基于深度学习和距离度量的行人再识别研究
2019-06-06韦忠亮张顺香梁兴柱许光宇
韦忠亮,张顺香,梁兴柱,许光宇
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
关键字:行人再识别;深度学习;距离度量;局部最大发生特征;交叉二次判别分析
行人再识别,是指利用数字图像处理技术判断在图像或者视频序列中是否存在某一特定行人的技术,利用该技术可以把行人的碎片化的多场景轨迹连接起来[1-2]。例如给定一个已拍摄的行人图像,检索跨设备下的图像是否存在该行人,如图1所示。该项技术主要用于弥补目前社会上大量存在的摄像头的视角局限,可以结合相关的行人检测、行人跟踪等技术,将之应用于视频监控、智能安防等新兴领域。
随着城市建设的发展,城市规模在不断增大,城市人口密度越来越高,监控设备在社会发展中的作用愈加显著,其应用也在不断扩展,图像处理的需求增大[3-4]。在视频监控设备获取的图像中,行人外部特征容易受到其穿着、障碍物遮挡、行人姿态及摄像视角的影响,同时图像的分辨率不一,图像中的光照变换也会给图像中的行人特征提取带来麻烦,使得行人再识别成为计算机视觉领域中极具挑战性的问题。

图1 行人再识别
2006年,在CVPR上第一次提出行人再识别的概念后[5],相关的研究不断涌现。2007年,Davis等人[6]基于信息论提出了相应的距离度量学习算法;2011年,Zheng等人[7]基于概率相对距离比较提出了相应的距离度量学习算法,在其中首次引入尺度学习算法的思想;2013年,Pedagadi等人[8]提出局部线性判别分析算法用于距离度量;2015年,Chen等人[9]依据相似度计算理论提出了一种相似性学习算法;2017年,Zhao等人[10]提出一种显著性学习算法;2018年,Zheng等人[11]提出一种学习不规则空间变换算法用于行人再识别问题。
目前主流的行人再识别方法主要分为三个步骤,分别是图像预处理、特征提取、相似度计算[12],如图2所示。
在现实生活的行人再识别研究中,有一类问题比较突出,那就是雾霾天气对行人再识别带来的影响。在雾霾天气的情况下,由于场景的能见度降低,图像中行人目标对比度和颜色等特征被衰减,随着雾霾浓度的加重,雾霾天气使得大量可供描述行人特征细节的信息被掩盖,致使室外监视系统工作效率降低,对行人再识别问题带来巨大的挑战,因此需要在图像中消除雾霾对图像的影响。

图2 行人再识别处理框架
在图像去雾研究中,新的算法不断被提出。Li等[13]基于图像增强技术采用直方图均衡化算法进行去雾处理;Zhang等[14]提出一种改进的单尺度Retinex算法;He等[15]提出了暗原色先验理论的去雾算法;Dong等[16]基于深度学习设计了一个卷积神经网络用于图像的去雾处理。
本文针对雾霾天气下的图像进行处理,按照图2的行人再识别处理框架,首先采用基于深度学习的DehazeNet[17]对图像进行除雾霾预处理,然后对图像进行特征提取,生成特征相关性矩阵,再使用距离度量进行计算并得到识别结果,对雾霾天气下的行人再识别给予实现,最后基于行人再识别数据集VIPeR进行识别匹配率的比较。
1 基于深度学习的图像去雾
深度学习理论的发展推动了图像处理领域诸如图像分割[18]、图像去噪、图像复原、图像重建等方面的相关研究的进展。在图像去雾方面,深度学习可以将传统图像去雾技术上的特征提取和聚合通过深度网络结合在一起,利用网络结构本身的学习能力来提取图像的特征。
和传统卷积神经网络不同,DehazeNet是一个经过特殊设计的深度卷积网络,在传统的去雾算法基础上,利用深度网络学习雾霾特征,可以有效的解决手工特征设计的困扰。
DehazeNet的第一层采用“卷积+Maxout[19]”的结构来提取有雾图像的特征。Maxout可以看作是在深度学习网络中加入的一层激活函数层,在前馈式神经网络中,Maxout的输出取该层的多个全连接层同一位置的神经元的最大值。基于Maxout,DehazeNet的第一层被设计如下

在图像去雾处理中,为提升不同尺度下特征的鲁棒性,在去雾算法中可以采用不同尺度的滤波器(例如最小值、均值、中值)来处理,在多个空间尺度上密集地计算输入图像的特征能产生更高效的结果。GoogLeNet中的inception结构就采用这样的处理方式,使用了平行卷积操作,即同一张图用不同尺度的卷积核进行卷积。借鉴于此,DehazeNet采用 3组不同尺度(3×3、5×5和 7×7)的滤波器来实现尺度鲁棒性,因此,DehazeNet的第二层的输出为
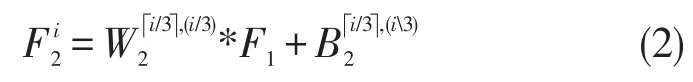
在深度卷积神经网络中,局部极值(MAX Pooling)通过选取邻域最大值来实现空间的不变性,约束了透射率的局部一致性,这样做可以有效抑制透射率的噪声。DehazeNet的第三层采用了局部极值操作:

其中Ω(x)是以x为中心的f3×f3邻域,n3是第三层的输出维数,其值和第二层的输出维数n2相同。卷积神经网络里的最大池化处理通常会降低特征映射的分辨率,和它不同的是,对每个特征映射的像素采用局部极值操作,能够很好的保留处理后的图像分辨率。
在深层网络中常用的非线性激活函数有Sigmoid和线性整流函数 ReLU(Rectified Linear Unit)。前者计算量大,很容易就会出现梯度消失的情况,从而导致网络训练中收敛缓慢。为了克服梯度消失的问题,ReLU在近些年来被广泛应用,其在梯度下降上比Sigmoid有更快的收敛速度,然而,ReLU专为分类问题而设计,并非完全对图像恢复重建等回归问题适用。特别是当大的梯度流经过ReLU单元时可能会导致神经元在以后任何数据节点不再被激活,经过此单元的梯度将永远为零,ReLU单元不可逆地在训练数据流中被关闭,这就导致了响应溢出。在神经网络的最后一层,因为要对图像恢复,输出值应该处于一个包含了上下限取值的小范围内。DehazeNet原创性的提出双边纠正线性单元(BReLU),既保持了局部线性,又保持了双边的限制。基于BReLU,最后一层设计如下

这里W4={W4}包含一个大小为n3×f4×f4的滤波器,B4={B4}表示单位偏差,tmin、tmax是BReLU的边际值(在DehazeNet实现中取值分别是0和1)。引入先验信息后,双边约束可以缩小参数的搜索空间,因此深度网络更易于训练。而根据公式(4),该激活函数的梯度可以表示为

上述四层级联在一起形成基于卷积神经网络的可训练系统,完成图像去雾的处理操作。使用DehazeNet进行图像去雾处理的效果如图3。

图3 DehazeNet图像去雾处理效果
2 基于距离度量的行人再识别
基于距离度量,行人再识别研究的主要内容包括行人的特征提取和距离度量学习两个方面[20],具体来说就是:(1)提取鲁棒性的特征映射来解决不同视角的行人外观变化的问题;(2)设计具有高匹配率的距离度量来衡量行人图像之间的相似性问题。
2.1 局部最大发生特征
在特征提取方面,局部最大发生特征算法对目标图像的颜色特征和纹理特征进行提取。颜色特征可以很直观的表示出目标图像的表观颜色,这里采用HSV颜色直方图来提取颜色特征。纹理特征是一种反映目标图像中同质化现象的视觉特征,体现了物体表面共有的内在属性,这里采用SILTP纹理直方图来提取纹理特征。
特征提取的方法,采用将预提取特征的人物图像划分为六个水平条带,并在每个水平条带中单独提取其颜色和纹理的特征。这种提取方式在视角不变的情况下取得了很好的效果,但是也可能会导致空间结构信息的丢失,从而影响其匹配率[21]。而不同摄像机下的行人通常具有不同的视角,例如图1中的行人在CameraA中是正面,而在CameraB中是以侧面的形式出现,这就导致行人再识别难度的增大。为了解决这个问题,解决的方法是使用滑动窗口的方式对行人图像进行特征提取,图4展示了特征提取的简要过程。

图4 LOMO特征提取示意图
对已经归一化的128×48图像,划分成6个水平条带,使用10×10像素大小的子窗口、步长为5个像素滑动提取图像的局部特征。在每个子窗口中,提取两个SILTP不同尺度的直方图以及一个 8×8×8-bin的联合 HSV 直方图。为了降低视角变化的影响,在同一个水平条带上,扫描所有子窗口,取所有直方图相同bin中出现的最大值作为该水平条带的直方图特征。多尺度特征能有效改善图像复原、分类以及目标检测等相关任务的效果,通过对原始128×48图像进行两次局部平均池化操作进行下采样,得到两张分辨率是64×24和32×12的图像,和原始图像一起构建一个三尺度的金字塔表示,来进一步处理多尺度信息。重复上述特征提取过程,通过连接所有计算的局部最大发生特征的次数,一张行人图片能够提取 26 960 维((8×8×8+(34)×2)×(24+11+5))的特征数据。最后,应用对数转换来抑制较大的特征值。由于只使用简单的HSV和SILTP进行特征提取,所以该特征提取方法在执行过程中很有效率。
2.2 交叉视角二次判别分析
在行人再识别的过程中,由于多种因素(例如图片成像的视角不同、尺度信息不一、光照强弱变换、服饰与姿态变化、分辨率的高低以及是否存在遮挡)的影响,不同设备采集的图像之间可能会丢失关键性的特征信息,在度量行人特征相似度的时候,使用欧氏距离、巴氏距离等传统的距离度量方式并不能达到很好的效果。因此,有学者提出通过基于度量学习的方法,该方法一般在进行距离计算时采用马氏距离(Mahalanobis Distance)[22]进行,使得待识别的图像中行人的特征距离在不同图像中小于其与其他人的距离。
在马氏距离的表示中,样本xi和xj的马氏距离可定义为

其中M表示进行马氏距离度量的度量矩阵。
Roth等提出KISSME算法[23],该算法定义所有类内样本对和类间样本对的差向量均满足高斯分布,类内训练样本对和类间训练样本对可以分别计算出均值向量和协方差矩阵。对于选定的样本对,分别计算该样本对属于类内样本对的概率和该样本对属于类间样本对的概率,用其比值表示两个样本之间的距离,并把该距离变换成马氏距离的形式,而马氏距离中的矩阵正好等于类内样本对高斯分布协方差矩阵的逆矩阵减去类间样本对高斯分布协方差矩阵的逆矩阵。
因此可以根据两个高斯分布的对数似然比来推导出相应的马氏距离,由此得到的距离函数可以表示为
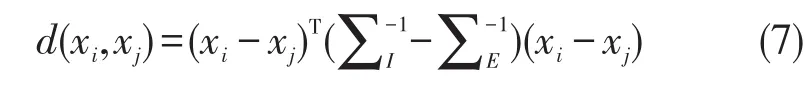
其中∑l和∑E分别表示类内样本差异的协方差矩阵和类间样本差异的协方差矩阵,因此度量矩阵M就可以由∑l和∑E来表示。
Liao等提出的XQDA算法[24]是对KISSME算法在多场景交叉视角下的扩展。原始特征矩阵的维数d通常很大,采用相应的技术对原始特征矩阵降维有利于对特征进行分类,该算法在原始特征的基础上学习样本数据的子空间W=(w1,w2,…,wr)∈Rd×r,并且同时在r维子空间中学习相似性度量的距离函数用于交叉视角的相似性度量。考虑子空间W后,距离函数在r维子空间可以表示为

其中∑′l=WT∑1W,∑′E=WT∑EW,所以计算马氏距离的问题就转化为学习一个核矩阵的问题。然而在这个过程中由于该核矩阵中包含了两个逆矩阵,直接优化dw变的很困难。为了得到一个具有区分能力的目标子空间W,即类内方差小,类外方差大,因此得到以下的优化函数

将这个优化函数进行最大化,得到

3 实验
3.1 实验数据集
在行人再识别研究中,VIPeR数据集是使用最为普遍的数据集,其中有632个行人,每个行人有两个视角且成像视角差距较大,一共包含1 264幅图像。数据集中所有的图像都已做好分辨率的归一化处理,具有相同的大小,其分辨率值为128×48。通过人工合成雾图完成对VIPeR数据集的处理,方式定义如下

其中,G(x)表示原VIPeR数据库中的图像,H(x)表示雾霾噪声图像,表示雾霾噪声图像所占比率,取值范围在0到1之间。处理后的部分数据集效果图如图5所示。
3.2 实验结果与分析
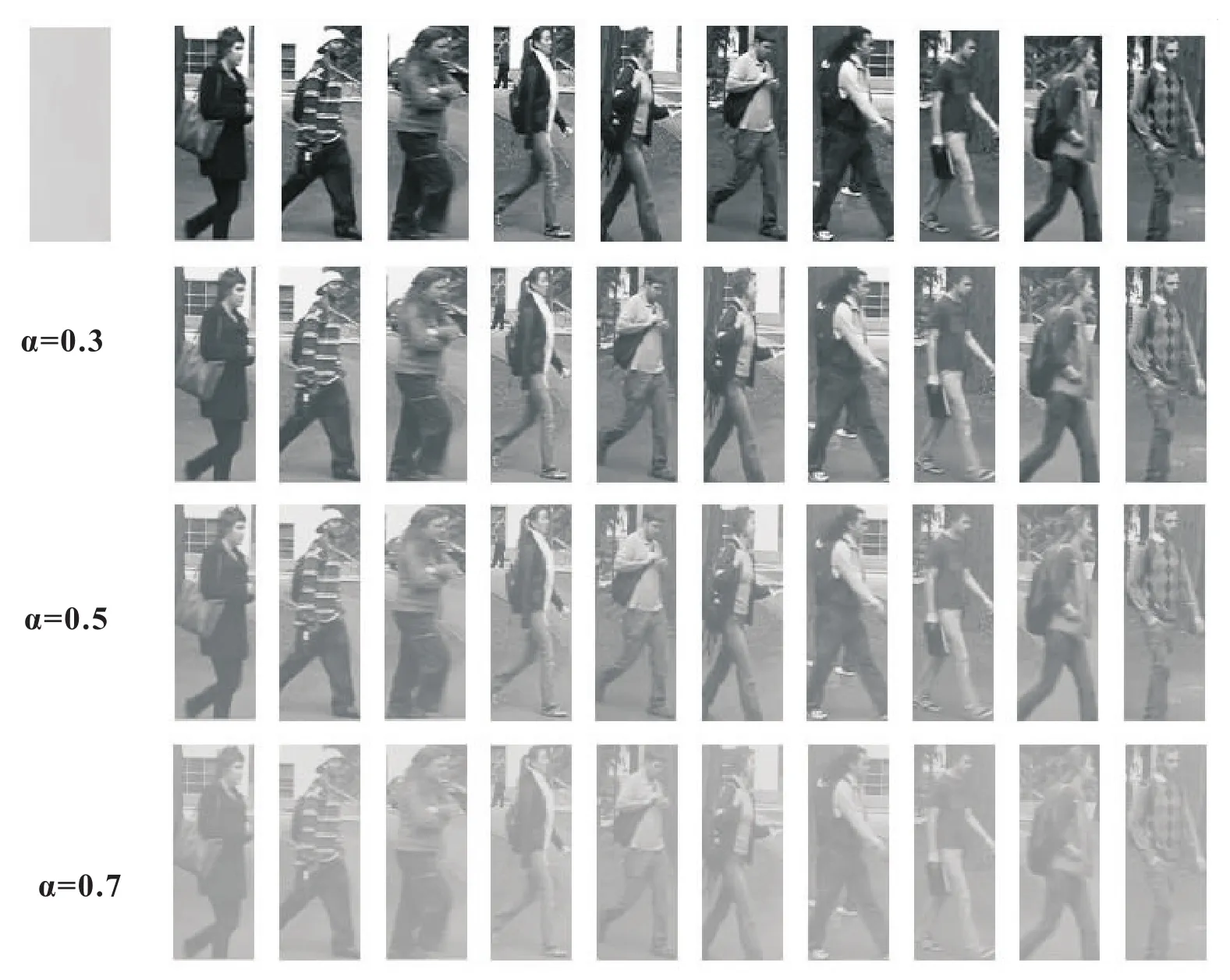
图5 VIPeR数据集部分合成雾图
本实验在VIPeR数据集及其改进数据集上进行,并在所有数据集上采用累积匹配特性曲线及其匹配率排名对本文算法进行平均性能评估,得出的 Rank1,Rank5,Rank10,Rank15,Rank20 的数据如表1所示。
Liao的方法在参数α=0时取得,作为比较的基线,随着合成雾霾图像中雾霾的比率增大,其识别率在逐步下降,例如在α=0.3、α=0.5和α=0.7时,其Rank1的匹配率分别为34.27%、28.61%和19.75%,Rank10的匹配率分别为77.53%、71.71%和59.68%,Rank20的匹配率为89.30%、85.25%和73.67%。总体而言,随着雾霾的加重,其匹配率下降的幅度较大。
本文的方法是在行人再识别操作第一步的图片预处理中,增加了去雾霾处理,随着合成雾霾图像中雾霾的比率增大,其识别率也在逐步下降,例如在 α=0.3、α=0.5和 α=0.7时,其 Rank1的匹配率分别为35.19%、33.54%和30.27%,Rank10的匹配率分别为79.02%、78.51%和73.29%,Rank20的匹配率为90.16%、89.30%和85.54%。在不同的rank中,其识别率高于同等条件下Liao的方法,而识别匹配率的降幅则低于未作去雾霾处理Liao的方法。更直观的去雾前后的对比数据如图5。
实验表明对于雾霾天气情况下的行人再识别,随着雾的浓度增大,本文的方法可以取得更好的效果。

表1 本文算法匹配率列表/%
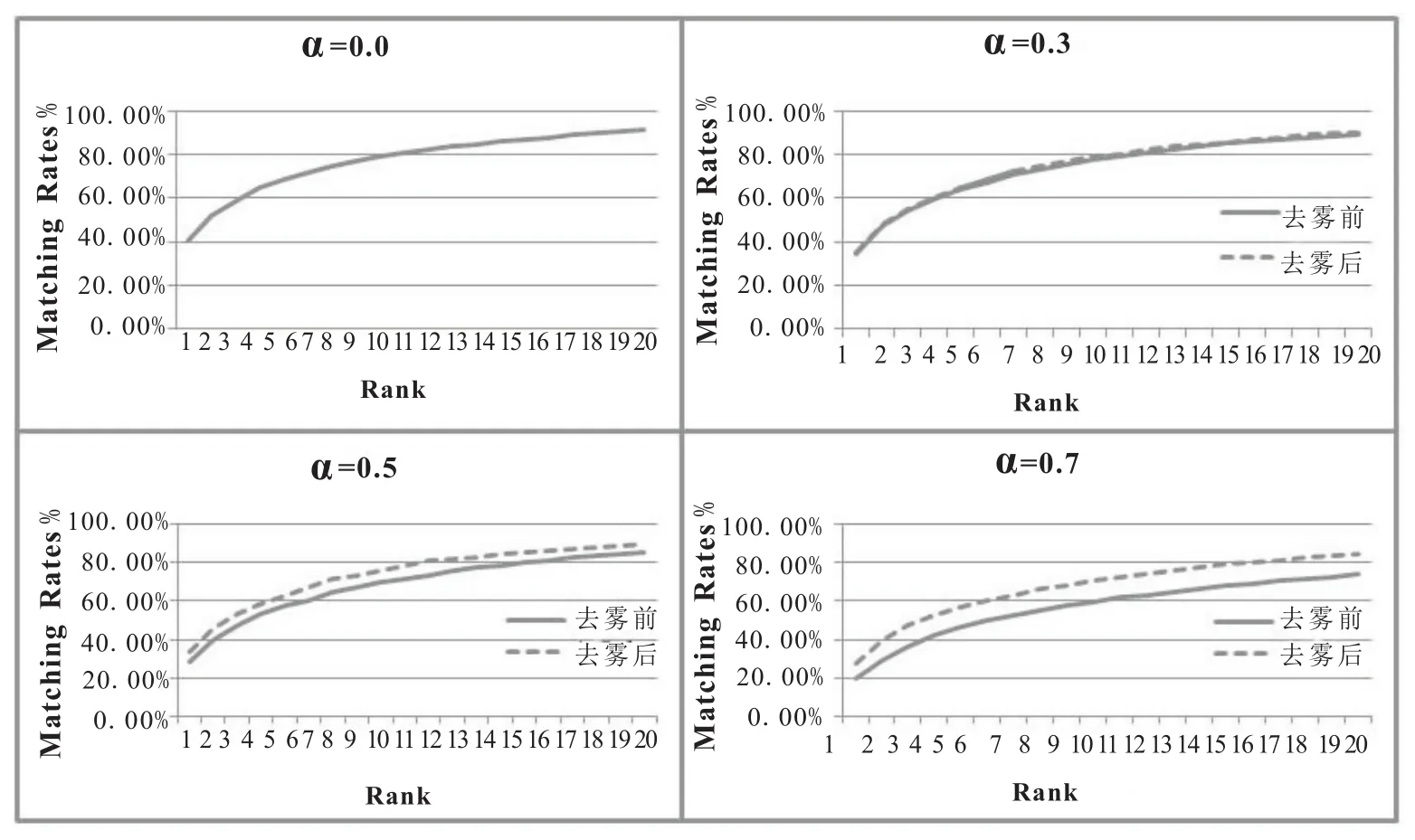
图6 去雾前后的匹配率对比
4 小结
在恶劣天气尤其是近些年来多发的雾霾天气环境下,行人再识别研究面临着很大的挑战,因为雾霾会掩盖图像中的特征细节,给行人再识别的特征提取模块中增加了很多的困难。针对上述问题,在行人再识别处理框架对图像的预处理中,增加基于深度学习的图像去雾处理,在VIPeR及其改进的数据集中进行实验,匹配率得到了较好的改善。行人再识别问题是一个复杂的问题,雾霾天气下的研究只是其中的一部分,遮挡、光照变换等因素也在影响着再识别的匹配率,下一步的工作还需结合更多因素来完善行人再识别的研究。
