基于词间距和点互信息的影评情感词库构建
2019-06-06王侨云朱广丽张顺香
王侨云,朱广丽,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
虚拟社交平台已成为人们彰显个性、发表观点和获取信息的重要平台,社交平台的评论信息更是用户在做选择时的一个重要参考依据。电影评论便是生活服务社交平台的一项重要数据,因为它直接反映了观众观影后对电影剧情、特效、演员、音效的评价和观影感受,不仅可以帮助想要观影的用户迅速了解一部影片的口碑,还可以让投资方根据观众反应适时调整宣传和投资策略、合理调整排片率以达到利润的最大化。因此如何快速有效的对电影评论进行情感分析,判断出电影评论的情感倾向性已成为近年来文本情感分析研究的热点之一。
情感词典的覆盖度是影响情感分析准确度的一个重要因素[1]。然而,中文词语不仅语义丰富而且复杂多变,这使得构建特定领域的情感词库变得相对困难。因此,目前尚未出现专门的电影领域情感词库。一个涵盖范围广、情感极性准确的中文电影评论情感词库应考虑到:如何选取出覆盖度广、情感强度大和区分能力强的种子词集;如何提高语义相似度计算的准确性使得未知极性的影评领域情感词可被更为准确赋予情感极性值。
本文提出一种基于词间距和点互信息的中文影评情感词库构建方法,并构建了影评情感词库。具体情感词库构建流程如图1所示。
1 相关工作
分析用户产生内容的隐含情绪状态、态度和意见是情感分析的主要任务[2]。而基于语义进行文本情感分析的基础和判定标准是情感词典的构建[3]。词典构建的主要工作是将适用一定范围的情感倾向明显且情感极性已知的词语聚合,为后续的情感分析奠定基础[4]。根据人工在词典构建中参与程度不同,词典构建方法可分为人工构建和自动构建两种方法。
第一,人工构建情感词典的方法是利用现有的情感资源结合前人总结的情感资源进行人工标注和扩充。徐琳宏等采用人工进行情感分类的方法构建了较为权威的情感词典——情感词汇本体[5-6]。Wu等考虑词在用户之间的分布来计算候选词在用户间出现的频率,通过手工获得微博的新词构建了适应微博语料的情感词典[7-8]。王勇等对获取的网络用词进行正负向情感强度标注,同时还加入了否定词词表和表情符词表,构建了相对完善的微博领域情感词典[9]。Zhang提出了一种基于微博话题构建情感词典的方法。人工构建了包括基本情感词典、程度副词词典、否定词词典、网络词词典、表情词词典、关系连词词典,实现了基础情感词典的丰富化[10-11]。

图1 面向中文影评的情感词库构建
第二,自动构建情感词典的方法包括基于语料库的方法、基于知识库的方法和基于知识库与语料库相结合的方法。谢松县等提出了一种基于混合特征的中文情感词典扩展方法,将连词语言特征和词性特征向量统计特征进行综合,自动构建了情感词典,提高了基础情感词典的覆盖面[12]。马秉楠等提出一种基于社交网络中特殊情感符号的跨媒体多情绪情感词典构建方法。将图片与短文本内容相结合,自动筛选构建了基于社交网络的情绪词典[13-14]。周咏梅等以HowNet作为基础情感词集,利用上下文熵、TFIDF和SO-PMI算法形成基础情感词典和微博网络用语情感词典[15-16]。Fang等依据汉语短语的特点结合sigmoid函数,设计了七个具体公式分类计算复合情感短语的情感强度,构建了具有词语情感极性和情感强度的情感词典[17]。Do提出了加权tweet频率方法,利用基于知识和翻译的方法来扩展种子集,构建相应的情绪词典[18]。王志涛等基于内部耦合度和邻字集信息熵发现新词,针对不同领域构建了词典[19]。
2 种子词集选取
首先需对爬取的10 000条豆瓣影评进行预处理,再以情感词汇本体作为基础情感词典结合语料中的词频,选取合适的种子词集,因种子词集是后续构建影评领域情感词表的基础,所以我们所构建的种子情感词集必须具有以下3个特点,一是具有较高的覆盖度即需是常用的有代表性的词;二是区分度高、种子词间的相似度低;三是情感极性强度大。本章节将基于这三个要求对基础情感词典和语料库词层层筛选直至筛选出较为理想的种子词集。
为了确保种子词集具有较好的覆盖度的同时具有较大的情感极性强度,本文将先统计基础情感词典中正(负)向情感词语在影评语料库中的频率;再结合情感词汇本体中标注的情感强度计算出情感词的频率强度(frequency-intensity,FI),筛选出数值较大的1 000个(正负各500个)词语;接着对其使用K-means++聚类算法进行聚类筛选出最终的正负种子词集。选取正向种子词集的基本流程如图2所示,负向种子词集的选取也类似。
(ⅰ)统计情感词i词频及情感强度。首先手工统计词语i在影评语料中的词频,再通过查阅基础情感词典获得i的情感强度。词语i来自大连理工大学提供的中文情感词汇本体库,该词典共收录27 466个情感词,情感词的情感极性可分为正向词、负向词和中性词三种(0表示中性词、1表示正向词、2表示负向词),情感极性强度包括5个层次(1、3、5、7、9)数值越大强度越大。为了方便后期的计算,我们将极性强度改为权值,中性词赋权值为0,负向词的权值为负数,正向词的权值为正数。具体基础情感词典的示例如表1所示。
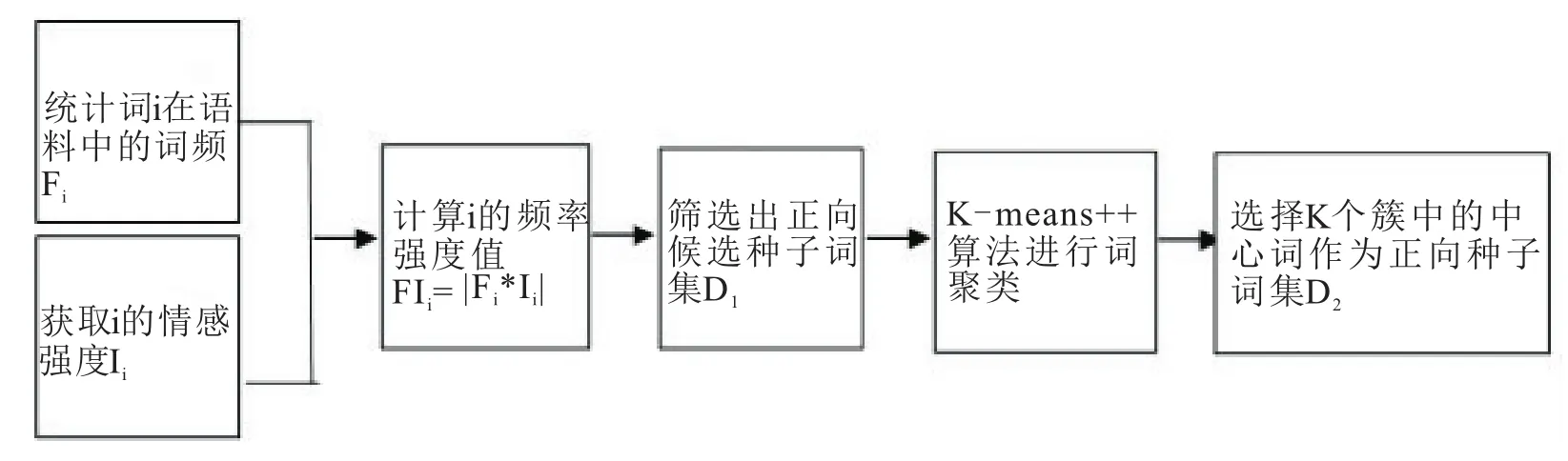
图2 选取正向种子词集的基本流程
(ⅱ)计算情感词频率强度。判断一个词语是否可以作为种子词语,首先要考虑的是其在语料库中的覆盖程度,其次要考虑其情感极性的强弱。当一个词语在语料库中频繁出现且具有较强的情感极性时,就认为它可以作为候选种子词,所以给出了如下定义:
定义1频率强度FI用于衡量情感词i在语料库中的频率和情感强度,通过如下公式计算:

表1 基础情感词典的示例

其中Fi表示情感词i在整个影评语料库中出现的频率,Ii表示情感词i的情感强度。
(ⅲ)词聚类。词聚类是对候选种子词集进行筛选得到最终的种子词集,本文采用改进后的K-means++算法,用点互信息来计算词语间的语义距离d。K-means++算法对初始化质心进行了优化,克服了K-means算法聚类时收敛慢的缺点。经过词聚类我们最终将选择K个簇的中心词作为种子词,词聚类算法可描述如算法1所示。
算法1主要包括两个部分,第一部分为顺序语句,第二部分除了顺序语句外主要包括了一个循环语句。

算法1:K-m e a n s++词聚类算法输入:候选正向种子词集D1={w1,w2,……,w m},聚类种类K,最大迭代次数N输出:K个种子词1:初始化K个簇中心2:从D1中随机选择一个词作为第一个聚类中心u1 3:i f词w i在词集D1中,计算它与已有的聚类中心的最近语义距离d(w i)4:选择新的数据点且d(w i)较大的词作为新的聚类中心5:重复3和4直到选择出K个聚类中心6:e n d i f 7:进行聚类8:f o r(n=1,2,……,N)9:{将簇划分C初始化为C t=∅,t=1,2,…,k1 0:对于i=1,2,…,m,计算词语w i和各个质心词语u j(j=1,2,…,k)的语义距离d ij,将w i标记最小的d ij所对应的类别λ i。此时更新C λ i=C λ i∪{w i}1 1:对j=1,2,…,k,对C j中所有的样本点重新计算新的质心u j1 2:如果所有的K个质心向量都没有发生变化,则转到步骤1 3 1 3:e n d f o r 1 4:输出簇划分C={C1,C2,…,C k}1 5:e n d
(i)初始化K个簇中心,即Step 2~6,以确定K个初始化的质心,其中两个词语的语义距离d(wi)采用点间互信息进行计算,计算公式如下:

其中P(wi,uj)表示词wi和词uj同时出现在一个影评的概率,p(uj)表示词uj单独出现的概率,P(wi)表示词wi单独出现的概率。
(ii)对候选种子词集D1进行聚类,即Step8~16,用于将候选种子词集划分为K个簇,取K个簇的中心词为种子词集。
为了降低实验难度和复杂度,本文最终将K确定为30。最终选取的正向情感种子词集{好,不错,幽默,惊喜,完美,紧凑,精致,善良,甜蜜,痛快,鲜明,火爆,酣畅,优美,鲜活,精湛,睿智,悲壮,感动,平实,美妙,清晰,朴实,亲切,完整,有趣,美好,清新,强,喜欢}和负向种子词集{枯燥,失望,气愤,矫情,沉闷,血腥,难受,混乱,讽刺,扫兴,单调,惊悚,发怒,吐槽,晕死,懊恼,难看,沉郁,不屑,不满,斥骂,窘迫,揪心,哀切,恐怖,激愤,心疼,可恶,憋闷,愤懑}。
3 构建影评领域情感词库
本文采用的构建情感词库的方法是基于语料库的方法,主要利用未知情感词在语料库中与种子词的共现信息以及在《同义词词林》中的上下文信息进行语义相似度计算[21]。本文利用基于词间距离的点互信息(distance of word point-wise mutual information,DW-PMI)算法处理共现信息进行初次语义相似度计算;若出现未知情感词共现稀疏问题,则利用原子词群与种子词集的共现信息进行语义相似度计算;最后将构建出影评领域的词语情感词典结合基础情感词典共同构建影评领域情感词库。语义相似度的计算流程如图3所示。
3.1 基于词间距点互信息计算未知词情感倾向
互信息是用于衡量两个元素之间关联程度的变量,早期仅用于信息论中,现今随着自然语言处理技术的发展,互信息的计算公式也常被用于情感计算中,通常被用于计算两个词语间的语义相似度,两个词语间的语义相似度计算方法如公式2所示。可以看出传统的点互信息仅考虑到两个词语的共现频率但未考虑两个词语间的共现距离,根据汉语的语义用法规则,不难发现在同一句话中语义相似度高的词一般在句中相距较近,因此本文提出了基于词间距离的点互信息计算方法。通过定义词间距离来提高点互信息的精确度,定义如下:
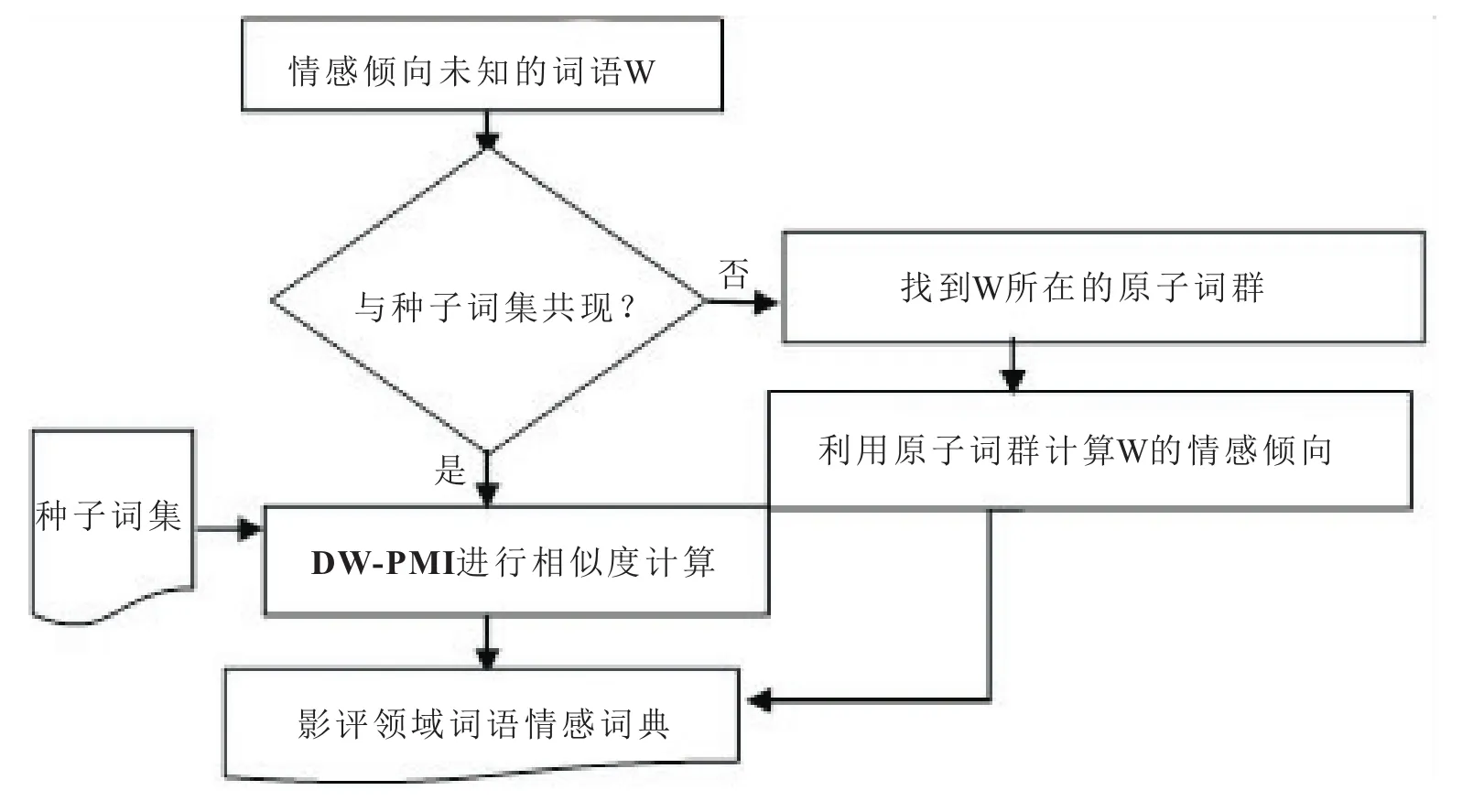
图3 语义相似度的计算流程
定义2词间距(distance between the words,DW)用于衡量两个词语在一条影评中的相对距离,计算公式如下:

其中posi和posj分别表示词语i和词语j之间的词间距。
定义3DW-PMI用于计算两个词语间的语义相似度。计算公式如下:
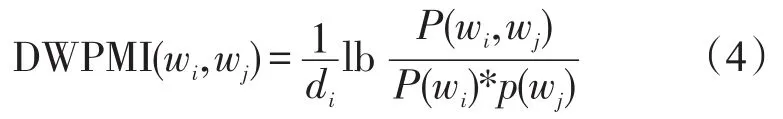
其中P(wi,wj)表示词wi和词wj同时出现在一个影评的概率,P(wj)表示词wj单独出现的概率,P(wi)表示词wi单独出现的概率,di表示两个词语间的词间距。
如果两个词语间的点互信息较大,则两个词语间的相似度较高,词语相似度大于0.5则认为两个词语具有相同的情感极性,小于等于0.5则认为两个词语具有相反的情感极性。为了提高精确度,必须计算wi与种子词集中每一个词语之间的点互信息之和,wi的情感倾向判别公式如下:
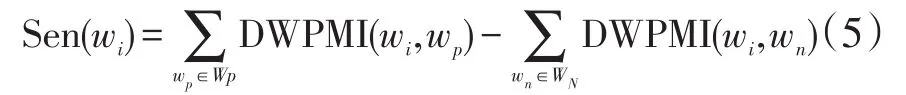
其中Sen(wi)为wi的倾向值,Wp和WN分别表示正向种子词集和负向种子词集,表示wi与正向种子词集中的每个词DWPMI数值之和,表示wi与负向种子词集中的每个词DWPMI数值之和。当Sen(wi)的数值为0时,wi的情感倾向为正;数值小于0时,情感倾向为负向;数值大于0时,情感倾向为正。对于没有共现种子词的未知情感词,我们将基于《同义词词林》对其进行语义相似度计算。
3.2 基于《同义词词林》计算未知词情感倾向
利用互信息进行情感计算时往往会出现共现稀疏的问题,即在语料库中找不到与未知情感词共同出现在同一条影评的种子词,针对以上问题,本文利用未知情感词在《同义词词林》中原子词群与种子词的语义相似度平均值代替未知情感词自身与种子词集语义相似度的方法来解决共现稀疏问题。原子词群处于同义词词林5层结构中的第5层,是词义不可再分的原子类或原子节点,可用于同义词替换。
利用互信息进行情感计算时往往会出现共现稀疏的问题,即在语料库中找不到与未知情感词共现的种子词,本文将利用《同义词词林》中未知情感的原子词群与种子词集互信息的均值替代未知情感词与种子词集的互信息,其计算公式如下:

其中Sen(wi)表示wi的情感倾向值,J表示wi的原子词群,M表示wi的原子词群词语总数。构建影评领域情感词库算法如算法2。
通过算法1和算法2在10 000条影评领域进行情感词库构建,共得到了800个词语,正负面情感词各400个。
4 实验及结果分析

算法2:基于词间距影评情感词库构建算法输入:待标注词语集{wi},极性已知种子词集{wj},《同义词词林》原子词群输出:影评领域情感词集{wi}1:for每一待标注词语w1∈{wi}2:if每一与w1在同一条影评中词w2∈{wj}then 3: 依据词间距离点互信息计算公式(3)进行语义相似度计算4: 依据公式(4)计算数值的正负判断w1的情感极性值5:else 6: 找到w1在《同义词词林》中的原子词群J7:依据公式(5)计算数值的正负判断w1的情感极性值8:end if 9:将w1加入到集合{wi}10:end for 11:end
4.1 实验数据
编写程序调用豆瓣影评API,采集两部热门电影影评,每部电影3 000条,去除只有标点符号、没有任何内容以及3星的影评(3星影评情感倾向模糊,不宜进行情感标注),最终筛选出的影评数据集如表2所示。

表2 影评数据集/条
4.2 实验方法
本文从豆瓣网中获取热门影评进行实验,具体实验操作如下:
Step1:获取影评数据。采集两部热门电影影评,去噪后筛选出有利于情感分析的影评。
Step2:影评情感倾向标注。对获取的所有影评采用机器标注与人工标注相结合的方式进行情感倾向分类。
Step3:构建中文影评情感词库。利用本文提出的基于词间距和点互信息的方法构建中文影评情感词库。
Step4:对获取的影评进行情感分析。采用有监督的基于词典的情感分类方法,简单的对影评中出现的情感词积极和消极的极性值进行累加和归一化,然后判定整条影评的情感极性值,并计算出分类的正确率。
为了验证所构建的情感词库的有效性,我们将实验结果与基于大连理工大学提供的中文情感词汇本体库进行实验的结果进行对比。
4.3 实验分析
根据上述的实验步骤,本文做了如下实验:
实验一:用基于情感词典的情感分类方法分别基于本文构建的影评情感词库和大连理工大学提供的中文情感词汇本体库对爬取的影评评论集1进行正负情感倾向二分类,并计算出分类的正确率P。具体实验结果如图4所示。
实验二:结合本文构建影评情感词库对影评评论集2的2 957条影评进行情感分类。最后将实验结果与中文情感词汇本体库的结果进行比较,具体实验结果如图4所示。
由图4可以得到不同词典情感分类性能,基于本文构建的影评情感词库进行两次实验得到的
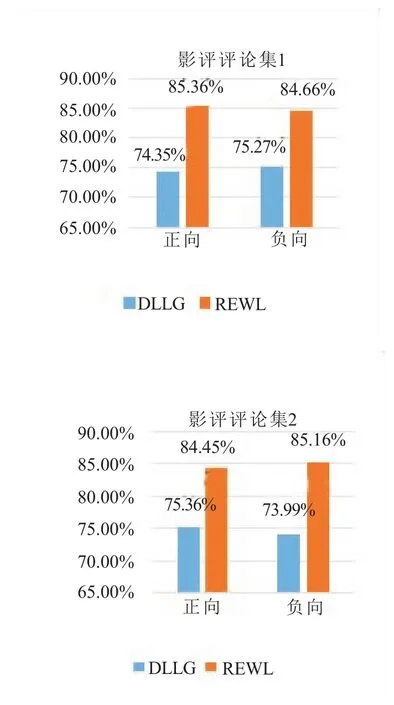
图4 影评情感分类结果
正负分类准确率均高于基于大连理工大学提供的中文情感词汇本体库进行实验得到的结果,本文构建的影评情感词库在影评领域的词语覆盖面较广,进行影评情感分析效果更好。说明本文构建影评情感词库在进行影评情感分析方面能提供有效的帮助。
上述实验表明,进行文本情感分析时,仅仅使用基础情感词典是不够的,还要针对不同的领域构建专门的情感词库。本文基于词间距和点互信息构建了中文影评情感词库,通过上述的实验,证明了该方法构建的情感词库是有效的。
5 小结
针对如何构建影评领域情感词库,本文提出一种基于词间距和点互信息的语义相似度计算方法。该方法主要是结合语料库和基础情感词典对种子词集进行扩充以构建中文影评领域的情感词库来提高影评情感分析的准确度。本文提出了种子词集的选取算法并构建了中文影评情感词库。实验结果表明本文方法明显提高影评情感分析的准确度。将来基于词间距和点互信息的中文影评情感词库构建也可以为其他的相关研究,例如商品评论情感词库的构建、微博话题情感词库的构建提供方法借鉴,以提文本情感分析的准确度。
