IVMD对泵站管道振动响应趋势的预测分析*
2019-06-25张建伟华薇薇
张建伟, 华薇薇, 侯 鸽
(1.华北水利水电大学水利学院 郑州,450046) (2.水资源高效利用与保障工程河南省协同创新中心 郑州,450046) (3.河南省水工结构安全工程技术研究中心 郑州,450046)
引 言
管道结构普遍应用于水利工程、石油、消防等领域,主要在给水、排水、水力枢纽和各种工业装置中发挥重要作用。管道作为运输载体,在运行过程中受到与其连接设备的振动和内部液体激励等因素耦合作用影响,会出现各种损伤和断裂等问题,导致管道的安全运营受到威胁[1-2]。为了保障管道系统的安全运转,促进其发挥最大的综合效益,对管道的振动预测至关重要[3-5]。近年来,利用动力测试信号对结构工程的振动趋势预测是水利工程的热门话题,对真实信号的获取是振动趋势预测的前提,并将此信号进行泛化拟合回归,从而增加预测值的准确性。
VMD[6]是多分量信号自适应分解的新方法。VMD方法中IMFs的频率及带宽是通过迭代循环求解约束变分问题的最优解得到的。与EMD等传统非平稳信号分解方法相比,VMD的分解过程收敛速度更快,计算精度更高,且分解得到的IMFs能更好地反映管道和机组的振动特性。VMD在信号处理前需要预设分解模态数K,K值过大或者过小都会对振动序列信号分解的准确性造成很大的影响。互信息法表征两个变量的依赖水平,与中心频率和相关系数等方法相比,该方法具有明确的衡量标准,避免了K值选取的主观性,因此,利用互信息准则自适应确定K值。针对小样本、非线性、高维数等问题,支持向量机经实践证明是行之有效的[7]。SVM对模态的识别精度受内部参数影响,采用PSO来搜索其内部参数的最优值,解决SVM中人工选用参数的主观性。
基于上述分析,笔者利用管道与机组之间的相关特性提出了一种改进的IVMD算法,并将IVMD与SVM联合进行管道振动预测。
1 基本原理
1.1 变分模态分解
VMD是一种多分量自适应信号分解的新方法,与传统信号分解方法相比,能够有效避免模态混叠和过分解等缺陷且利用价值较高[8]。VMD方法由建立变分约束问题和迭代求取最优解两个过程组成,具体运算过程如下:利用变分约束将给定信号f分解为K个模态函数mk(t),各个IMF分量的带宽特定有限,且每个模态函数都分布在中心脉动频率周围。变分约束模型表达式[9]如下
(1)
其中:{mk}为分解得到的K个IMF分量,{mk}={m1,m2,…,mk};σ(t)为脉冲函数;{wk}为各IMF分量的中心频率,{wk}={w1,w2,…,wk}。
为完成输入信号f的自适应分解,获取带宽之和最小的IMFs,引入拓展的Lagrange表达式
(2)
其中:α为惩罚因子,确保信号重构的准确性;λ(t)为拉格朗日乘子,用来强化约束的严谨性;〈·〉表示内积运算。
为解决上述变分约束问题,引用对偶分解和交替方向乘子算法[10],一直更新mk,wk与λ(t),使其循环迭代求取式(2)的鞍点,即为式(1)的最优解。模态分量函数mk和中心频率wk如式(3)和式(4)所示
(3)
(4)
(5)
1.2 改进的变分模态分解
VMD在对振动趋势序列信号进行分解时,模态总数K的确定至关重要,K值的选取极大影响结果的准确性[11]。若K值大于信号分解得到有用成分的个数,则会产生信息叠加的情况;若K值小于信号分解得到有用成分的个数,会导致部分有限带宽的固态模量不能完全被分解出来。
互信息(mutual information, 简称MI)反映两个随机变量间的彼此关联性,能更好地辨别两变量的相关水平[12]。互信息表示如下
I(X,Y)=H(Y)-H(Y|X)
(6)
其中:H(Y)为Y的熵;H(Y|X)为X已知时Y的条件熵。
当I(X,Y)=0时,X与Y相互独立。
计算IVMD分解后的各模态分量与原始信号的互信息Ik,并利用式(7)进行归一化处理,进而判断各模态分量与原始信号的相关程度,即原信号是否完全被分解
σi=Ii/max(Ii)
(7)
当σi≤0.02时,认为IMF分量中已不含有效的特征信息,原信号全被分解,停止整个运算过程。
采用互信息法自适应确定K值的具体算法流程如下:
1) 初始化n=n+1,令K=1;
2)K=K+1,执行外层循环;
4) 令n=n+1,执行内层循环;
5) 对一切w≥0,根据式(3)和式(4)分别更新mk和wk;
6) 由式(5)更新λ;
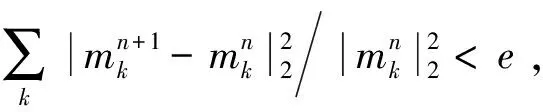
8) 循环步骤2~步骤7,直至设定阀值σ大于原给定信号f分解得到的各IMF与f的归一化互信息值σi,即I(f-∑mk,f)<σ,结束循环。
1.3 支持向量机
SVM[7]利用已知的少量数据,建立合适的数学模型并且保证拥有良好的学习能力,推广性更强。 SVM巧妙地使用了核函数,避免出现过度学习的现象,也不会因为维数过高出现计算过多的问题。结合以上优点,SVM可作为管道科学合理的预测模型。
假设样本集(xi,yi) (i=1,2,…,n;xi∈Rn)表示n维向量,yi∈{±1}为样本输出向量。在线性可分时,构造最优分类超平面(w,x)+b=0,满足将样本集正确分为两个类别,且满足分类间隔。其中支持向量为离分类超平面最近的两种样本向量,计算可得分类间隔之和为2/w,此时得到
(8)
其中:w为权值向量;b为偏移值。
引入松弛变量ξi,将约束降至yi((wxi)+b)≥1-ξi(ξi≥0),定义惩罚参数C来实现ξi的最小化,则目标函数演变为
(9)
为解决约束问题,运用Lagrange函数来求取最优解
(10)
其中:βi>0为拉格朗日乘数。
由式(10)求解得到的鞍点为约束问题的最优解
(11)
(12)
求解式(11)和式(12)得到决策函数为
f(x)=sgn{(w*x)+b*}=
(x∈Rn)
(13)
粒子群算法是由随机解连续迭代求得最优解的过程[13],在搜索参数的过程中具有较强的鲁棒性,且收敛速度快。具体的优化步骤如下:
1) 初始PSO参数,包括种群数目N、迭代的最大次数n、粒子群的初始参数c1和c2、初始速度v和每个初始粒子个体最优位置pi及全局最优位置pg;

3) 分别运用速度公式vid(t+1)=wvid(t)+c1r1(pid-xid(t))+c2r2(pgd-xid(t))及位置公式xid(t+1)=xid(t)+vid(t+1)得到粒子新的速度和位置。重新计算粒子的适应度值并根据适应度值更新pi及pg;
4) 若寻优的迭代次数达到最大,则终止循环过程,得到的群体极值pg为最佳参数,否则循环步骤2。
2 预测模型
为解决其振动响应信号的非线性和非平稳性问题,得到更精确的预测结果,采用IVMD将原始给定信号分解。针对管道复杂的振动特性,利用机组和管道的相关性,建立IVMD-SVM预测模型,其关键步骤如下:
1) 依据原始观测数据,利用IVMD方法分别将机组和管道原始振动信号分解为K个IMFs,作为预测模型的输入样本和输出样本;
2) 分别构造各IMF对应的SVM预测模型,使用PSO搜索各模型参数的最优值并对各分量进行训练预测;
3) 将管道中各拾振器对应的预测结果相加重构得到管道最终的预测值。
3 管道振动预测
以某大型泵站2号管道为研究分析对象,内部均为1200S-56型卧式离心泵的4号机组和5号机组与2号管道的支管连接。两个机组一共设置6个测点,每个机组有3个测点,机组蜗壳顶部设置1个测点,蜗壳尾部左右各1个测点,每个测点位置布置2个拾振器(水平向、垂直向),共计12个拾振器,如图1所示。在管道的主管和两个支管上共选取6个测点,每个测点的x,y,z方向上各放置1个传感器,6个测点水平方向的传感器号分别为1,3,5,7,9,11;垂向传感器号分别为2,4,6,8,10,12,测点布置平面图如图2所示。原型实验研究对象的工况为4号机组稳定运行、5号机组关闭,测试采样时间为900s,采样频率为512Hz。管道的原型观测虽然可以准确反映其真实的振动情况,但是由于所处的环境限制,管道上测点数量较少,无法对所有关键部位进行监测。一般都是依据泵站机组和管道振动的耦联作用以及两者具有的相关关系,采取智能算法来对管道结构进行预测。

图1 机组传感器布置平面图Fig.1 Layout plan of pipeline sensor
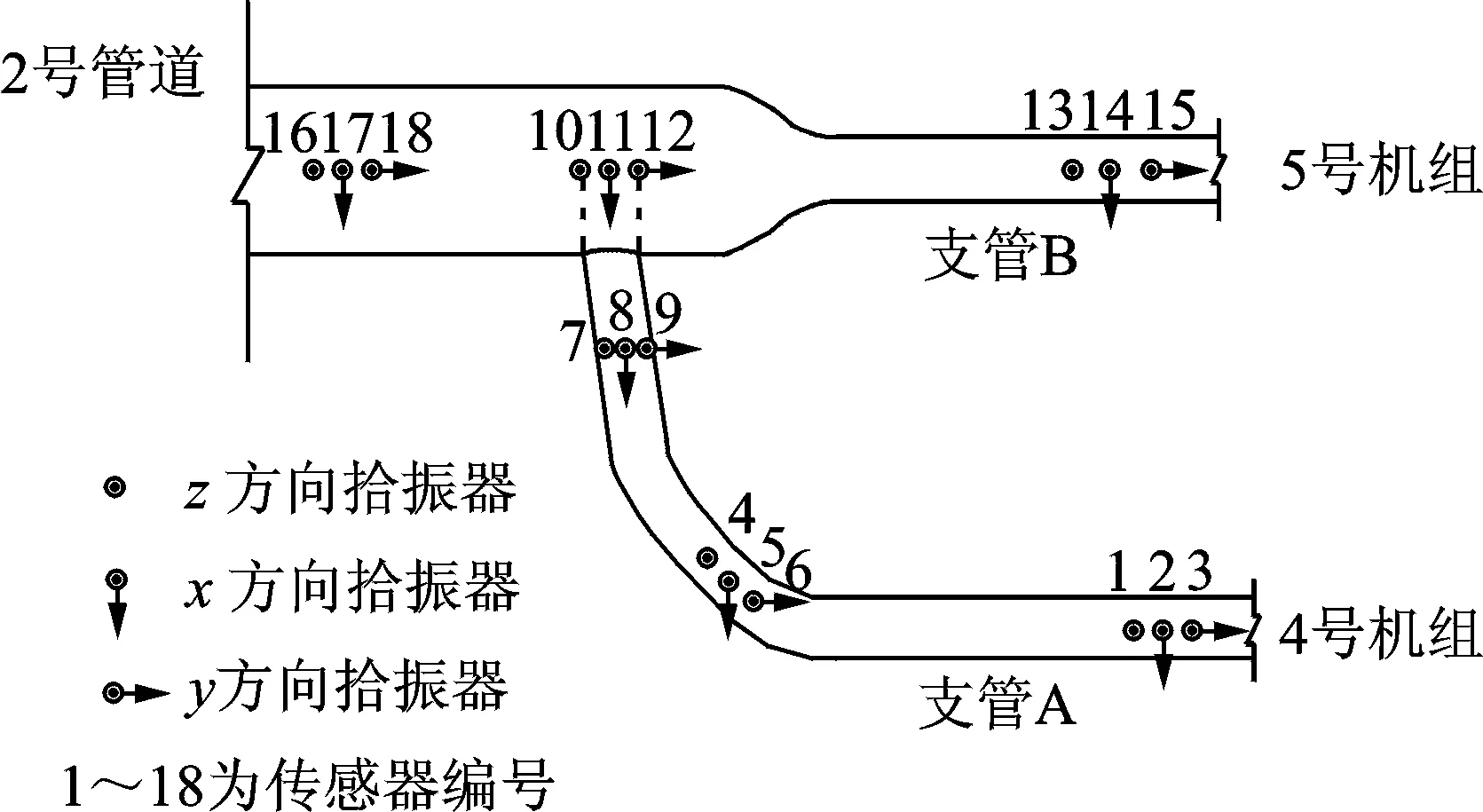
图2 管道传感器平面布置图Fig.2 Layout plan of pipeline sensor
机组与管道的两支管相连,机组在运行过程中产生的振动对管道有很大影响, 管道与机组振动的相关特性通过两者的相关系数来反映。管道与机组6个测点在水平和垂向的相关性系数见表1。由表1可知,6个测点水平方向的相关系数均大于竖直方向且各个测点的值不同,管道的x方向能更好表现振动特征,故选用管道x方向代表管道的平面振动特性并与机组水平方向互相对应。在1,2,4,5,6测点处,两者振动的相关系数均大于0.60,其中最大为0.74;而3号测点所在位置受两端支墩的影响,在某种程度上对振动能量的传播产生了约束,因此在3号测点处,管道和机组的相关系数最小。上述分析表明,机组和管道之间存在一定的相关性,可采用机组振动数据来预测管道的振动趋势。
表1 机组和管道振动相关性系数
Tab.1 Frequency division proportion of pipeline vibration to reach peak in each direction vibration
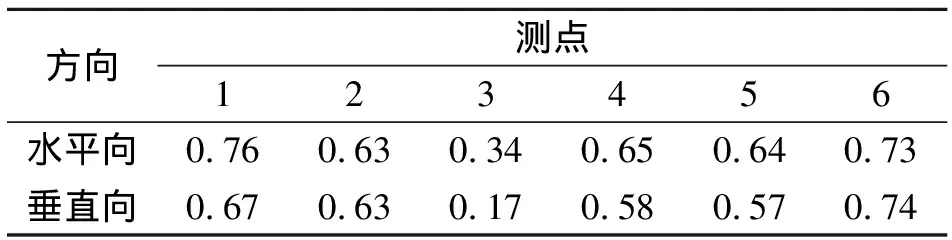
1234560.760.630.340.650.640.730.670.630.170.580.570.74
选择4号机组1~6号传感器振动序列作为输入数据。由表1可知,在6个测点中,1号测点和6号测点处管道和机组的相关系数较大,因此选择管道上1,2,16,17号传感器的振动序列为输出因数。为使预测结果更加全面准确,每隔100个数据点选取50个,机组和管道各选900个数据。
利用互信息法确定出IVMD的模态数K=4,管道和机组的每个拾振器经IVMD分解后各得4个IMF分量。图3、图4为机组和管道1号拾振器振动序列经IVMD分解的模态分量。各个IMF分量与原给定振动序列的归一化互信息值见表2、表3。
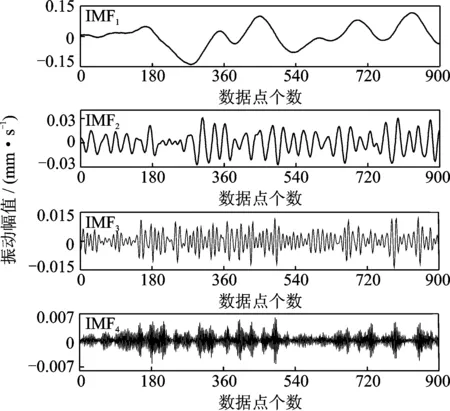
图3 机组1号拾振器振动信号的IVMD分解结果Fig.3 IVMD decomposition result of vibration signal of the unit 1
Tab.2 Each IMF normalized mutual information value of the 1 pickup device of the unit

IMF1IMF2IMF3IMF41.000 00.159 10.063 00.064 0
Tab.3 Each IMF normalized mutual information value of the 1 pickup device of the pipeline

IMF1IMF2IMF3IMF40.528 01.000 00.905 60.840 1
由图3、图4可知,各个IMF分量被较好地分解出来,且波动速率依次增高。由表2、表3可知,4个分量归一化值均大于阈值0.02,满足分解要求。从分解后的各个分量组成的数据中分别随机选取870组作为训练样本,其余30组为预测样本。
构建机组和管道的SVM预测模型,并对分解得到的各个IMF分别进行训练预测。依据大量理论研究和试验数据[14-15],设置模型的初始参数如下:最大迭代次数为200;粒子种群数目为20;初始学习因子C1=1.5;C2=1.7。使用PSO搜索各模型参数的最优值,通过模型进行训练预测,将各测点对应的预测值相加重构得到原始信号的预测结果。
笔者同时采用BP神经网络、PSO-SVM两种模型与本研究方法预测结果进行对比,3种模型的预测值与实测值比较结果如图5所示。

图5 各拾振器3种方法预测结果对比Fig.5 Comparison of predicted results for each sensor between three methods
由图5可知,采用BP神经网络预测模型得到的结果和实测值吻合程度较差,其预测值无法确切反映管道真实的振动趋势。PSO-SVM方法采用PSO搜索各模态分量对应支持向量机模型参数的最优值,避免选取参数的主观盲目性,提升了分类器的精确度,但预测结果与真实值的吻合程度低于笔者提出的IVMD-SVM预测模型。IVMD-SVM方法的预测值与真实值更为接近,较好地反映管道振动趋势,保证了预测精密度,更接近工程要求。
为对振动预测效果进行更直观的定量分析,引入平均相对误差(mean relative error,简称MRE)和根均方误差(root mean square error,简称RMSE)作为预测效果的评价指标[15]。MRE与RMSE的计算结果越小,表明预测成果越理想

由表4、表5可知,IVMD-SVM方法与BP神经网络、PSO-SVM预测方法相比,MRE值和RMSE值都较小,在4个拾振器的预测中都具有更高的精度。分析对比3种方法的误差, IVMD-SVM方法的预测误差最小,这是由于IVMD将原始振动序列分解为相对稳定的单一分量,且这些分量具有一定的规律,预测效果更好。由此说明,IVMD-SVM方法对管道的振动预测具有更高的推广价值。
表4 MRE方法振动效果评定指标对比
Tab.4 Comparison of the evaluation indexes of the vibration effect of MRE method

/%IVMD-SVMPSO-SVMBP11.263.019.921.022.922.6163.827.624.1172.134.727.2
Tab.5 Comparison of the evaluation indexes of the vibration effect of RMSE method
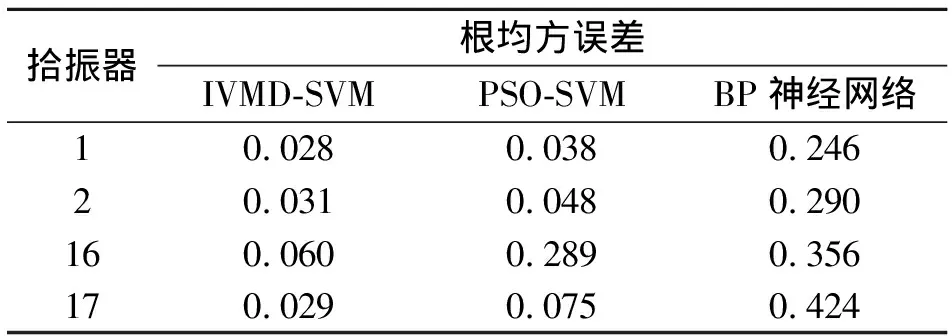
IVMD-SVMPSO-SVMBP10.0280.0380.24620.0310.0480.290160.0600.2890.356170.0290.0750.424
4 结 论
1) 分解模态数K的确定在IVMD方法中占有至关重要的地位。利用互信息法来确定K值,并通过各个IMF分量与原振动信号的归一化互信息值来定量,与中心频率方法相比,互信息法操作简单,计算量小,有一定的衡量标准,避免了K值选取的盲目性。
2) IVMD方法能克服模态混叠现象,并且有效地将原始振动序列分解为K个相应平稳的单一IMF。对分解得到的各IMF分别构造对应的SVM预测模型,并把各测点对应的预测值进行重构,有效避免原始振动序列的非平稳性对预测结果的影响。
3) 将IVMD-SVM方法、BP神经网络和PSO-SVM方法进行对比分析表明,IVMD-SVM方法的预测结果误差较小,且预测值与真实值更为接近,预测精度更高。该方法的提出为管道工程振动及类似流激振动趋势的预测提供一定参考。
