基于R语言的齐普夫信息挖掘
2019-06-20张含阳
张含阳

摘要 本课题以机器人产业领域的数字媒体为采样资料,以R语言编程方法为研究工具,详细探索齐普夫定律对于信息挖掘的理论指导意义,进一步分析出国内数字媒体对于机器人产业发展趋势的关注点。该方法论同样适用于其他产业领域。
【关键词】齐普夫定律 数理语言学 R语言编程 采样 信息挖掘 机器人产业 概率
对于机器人产业来说,通过对于信息资源的数据挖掘工作,我们可以理论化地预测短期内的行业关注点,对于信息资源的采集和编写具有指导性意义,以便更好地为杂志定位,为新媒体的数字信息采集、规划提供理论性指导,同时对产业发展重点也有很强的指导意义。
1 文本采样
为了集中讨论齐普夫信息挖掘对于信息资源的现实性意义,本文选定了10篇知名数字媒体,上发布的有关机器人产业的文章,且文章内容具有较高的代表性。采样文本充分满足产业领域人士的政策性需求、学术性需求与实用性需求。由于齐普夫定律具有广适性,本文研究方法同样适用于除机器人产业外的其他专业领域的问题。
样本源如下:
(1)和讯网(各地政府力推机器人计划,智能制造前景广阔)
(2)网易新闻(想象空间大,机器人板块集体飙升)
(3)新浪新闻中心(学习搞不好的孩子不能搞机器人?)
(4)中国机器人网(美国科学家称未来自主材料能让机器人改变颜色和形状)
(5)新浪科技(智能机器人首次用于三叉神经痛临床)
(6)财富中文网(放一百个心,机器人不会反攻人类)
(7)南方企业新闻网(沈阳获批筹建国家机器人质量监督检验中心)
(8)百度百家(暖男大白背后:靠谱智能机器人3元素)
(9)凤凰财经(巨轮股份机器人产品市场逐步打开)
(10)雷锋网(机器人取代婴儿做研究:姿势很重要!)。
经统计,采样文本全文共19886字,基本涵盖了机器人产业中的各个领域,符合采样应满足的随机性,能够说明结果的准确性。
關于采样文本的切分,最理想的处理是把句子切分成最小、最有意义的语言成份——语素。但是语素和作为最小自由活动的语言片段的词之间,常产生很多难以辨认的文义现象。再则,中文文献的体裁不同、风格各异。
鉴于以上两个因素,本课题做两点解释。
(1)由于计算机无法详细进行语义分析,本课题所做的切分尝试,并非严格按照汉语的语素切分规则进行切分,而是采用计算机初筛加人工细筛相结合的方式。
(2)按最长切分原则,本课题尽量保持词意的独立性,如“机器人”不再切分为“机器”+人”。
2 R语言的应用
2.1 何为R语言
R语言是主要用于统计分析的语言和操作环境。R编程语言由新西兰奥克兰大学的RossIhaka和RobertGentleman创造,被广泛应用在统计和科学领域,在云计算领域处于领先地位。EEESpectrum推出的最流行的编程语言排行榜中,R语言在数据语言中位列第三。2.2利用R语言对采样文本的词语进行概率统计本课题采用R语言对采样文本进行汉语词语切分,同时对词语的出现频率进行统计。本课题采用直接拆分法,分别对采样文本的所有两字词、三字词进行拆分,并逐个比较,比如“机器人产业”的所有二字组合为“机器、“器人”“人产”“产业”,所有三字组合为“机器人”、“器人产”、“人产业”。由于语义混乱的词使用频率很低,因此也就间接对所有语素进行了过滤,如遇特殊情况,我们可人工对排序结果进行筛选。
我们先对双字词进行频率排序,其中采样文本置于F盘下data文档中。
源代码如下所示:
p=scan("F:/data.txt","character',sep="\n");#计算每一行的长度
p.len=nchar(p);
data=p;
#利用标点将文章分成句子
sentences-strsplit(data,"、|,|?|。|、”);sentences=-unlist(sentences);
sentences-sentences[sentences!=""];
#计算句子的长度
length=nchar(sentences);
#将每一一个句子拆分为双字词
divide-function(x,x.len)substring(x,1:(x..len-l),2:x.len);
phrase-mapply(divide,sentences,length,SIM
PLIFY=TRUE,USE.NAMES-=FALSE);
words=unlist(phrase);
#统计频数
words.freq=table(words);
#降序排列
words.freq=sort(words.
freq,decreasing=TRUE);
#显示结果
data.frame(Word=names(words.freq[1:200]),Freq-=as.integer(words.freq[1:200]);
通过以上代码,我们就可清晰地得到该采样文本的双字词频率排序表。通过修改拆分代码,即“divide-function(x,x.len)substring(x,1:(x.len-1),3:x.len);”,我们可以对三字词进行频率排序。
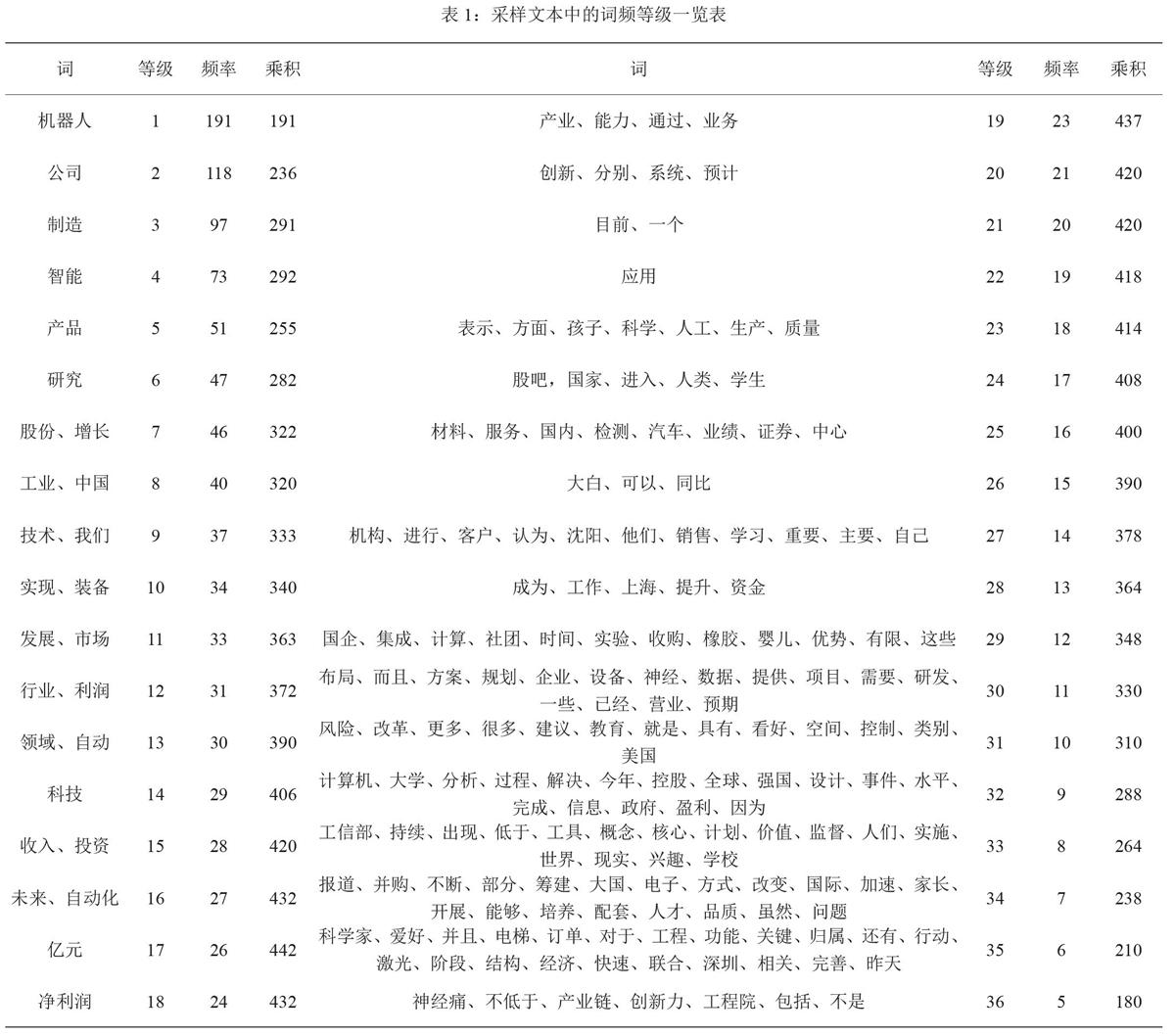
通过以上代码,我们可清晰地得到该采样文本的三字词频率排序表。整理之后,我们便得到了整个采样文本的词频统计表,详细列表见附表1。由于低频词过多,且对该课题的研究价值不大,因此列表中并未详尽列出全部词频等级的词汇。
3 利用齐普夫定律进行信息挖掘
3.1 齐普夫定律的意义
上世纪30年代,美国哈佛大学语言学教授齐普夫(G·K·Zipf)经过对文献集中单词的出现频率进行统计后发现,虽然各个作者使用了不同的写作风格,但是文集中单词的频次与它的等级之间均呈现某种限定关系。齐普夫用文字描述为“最小努力原则”。齐普夫法则是众所周知的数理语言学中的重要法则,这个法则发现了在按频率递减顺序排列的频率词表中,单词的频率与它的序号之间存在某种幂律关系。
齐普夫型分布在社会现象中处处存在,如词语分布、收入分布、地理特征分布、生物种属分布等等。本课题利用齐普夫定律分析信息的深层内涵,正是基于它对社会科学很多实践活动有理论指导作用。文献计量学家海通曾说过,齐普夫定律是解决社会科学分布现象最好的定律。
3.2 齐普夫第一定律
如果把一篇较长的文章中每个词的出现频率按递减顺序排列,并编上等级序号,即频次最高的词等级为1,频次次之的等级为2,......,频次最小的词等级为N。若用f表示频次(frequency),r表示等级(rank),C和α是参数。公式如下:
f=Cr-α
根据齐普夫的研究,凡是高频率使用的词,其价值就较小。同时,低频词不常出现,其词义本身在这个场合中价值比较少,因此传递它们所需要的“力”就不大。因此,最常见且最具有功能的词是居于中间乘积的中频词。经验表明,中频词往往包含大量有研究價值的关键词。那么,本课题的关键就在于如何确定该采样文本的中频词。
齐普夫定律规定,若采用对数轴描绘,中频词的等级直线斜率近似-1。对于上式两边取对数后得到 公式 ,可化简为y=b-kx,即采用对数轴描述的齐普夫第一定律是以-k为斜率的直线。也就是说,当 公式 时,该函数对应的语素为中频词。
3.3 齐普夫第一定律在本课题中的应用
当时,,即中频词的频率与等级的成绩近似为一固定常数。将表1中的数据生成曲线图(以等级为x轴,以乘积为y轴),如图1所示。
我们对该曲线进行多项式趋势线拟合,多项式的阶数为2阶,得到黑色曲线,如图2所示。
通过观察拟合曲线,我们可以看到,等级18可近似视为该凸曲线的拐点,那么该点的二阶导数约为0,即 公式 。由于拐点附近的函数变化率最小,因此等级18附近的点更接近某一固定值。我们取15-22这个区间,令这个区间内的词为中频词。那么,这些词代表着它们所需的“力”最大、最具有研究意义。
经过筛选,我们将本课题采样文本中的中频词总结如表2所示。
4 中国机器人产业新媒体内容的发展趋势
综合分析本课题使用的齐普夫信息挖掘技术,再析回到原文,我们可以得出中国机器人产业相关媒体近期关注的焦点主要在三个方面。
(1)对于机器人产业的经济类的报道主要关注于机器人公司的综合实力,包括营业收入、净利润、业务发展状态。同时,各种投融资机构、基金、股票市场对于机器人产业的行情预测也是各类媒体关注的焦点;
(2)对于机器人产业的方针政策的报道主要集中在提高中国机器人企业的创新能力的制度建设、产业各环节的新政策、新方针;
(3)对于机器人产业的技术类的报道主要关注于机器人领域的自动化或自动控制相关技术、机器人的系统集成,以及机器人产品的应用工程。
5 结语
社会学科研究正在走向定量化的发展方向,整个科学研究群体的特征呈现专业化和综合化之势,单纯凭直觉和经验的信息挖掘将被逐步淘汰,而齐普夫信息挖掘技术就成为了解释各个领域内在规律的最有效的定律。而利用R语言强大的统计分析能力支持齐普夫定律的运用,则使得信息资源的词频与齐普夫分布的拟合实现更快速、更标准的概率化统计,对各个媒体的信息资源挖掘将产生深远意义,对指导产业发展的关注重点提供了一种更精准的方法论。
参考文献
[1]徐文霞.齐普夫定律与中文词频分布机理[J].情报科学,1986(01):29.
[2]刘光牛,南隽,刘滢.中国传媒全媒体发展研究报告[J].科技传播,2010,2-81.
[3]杨霞,吴东伟.R语言在大数据处理中的应用[J].信息技术,2013(10):19.
