基于功能结构元组的技术文档的特征提取研究
2019-05-17孙龙,李彦
孙 龙,李 彦
(1.四川大学 计算机学院,四川 成都 610065;2.四川大学 制造学院,四川 成都 610065)
1 概 述
一般而言,技术系统可提供具有人为效应即所需功能,因此功能的概念对于确定产品的基本特性至关重要,被认为是技术分析的基础[1],而获取文档隐含的功能概念涉及到文档语义技术[2]。为了有效表征文档的语义信息,目前越来越多的研究开始聚集于基于语义元组模型的文档结构特征提取。一些研究中以SAO(subject-action-object)[3]或AO(action-object)[4]结构表达功能信息。这种结构可以使用文本挖掘技术提取。目前,大量研究采用了自然语言处理技术(NLP)进行文本包含功能结构元组(SAO,AO)的挖掘,并对提取的功能结构元组进行了广泛应用。如基于(SAO)结构专利挖掘开发的半自动构建客户作业图的方法[5],通过功能结构元组挖掘识别专利技术发展趋势和新兴技术[6]以及结合TRIZ趋势分析确定可以转让的有前景的技术专利[7],利用功能结构元组的语义专利检索完成关键词专利检索[8]。
在词汇模型(又称词袋模型)[9]中,其词汇构成是一个个孤立的词,缺少上下文环境,难以解决歧义问题。而功能结构元组由于有明确的主谓宾(SAO)或动宾(AO)结构,一定程度上具备了上下文解释的基础,有利于减少同形同义词的歧义。同时,提取的功能结构元组(SAO)、(AO)中共同的Action可以更明确揭示出与主题概念S或O的关系,而且可以具体化为P&S模式[10]:“Problem问题”和“Solution解决方案”。
目前,SAO结构提取研究有很大进展,总体归纳起来有基于规则和基于统计两种途径。基于规则的方法主要采取人工(也可以是自动学习)建立的语言的规则集合,按照这些规则从语句结构中抽取SAO。例如,文献[11]通过LinkGrammer语法解析实现了SAO的抽取,文献[12]根据stanford nlp设计了SAO解析规则,这些基于规则的SAO抽取方法基本上采取无监督学习实现。相比监督学习方式,其优点是不用标注大量的用于学习的语料,而且能够很方便地通过规则的增删修改控制抽取过程,从而修正结果实现SAO结构提取。这种方法目前应用较为普遍,但也存在一些缺点,主要是设计建立抽取规则阶段工作量大,而且受设计者主观影响较大。
另一些研究是通过机器学习及统计技术来学习语句抽取,这些统计方法基本上采取了词袋模式常用的支持向量机、条件随机场以及共现算法来进行实现。例如,文献[13]中采取了支持向量机,通过语句上下文、词语距离以及句法特征来实现SAO抽取。基于统计的方法可以通过样本的学习去发现语料中的规律,而且一定程度上能够减少主观的判别失误。但基于统计的方法需要对实体之间的关系定义进行大量的人工标注[14],概率模型、语言模型参数的准确性直接依赖于语料的多少,而提取质量的高低主要取决于概率模型的好坏和语料库的覆盖能力。同时,由于基于统计的学习算法模型一般是黑箱,比较难以解释。
2 基于词法分析的功能结构元组识别
为了提高功能结构元组SAO或AO识别的准确性,有必要将基于规则的方法与基于统计的方法相结合,发挥两种方法各自的优点,具体思路是:
(1)为解决直接由原始文本识别功能结构元组带来的提取的功能结构元组数量过大,矩阵稀疏的问题,利用基于统计textrank方法,先对文本进行主题提取,获取文档关联度最高的主题词汇,过滤噪声词汇;
(2)按照基于规则的方式,通过词法分析树结构,提取文档的功能结构元组。针对工程技术知识文档的功能结构特点,可以按照分析树的结构,设计出一系列规则,对subject,action,object进行识别,进而抽取功能结构元组;
(3)用第一步获取的主题词汇与文档中提取的功能结构元组进行比对计算,保留关联度高的功能元组,过滤掉关联度低的功能元组。
整个过程如图1所示。
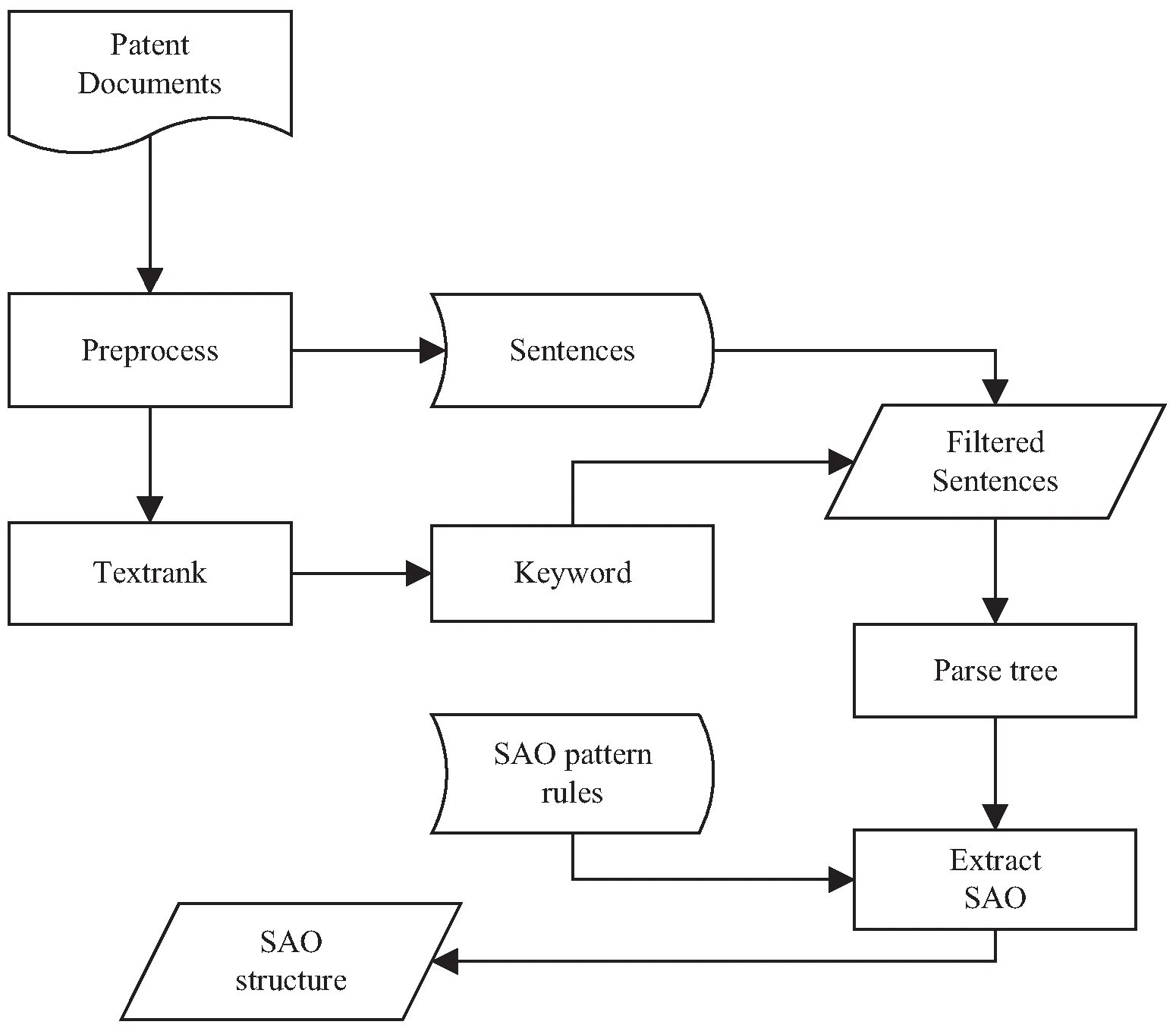
图1 功能结构元组提取流程
在整个流程中,首先要解决的是从分析树中提取功能结构元组的算法。分析树是一种有序的、有根的树,根据上下文无关文法表示字符串的句法结构。解析树通常基于词语结构语法或依赖语法的依赖关系构造。可以生成自然语言语句的解析树。比如将某防盗锁技术文档中的语句“在一侧锁芯体遭暴力破坏时即能主动限制开锁拨轮的旋转开启”进行解析,将获得如图2所示的解析树。可以看出,解析树每个节点要么是根节点,要么是分支节点,要么是叶节点。分支节点是连接到两个或多个子节点的母节点,叶节点是不支配树中其他节点的终端节点。root是根节点,NP和VP是分支节点,“锁芯体”(NN常用名字)、破坏(VV动词)、限制(VV动词)和开锁拔轮(NR固有名字)都是叶节点。叶节点包含了句子的词汇和标记。在这个例子中,LCP(方位短语)是IP(简单从句)和LC(方位词)的父元素。子节点是至少有一个节点在其上面的节点,由树的一个分支连接。图中DEG(助词)即为DNP(由“的”构成的表示所属关系的短语)的子节点。
通过解析树提取SAO或AO结构,文中是通过基于规则的方法,主要是建立产生式规则来进行。当前,上下文无关文法CFG一般由四元组(T,N,R,S)来表示:其中“终结符”T表示词集,“非终结符”N表示语法成分。“终结符”T、“非终结符”N的交集为空集,T∩N=∅。“产生式”R表示规则集合,S为起始符。产生式规则集R形式化表示为(α,β)∈R,其中非终结符α∈N,β∈(T∪N)为终结符或字符串变量;通常更多地用α→β来表示产生式。

图2 解析树
比如,对于句法规则:
(1)S→NP VP;
(2)NP→n;
(3)VP→v VP。
若其对串“token/n token/v token/n”进行解析,那么其结构正好与SAO的subject,action,object实现一一映射。因为实践中,对工程技术文本的解析语法树要比以上规则更加复杂,为了从其中有效地提取SAO或AO结构,需要从语句的词法分析树中寻找规律性的规则。从解析树中的词法规则看,一些工程技术文档中部分可以通过模式匹配的方式去获取功能结构元组。一些信号词汇,比如装置、系统等名词短语后面常跟subject元组,可以通过语法标记来对这些匹配模式进行泛化。通过识别名词短语,并扩展到其关联动词,可以从语句中模式匹配出action并进行抽取。同时,结合语法解析树的标签,一方面,可以将所在包含subject,action,object信息的浅层模式建立集合;另一方面,可将文法解析树中的相关结构模式组合成更通用的语法标记模式,如…/NN+和/NN+/PP+/VP+/NN…等等。从语句分解的词列中,可先分别设定subject,action,object的匹配规则,再进行(SAO)或(AO)的识别。
F={f1,f2,…,fn}为文档提取的功能结构元组(SAO)或(AO);
S为语句,由词列{w1,w2,…,wn}组成;
Key={key1,key2,…,keym}为关键动词(“采用”,“提高”……);
Rule={r1,r2,…,rl}为抽取的规则合集。
其中规则的表达样例,为了简化,仅将其中主要部分摘录如下:
……
VP:V[-aux] and V[-key] +Np→Obj=N
NP VP:N VP→Sub=N
Sub V Obj→act=V
……
比如第一条,如果在动词短语中,名词短语前接的动词不是助动词或信号动词,由此可以判断该名词短语为object。接下来的规则可以依此类推。通过判断各词汇成分在语法分析树中的词性及位置信息而获得相应SAO或AO的结构信息。其关键算法图解如图3所示。
具体流程解释:
(1)分词后的词列向量逐一生成语法解析树;
(2)若存在关键指示性动词,在伪代码中以[+key]表示,抽取出指示性动词后面的从句;
(3)对从句进行递归解析,通过之前建立的规则,解析和识别其中的名词短语NN、动词短语VP等等;
(4)根据相应规则,分别识别出subject,object,action;
(5)根据识别出的短语,存入SAO或AO元组集中。
其算法的伪代码如下:

图3 从分析树递归抽取功能结构元组示意
Function extractSAO(parsetree)
For each subtree in parsetree
If pattern(subtree)∈VPrule
Obj=NP(subtree)
Act=V(subtree)
extractSAO(subtree)
Else if pattern(subtree)∈NPVPrule
Sub=Np(subtree)
Else
Add (Act,Obj) to FunTuple
Add (Sub,Act,Obj) to FunTuple
End if
End for在这段代码中,使用了递归的方法对解析树进行分层解析,抽取SAO或AO功能结构元组。其中pattern函数定义了匹配模式的规则,一般是通过对解析树结构和词性进行运算组合来进行设计,公式举例如表1所示。

表1 公 式
上述公式中V[-aux]表示动词V是非助动词,V[-key]表示动词V是非提示性动词。
3 基于功能结构元组的工程技术知识文档分类
获取SAO或AO功能结构元组集之后,接下来所需要做的就是根据文档提取的特征词对SAO或AO元组集合进行过滤,去掉无意义的噪声SAO结构元组:{s·s∈SAO∪AO,w∈keyword|s∩w≠∅}。
在完成对SAO或AO结构抽取之后,下一步将进行相似度计算。其方法主要就SAO或AO结构词汇与分类标签相似度的加权值计算,并按最短距离原则归入相应文档类别。对功能元组的权重计算公式如下:
(1)
其中,Wfuni表示功能元组funi所占权重;freq(funi,j)表示功能元组funi在文档j中出现的频率;公式分母则为文档j提取的各种功能元组的数量之和。
Sim(D,Ti)=∑Sim(Sj,Ti)×WSj,
Sj∈SAO∪AO
(2)
其中,Ti为分类标签;D为文档;Sj为文档中提取的功能元组;WSj为功能元组Sj所占权重。
在相似度距离计算出来之后,即可最近距离归出相应类别。
4 实验结果及分析
为检验功能结构元组的特征提取效果,本实验以从中国专利网下载的工程技术文档为基础,以国际专利分类标准IPC的8个部类词汇作为分类标签,按每个分类标签分别下载20份专利文档,总共160份文档进行验证测试。提取出160份文档中的功能结构元组,根据计算的语义相似度将样本文档均归属到相应类别。对每个文档相应的IPC类别标签,再计算出分类的混淆矩阵。同时采取TFIDF、TextRank算法对这160份文档进行特征提取和分类,将其主要分类指标进行对比,结果如表2所示。
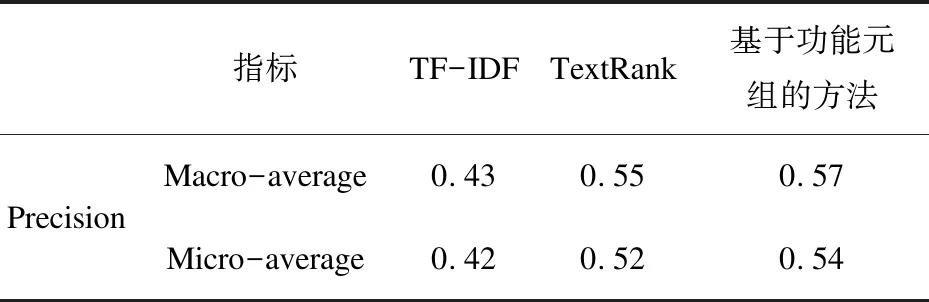
表2 文本分类指标对比
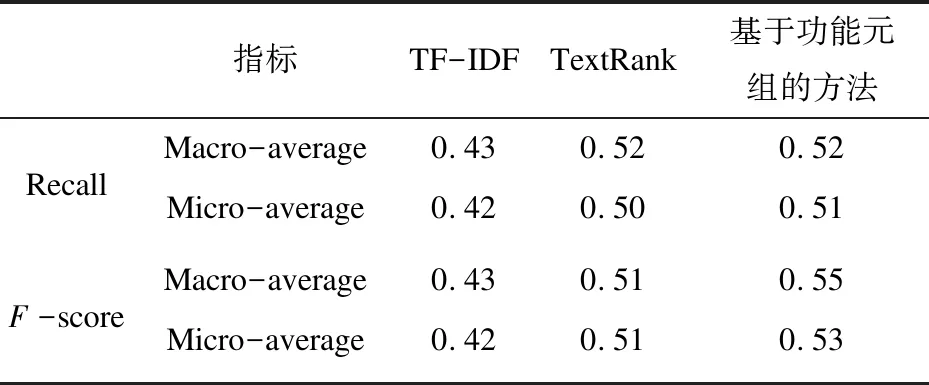
续表2
根据上面的数据,建立对应的直方图,如图4所示。
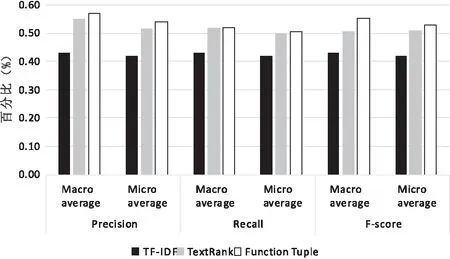
图4 文本分类效果比较
从上面分析可以看出,对相同的文档语料库、分词组件,基于功能结构元组的文本特征提取方法对比基于词汇的TextRank、TF-IDF等文本特征提取方法,其分类效果有明显改善。
5 结束语
在归纳总结现有提取文本功能结构元组方法的基础上,探索将基于统计的方法和基于规则的方法相结合,先通过TextRank提取出的文档特征词过滤掉文档中的噪声和无意义的语句。再从过滤后的语句中,按照语法分析树的层次,以递归方式提取文档中的功能结构元组。为更有效地提取语句中的功能结构元组,从语句的词法分析树中寻找规律性的规则。通过模式匹配的方式去抽取功能结构元组,并通过语法标记来对这些匹配模式进行泛化,并通过建立一系列产生式来定义提取规则。
经验证,该功能结构元组的文本特征提取方法,对比词汇模型的分类方法,其类别查全率、查准率、F1值的宏平均、微平均等指标均有改善。
