一幅图只有一个标签的假设上。在现实场景中,所用到的图数据一般都具有多个标签集[1-2]。
半监督学习即利用大量无标签数据和少量有标签数据共同训练模型。但半监督学习很难与监督学习分类性能相比,但从目前算法优化发展来看,半监督学习很有可能达到传统分类方法的性能。
1 基于半监督的SVM分类算法
2 实验
2.1 数据集
用一组化合物抗癌活性性能数据集作为实验用多标签数据集。该组数据包含了化合物对于10种癌症的抗癌活性性能的记录,将10种癌症中记录不完全的数据移除,得到812个被分配了10个标签的图。
2.2 评估方法
多标签分类比传统单标签分类问题需要不同的实验结果评估标准。在这里采用Ranking Loss和Average Precision评估多标签[3-4]分类性能。实验结果评估标准如下:
(1)Ranking Loss:评估分类实际输出值的性能,它的值由错误预测的标签对的平均值计算得到的。
(2)平均准确率:评估排列顺序在特殊标签y之上的标签的平均值,把y设置为真实标签集。
2.3 实验设置
为了体现本文算法的有效性与实用性,采用以下对比方法进行实验。
(1)单标签+SVM:这个方法采用单标签图数据训练普通的SVM模型。
(2)多标签+SVM:这个方法采用多标签图数据训练自适应SVM模型。
2.4 实验结果
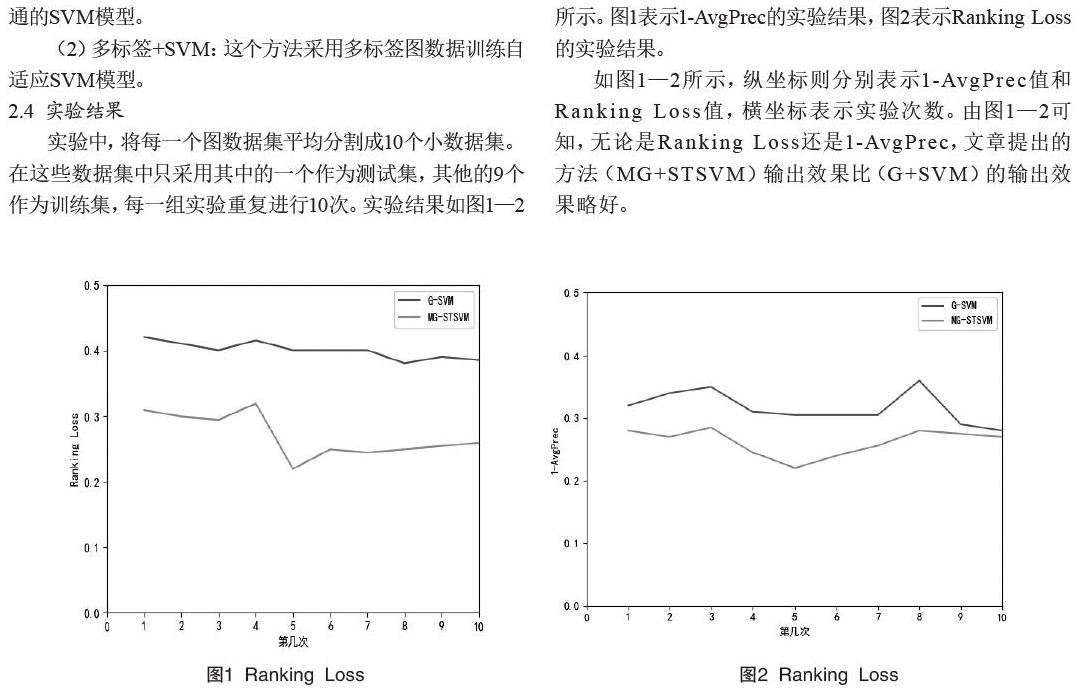
实验中,将每一个图数据集平均分割成10个小数据集。在这些数据集中只采用其中的一个作为测试集,其他的9个作为训练集,每一组实验重复进行10次。实验结果如图1—2所示。图1表示1-AvgPrec的实验结果,图2表示Ranking Loss的实验结果。
如图1—2所示,纵坐标则分别表示1-AvgPrec值和Ranking Loss值,横坐标表示实验次数。由图1—2可知,无论是Ranking Loss还是1-AvgPrec,文章提出的方法(MG+STSVM)输出效果比(G+SVM)的输出效果略好。
3 结语
本文采用半监督SVM方法可以利用大量未标注数据来帮助分类模型的训练,从而挖掘出未标注数据中可能含有的对分类起重要作用的信息。进而,在已标注多标签图数据比较少的情况下,得到不错的分类器。在以后的研究工作中,将会继续完善研究方法,并寻找提高目标域子图数量的算法。
[参考文献]
[1]BRAVO MARQUEZ F,FRANK E,MOHAMMAD S M,et al.Determining word-emotion associations from tweets by multi-label classification[C].Nebraska:IEEE/WIC/ACM International Conference on Web Intelligence,2017.
[2]AGGARWAL C C,ZHAI C X.A survey of text classification algorithms[J].Springer US,2012(3):163-222.
[3]SEBASTINAI F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002(1):1-47.
[4]YEH C K,WU W C,KO W J,et al.Learning deep latent spaces for multi-label classification[J]. 2017(7):12-15.
