基于LCS的应急决策文本相似性比对分析模型*
2019-06-05盖文妹邓云峰
徐 可,盖文妹,邓云峰
(1.中国地质大学(北京) 工程技术学院,北京 100083;2. 中共中央党校(国家行政学院),北京 100089)
0 引言
近年来,各种突发事件频繁发生,给人类社会造成了严重的伤亡、损失和恶劣的影响[1]。作为应急管理的“大脑”,应急决策是应急管理过程至关重要的一环。同时,这种决策大多发生在各级指挥部的小范围内,在极少数情况下就由指挥部的核心成员甚至就是最高首长临机决断决策[2],这些决策往往通过决策文本的各种形式下发,通过对决策主体所制定决策文本的研究分析,就能较好地把握决策主体对相关形势的判断、态度以及接下来工作方向的指导和偏好。
对于危机情境下的高层决策文本分析,国内外对此的研究不多。国内外的研究主要集中在制度文本分析的方法与理论框架,如Yamashiro, Daniel K.M.分析了在国家危机时期宗教对美国总统外交政策决策的影响[3];美国国家总评估办公室 (The U.S.A General Accountability Office,GAO) 提出的内容分析法这种定性分析方法[4],以及国内很多学者提出的制度文本分析框架[5-6]。总体来讲,有关制度文本分析的研究已有大量文献,但针对危机情境下高层决策文本分析的研究文献相对较少,已有的文献大部分是关于重大事件决策的影响因素的研究[7-8],也有文献对突发事件中的相似度计算进行了相关论述,但主要是集中在突发事件的匹配度,通过将突发事件的文本视为各种属性的集合,并通过基于语义词典以及句子依存结构计算突发事件框架的相似度[1]。这种框架更适合于标准化的表述文本形式,对于高层应急决策文本中简略的口语化表达过于复杂,同时框架中的“事件基本属性”、“承灾载体”、“应急管理”、“次生衍生灾害”4个子集合也不太适用于高层应急决策文本。关于文本相似度方面的研究,主要是将非结构化的文本形式转化为结构化形式。如Salton等提出的基于统计学方法的向量空间模型(VSM)[9],虽然VSM结构简单,但它是基于文本中的特征词频数统计计算的相似度[10],并没有考虑特征词的位置关系,对于高层应急决策文本的相似度分析来说过于片面。同时,也有学者基于自然语言处理进行了相似度方面的研究,如Hofmann,Thomas引入潜在类变量来提高相似度计算的精度[11];Emesto等通过对指定本体概念派生出的类使用聚类的方法进行语义消歧[12]。
本文针对危机情景下高层决策文本特征分析中的相似度计算问题,通过歧义消除、同近义合并、编码的方法将非结构化的决策文本转化为结构化的字符串形式,同时根据决策文本的特点细化其主题词分级,并运用序列比对中最长公共子序列模型(LCS)的理论及方法,综合考虑字符匹配度以及字符顺序来计算决策序列对的相似度,将决策样本的聚类分析转化为求解决策序列之间的相似性问题,建立了高层应急决策文本相似性比对分析模型,定量化序列之间的差异性;用Needleman-Wunsch算法求解该模型,并通过实例检验了模型的有效性和可行性,研究结果可为高层应急决策文本分析研究提供参考和借鉴。
1 问题描诉与模型建立
1.1 问题提出
应急决策文本,不同于一般的政策工具,其可能是1项通知、1则公告或者几行命令。它是承载了决策主体在不确定条件下对各种意外事态进行研判并采取应急处置措施的文本。为了应对突发事件,决策主体根据经验、知识、能力等提出自己认为正确的“任务”或“行动”,由于突发事件的复杂性,这些应对措施往往不是唯一的,所以这些决策文本的内容往往是多主题的。当我们对这些决策文本进行主题词提取、整合,就会得到该决策文本所特有的决策序列,如图1。当处于同一危机情境下,如何对这些序列进行聚类分析进而得到决策主体的决策行为特征就是本文研究的问题。

图1 决策序列示意Fig.1 Schematic diagram of decision-making sequence
1.2 变量及名词定义
最长公共子序列模型(LCS)是由Wagner和Fisher在20世纪70年代提出的一种较为基础的算法,其主要用途是查找2个序列之间的最长公共子序列[1]。这种算法一经提出就广泛应用于生物信息学,对于发现核酸和蛋白质序列上的功能、结构和进化的信息具有非常重要的意义[13]。对于高层应急决策序列对,可以通过得到序列对之间的相似性分值来对样本进行聚类分析,进而研究各类之间的区别及联系,由此,序列比对时应该考虑的内容就在于决策内容和决策顺序。决策内容本质上是决策主体从应对特定突发事件的各种措施的大集合中挑选出满足自身要求、各种任务部署的小集合,而决策顺序则代表了决策主体对这些任务部署的优先级的确定。各变量及名词定义如下。
1)主题词:用以表达决策文本主题的词汇,具有概念化和规范化的特征。主题词来源于样本数据,1个主题词的来源可能是多个样本,比如:“全力加强人员搜救,这是第一位的工作”与“全力以赴开展人员搜救”这2句的主题词都可以为“人员搜救”。同时,根据决策文本的特点,从执行层面上大致分为2级:目标和行动,并且后者属于前者,1个目标可以有很多活动或者没有活动。
2)编码号:连接序列和决策文本的中间元素。既是决策序列的组成部分,又一一对应决策文本中的主题词。
3)设序列S记为S=s1s2s3…sx,序列T记为T=t1t2t3…ty。用Si和Tj分别表示序列S的第i个编码号和序列T的第j个编码号。
4)在整个样本数据中,m是目标级别编码的数量,n是各目标级别所含行动级别编码的数量。
5)置换得分ωij:Si与Tj的相似性分值。
6)相似性计分矩阵:基于置换得分得到的打分矩阵。
7)空位罚分Q:序列比对时,加入空位时的相似性罚分。在这里,Q=G×num。G表示1个空位设置的罚分;num表示序列比对中所设置的空位数目。
8)相似性分值F:2序列比对得到的相似性得分。目标函数为:
(1)
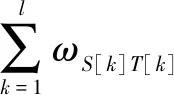
1.3 模型建立
基于以上变量及名词定义,以2序列比对的相似性分值最大为优化目标,建立高层应急决策文本相似性比对分析模型,如式(2)~(4)所示,其中,式(3)代表了相似性计分矩阵的取值,表示不同的替换情况的替换得分。
(2)
(3)
Q=G×num
(4)
2 模型的求解算法
Needleman-Wunsch算法是基于动态规划的全局比对算法[14]。算法的基本思想为:使用迭代的方法逐步计算出2条序列的相似分值,并将其保存在1个得分矩阵中,然后根据这个得分矩阵,通过动态规划的方法回溯寻找最优的比对序列[15]。该算法使用二维表格,表格里的每1个分值分别有3个来源:
1)来自上方的单元格,代表将对应行的编码与空格比对。
2)来自左侧的单元格,代表将对应列的编码与空格比对。
3)来自左上侧的单元格,代表将对应行与列的编码比对。
根据相似性计分矩阵和空位罚分值,该单元格的值取这3个来源的最大值。此算法的计算步骤如下:
1)初始化表格。在进行比对的2条序列前面都加上空格,然后填充第2行和第2列的值。比如:填充第2行意味着使用位于顶部的序列的编码与空格进行比对,而不是与最左侧序列的编码,用相似的方法得到第2列的值。同时将位于左上角的第1个分值设为0。
2)填充剩下的表格,根据相似性积分矩阵和设置的空位罚分值,取上述3个来源的最大值。
3)回溯。可以假设2个新字符串U和V,将上侧的字符串加入到U中,将左侧的字符串加入到V中。从右下角开始回溯,根据表格的构建过程可知,有3个方向回溯:“从右到左”、“从下到上”和“从右下到左上”。选取3个方向中的最大值(当最大值不止1个时,可以从中任选1个),同时遵循以下原则:“从右到左”意味着将左侧字符加入到V中,将空格加入到U中;“从下到上”意味着将上侧字符加入到U中,将空格加入到V中;“从右下到左上”意味着分别将2侧字符加入到U和V中,如图2所示。
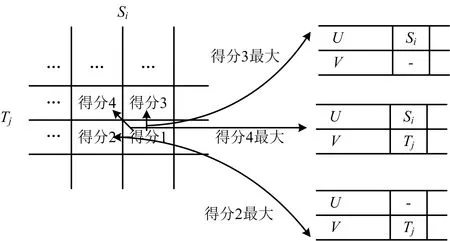
图2 回溯示意Fig.2 Schematic diagram of backtracking
3 实例分析
3.1 数据来源和初始化
数据来源是45位政府高层管理人员参加的1次地震演练情景,共得到45份应急决策文本。通过对这些文本进行主题词提取、整理和编译,得到全样本决策编码,如表1所示。根据表1,任取2份样本得到2条决策序列对S和T,如图3所示。
3.2 相对相似性得分
从表1中可知,此实例共得到了目标决策12个,相应的行动决策31个。同时根据模型中的公式(3),当总样本确定后,根据样本得到目标决策以及相对应的行动决策,其对比序列的替换矩阵也就确定,即序列比对时编码匹配度的影响因素就已确定,影响最终相似性得分的因素只有G(单个的空位罚分值)和num(插入空位的数量)。G的设置是避免为了得到最大相似性得分而插入过多空位。当G设置为0时,2条序列比对的相似性得分等价于拥有长度相同的“最长公共子序列”的2序列比对相似性得分(这里的“最长公共子序列”不止包括相等,还包括从属关系、并列关系);当G<-m时,序列比对时,当2个编码不同而位置相同时,不管其他编码情况如何,都会选择插入2个空位,进而造成序列比对插入过多的空位;当0>G>-m时,相同序列进行对比的相似性得分随着单个空位罚分值的增大而增大,但不同序列相似性得分的大小比较结果并不会有所改变。为了降低空位罚分在整个目标函数中的权重,可以设置此次序列比对的单个空位罚分值G为-5。经计算得到S和T2条序列比对的打分矩阵,如表2所示。
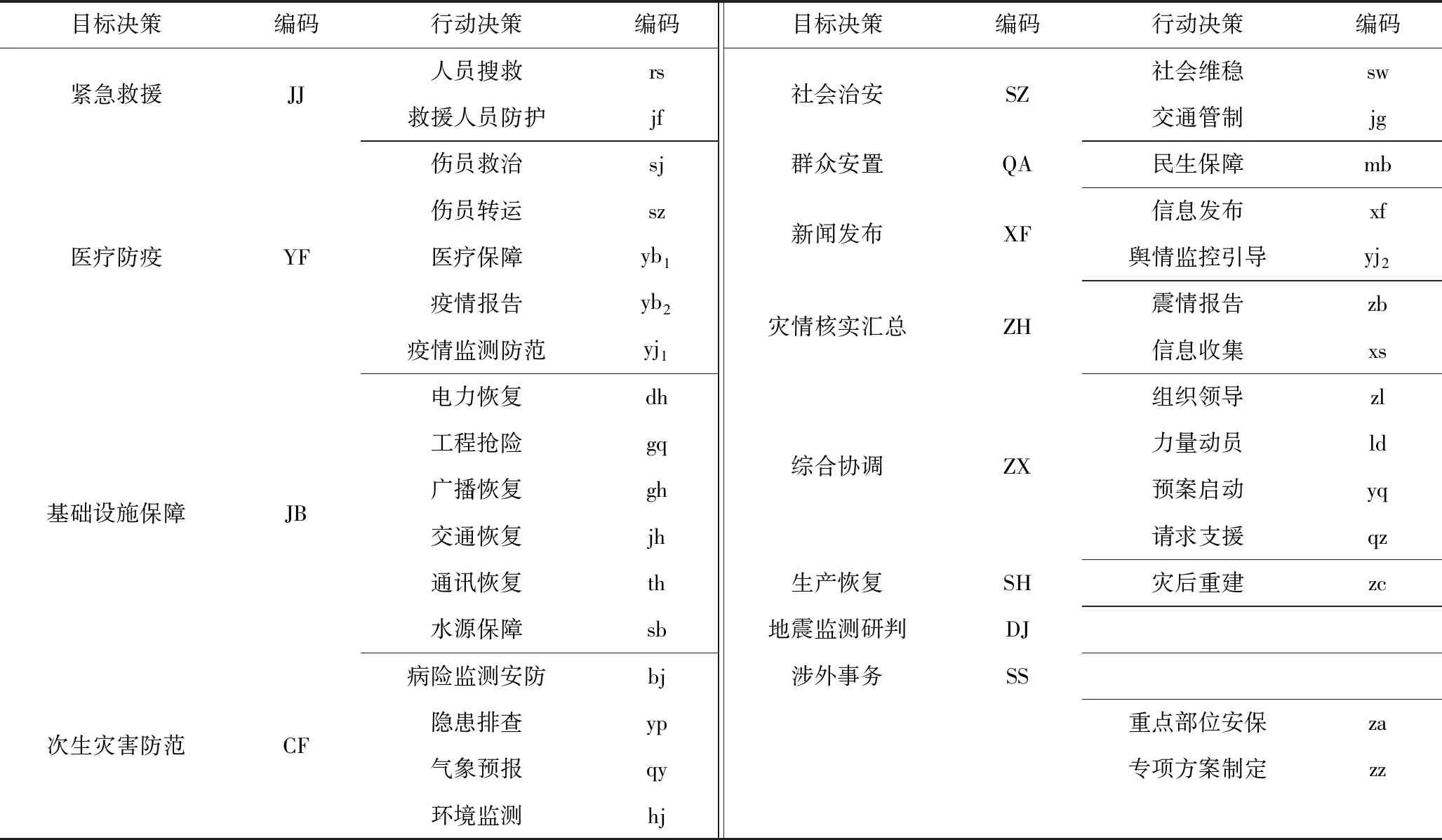
表1 地震演练情景下的高层应急决策编码Table 1 Emergency decision-making codes of senior people under earthquake drill scenario

图3 决策序列Fig. 3 Sequence of decision-making
根据打分矩阵表可以得出决策序列对S和T的全局相似性得分为80,同时其最优比对结果之一为表3,其中“-”表示插入的空位。
从模型以及算法的计算过程可以得到,当多条序列进行比对时,假设其中2条序列很短,仅有几个编码,即使他们的相似性很高,得分也不会太高,反之,当2条序列很长时,即使相似性不那么高,他们的得分也可能会超过前2条序列的得分,如何处理这些情况,或者说如何根据相似性得分来判定所有序列的聚类情况。在这里,本文引入相对相似性得分的概念,其计算公式如下:
(5)
式中:a和b分别为序列S和T的编码数量。
根据式(5)可得S和T的相对相似性得分为0.476,从数学意义上来说,约等于大约有一半的相同编码相同位置的序列比对结果,同时可以从表3中得到,序列对相同的编码为rs,sj,CF,bj,DJ,xf,yj2,sz,ld,zl,大于一半的数目,如前文所述,序列之间的相似性取决于序列编码号以及编码顺序,这一结果也很好地说明了这一点。
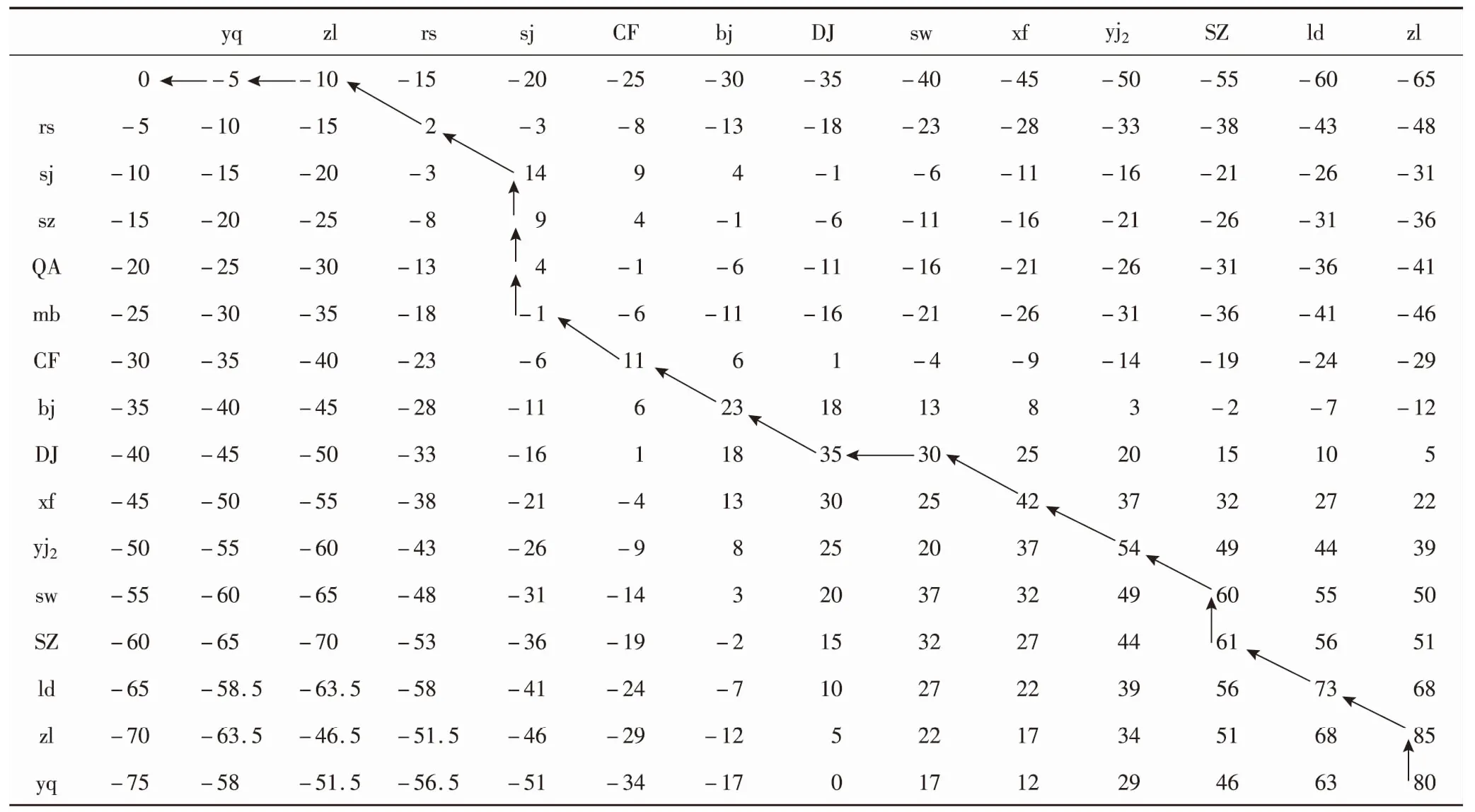
表2 打分矩阵Table 2 Scoring matrix
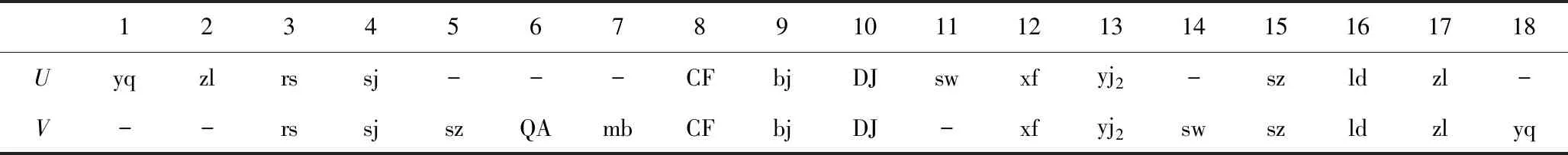
表3 序列最优比对结果Table 3 Optimal comparative results of sequences
3.3 与VSM算法的比较
本文选取另1个样本与前2个样本进行两两之间的相似度计算,并与VSM算法计算得到的结果进行比较,计算结果如表4所示。

表4 相似度计算结果Table 4 Calculation results of similarity
从表4中结果可以看到,由于算法中设置了空位罚分值,2序列之间的相似性比较更为严格,所以本文算法得到的相似性得分普遍低于VSM算法得到的分值,而且由于VSM只是考虑了主题词匹配度的问题,并没有考虑主题词之间的位置差异,所以在序号2和3中,本文算法得到相比于样本1,样本2和样本3更相似的结果,而这更能体现决策文本区别于普通文本的序列性的特点。同时,由于决策文本中的主题词都有着相对独立性,VSM模型中各主题词的权重设置就体现不出差异性,而本文算法根据决策文本特点,将其分为目标和行动2级,并根据两者之间的关系设置不同的比对得分,提高了精确性。
3.4 样本数量敏感性分析
为了研究样本数量对模型结果的影响,取上述2条序列对,并依次增加样本数量,同时将G设置为-2,得到不同样本数量情况下同一序列对的相对相似性得分,如图4所示。
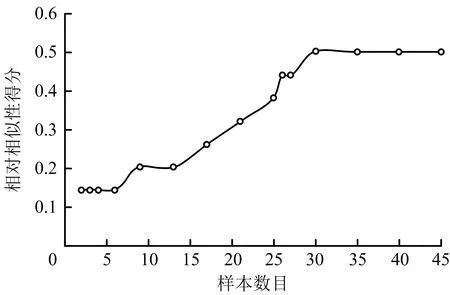
图4 同一序列对在不同样本数量下的相对相似性得分Fig.4 Relative similarity scores of same sequence pair under different sample amounts
从图4中可以看出,随着样本数量的增加,序列对的相对相似性得分是逐渐增加的,这是由于样本数量的增多导致目标级别主题词的完善,将本没有关系的行动级别的主题词联系起来,进而增加了相似性得分。同时也可以看到,在曲线的某些阶段以及最后一段,曲线趋于平滑。这是由于样本数量的增加并没有对同一序列对的相对相似性得分造成影响,间接说明了此实例中的主题词并不是无限扩展的,同时此实例中的45份样本也已经满足实验要求。
4 结论
1)为了计算高层应急决策文本的相似度,在对文本进行主题词提取得到决策序列对的基础上,提出高层应急决策文本分析模型,并用Needleman-Wunsch算法求解该模型。模型中将主题词分为“目标”和“行动”2级,对比时基于样本数据得到替换矩阵,并通过设置空位罚分来避免过多插入空位,进而计算决策序列对的相似性得分。
2)对基于地震情景下得到的45份高层应急决策文本的分析证明了模型的可行性,并由此确定了相对相似性得分的概念,来更好地分析相似性得分在决策序列中的数学意义。同时,通过与文本相似度经典的VSM算法的对比结果,体现了本文模型在进行决策文本相似度计算中有着更严格、更精确的特点。
3)本文提出模型可为其他情景下的应急决策文本的相似度计算和模型构建提供思路和借鉴。同时,应急决策文本的相似度分析是决策行为分析的一个重要方面,在接下来的研究中,作者将会考虑决策主体经验、学识及地理文化差异等更多与决策行为相关的实际影响因素,对决策行为分析进行更深入的研究。
