基于改进卷积神经网络的单幅图像物体重建方法
2019-06-17张玉麒叶立志陈亚松
张玉麒 陈 加 叶立志 田 元 夏 丹 陈亚松
(华中师范大学教育信息技术学院 湖北 武汉 430079)
0 引 言
从二维图像中获得三维信息并恢复三维模型是计算机视觉研究的主要方向之一。基于图像的三维重建在诸如商品展示、文物三维修复、智慧城市建设、医疗器官重建等领域也具有重要的应用价值[1-5]。基于图像的三维重建问题按照重建图像的数量可以分为基于多幅图像的三维重建方法[6-9]和基于单幅图像的重建方法,按照重建的内容可以分为对物体的重建和对场景的重建[10]。本文主要针对基于单幅图像的物体重建方法展开研究。
传统方法按照重建方法的不同可以分为基于模型的重建方法和基于几何外形恢复的重建方法。基于模型重建的方法通过匹配输入图像和模型,找到模型的最佳参数来进行重建。基于CAD模型的方法[11-12],能够大致地展现物体的近似外形,在找到一组对应点后,可以很好地确定相应实例的视点,但是其获得的模型和实际的模型仍然有很大偏差。形变模型(Morphable model)常用来重建人脸部分[13-14],其主要为一些可以变形的线性组合模型,通常由一些三维扫描的设备获取。Cashman等[15]找到了降低三维数据获取门槛的方式,通过三维模型和辅助的二维信息学习到相应的形变模型来重建物体。Vicente等[16]先在图像数据集中匹配一张和输入图像相同类型相似视角的图像,结合了可视外壳的方法,但是其无法应用于真实拍摄的图像。Kar等[17]在Vicente等的工作基础上,通过物体的二维注释来学习相应的形变模型,不但可以重建真实拍摄的图像,在重建效果上也有了一定的提升。基于模型的方法因为存在设计好的模型,对固定类别的物体能够取得相对较好的重建效果,但是无法具有较好的泛化性。基于几何外形恢复的方法主要包括从阴影中恢复外形(Shape from shading)[18-19]和从纹理中恢复外形(Shape from texture)[20-21],基于几何外形恢复的方法能重建较多种类的物体,但其往往对灰度和光照等要求较高,对真实场景的物体图片的重建效果欠佳。
近年来,随着深度学习技术的不断发展,出现了基于深度学习的物体重建方法。Choy等[22]提出了一套端到端的基于体素的重建网络结构(3D recurrent reconstruction neural network,3D-R2N2),与传统方法通过匹配一个最近似的模型并不断优化其参数得到最佳模型不同,3D-R2N2利用大量的训练去学习二维图像和三维模型之间的映射,其无需对图像加入分类标签。在以IoU(Intersection-over-Union)值作为评价指标的对比实验中,3D-R2N2的重建效果优于效果最好的传统方法。但其在重建精度上仍无法达到可以使用的程度,且部分重建细节如桌腿等会存在缺失的问题,相较于二维领域也存在着计算量大、训练时间长的缺点。此外也出现了基于深度学习的点云重建方法[23-25]和网格重建方法[26-28],与传统方法相比也取得了较好的重建效果。
本文采用与3D-R2N2相似的网络结构来做基于体素的单幅图像物体重建,并针对相应模块作出改进。
本文方法具有如下特点:
(1) 针对Encoder模块进行了改进。本文的Encoder模块使用改进的inception-resnet网络结构,并使用全局平均池化来代替全连接层,与3D-R2N2的重建结果相比能够得到更高的IoU值,重建精度更高。
(2) 针对单幅图像信息量少的问题,采用多种网络结构提取多特征并依次输入3D-LSTM模块中,从而增强单幅图像的重建效果。
(3) 与3D-R2N2相比,本文提出的方法具有更低的计算开销。
1 3D-R2N2网络模型
3D-R2N2网络采用监督学习的方式,仅在边界框信息(Bounding boxes)的辅助下,就可以端到端地从单幅或者多幅图像中重建出图像中物体的三维模型。其网络结构由三部分组成:卷积神经网络构成的编码器(Encoder)、三维卷积长短期记忆网络(3D convolutional LSTM)和解码器(Decoder)。
1.1 Encoder模块
Encoder模块将输入的图像转化为较低纬度的特征向量。其网络结构包含了12个卷积层,1个全连接层和5条残余连接(Residual connection)。其中残余连接是在每两个卷积层间添加,为了匹配卷积操作后的通道数,残余连接使用1×1卷积。Encoder模块最终输出一个维度为1 024的特征向量。
1.2 3D convolutional LSTM模块
3D convolutional LSTM模块通过Encoder模块得到的特征向量去更新其中记忆单元的信息。该模块由n×n×n个3D-LSTM单元组成,其中n为3D-LSTM网格的空间分辨率。3D-LSTM单元在空间上分布在3D网格结构中,每个单元负责重建特定部分的最终输出,其都对应最终重建输出矩阵的一个元素(i,j,k),单元中还伴随着一个独立的隐藏状态ht。
1.3 Decoder模块
Decoder模块接收3D-LSTM传来的隐藏状态ht,并将它们转化为体素块存在与否的概率,最终通过得到每个体素块概率的值为0或者1来确认是否重建该体素块。与Encoder模块相同,Decoder模块也由卷积神经网络和相应的残余连接组成,但这里使用了3×3×3的卷积核进行三维卷积,同时在Decoder模块会进行三维上池化(3D unpooling)来对三维信息进行处理。
2 改进神经网络的单幅图像物体重建方法
2.1 对Encoder模块的优化
尽管3D-R2N2的Encoder模块使用了带有残余连接的卷积网络,但仍存在着特征提取效果差导致的重建精度问题。GooleNet[29]首次提出的Inception模块可以一次性使用多个不同尺寸的卷积核,能够让网络自己选择需要的特征,如选择大尺寸的卷积核可以抓取到像素与周边像素之间的关系。同时,Inception模块增大了网络宽度,能够对有噪声的图片提取到更多的深度特征,让含噪声的图片具有更好的泛化能力。受到Szegedy等[30]提出的方法的启发,本文在保存残余连接的同时加入了Inception模块,既能够利用Resnet中的残余连接解决梯度消失的问题,又能够利用Inception模块提取更深更细节的图像特征。本文设计了两种改进的Inception-resnet模块,其中Inception-resnet-A结构如图1所示。

图1 Inception-resnet-A的结构
Inception-resnet-A模块包括3个卷积分支,在第一个卷积分支中将3×3卷积替换为1×3和3×1两种大小的卷积核,这种非对称卷积核能够替代3×3卷积核的同时节省计算量,并提取到更多图像的局部特征。放在3×3卷积核前的1×1卷积用于控制输入特征的通道数。第三个卷积分支使用池化来增加整体的非线性特征。同时模块仍保留着残余连接,整体模块使用较小的卷积核,但能够较好地提取局部特征。
Inception-resnet-B模块采用了更大的卷积核尺寸,5×1和1×5两个卷积核由5×5的卷积核拆分得到,中间分支仅采用了1×1特征用来对不同通道的特征进行统一。该结构能够更好地抓取像素与像素之间的关系。其结构如图2所示。

图2 Inception-resnet-B的结构

(1)
改进后的Encoder模块的网络结构如图3所示。与3D-R2N2相比,网络在层数上没有增加,网络的前四层没有变化,仍使用带有残余连接的卷积神经网络。但是从第五层开始使用了改进的Inception-resnet模块替换了单纯带有残余连接的卷积网络,每个Inception的分支后连接有1×1的线性卷积核,其主要用来统一跳跃连接后的通道维度。输入的图片经过Inception-resnet模块后,再经过全局平均池化的处理,最终输出一个维度为1 024的特征向量。

图3 改进的Encoder模块网络结构
2.2 多特征重建网络
使用不同的Encoder网络结构会得到不同的重建结果,原因在于不同的网络结构的特征提取能力不同,某一种网络结构在特定的特征上表现出较好的能力,但可能在其他特征上表现较差。单幅图像本身就包含较少的信息,如果只使用一种网络结构用作特征提取,则会限制重建的性能。
本文在Encoder模块中使用多种网络结构进行特征提取,采用的网络结构有AlexNet[31]、ResNet[32]、DenseNet[33]以及本文中改进的Inception-resnet,几种网络结构均为现有方法中具有开创性且效果较好的网络结构。在本文提出的多特征重建网络框架中,四种网络结构对同一张图像提取到四种不同的特征,所提取的四种特征分别依次输入3D-LSTM中并进行整合,从而达到模拟多幅图像的重建的过程,进而增强单幅图像的重建效果。多特征重建网络的整体结构如图4所示。

图4 多特征重建网络结构框架
3 实验与结果分析
本文使用Theano框架来实现相应的网络模型。实验在配置有 Intel Xeon E3 1230 V5 CPU(3.40 Ghz),Nvidia GeForce 1080 Ti GPU(11 GB)的硬件平台上进行。
3.1 实验数据集与评价标准
本文采用ShapeNet数据集[34]作为网络训练和测试所使用的数据集。该数据集包括了13个种类共43 783个CAD模型,本文采用数据集中的37 192个CAD模型作为训练集,6 591个剩余的CAD模型作为测试集。
本文采用IoU值,也即网络输出结果与对应真实模型的交叠率作为评价三维重建精度的评判标准。
3.2 网络模型及训练
网络输入的图像大小为127×127,输出体素大小为32×32×32,在网络模型中使用了Adam算法[35]来优化梯度下降过程,加速网络的训练速度,其中的超参数β1值为0.9,β2值为0.999,权重衰减值为5×10-6。LeakyReLU中斜率设置为0.1,初始的学习率设置为了10-5。为了实现实验的公平对照,本文网络的初始超参数值采用了和3D-R2N2一样的设置。多特征重建网络的四种网络结构均采用与3D-R2N2相同的12层。
3.3 ShapeNet数据集实验结果分析
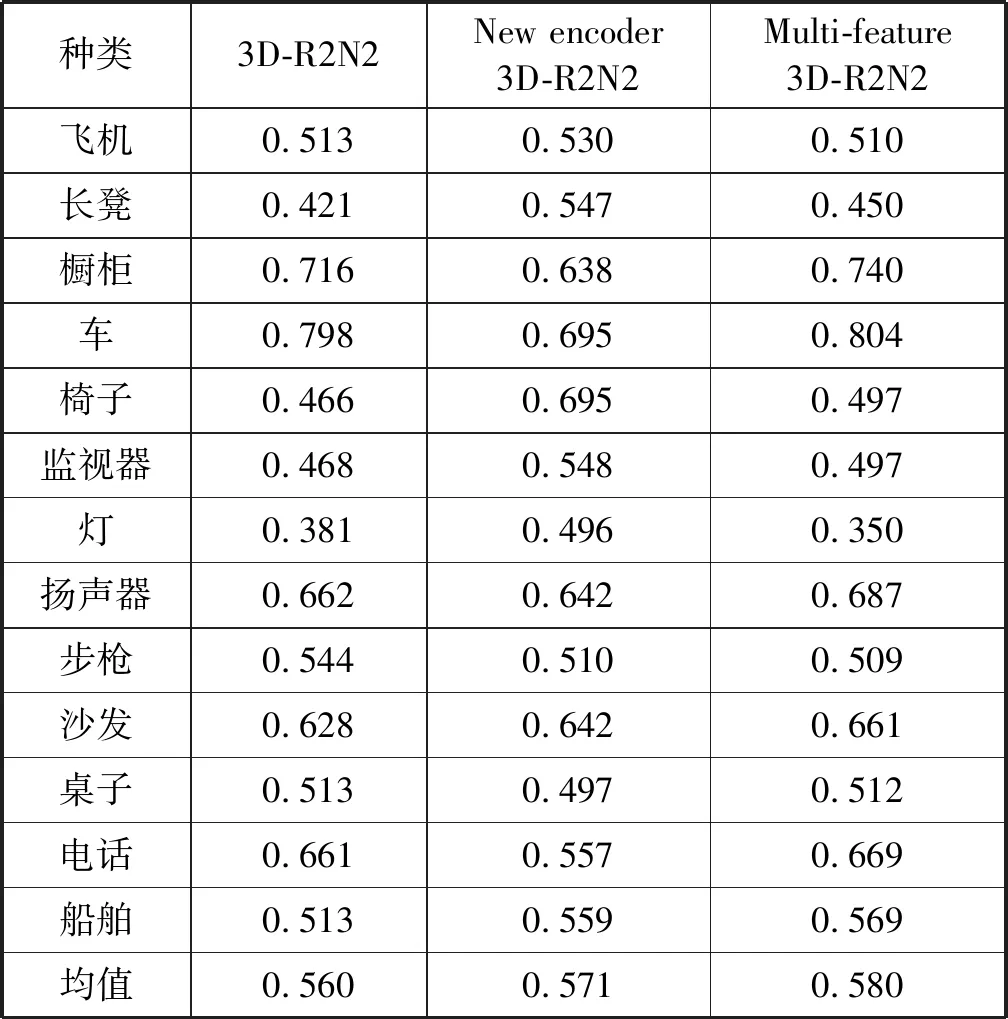
本文针对ShapeNet数据集中13个种类的物体分别进行了实验,并且针对Encoder模块的改动以及多特征重建网络分别做了单一的对照实验,仅使用改进后的Inception-resnet模块的网络称为New encoder 3D-R2N2,使用多种网络结构作为Encoder的多特征网络结构称为Multi-feature 3D-R2N2。表1显示New encoder 3D-R2N2在13个主要类别中有7类的重建效果优于3D-R2N2,Multi-feature 3D-R2N2在13个主要类别中有10类优于3D-R2N2,且两者整体平均重建表现均优于3D-R2N2,该结果证明了本文方法的有效性。实验分析可知,引入改进后的Inception-resnet结构的Encoder模块能够更好地提取图像的细部特征及深度特征,在面对灯、电话等重建细节较多的物体时有相对较大的效果提升。但在面对诸如桌子、橱柜等结构相对简单的物体,其表现反而不如3D-R2N2,这也印证了本文提到的使用不同的网络结构提取特征,会对不同的特征产生不同的表现。而使用了多种网络结构来提取多特征的多特征重建网络,对重建效果的提升则是全面的,仅在飞机、灯和步枪三类上IoU值与3D-R2N2近乎持平,其余10类均优于3D-R2N2。本文将多特征重建网络的重建模型与3D-R2N2进行了对比,其重建模型对比如图5所示。通过模型对比可以看出,本文的重建结果拥有更多细节,重建效果更好。
表1 不同重建方法的IoU值对比
种类3D-R2N2New encoder 3D-R2N2Multi-feature 3D-R2N2飞机0.5130.5300.510长凳0.4210.5470.450橱柜0.7160.6380.740车0.7980.6950.804椅子0.4660.6950.497监视器0.4680.5480.497灯0.3810.4960.350扬声器0.6620.6420.687步枪0.5440.5100.509沙发0.6280.6420.661桌子0.5130.4970.512电话0.6610.5570.669船舶0.5130.5590.569均值0.5600.5710.580

图5 多特征重建网络与3D-R2N2的重建效果对比
3.4 改进的Encoder模块对计算开销的提升
为了验证改进Inception-resnet后的Encoder模块对计算开销的提升,本文仍使用ShapeNet数据集对模型的训练时间及训练模型的参数数量进行对比,其结果如表2所示。

表2 不同重建方法训练时间及参数数量比较
其中,由于全局平均池化取代了全连接层大量的参数,使得参数数量减掉了60%,同时参数的减少也加快了训练的时长,Inception-resnet模块中加入的非对称卷积核也能省去该模块近1/3的训练时间,最终改进的网络结构在训练时间上也有了较大的改善。实验结果也证明了本文所提方法对计算开销的提升。
4 结 语
本文采用类似于3D-R2N2的网络结构,通过使用改进的Encoder模块及结合多特征的重建网络结构,进一步提高了特征的表达能力和网络的优化能力。通过实验对重建的输出模型的IoU值计算,得到的结果证明了本文方法在重建精度上和计算开销上的提升。下一步的工作是添加一些人为设计的结构信息和几何信息作为网络的辅助信息,从而提高该类物体的重建精度。
