集中连片特困地区精准扶贫效率影响因素分析
2019-06-25郭宁宁
郭宁宁,钱 力
(安徽财经大学 经济学院,安徽 蚌埠 233030)
改革开放以来,经过全国范围有计划有组织的大规模开发式扶贫,我国贫困人口大量减少,贫困地区面貌变化显著。[1]贫困人口由 1978 年的7.7亿人减少至2018年的1660万人,近五年共减少贫困人口5357万人,年均减少1000多万人。农村贫困人口脱贫是全面建设小康社会最艰巨的任务,为打赢脱贫攻坚战,党的十八届五中全会提出了精准扶贫、精准脱贫的基本方略,但由于历史和自然等方面的原因,我国各地区之间和地区内部的经济发展很不平衡,特别是贫困地区的生产力发展十分缓慢。[2]按照“集中连片、突出重点、全国统筹、区划完整”的原则,国家将六盘山区、秦巴山区、大别山区、乌蒙山区、滇桂黔石漠化区、武陵山区、滇西边境山区、大兴安岭南麓山区、燕山-太行山区、吕梁山区、罗霄山区等区域的连片特困地区和已明确实施特殊政策的西藏、四省藏区、新疆南疆四地州,共计689个县作为扶贫攻坚主战场。集中连片特困地区基本覆盖了全国绝大部分贫困地区和深度贫困群体,2017年末农村贫困人口1540人,占全国总农村贫困人口的50.6%,农村贫困人口比上年减少649万人,占全国农村贫困人口减少总规模的50.3%,贫困发生率7.4%,比2017年全国贫困发生率高4.3%。致贫因素复杂多样的集中连片特困地区是精准扶贫的重点和难点,[3]目前扶贫开发工作已进入啃硬骨头、攻坚拔寨的冲刺阶段,对党和国家的扶贫工作提出了新的要求和挑战,扶贫开发工作任务异常艰巨。[4]
精准扶贫实施以来,国内外学者对集中连片特困地区的相关问题做了大量的研究,内容可以概括为以下几个方面:一是集中连片特困地区精准扶贫中的实践困境,大部分学者从对象识别、制度供给、经济发展等方面进行了探讨,如邓维杰(2014)[5]认为在精准识别方面出现了规模排斥、区域排斥、识别排斥,在精准帮扶中出现了需求排斥、入门排斥、资金用途排斥、市场排斥、专业排斥等现象;汪三贵(2015)[6]以乌蒙山区为研究对象,认为在精准扶贫过程中存在精准扶持、精准考核和精准识别等问题;刘七军(2016)[7]等以农户的自我发展能力为切入点,认为精准扶贫过程中存在投资能力脆弱、经营管理能力不高、学习能力欠缺、基本发展能力不够、沟通交际能力缺乏等挑战;王美英(2017)[8]认为乌蒙山的布拖县在精准扶贫过程中存在内生发展动力不足、主导产业不突出、带动经济不强等问题。陶少华(2018)[9]以武陵山片区的重庆民族地区为例,认为精准扶贫过程中存在着精准识别、差异化精准政策、产业发展乏力等现象;方菲(2019)[10]等人认为精准扶贫政策实施过程中,存在着结构性脱嵌和文化性脱嵌,有可能会引起农户福利依赖和农户争贫闹访。二是集中连片特困地区精准扶贫路径优化,普遍认为应从完善精准扶贫考核机制、完善精准识别机制、探索和建立贫困户的受益机制、改革贫困标准的制定方法等方面着手,如王赞新(2015)[11]以大湘西地区为例,提出了生态补偿式扶贫,并对其实施可行性进行了分析研究;韩斌(2015)[12]基于精准扶贫的视角,以滇黔桂石漠化片区为例,提出了“种养+加工+科技”、特殊群体“救助+帮扶”等精准扶贫的实现路径;陈灿平(2016)[13]以四川少数民族特困地区为例,提出大力推进旅游扶贫、创新金融扶贫理念,提高精准扶贫成效、实施“互联网+”扶贫模式等路径;钱力、李剑芳(2018)[14]认为集中连片特困地区可通过精准识别帮扶对象、加快贫困地区基础设施建设、创新扶贫模式、激发脱贫内生动力等路径确保精准扶贫的成果;郑瑞强(2018)[15]以新型城乡为背景,结合益贫机理分析,提出新时期应从新型扶贫模式、新型投入方式、新型战略定位等方面展开优化。三是集中连片特困地区致贫因素,主要从制度供给、人力资源、地理环境等方面进行探讨,如Kam S P(2006)[16]、Okwi P O(2007)[17]等认为公共服务设施水平落后会阻碍农村贫困人口的自我发展能力提升, 导致贫困程度进一步加深;曾志红(2013)[18]认为在新扶贫标准下,集中连片特困地区主要致贫因素为自然环境因素、资本投入因素、个人能力因素、社会制度因素;Das Gupta M(2014)[19]、张永丽(2018)[20]等认为自然条件、劳动力资源和配置是导致贫困问题的关键所在;张艾力(2019)[21]以内蒙古农牧区深度贫困人口为研究对象,分析得出该群体致贫的主要原因是内生动力不足、习俗致贫、发展不足、自然生态恶劣等等。
综上所述,国内外学者的研究成果较为丰富,为进一步客观、科学的分析提供了科学的参考依据,但就现有文献来看,存在一定的扩展空间。一方面,现有文献较多采用的是传统的DEA模型,在进行有效的区分多个决策单元差异方面具有一定的局限性。另一方面,研究层面多为某一个片区,其中六盘山区、武陵山区、乌蒙山区研究相对较多,对整个集中连片特困地区的研究相对较少。本文选择超效率DEA-Tobit模型分析集中连片特困地区精准扶贫效率及精准扶贫效率的影响因素,以为后续精准扶贫工作的扎实开展提供科学依据。
一、模型介绍与数据来源
根据本文研究对象和内容,拟采用超效率DEA-Tobit两步法,首先采用超效率DEA模型对集中连片特困地区精准扶贫效率进行测算,然后进行Tobit回归分析其影响因素,回归分析中,因变量为超效率结果,自变量为所选定的影响因素。
1.超效率DEA模型
DEA也就是数据包络分析,是一种以线性规划为基础,距离函数为方式的模型方法,里面包括CCR,BCC、SBM等若干种模型。首个DEA模型由 Charnes,Cooper and Rhodes(1978)提出,即用来评价决策单元的相对效率的CCR模型。[22]之后学者们在基础模型上不断发展和完善,DEA模型也逐渐成为评价相同决策单元较为广泛使用的一种方法。但如果出现多个决策单元同时位于效率前沿面时,传统DEA模型将无法评价和比较相对效率。据此,Anderson于1993年基于传统DEA模型提出了超效率DEA模型,[23]该模型可弥补传统DEA的缺陷,可对有效决策单元进行比较和排序。具体模型如下:
minθ
(1)
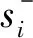
2.Tobit模型
Tobit模型不同于一般的连续变量选择模型和离散选择模型,是因变量满足某种约束条件下取值的模型。最显著的特点是其因变量取值有一定的限制,主要研究在不同的选择行为条件下,连续变量如何随之变化。Tobit 模型公式如下:
(2)
式中,yit为潜在应变量,当潜变量yi>0时被观察到,取yit=yi>0,称yi为“无限制”观测值,当yi≤0在0处截尾时,取yit=0,称yit为“受限”观察值,βT是回归系数向量,xit为自变量向量,误差项独立且服从正态分布:εit~N(0,σ2)。再进行估计Tobit模型中的参数时,为避免在含有截尾数据的模型参数时会产生偏差且估计量不一致的情况,这里采用最大似然法估计其参数
3.数据来源
本文以集中连片特困地区为研究样本,在时间层面上选取2011—2017年作为研究年限。原始数据主要来源于《中国农村贫困监测报告》,缺失数据通过查找《中国统计年鉴》《中国县域统计年鉴》等。
二、集中连片特困地区精准扶贫效率评价
1.投入产出指标
结合研究需要并参考相关文献[24-25],这里投入指标主要选取医疗、教育、环境、基础设施四个方面。在医疗方面,选择医疗卫生床位数作为投入变量。教育方面,选择普通中学在校学生数为投入变量。环境方面,选择所在自然村垃圾能集中处理的农户比重比作为投入变量。基础设施方面,选择使用经过净化处理自来水的农户比重和所在自然村进村主干道路硬化的农户比重作为投入变量。精准扶贫最主要的目的是提高贫困户的收入,达到较好的生活水平。故这里产出指标选取人均可支配收入、人均消费支出、年末金融机构各项贷款余额作为产出变量。
在DEA模型中,投入和产出之间呈正相关性,即随着投入增加,产出也会相应有所增加,不能出现产出随着投入增加而减少的情况。为了保证所选指标的科学性、合理性,采用SPSS 22.0对本文所选取的投入、产出指标进行Pearson相关性检验,检验结果见表1。
表1投入、产出指标相关系数检验结果

指标Pearson相关系数人均可支配收入人均消费支出年末金融机构各项贷款余额医疗卫生床位数0.643(0.000)0.612(0.000)0.583(0.000)普通中学在校学生数0.532(0.000)0.784(0.000)0.468(0.003)所在自然村垃圾能集中处理的农户比重0.461(0.007)0.531(0.000)0.632(0.000)经过净化处理自来水的农户比重0.342(0.008)0.461(0.005)0.453(0.007)所在自然村进村主干道路硬化的农户比重0.764(0.000)0.685(0.000)0.764(0.000)
注:显著性水平为0.01,表中括号内的数字表示的是显著性检验的P值。
从表1可以看出,从投入、产出中任各选一个指标之间的Pearson相关系数均大于0.2,表明所选的投入、产出指标之间存在着相关性。且在0.01的显著水平上,各P值均小于显著性水平,表明所对应的两指标之间存在差别,且有非常显著意义。故本文所选择的投入、产出指标较为合理。
2.精准扶贫效率分析
在传统DEA模型中,所测算的效率值均小于或等于1,超效率DEA中,可对效率值为1的决策单元进行有效的区分和比较,这样可以使各决策单元之间的效率值差别更加显著。采用EMS1.3(效率评价软件)对集中连片特困地区2011—2017年精准扶贫效率值进行测算。根据表2可以看出集中连片特困地区精准扶贫绩效是逐年上升的,特别是2013年以后,上升的趋势更为明显,2015年以后,绩效值处于大于1的状态。贫困状况逐年好转,从实证层面上也说明了集中连片特困地区相关的精准扶贫开发工作取得了不错的成效。但从目前情况来看,精准扶贫效率整体水平仍有待提高。
表22011-2017年集中连片特困地区精准扶贫绩效结果

年度精准扶贫绩效值20110.74820120.76320130.81220140.90320150.99720161.01320171.068
数据来源:根据《中国农村贫困监测报告》《中国县域统计年鉴》《中国统计年鉴》相关数据计算整理。
不同片区的精准扶贫效率之间存在着差异性,以2017年为例,在各片区绩效得分基础上,采用mapinfo 15.0绘制图1。从图中可以看出,2017年集中连片特困地区精准扶贫生产效率大于1的只有两个片区,分别是大别山区和西藏,说明这两个片区的扶贫效率相对较好,新疆南疆三地州、秦巴山区、武陵山区、罗霄山区、滇桂黔石漠化区、大兴安岭南麓山区扶贫效率相对良好,四省藏区、乌蒙山区、滇西边境山区、燕山—太行山区精准扶贫优势尚不明显,六盘山区、吕梁山区精准扶贫效率相对较低,相对无效率。在国家重点扶贫的三区中,西藏精准扶贫生产效率相对高一点,新疆南疆四地州次之,四省藏区最低,生产效率为0.80,但三区的精准扶贫生产效率整体来说较为良好。

图1 2017年集中连片特困区精准扶贫效率情况
三、基于Tobit模型的影响因素分析
1.指标选取
贫困不仅仅只包括收入贫困方面,还包括了保障、公共服务、所获得的社会福利等指标[26],基于Sen的可行能力理论,参考相关文献[27-29],本文主要从经济发展水平、生产生活水平、文化教育水平、基础设施水平、生态环境水平五个方面,选取了10个指标对集中连片特困地区精准扶贫效率影响因素进行分析。
2.模型构建
运用Tobit模型对集中连片特困地区精准扶贫影响因素进行回归分析,因变量(Yi)为各决策单元的超效率值,自变量为所选的10个指标,回归模型构建如下:
表3精准扶贫致贫因素指标体系

目标层准则层指标层单位精准扶贫致贫因素指标体系经济发展水平A人均生产总值A1规模以上工业总产值A2元元生产生活水平B农业机械总动力B1粮食总产量B2wt文化教育水平C小学在校学生数C1体育馆个数C2个个基础设施水平D通客运班车的自然村比重D1有卫生站(室)的村比重D2%%生态环境水平E污水处理厂数E1垃圾处理站数E2座个
Yi=β0+β1A1+β2A2+β3B1+β4B2
+β5C1+β6C2+β7D1+β8D2+β9E1+β10E2+εi
上式中,β0表示常数项,β1~β17表示各个自变量的回归系数,εi表示随机误差项。
在进行Tobit 回归分析之前,先采用SPSS22.0对原始数据进行标准化处理,这里采用的是最小-最大标准化,公式为:X′=(X-Xmin)/
(Xmax-Xmin)。
3.Tobit回归结果分析
采用Eviews 9.0软件对标准化后的数据进行回归分析,结果如表4所示。从Tobit回归结果可以看出,所选影响因素对精准扶贫效率的影响在统计上均显著,下面对各致贫维度进行分析。
表4精准扶贫效率影响因素回归结果

变量系数标准误差Z统计量P值人均生产总值0.001∗∗0.000-0.8780.374规模以上工业总产值2.134∗∗1.2361.9270.261农业机械总动力0.013∗∗0.1020.9870.214粮食总产量0.017∗∗0.0121.9780.243小学在校学生数0.000∗∗0.001-2.3120.237体育馆个数0.032∗∗∗0.0034.2410.001通客运班车的自然村比重0.028∗∗∗0.0123.2120.142有卫生站(室)的村比重0.417∗∗0.182-2.7240.112污水处理厂数0.000∗∗0.000-0.7870.227垃圾处理站数0.002∗∗0.000-0.6720.237常数项2.529∗1.4271.9270.063
注:*、**、***分别表示在0.1、0.05、0.01的统计水平上差异显著。
(1)经济发展水平方面。从回归系数为正可以看出,片区的经济发展对于精准扶贫的效率起到正向作用。在所选取的10个变量中,人均生产总值对于精准扶贫效率的影响程度最大,当人均生产总值提升一个百分点的时候,精准扶贫绩效将提高0.374个百分点。规模以上工业总产值的影响程度也相对较高,工业是社会稳定和发展的基础,同时工业的发展有利于三产结构的优化,生产效率的提高也更有利于精准扶贫取得较好的成果。
(2)生产生活水平方面。从回归结果看出,生产生活水平的提高对精准扶贫效率的提高起到了积极的作用。除经济发展水平外,生产生活水平的影响程度相对较高。在生产生活水平中,粮食总产量对精准扶贫的影响程度相对较大,农业尤其是种植业是集中连片特困地区的主导和基础性产业,农业收入是居民收入的主要来源,随着农业机械总动力的提高,粮食总产量有所提升,但由于部分片区土地退化、石质荒漠、水土流失、地上和地下溶蚀面积的不断扩大,农业发展极受限制,耕种面积有限的地区农业生产总值相对较低,导致“喀斯特贫困”现象的出现。
(3)文化教育水平方面。教育作为人力资本积累的主要途径,在经济增长过程中发挥着重要的作用。从回归的结果中也可以看出,当小学在校学生数提高1个百分点的时候,精准扶贫效率将提高0.237个百分点。国家也在不断增加扶持力度,文化教育情况等相对往年有明显改善,但由于部分地区是多民族聚居的区域,自然环境、历史、地理条件和诸多现实因素的影响,劳动人口文化程度相对较低,思想观念相对落后,适龄儿童辍学率相对偏高。2017年贫困地区劳动力平均受教育年限为7.6年,就业空间和劳动力的流动受到制约,集中连片特困地区农民收入水平仍有待提高。
(4)基础设施水平方面。基础设施薄弱、公共服务(教育、交通、供电、科技、供水、文化、通讯、卫生、体育设施等)不足也是阻碍集中连片特困地区脱贫减贫的重要因素。[30]从回归的结果可以看出,基础设施的建设有利于精准扶贫效率的提高,尤其是通客运班车的自然村比重相对较高,通客运班车的自然村比重提高1个百分点,可使精准扶贫效率提高0.142个百分点,交通的便利有利于劳动力、物质的流动,加快了当地经济的运转效率,给农户生活带来便利的同时增加了就业机会和机遇。但相对于其他地区,片区的交通仍不发达,随着卫生站的增加,人们就医更加便利,在新农合的政策下,看病贵的问题得到了有效的解决。例如2017年,片区自然村能便利乘坐公共汽车的农户比重仅有65.7%,交通的封闭还是在一定程度上阻隔了峡谷居民与外界的交流。
(5)生态环境水平方面。集中连片特困地区的贫困问题与环境之间存在着极大的关系,片区地域辽阔,自然条件复杂,地貌类型多样。以武陵山区、乌蒙山区以及滇桂黔石漠化区为例,三个片区的缺水、缺土问题较为严重。三个片区年降水量往往超过1000 mm,接近北京的两倍,但因众多的喀斯特孔洞就像是无底洞“吸”走了大部分流水,地表上几乎存不住水,地上干旱频发,人们不得不为水源奔波,必须精打细算地利用零散耕地。经过治理,虽然取得了很大的成绩,局部地区生态环境发生了明显的好转,但总体上水土流失、荒漠化、环境污染、水资源短缺、水旱灾害仍较为严重,尤其是环境污染问题仍未根本解决。从回归结果可以看出,污水处理厂数提高1个百分点,可使精准扶贫效率提高0.227个百分点,垃圾处理站提高1个百分点,可使精准扶贫效率提高0.237个百分点,生态环境的改善对精准扶贫效率的提升起到了较好的正向作用。
综上所述,经济发展水平、生产生活水平、文化教育水平、基础设施水平、生态环境水平都在一定程度上对集中连片特困地区的扶贫产生影响,五个主要致贫原因之间也是存在着紧密的联系。在脱贫攻坚的关键期,应理清哪个致贫因素是相对主要的,哪个致贫因素是相对次要的,在解决好主要原因的基础上,再不断解决相对次要的因素。集中连片特困地区的扶贫开发任务相当繁重,需要科学规划、统筹安排、扎实推进。
四、结语
基于集中连片特困地区2011—2017年相关数据,采用DEA-Tobit两阶段模型对集中连片特困地区精准扶贫效率及影响因素进行分析,主要得到以下结论:(1)2011—2017年集中连片特困地区精准扶贫效率总体呈不断上升的趋势,但目前总体水平仍有待提高,同时片区差异较为明显。(2)经济发展水平、生产生活水平、文化教育水平、基础设施水平、生态环境水平对精准扶贫效率的提高起到了正向作用,作用强度总体表现为经济发展水平>生产生活水平>生态环境水平>文化教育水平>基础设施水平。(3)人均生产总值、规模以上工业总产值、粮食总产量、污水处理厂数、垃圾处理厂数对精准扶贫效率影响较为显著,体育馆个数、通客运班车的自然村比重、有卫生站(室)的村比重对精准扶贫效率影响不明显。
