基于聚类的超密集网络干扰抑制方法
2019-06-27侯欢欢
姜 静, 侯欢欢
(1. 西安邮电大学 通信与信息工程学院, 陕西 西安 710121;2. 西安邮电大学 陕西省信息通信网络及安全重点实验室, 陕西 西安 710121)
随着无线技术的发展和普及,移动互联网流量的不断增长对当前的无线网络提出了巨大的挑战。超密集网络被认为是支持每秒千兆位面积吞吐量,无缝覆盖和高频谱效率的有效的解决方案[1-2]。超密集网络(ultra-dense networks, UDN)系统通过在宏小区的覆盖区域部署大量的小小区来实现网络密集化,以提高系统吞吐量。但是,小型小区的密集部署也带来了新的问题,如严重的干扰问题等。
聚类是一种标准的迭代算法,旨在将观测值划分为聚类,使得聚类后的类中每个观测值属于具有相似属性,因此,可以将机器学习的无监督学习聚类算法应用于UDN系统以处理的干扰抑制问题,如传统的K均值算法[3]。该算法在聚类之前需要选择初始聚类中心,这可能会导致聚类迭代和部分优化的增加,而不是全局优化,同时,不同的初始聚类中心可能会出现不同的聚类结果,这使得传统的K均值聚类算法更加不稳定。文献[4]提出了一种两阶段资源分配方案,用于监督干扰和资源分配。先利用K均值聚类算法将毫微微基站划分为不同的类,再将子信道分配算法用于不同类的毫微微基站,以减轻干扰并提高系统性能。文献[4]是对传统K均值算法进行改进,针对初始聚类中心不同可能会导致的不同聚类结果这一问题,使用余弦角方法来近似计算每对微基站之间的距离,然后应用最大距离算法计算初始簇头。改进后的K均值聚类算法既能防止算法出现局部优化,又具有更快的收敛速度和更低的复杂度。与K均值聚类方法相比较,基于密度的噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)算法[5]可以根据用户的分布发现分组的组数,不需要指定组的数量。另外,DBSCAN聚类算法还通过检测噪声,以区分与任何其他用户信道完全不相似的用户,这样对噪声的检测能够减少用户调度时不必要的计算。对于有大量用户的UDN系统来说[6],考虑使用比例公平(proportional fair, PF)调度算法[7-8],来保证用户的公平性。
在超密集网络系统中,为了既兼顾用户的公平性,又能更好地抑制干扰的效果,提出一种基于改进的DBSCAN聚类算法的干扰抑制方法。首先,基站利用改进后的DBSCAN聚类算法对小区里的用户进行分组,将具有相似信道特性的用户聚在一组。然后,使用比例公平调度来对每个分组中的用户计算调度优先级,选出各个分组中比例公平系数最高的用户进行调度。并利用仿真方法,验证改进算法的有效性和性能。
1 系统模型
考虑由小小区及其相关用户组成的UDN系统的下行链路,其中小小区基站(base station, BS)向K个用户传输数据。在系统中,假设BS端有Nt个发射天线,用户端有一个接收天线。采用迫零预编码[9]对数据进行预处理,第k个用户的接收信号[10]yk可以表示为
(1)
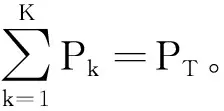
(2)
根据式(2),在时隙t用户k的瞬时和速率为
rk(t)=log2(1+RSINR,k(t)),
式中为RSINR,k(t)第k个用户t时刻的SINR。
2 改进的DBSCAN算法的用户分组
下面将通过改进的DBSCAN聚类算法对用户进行分组,让信道相关性高的用户分为一组,各个分组之间的用户的信道相关性较低。从每个分组中取出一个用户,让不同信道相关性的用户在相同的资源上传输,以保证能够很好的抑制用户间的干扰。
DBSCAN聚类算法[11]有两个重要参数,一个是表示一个点周围邻近区域的半径ε,另一个是表示邻近区域内至少包含用户的个数M。其核心思想是用一个用户的邻域内用户数来衡量该用户所在空间的密度,对随机分布的用户进行分组,且聚类时不需事先知道用户分组的组数。这样,利用DBSCAN聚类算法不但可以发现任意分布类型的组,而且还能够检测噪声。对噪声的检测能够有效减少用户调度时不必要的计算。
设S表示用户组,用户k的ε邻域表示为
NS(k)={j∈S:d(k,j)≤ε},
式中d(k,j)表示用户k到用户j之间的距离,|NS(k)|表示ε邻域里满足d(k,j)≤ε的条件的用户数。为了使DBSCAN算法更好地应用于用户分组,在此,对判断满足条件的方式进行修改。用户k与用户j的信道信息分别为hk和hj,用户k和用户j之间的信道相关性α(k,j)表示为

在确定用户的ε邻域后,在原判断基础上增加一个判断门限αb,即满足α(k,j)≥αb的用户才算有效用户。|NS(k)|表示ε邻域里面满足条件d(k,j)≤ε以及α(k,j)≥αb的用户数。
当|NS(k)|≥M时,用户k是核心用户;当1<|NS(k)| 改进的DBSCAN聚类算法流程的如下所述。 步骤1首先将用户集中的所有用户标记为未处理用户。 步骤2从集合中随机选择一个未被处理的用户k,找出用户k的ε邻域内满足条件d(k,j)≤ε以及α(k,j)≥αb的用户。 步骤3如果|NS(k)|=1,则用户k判定为噪声,并标记为已处理,返回步骤2继续进行;如果1<|NS(k)| 步骤4当每个用户被标记为已处理时,则结束算法,得到用户分组集合S1,S2,…,SM,M由DBSCAN算法的分组结果定。 在使用改进的DBSCAN聚类算法对用户进行分组后,具有相似信道特性的用户在一组,不同分组用户之间的信道相关性较低。然后,基站对各分组用户进行比例公平(proportional fair, PF)调度,选每组中比例公平系数最高的用户进行传输。调度后的多个用户的空间特性是不同的,有利于降低空间干扰,起到干扰抑制的效果。 为保证调度用户的公平性,让各组中的每个用户都有机会进行资源分配和数据传输,采用PF调度算法[12],其算法的步骤如下。 步骤1通过BS处的特定长度的时间窗口来跟踪每个用户的平均吞吐量。 步骤2BS获得每个用户的信道状态信息反馈。 步骤3根据用户集合S1,S2,…,SM,计算各分组中用户的调度优先级,即瞬时吞吐量与平均吞吐量的比值。在调度时,基站调度各个分组中优先级最高的用户,即 式中Rk(t)表示用户k的平均吞吐量。rk(t)随着信道信息的变化而变化,当在该时刻该用户没有数据要传输时,rk(t)=0。 步骤4当一个调度周期完成之后,分别为各个分组中的用户更新下一调度周期的平均吞吐量Rk(t+1)为 其中TC是时间窗口的长度。若TC越大,则缓存的用户数越多,待调度的用户就可能需要比较长的时间来获得基站的调度;若TC越小,则缓存的用户数越少,同时调度公平性也越好。在此,设定TC=100[13]。如果当前用户所处的信道状态一直较差,则该用户的当前时刻的瞬时吞吐量较低,从而导致其优先级较低,不能获得资源进行数据传输;当用户一直处于等待数据发送状态时,又会导致平均吞吐量变小,下一调度周期该用户的优先级就会提高,就能分配到资源进行数据传输了。这样,PF算法就可以保证用户得公平性,每个用户都有机会被调度,不会使信道状态一直差的用户出现“饿死”现象。 为验证改进基于聚类的超密集网络干扰抑制算法的有效性,采用MATLAB平台对算法的进行仿真,以评估提出算法的性能。仿真参数的设置见表1。 表1 仿真参数 首先,仿真了判定门限αb对系统和速率的影响,其结果如图1所示。可以看出,系统和速率随着判定门限的增大而增大,说明随着判定门限的增大,在改进的DBSCAN分组算法中对满足条件的用户的筛选更加严格,DBSCAN聚类算法的分组效果更好,从而系统和速率也随之提高。考虑到这个因素,根据图1中的曲线情况,设置判定门限αb=0.5。 图1 不同判定门限的系统和速率与用户数的关系 其次,为了验证改进的DBSCAN聚类分组后PF调度算法的系统性能,仿真了随机分组后PF调度算法、K均值聚类后PF调度算法和改进的DBSCAN聚类分组后PF调度算法等3种不同聚类算法下系统的和速率结果如图2所示。其中,随机分组算法是不进行聚类,随机的将用户分为10组,K均值聚类分组算法的分组数设定为10。从仿真结果可以看出,没有进行聚类的随机分组性能是最差的,DBSAN聚类分组算法因为能分离出噪声用户,还能根据用户的信道状态改变分组数目,相比较于固定分组个数的K均值聚类算法来说性能要更好。 图2 3种聚类算法下系统和速率随信噪比的关系 另外,在上述3种分组算法中,不聚类随机分组算法的计算复杂度最低,DBSCAN聚类算法的计算复杂度最高。 UDN技术是第五代移动网络中提高容量和频谱效率的关键技术之一。针对UDN系统所提出了基于聚类的干扰抑制技术,基站首先根据改进的DBSCAN聚类算法对用户进行分组,让信道相关性高的分为一组,其次,利用PF调度算法进行调度。改进算法既兼顾了系统吞吐量与用户公平性的同时,又降低了空间干扰。仿真结果显示,改进DBSCAN聚类算法的相比较于K均值聚类分组来说,系统的和速率更高。3 比例公平的用户调度算法
4 仿真结果及分析



5 结语
