基于决策类划分多变量决策树天气户外运动分析实例
2019-05-30黄俊南
黄俊南
(泉州经贸职业技术学院 信息系,福建 泉州 362000)
0 前言
决策树是机器学习最基础且广泛应用的算法模型,大多数归纳学习系统得到的结果是一棵决策树[1].决策树算法从早期的单变量算法转变为如今的多变量算法,典型算法包含Quinlan的单变量算法ID3[2]和C4.5[3]及粗糙集多变量算法[1].2015年笔者发表论文“基于决策类划分的新型多变量决策树算法”[4],这是一种基于不可分辨关系、复合运算、集合运算和逻辑运算推导出的新型多变量算法.研究采用新型多变量决策树算法“算”出天气与是否进行户外运动的关系,验证其准确性和高效性.
1 选取户外运动典型数据
天气预报是计算机“算”出来的.天气预报员先用计算机解出描述天气演变的方程组,“算”出来天气;再通过分析天气图、气象卫星资料等,结合积累的经验,做出未来3天至5天的具体天气预报[5].气候对人类生产活动方方面面均起着重大的影响,主要因素包含:气温、风、日照、降水和气压.对于体育运动而言主要影响因素有:温度、风向风速、湿度、降水和雷电.但并非各种体育项目均会受上述因素影响,如雷电对足球、棒球、网球、高尔夫、田径等空旷场地运动有较大雷击风险,而降水的大小也影响类似网球、马拉松、小轮车等运动.
在研究中选用东南沿海的5个气候因素(常见数据值),分别是:温度(冷、热、适中)、风(大、小、无)、湿度(正常、高)、降水(大、小、无)和雷电(有、无).训练集数据选用常见天气数据,具体情况如表1所示.
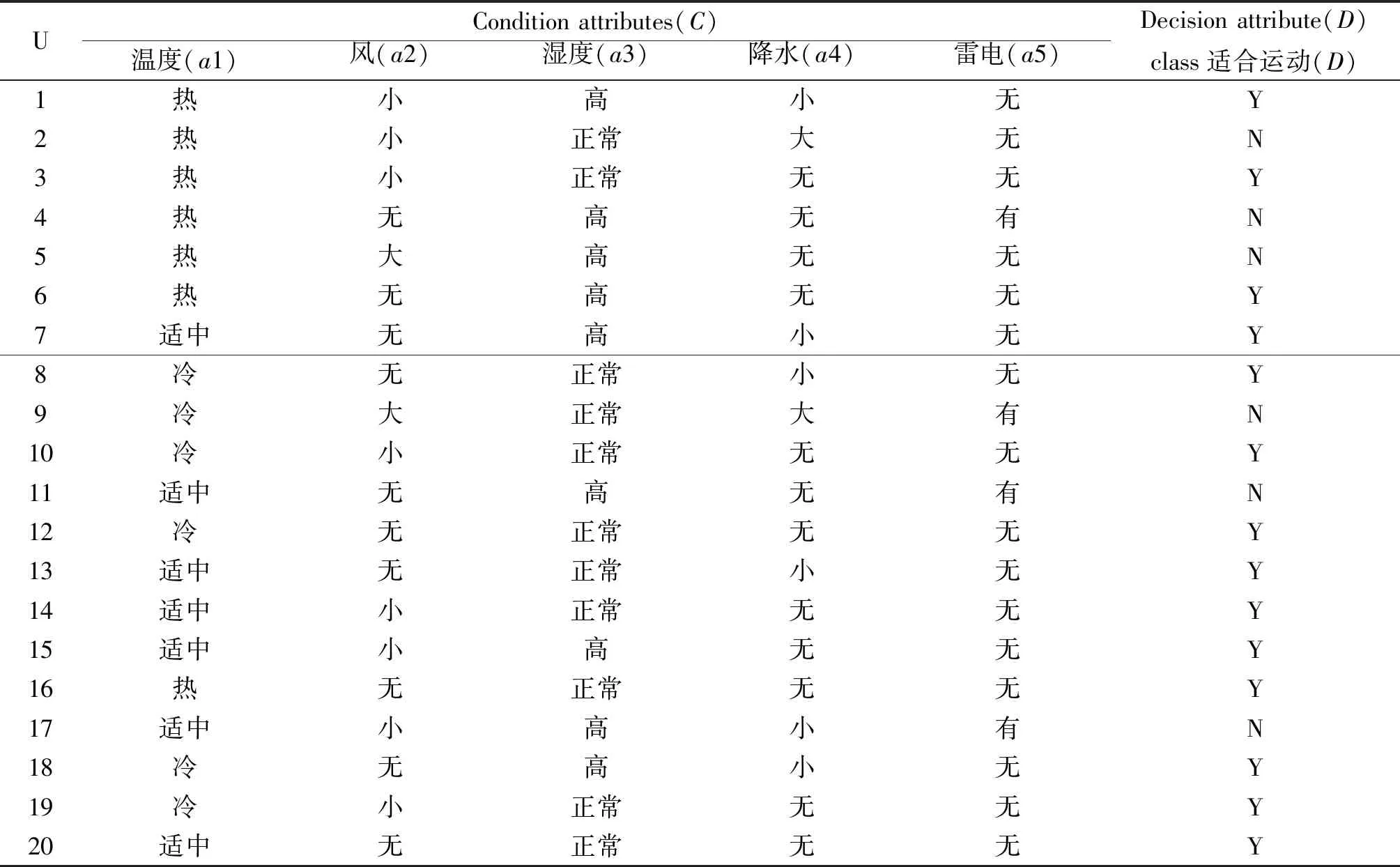
表1 户外运动信息系统表 续表
2 决策类划分的多变量决策树实例解析
决策表可以形式化定义[6]为:S=〈U,C∪D,V,F〉,其中U={u1,u2,…,un}是所感兴趣对象的有限集合,C∪D是属性的有限集,C为条件属性集,D为决策属性集,并且C∩D= ∅,V为属性集C∪D的值域,f:U×(C∪D)→V为一个信息函数,表示任一对象的属性在V上的取值,即f(x,r)∈Vr,它指定了U中每个对象x的属性值.决策表S=〈U,C∪D〉中的依赖关系C→KD决定了一套if…then…形式的规则集.从逻辑观点出发,决策规则将形如a=v(a为属性名,v为属性值)的基本公式是利用连接词语“与”“或”和“蕴含”连接起来所建立的蕴含式.蕴含式前件表示条件,后件表示决策[7].
2.1 根据决策树性值划分决策类
对户外运动信息系统表(表1)U的决策值进行不可分辨关系划分.决策属性值域VD={Y,N},论域U被划分为Y,N两个等价决策类,分别用UY,UN表示.划分后的结果为:UY={1,3,6,7,8,10,12,13,14,15,16,18,19,20},UN={2,4,5,9,11,17} .
2.2 二义性[8]条件属性判断
当存在相同的条件属性值能推导出不同的决策属性值时,表明论域存在数据二义性.通过二义性条件属性排除法对上述论域样本进行运算,CY∩CN=∅,表明数据并未存在二义性.在选取典型数据时已充分考虑二义性问题,故在此未出现此类情况才为正常.
2.3 判断独立决策条件属性
用CY和CN表示各条件属性对应决策值Y和N的集合,CN各个条件属性的值域为:Va1N={热,冷,适中},Va2N={小,无,大},Va3N={正常,高},Va4N={大,无,小},Va5N={无,有}.
CP各个条件属性的值域为:Va1Y={热,冷,适中},Va2Y={小,无},Va3Y={正常,高},Va4Y={无,小},Va5Y={无}.
对VY和VN各值域集进行比较,且将值域数大的集合减去小的集合得:Va1N-Va1Y=φ、Va2N-Va2Y={大},Va3N-Va3Y=φ,Va4N-Va4Y={大},Va5N-Va5Y={有}.当值为空时,说明该条件属性不存在独立决策条件属性值,所以a1和a3没有独立条件属性值.对其他三个条件属性分别从UN中提取样本得:σa2=大(UN)={5,9},σa4=大(UN)={2,9},σa5=有(UN)={4,9,11,17}.对所取得样本集进行包含性分析:σa2=大(UN)⊄σa4=大(UN)⊄σa5=有(UN),说明a2,a4,a5均有存在独立决策条件属性值,故推导结果为:a2=大D=Nora4=大D=Nora5=有D=N.
推导完毕后,将上述样本从论域中删除,UY保持不变,UN= ∅.
2.4 重设论域数据值
为便于后续运算,对论域中的数据值重新进行定义,设置内容如下:温度(a1)中的冷为0、热为1、适中为2;风(a2)中的大为0、小为1、无为2;湿度(a3)中的正常为0、高为1;降水(a4)中的大为0、小为1、无为2;雷电(a5)中的有为0、无为1.重定义后的条件属性集CY的情况如表2所示(UN= ∅表明CN无数据).

表2 属性集CY数据表
2.5 获取多变量逻辑表达式步骤
1)执行对象分量相交复合运算,运算法则为:将样本某行中的每个条件属性值一一与其他行相同条件属性值进行交运算,并生产新的条件属性集,对样本其他行分别执行上述算法.如样本有n行数据则生成n-1个新数据表,每个新数据表有n-1个新样本.
2)删除无效样本,运算法则为:由于是多变量逻辑表达式运算,当某行样本的有效条件属性值小于2个有效数据时,该样本无效删除之.
3)判断最优对象近似度,运算法则为:统计各样本有效数据个数,个数最多为最优近似度最高.
对CY执行1)~3)步骤后生成13个数据表,每个数据表包含13条样本.最优近似度分析结果如表3所示:

表3 第一次复合运算最优近似度数据表
4)保留最优近似度最高的数据表.分析表3样本12,16,20生成的新数据表最优近似度最大且均为39,保留之(未保留样本数据量过大,略之).保留下的数据表如表4所示:

表4 第一次复合运算保留下的数据表 续表
注:样本12和样本20均有一行加删除线,表明该样本数据无效(有效值为1).
5) 对上述样本分别执行步骤1)~3),共生成34个新数据表(数据量过大,略之),最优近似度最大值为31的数据表一共有5个.
6)优化数据表:文献4中提出对最优近似度数据表循环执行步骤1)~3),直至获取多变量决策表达式.在此对步骤5)所获取的数据表进行分析,发现5个数据表中有2个重复,如直接循环执行步1)~3),则会造成非常严重数据重复运算.因此对该算法提出优化数据步骤,法则为:对最优近似度数据表进行数据比较,并去除重复数据表,再执行循环步骤.优化步骤5)后的3个数据表样本数减少为12行,如表5所示.
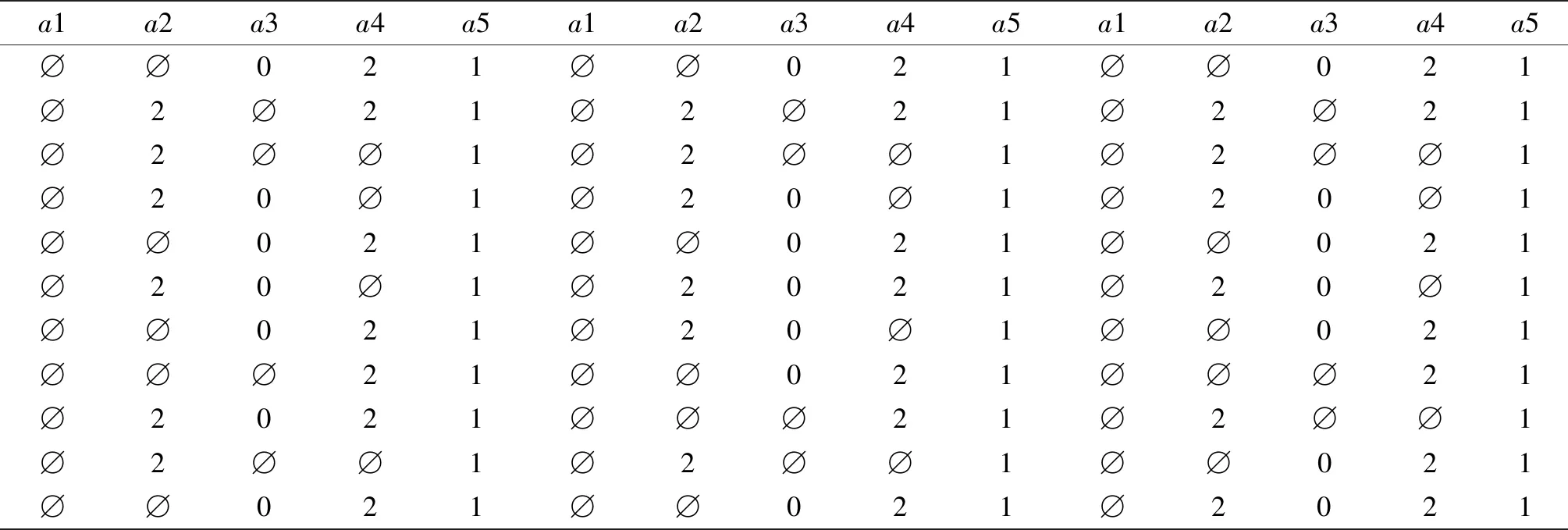
表5 优化后的3个数据表
7)对表6分别执行步骤1)~3),共生成30个新数据表(数据量过大,略之),最优近似度最大值为27的数据表一共3个,且数据完全相同.因此也证明了文献4算法的内敛性行为.获取的数据表如表6所示.

表6 第二次复合运算最优近似度数据表
8)对表7循环执行上述步骤(后续步骤,略之)直至推导出最终数据,值为:{∅,∅,∅,2,1}.约简后的多变量表达式为:a4=2∧a5=1.
9)重设论域数据:获取UY中可以用a4=2∧a5=1决策的数据σa4=2∧a5=1(UY)={3,6,10,12,14,15,16,19,20}.重设UY数据:UY=UY-σa4=2∧a5=1(UY)={1,7,8,13,18}.重设UY后的数据如表7所示.

表7 重设后的UY数据表
10)对表7循环执行步骤1)~8)过程略…,推导出最终结果为:{∅,∅,∅,1,1}.约简后的多变量表达式为:a4=1∧a5=1.分析表7,发现CY数据满足被推导完毕.
2.6 完整的多变量逻辑表达式
根据上述分析后所获取的多变量逻辑表达式包含:
1)独立决策表达式有:a2=大D=Nora4=大D=Nora5=有D=N.
2)多变量表达式有:(a4=2∧a5=1)D=Y、(a4=1∧a5=1)D=Y.
依据2.4的声明,将多变量表达式中的数值转换回状态值,最后获取的多变量表达式为:(a4=无∧a5=无)D=Yor (a4=小∧a5=无)D=Y.
综上所述,完整的逻辑表达式最终结果为:(风=大)∨(降水=大)∨(雷电=有)D=N,(降水=无∧雷电=无)∨(降水=小∧雷电=无)D=Y.
转换成对应的逻辑语句为:
if (风=”大”) or (降水=”大”) or (雷电=”有”)
then class=”N”;
if (降水=”无” and 雷电=”无”) or (降水=”小” and 雷电=”无”)
then class=”Y”;
3 结语
使用新型多变量决策树算法,对选用的“天气与户外运动”典型数据进行训练并构造出相关决策树,证明了该算法在“天气与户外运动”中的有效性、准确性和高效性,也证明的户外运动与雷电和降雨关系密切.同时为算法增加了步骤6)简单的“优化数据”判断方法,为算法进一步提升运算速度.在步骤7)中同时证明了新型多变量算法的内敛性.然天气变化因素并非单一,针对不同户外运动进行决策时应针对实际情况对条件属性进行增删,而非拘泥与此.故在使用新型多变量决策树算法做各种决策时,更应根据事实进行实际分析.
