适应性回归分析(Ⅱ)
——排除噪声变量的干扰
2019-06-18罗艳虹胡良平
罗艳虹,胡良平
(1.山西医科大学公共卫生学院卫生统计学教研室,山西 太原 030001;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029;3.军事科学院研究生院,北京 100850
1 一个人工生成的数据集
1.1 生成数据的构想
生成包含一个因变量和10个连续型自变量的模拟数据集,样本含量N=400。生成的方法如下:
第一,每个连续型自变量都是从一个均匀分布总体U(0,1)中独立抽样产生的,它们分别被命名为x1~x10。
第二,因变量y仅由两个连续型自变量x1和x2按式(1)计算而得到:
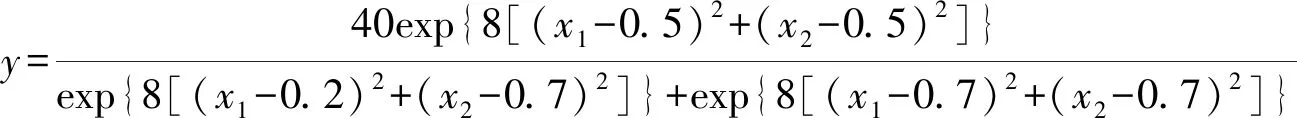
(1)
在给定了连续型自变量x1和x2的每一对数值后,将它们代入式(1),并且,基于标准正态分布N(0,1)添加误差而生成真实模型。把样本含量设定为N=400[1]。
1.2 用SAS生成上述数据的方法
1.2.1生成包含11个变量及其400个观测值所需要的SAS程序
data artificial;
drop i;
array x{10};
do i=1 to 400;
do j=1 to 10;
x{j} = ranuni(1);
end;
y=40*exp(8*((x1-0.5)**2+(x2-0.5)**2))/
exp(8*((x1-0.2)**2+(x2-0.7)**2))+
exp(8*((x1-0.7)**2+(x2-0.2)**2)))+rannor(1);
output;
end;
run;
1.2.2输出数据集前10个观测所需要的SAS程序
proc print data=artificial(obs=10);
var x1-x10 y;
run;
1.2.3 输出数据集前10个观测
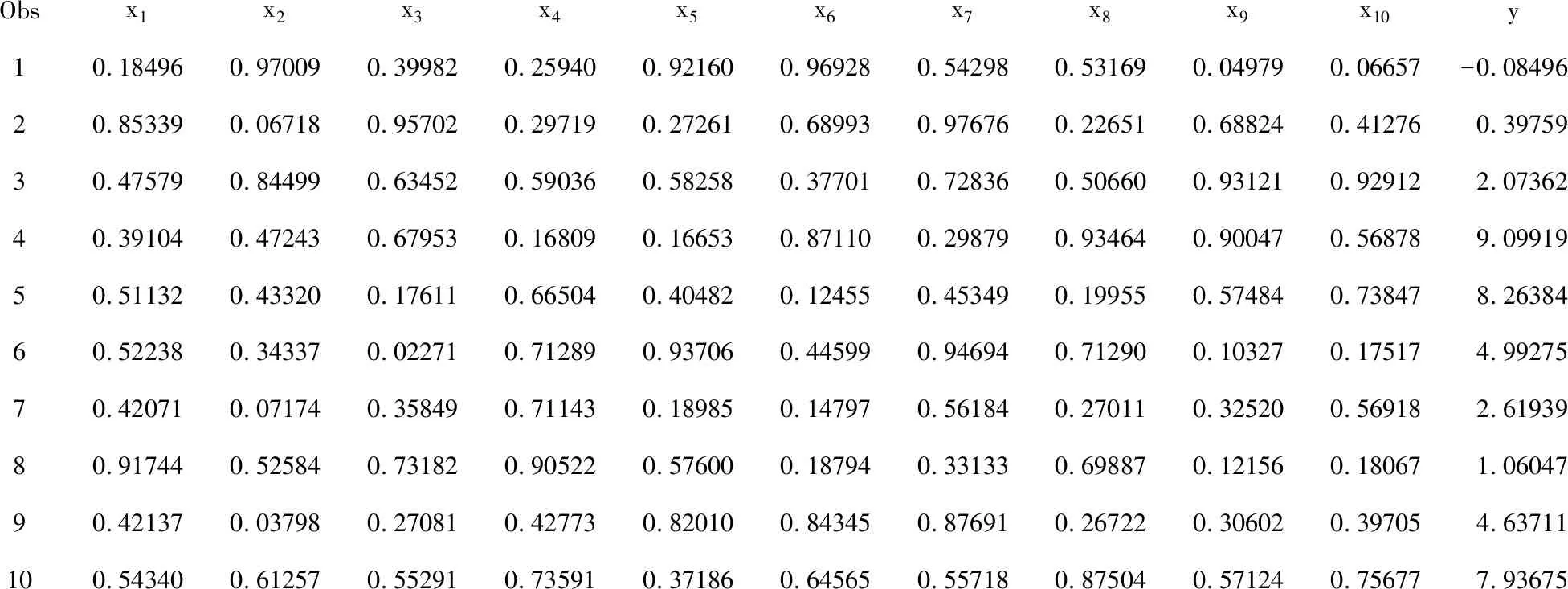
Obsx1x2x3x4x5x6x7x8x9x10y10.184960.970090.399820.259400.921600.969280.542980.531690.049790.06657-0.0849620.853390.067180.957020.297190.272610.689930.976760.226510.688240.412760.3975930.475790.844990.634520.590360.582580.377010.728360.506600.931210.929122.0736240.391040.472430.679530.168090.166530.871100.298790.934640.900470.568789.0991950.511320.433200.176110.665040.404820.124550.453490.199550.574840.738478.2638460.522380.343370.022710.712890.937060.445990.946940.712900.103270.175174.9927570.420710.071740.358490.711430.189850.147970.561840.270110.325200.569182.6193980.917440.525840.731820.905220.576000.187940.331330.698870.121560.180671.0604790.421370.037980.270810.427730.820100.843450.876910.267220.306020.397054.63711100.543400.612570.552910.735910.371860.645650.557180.875040.571240.756777.93675
1.3 数据结构的特点
x1~x10都是在“0~1”之间取值且服从均匀分布的随机变量,它们之间是互相独立的;y是在依据式(1)计算结果的基础上,添加一个服从“均值为0、方差为1”的标准正态分布随机变量的取值(或称为误差)。显然,11个变量都是计量的,且y仅依赖于x1和x2两个变量,独立于“x3~x10”这8个变量。
1.4 回归分析的目的
【实例1】 基于前述的数据集,试建立y依赖于x1~x10的多重回归模型。
【实例2】 基于前述的数据集,试建立y依赖于x1和x1~x10的多重回归模型(即丢弃x2)。
【实例3】 基于前述的数据集,试建立y依赖于x2~x10的多重回归模型(即丢弃x1)。
【实例4】 基于前述的数据集,试建立y依赖于x3~x10的多重回归模型(即丢弃x1和x2)。
2 利用ADAPTIVEREG过程建模[1-2]
2.1 对实例1进行适应性回归分析
2.1.1 所需要的SAS过程步程序
ods graphics on;
proc adaptivereg data=artificial plots=fit;
model y=x1-x10;
run;
2.1.2 SAS输出结果及解释

拟合统计量GCV1.55656GCV R-Square0.86166Effective Degrees of Freedom27R-Square0.87910Adjusted R-Square0.87503Mean Square Error1.40260Average Square Error1.35351
以上为“拟合统计量”的计算结果,模型对资料的拟合优度界值GCV=1.55656;R2和调整R2分别为0.87910和0.87503;均方误差和平均平方误差分别为1.40260和1.35351。
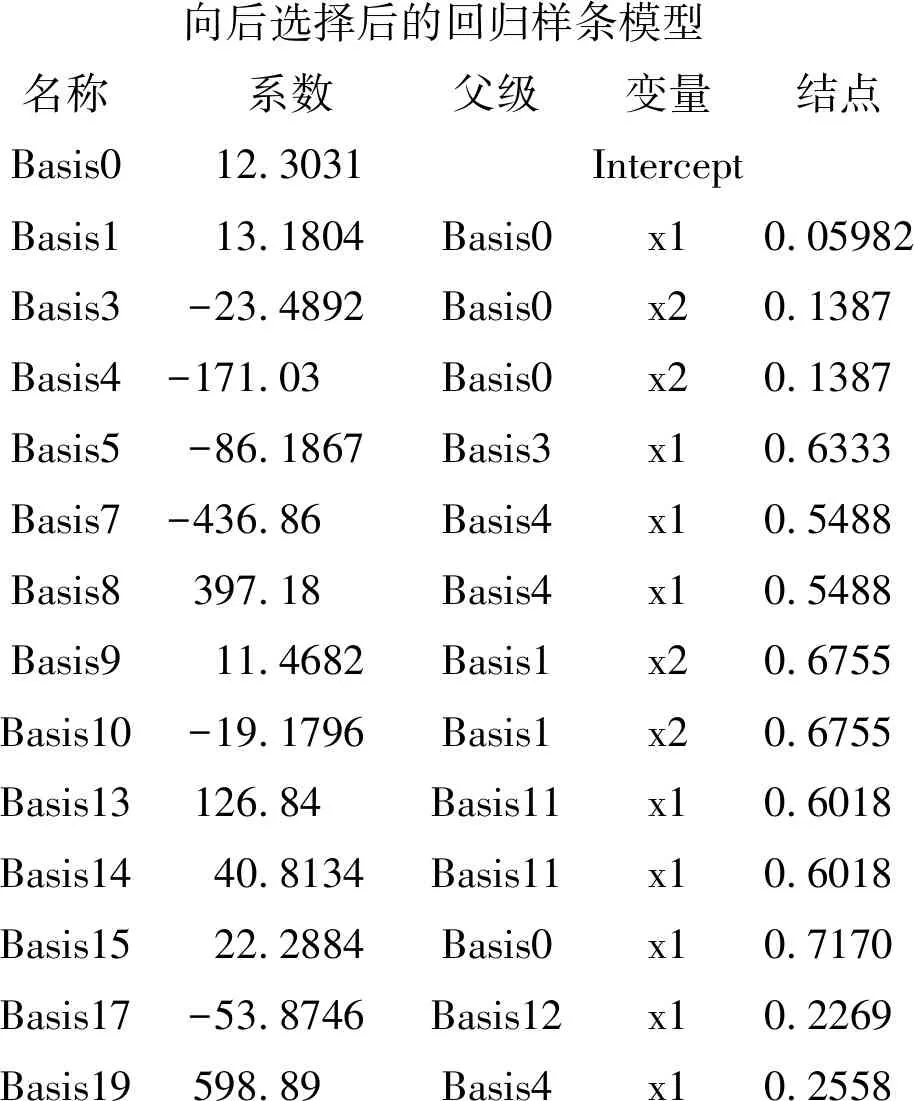
向后选择后的回归样条模型名称系数父级变量结点Basis012.3031InterceptBasis113.1804Basis0x10.05982Basis3-23.4892Basis0x20.1387Basis4-171.03Basis0x20.1387Basis5-86.1867Basis3x10.6333Basis7-436.86Basis4x10.5488Basis8397.18Basis4x10.5488Basis911.4682Basis1x20.6755Basis10-19.1796Basis1x20.6755Basis13126.84Basis11x10.6018Basis1440.8134Basis11x10.6018Basis1522.2884Basis0x10.7170Basis17-53.8746Basis12x10.2269Basis19598.89Basis4x10.2558
以上为“向后选择后的回归样条模型”的计算结果。此结果中涉及到很多“基函数(Basis)”,而基函数中的“元素”基本上只有“x1”“x2”以及由它们以不同的系数联系起来的“交互作用项”。
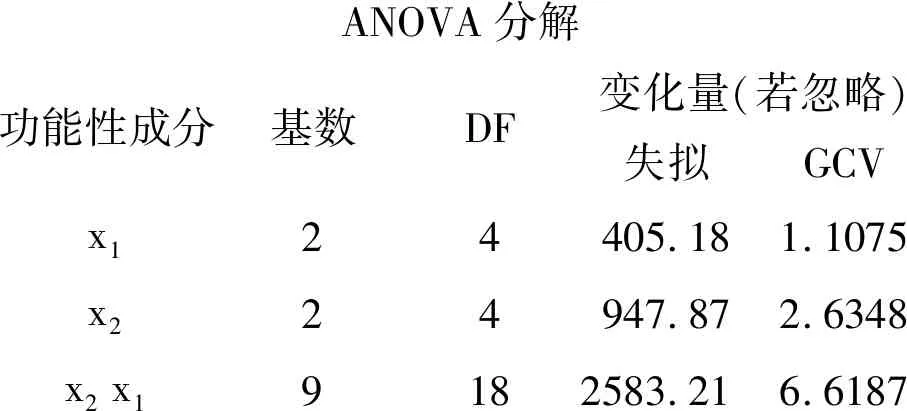
ANOVA分解功能性成分基数DF变化量(若忽略)失拟GCVx124405.181.1075x224947.872.6348x2 x19182583.216.6187
以上是基于“方差分析分解”的算法对所构建的模型进行逐项分解的结果。其中,涉及到“x1”的基函数有2个,占用了4个自由度,其对应的“失拟”LOF=405.18,GCV=1.1075;涉及到“x2”的基函数有2个,占用了4个自由度,其对应的LOF=947.87,GCV=2.6348;涉及到“x1”与“x2”交互作用项的基函数有9个,占用了18个自由度,其对应的LOF=2583.21,GCV=6.6187。
【说明】在上面的输出结果中,最后两列的顶端“变化量(若忽略)”,其含义是:若忽略掉各行上的“项”(第1行为“x1”、第2行为“x2”、第3行为“x1×x2”),将会使“失拟(LOF)”或“广义交叉验证(GCV)”发生改变的数量大小,此“变化量”越大,表明对应行上的“项”对因变量的影响越大。

变量重要性变量基数重要性x111100.00x21199.19
以上结果表明:x1与x2对因变量y的重要性接近相等,分别为100.00%、99.19%。
因变量y关于x1与x2的二次曲面回归模型在二维直角坐标系内以“等高线”呈现出来的图形见图1。
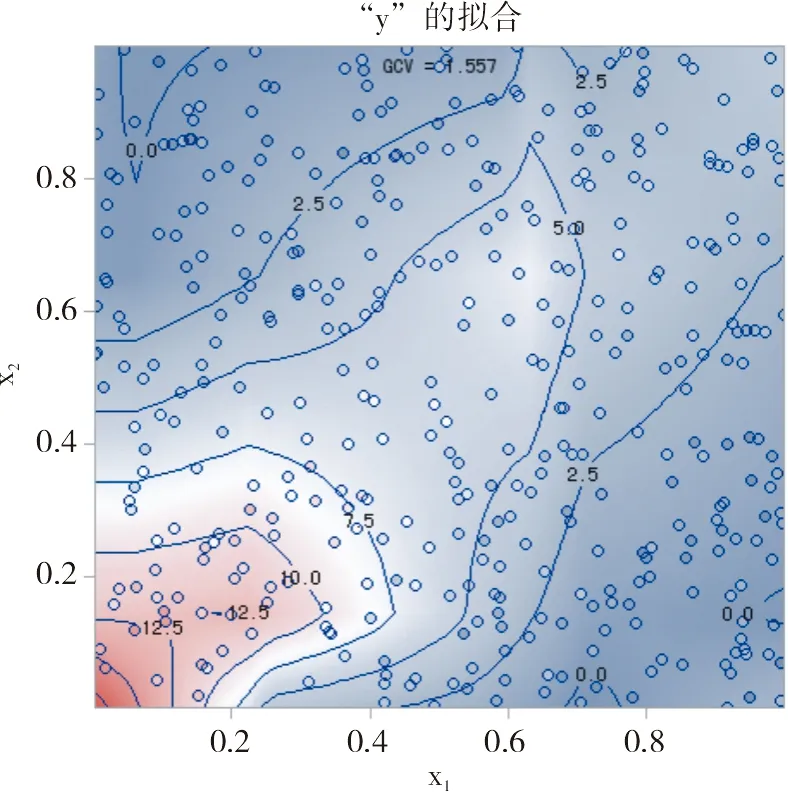
图1 因变量y关于x1与x2的二次曲面回归模型的等高线图
图1是以“等高线”形式呈现式(1)所代表的二次曲面。由于式(1)属于三维空间里的二次曲面,无法采用二维平面图来呈现其立体形状。设想:采用一系列平行于二维平面的“平面”去切割三维空间里的“二次曲面”,所形成的“切口”自上而下沿垂直于纵轴y的方向投影到由(x1,x2)所形成的二维平面上,就出现了图1中的“曲线”。每一条曲线的高度“y”是相同的,故被称为“等高线”。等高线上标注的“数据”(例如12.5、10.0、7.5、5.0和2.5等)代表“切割平面”离“底部二维平面”的“高度”的数值。
由图1中多条等高线的形状可知:式(1)所代表的“二次曲面”比较复杂;若是一个“圆球”曲面模型,则其所有等高线就会形成一系列的“同心圆”。
2.2 对实例2进行适应性回归分析
2.2.1 所需要的SAS过程步程序
在前面的SAS过程步程序的“MODEL语句”中,不写入“ x2即可。
2.2.2 SAS输出结果及解释
下面仅给出最后一部分输出结果:
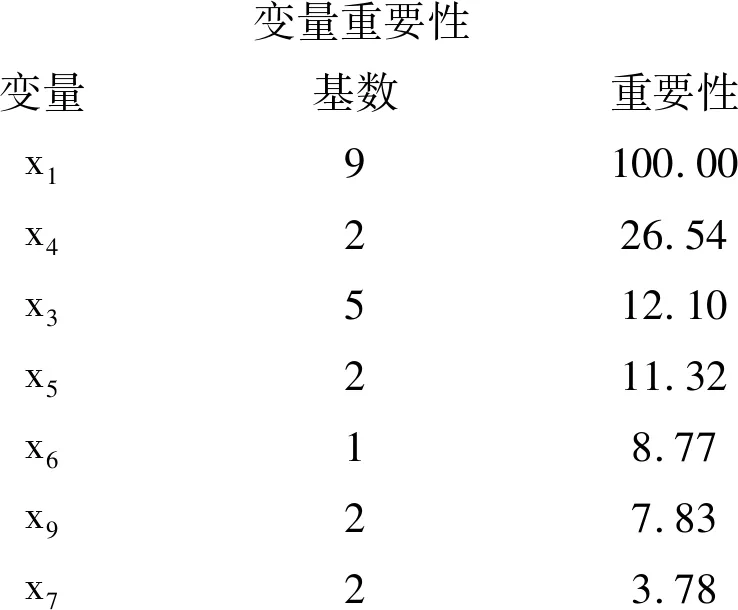
变量重要性变量基数重要性x19100.00x4226.54x3512.10x5211.32x618.77x927.83x723.78
以上结果表明:除x1真正对因变量y有影响外,还得出x4对因变量 有较大的影响;甚至还有x3和x5。而实际上,除x1之外,其他变量对因变量y没有任何影响。
2.3 对实例3进行适应性回归分析
2.3.1 所需要的SAS过程步程序
在前面的SAS过程步程序的“MODEL语句”中,不写入“x1”即可。
2.3.2 SAS输出结果及解释
下面仅给出最后一部分输出结果:
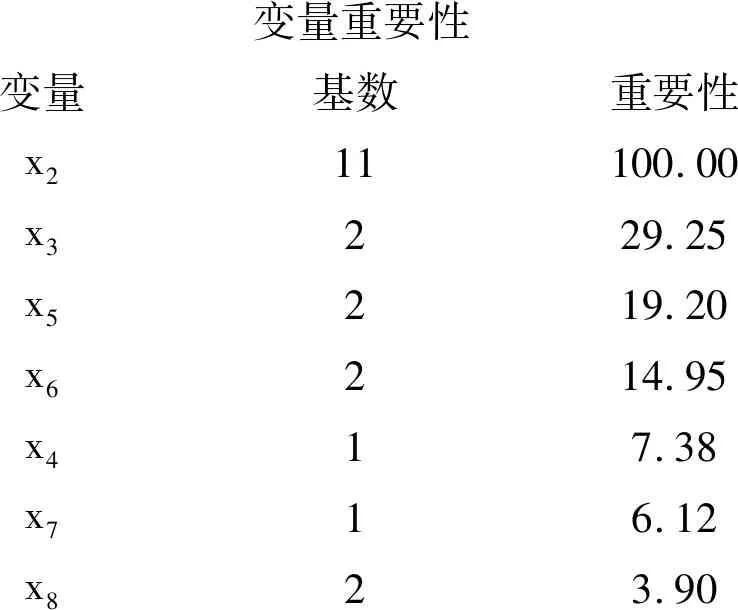
变量重要性变量基数重要性x211100.00x3229.25x5219.20x6214.95x417.38x716.12x823.90
以上结果表明:除x2真正对因变量y有影响外,还得出x3对因变量y有较大的影响;甚至还有x5和x6。而实际上,除x2之外,其他变量对因变量y没有任何影响。
2.4 对实例4进行适应性回归分析
2.4.1 所需要的SAS过程步程序
在前面的SAS过程步程序的“MODEL语句”中,不写入“x1”和“x2”即可。
2.4.2 SAS输出结果及解释
下面仅给出最后一部分输出结果:

变量重要性变量基数重要性x36100.00x4260.87x7242.66x8116.58
以上结果表明:在x3~x10这8个与因变量y毫无关系的变量中,得出:x3和x4对因变量y的影响很大;x7和x8对因变量y的影响也比较大。显然,这个结果是不可信的。
3 讨论与结论
3.1 讨论
基于对“实例1”的分析结果来看,“ADAPTIVEREG过程”对于包含多个“噪声变量”的数据结构具有很强的“甄别能力”,能够“挖掘”出“隐藏”在复杂数据结构中的“真正规律”;而基于对“实例2”和“实例3”的分析结果来看,“ADAPTIVEREG过程”对于包含多个“噪声变量”的数据结构具有较强的“甄别能力”,能够“突显”出“隐藏”在复杂数据结构中的“真正规律”,但也在较大程度上受到了“噪声变量”的干扰和影响;再基于对“实例4”的分析结果来看,“ADAPTIVEREG过程”对于全部由“噪声变量”组成的数据结构不具有“甄别能力”。
通常,真实资料的数据结构是错综复杂的,其是否包含有变量之间的真实数量联系是未知的,比较可靠的做法是依据基本常识和专业知识尽可能找全找准与结果变量有联系的“自变量”和/或“中间变量”,并适当引入由前述提及的那些变量产生的“派生变量”[3-4]。在此基础上,尽可能使收集数据的过程受控于“标准操作规程”和“质量控制策略”[5],确保样本能很好地代表研究总体且具有足够大的样本含量。再尽可能多采用一些统计模型和技术方法去拟合数据,并基于测试数据集评估模型的拟合效果。
3.2 结论
适应性回归样条算法(即由“ADAPTIVEREG过程”来实现)并不是“万能的”,它仅适合于数据结构中确实包含了“具有某种联系的变量集合”,而并不适合于“因变量与自变量之间不存在任何数量联系”的数据结构。
