基于多示例遗传神经网络的室内PM2.5预测
2019-05-16吴宏杰柳维生傅启明
陈 成 吴宏杰,2* 柳维生 傅启明 汤 烨
1(苏州科技大学电子与信息工程学院 江苏 苏州 215009)2(苏州大学江苏省计算机信息处理技术重点实验室 江苏 苏州 215006)3(苏州市立医院(北区) 江苏 苏州 215000)
0 引 言
近年来,随着我国工业化和城市化进程加快,空气质量逐渐成为一个百姓关注的热点问题。在众多的空气污染物中,PM2.5由于粒径小、活性强且易附带有害物质,成为我国环境空气污染的重要污染物之一。现有的空气污染监测与预测主要关注室外空气质量。但是,人们每天在室内环境中停留时间占一天的80%以上,年老、幼小及患有慢性病的人群在室内停留更久的时间[1],室内空气污染往往比室外空气污染对人体造成更持久的危害[2]。PM2.5对人体健康的影响包括损害呼吸系统、致癌、破坏人体免疫系统等[3-4],这提示着人们室内环境与人群健康密切相关。因此,研究室内外空气中PM2.5的监测和预测有重大的科学意义和现实意义。
经验模型和统计模型是早年对空气质量进行预测的主要方法,随着大气物理、化学机制研究的发展,机理模型逐渐取代之前的预测方法。在基于机理模型的空气质量预测方法研究中,主要的思路是对污染物在空气中的传播、扩散、化学反应等过程实施抽象模拟,通过研究大气污染物的物理化学特性及其在特定条件下的转化规律,对未来的空气质量状况做出预测[5-6]。目前国内外使用的空气质量预测模型一般是机理模型[7],但是对于我国室内空气的重要污染物之一PM2.5来说,其来源具有多样性且其形成机理较为复杂,研究其在室内空气中的扩散及复杂的转化机理并进行有效的建模难度较大[8]。同时,在实际条件下,多种因素都可能影响空气中污染物的含量,如温度、湿度、光照等,所以空气中污染物的含量具有很高的复杂性和不确定性。而随着人工智能的发展,很多研究者开始尝试使用机器学习方法来进行空气质量预测的研究。如Feng等[9]提出了一种将PM2.5轨迹分析与小波变换相结合的混合模型,以提高人工神经网络预测PM2.5的平均预测精度;Yegaeh[10]将局部最小二乘方法与支持向量机方法结合对CO的日均值进行了预测,Garcia[11]利用支持向量回归方法对臭氧浓度进行了小时级预测。为了提高预测模型的精度,Kamali[12]提出一种通过谱分解构建的模型预测空气污染物浓度,通过Kolmogorov Zurbenko滤波器得到的人工神经网络(ANN),用于分离和单独预测空气污染物短期、季节和长期时间序列的三个光谱成分。尽管上述单示例方法在空气质量预测上取得了一定的效果,但是仍然存在两个问题:第一,样本采集粒度与预测粒度不一致,导致单示例方法难以准确描述本问题的实质;第二,对室内PM2.5预测的重要特征研究不足。因此上述方法预测精度难以进一步提高。且以上研究方法大多使用小时级测量的数据作为训练样本,忽略了小时内连续时刻的污染物数据隐藏的序列关系,导致最终预测的小时级污染物浓度不够准确。
基于此,本文提出一种基于多示例遗传神经网络的室内外PM2.5实时预测方法,将遗传神经网络与多示例方法结合,用遗传神经网络构建深层次预测模型,利用多示例机制将小时内的多个连续数据进行融合来挖掘其时序特征,最终提高了室内PM2.5小时级预测的精度。室外预测模型中以时间戳、温度和相对湿度作为输入特征,室内预测模型中选取与室内PM2.5密切相关的气温、相对湿度等属性作为输入特征。同时,研究表明[13],当室内无内扰动及污染源时,由室内外环境条件和外窗等特性决定的通风率成为影响室内PM2.5的重要因素,因此将通风率也作为一项模型输入特征。最后通过对医院办公室内外历史空气质量数据进行分析和深度挖掘,构建预测模型并进行了验证。
1 基于多示例遗传神经网络的PM2.5预测方法
1.1 数据采集与特征选取
分别于测试房间室内外设置监测点,室外监测点布于医院大楼3层,室内监测点布于1.5米呼吸带区域。我们分别于2017年7月、10月和2018年1月,即夏季、秋季、冬季3个季节采集连续的7天数据,形成3个数据集。采样间隔为全天24小时每隔1分钟进行一次采样,所采集数据分别为室内外气温(单位:℃)、室内外相对湿度(单位:%)以及室内外PM2.5(单位:μg/m3),每个样本集包含9 600条数据,同时把时间戳也作为模型输入特征之一。分别定义如下室外和室内预测模型。
moutdoor=F(t,wout,sout)
(1)
mindoor=F(t,pout,win,wout,sin,sout,v)
(2)
对于室内模型,当前室内的PM2.5与当前室内外温度、相对湿度、室外PM2.5以及通风率共7个参数有关[14],对应于示例子网的7个输入,而当前室内PM2.5对应于每个包的输出。每个数据集中以9 000条样本数据作为网络的训练集,600条数据作为测试集,室外和室内模型示例子网的特征输入如表1所示。

表1 室内外模型输入特征数据表
v表示当前房间室内通风率,计算公式如下:
v=s×|wout-win|
(3)
式中:s是为窗口打开的面积,wout为室外温度,win为室内温度。在实验前先对样本进行归一化处理,归一化公式如下所示,使之分布在[-1,1]之间。
(4)
1.2 基于多示例遗传神经网络的PM2.5预测模型
多示例框架下的遗传神经网络可由图1来描述。我们把N个样本作为N个包数据,把1小时内每隔1分钟所测的数据作为1个示例,则每个包中有60个示例。每个示例均为一个7维的特征向量,分别对应示例子网神经网络的室内外温湿度等7个输入特征,记包Bi中的第j个示例为[Bij1,Bij2, … ,Bij7]T。图中F1至F7表示表1室内特征所示的7个特征。

图1 多示例遗传神经网络模型框图
在多示例神经网络的回归学习问题中,包的实值标记是已知的[15-16]。因此,本文利用训练包的实际输出,在包的基础上定义全局误差函数为:
(5)
式中:Ei为包Bi对应的输出误差。
已有的相关研究指出[17],在多示例学习问题中,包的实际输出主要由包中示例的最大实际输出所决定。将包Bi的误差定义为:
(6)
式中:Ei为示例Bij经过模型得到的预测值。
神经网络隐藏层节点数的设置至今还没有确定的指导方法[18],试凑法是比较常见的方式。通常是使用不同的隐藏层节点数构建多个网络,分别对同一组训练数据进行训练,取最优模型的隐藏层节点数作为最佳网络参数。
也有研究者总结出一些经验公式[19],用来计算可能的隐藏层节点数目,把它设成试凑法的起始数值。常用的经验公式为:
(7)
式中:j、l、k分别对应输入、输出、隐藏层神经元数目,ξ为1到10 范围内的整数。综合前文分析,本实验中的示例子网输入层节点数为7,即j为7,输出层节点数为1,即l=1,根据式(7)可算出该神经网络隐藏层的节点数范围是3到12。经过多次实验对比论证,当隐藏层节点数k为11的时候,该多示例遗传传神经网络模型能得到最佳的预测结果。
1.3 多示例遗传神经网络预测流程
多示例遗传神经网络预测算法流程如图2所示。

图2 多示例遗传神经网络训练算法流程图
在图2所示的训练流程中,初始化网络结构包括每个包的多个示例子网中的前向神经网络结构,每个包的输出变量为预测的PM2.5数据。同时,根据本文前述分析针对本项目的实际情况,多示例子网中的隐藏层节点数设置为11。
初始化种群中,对包中示例子网的权重和偏置进行实数编码,然后求出种群中每个个体的适应度并进行评价,评价函数为误差平方和的倒数,即Fitness=1/SSE。
(8)
若满足进化结束条件则将当前权重和偏置作为示例子网的最优初始值来计算当前网络的预测结果与实际值的误差,并进行权重和偏置更新,否则产生新的种群继续迭代寻优。迭代停止后,将全局较好解作为初始权值和偏置进行接下来的多示例神经网络训练。
多示例遗传神经网络的优化停止条件为如下两个条件之一成立:
1) 运行到某一代时,全局误差Ei小于预先给定的阈值;
2) 训练次数达到预先设置好的最大训练次数。
1.4 多示例遗传神经网络初始权值训练算法
三层单元的神经网络可以满意地再现任何连续函数[20],神经网络具有自适应、自组织和实时学习的特点。常见的网络一般都使用误差导数来更新网络参数,从原理上来看并不是全局寻优算法,在随机初始化网络权重和偏置的情况下很可能导致输出结果陷入局部极小值点。
遗传算法起源于自然界“优胜劣汰”法则,是一种全局寻优算法。区别于传统优化算法的是,遗传算法能同时处理种群中的不同个体并根据不确定性原则来引导算法搜索方向,极大地扩展了问题解的覆盖面和搜索方向的多样性,降低陷入局部极小值点的可能性。由此,可以使用遗传算法来对示例子网的初始权值和偏置进行选取,以此来降低得到局部最小值的可能性,从而提高多示例框架下的神经网络的预测性能,算法实现如下所示:

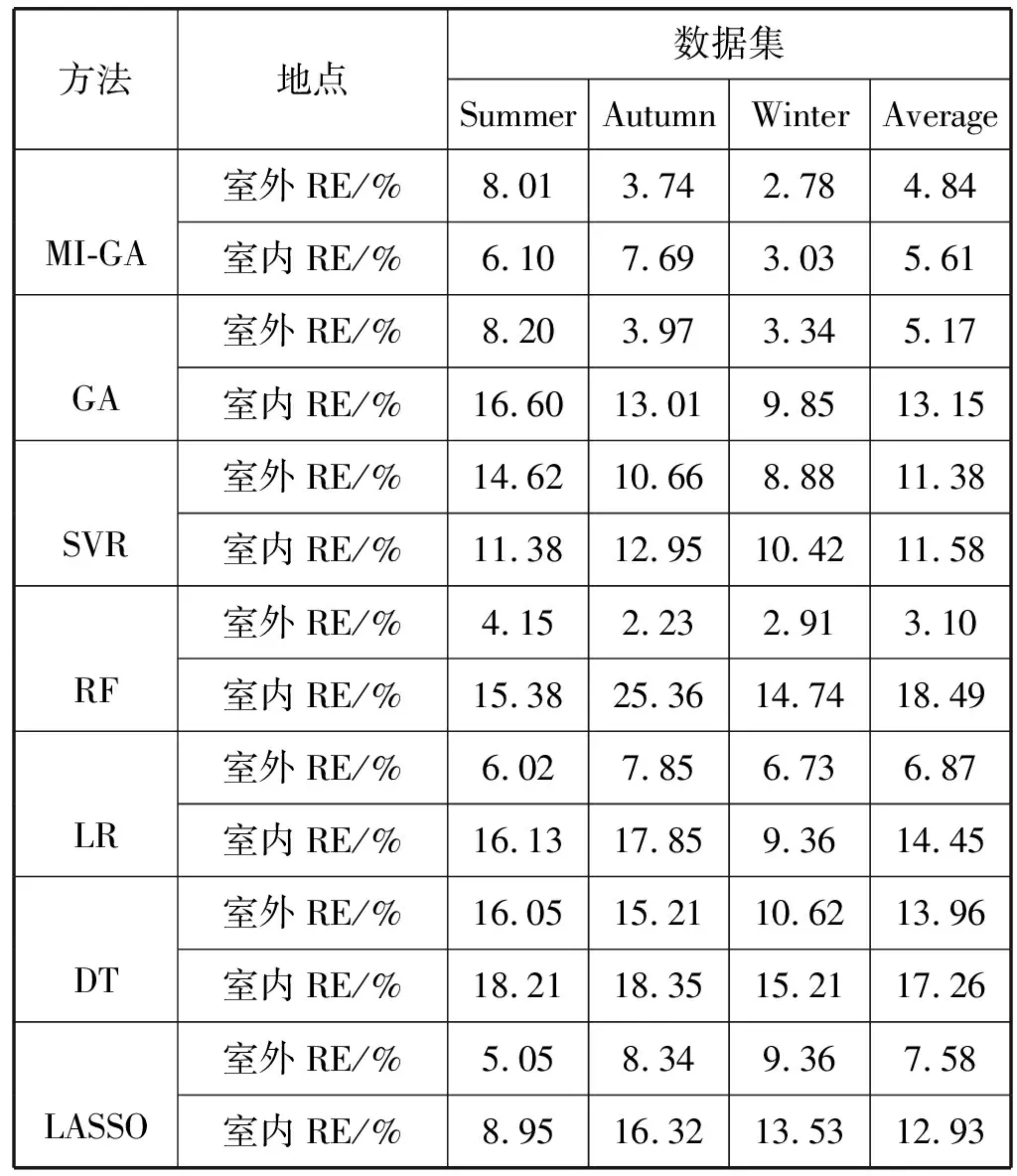
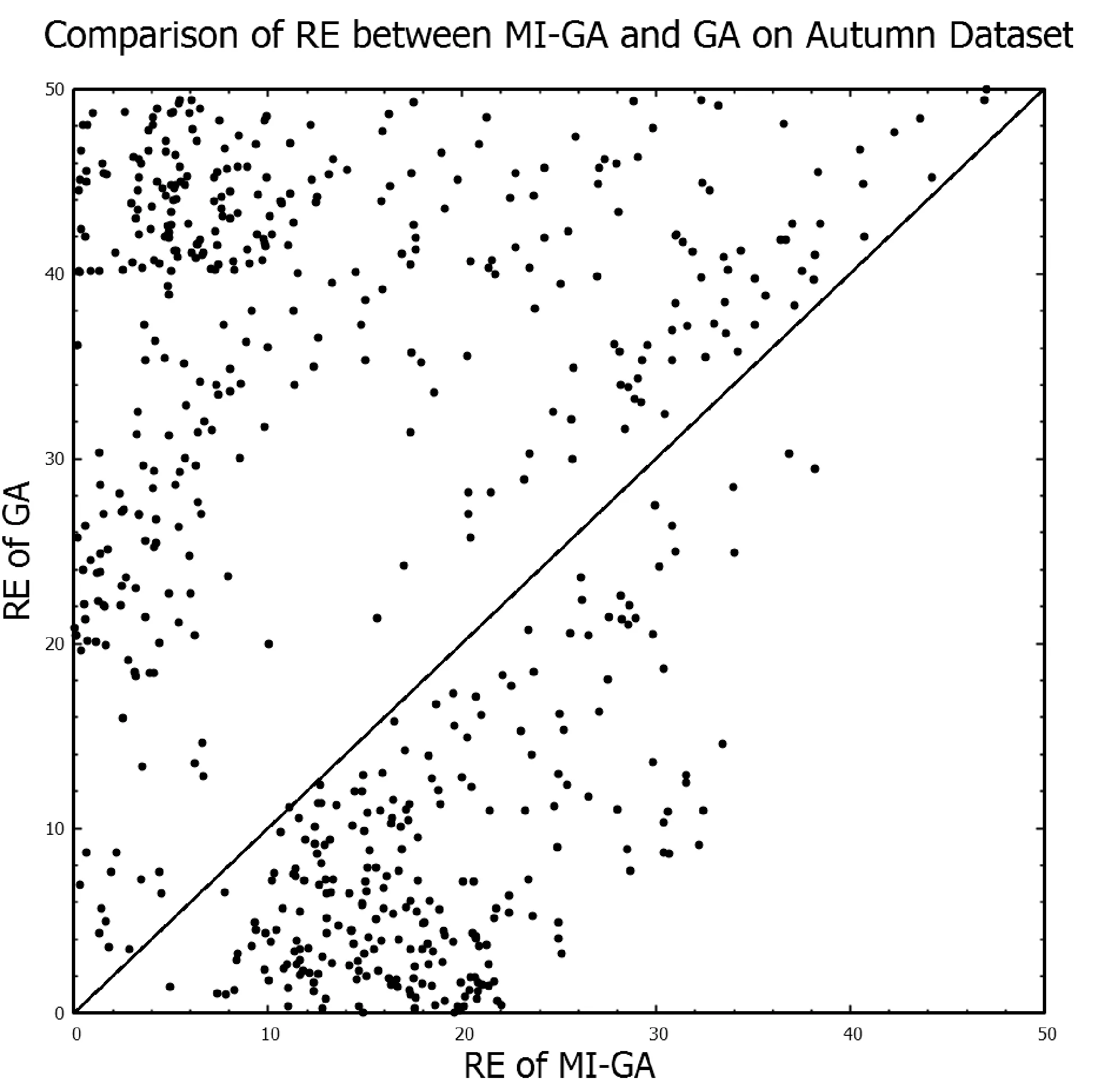
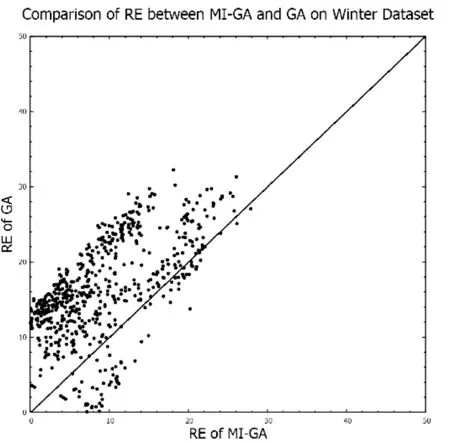
G:停止进化代数; Iter:繁殖代数 w:网络的权重CalFitness:计算适应度;Copy:选择个体进行复制;Crossover:交叉;Mutation:变异;M:个体个数;TN,Q:由N个包构成的数据集,每个包包含Q个示例1. Input: TN,Q2. Initialize(Sk, k=1,2,…,M)3. whileTrue4. w=Encoding(Sk)5. for(i=0; i CalFitness(w,N,Q)用于按式(8)计算包的适应度函数。该算法的时间复杂度为O(M×G),遗传算法搜索最优权值的停止条件定义为如下两个条件之一成立。 1) 运行到一定代数时,适应度函数中最高的适应度函数小于预先设定的阈值; 2) 进化次数增长到初始给定的最大进化次数。 多种指标可用于对预测模型的性能进行评价,其原理都是对标签和预测值之间的差距进行分析。对于回归问题来说,可以从2个方面来评价这种差异,分别是预测值与标签之间在数值上的偏差,以及二者的一致性程度。因此,本文采用2种指标对预测结果进行评价,分别是相对误差RE(Relative Error)、和拟合指数IA(Index of Agreement)[22],RE反映了预测值与标签之间在数值上的偏差,IA反映了预测值与标签之间的一致性,可以用来表示模型预测的效果,计算公式如下: (9) (10) 根据式(9)和式(10)可知,RE是越小越好,IA是越大越好。表2是多示例遗传神经网络算法MI-GA(Multi-Instance Genetic Neural Network Algorithm)、遗传神经网络算法GA(Genetic Neural Network Algorithm)、支持向量回归(Support Vector Regression)、随机森林(Random Forest)、线性回归(Linear Regression)、决策树(Decision Tree)、LASSO(Least Absolute Shrinkage and Selection Operator),在室外和室内的3个测试集(每个测试集为600条数据)上预测所得结果的平均相对误差RE的比较,表3为这七种方法在是否加“通风率”特征的实验比较。 表2 室内和室外预测结果相对误差(RE)比较 表3 MI-GA 与其他六种方法在室内数据上预测结果比较 续表3 (1) 室内与室外预测比较: 从表2中可看出,在对室内和室外PM2.5的预测中,对同一种方法,室外预测结果的相对误差RE都要小于室内预测结果,这是因为室内PM2.5来源复杂,相较于室外PM2.5而言更加难预测。在对室外PM2.5的预测中,本文提出的MI-GA方法获得了仅次于RF的预测结果,这是因为本文实验中,室外特征较少,而在特征较少和小数据集的情况下,相对于其他算法, RF能发挥更大的优势。而相对于GA、SVR、LR、DT、LASSO,MI-GA方法取得了更好的预测效果,平均RE降低了0.33%、8.31%、2.03%、9.12%和2.74%。对于难度较大的室内PM2.5的预测,因为特征由3个增加到7个,MI-GA方法取得了最好的预测效果,相较于GA、SVR、RF、LR、DT和LASSO,平均RE分别降低了7.54%、5.97%、12.88%、8.84%、11.65%和7.32%。 (2) 特征是否含通风率实验比较: 窗户是连接室内和室外的重要通道,通风情况是影响室内PM2.5的一个关键因素,因此,通风率成为预测室内PM2.5的一个重要特征。本文对室内的3个数据集进行了是否含“通风率”特征的实验比较,实验结果见表3。从表3中可看出,在加入“通风率”特征的情况下,七种方法预测结果的相对误差RE分别降低了1.93%、0.04%、12.02%、3.93%、3.89%、3.77%和8.09%,拟合指数IA提高了0.07、0.10、0.01、0.04、0.06、0.10和0.06。实验结果证明了“通风率”特征对于预测室内PM2.5的重要性,为今后的模型改善提供了一个新思路,同时也可以为其他相关专业研究人员提供新的参考特征。 从表3中可见,在加入“通风率”特征的结果中,本文提出的MI-GA方法预测结果RE为5.60%,比GA降低7.55%,比SVR降低5.98%,比RF低8.36%,比LR低7.66%,比DT低14.69%,比LASSO低8.21%。可见,使用多示例机制将预测时间与采样间隔时间有效融合后的遗传神经网络预测模型,预测结果的相对误差得到了很好的降低。 图3为MI-GA与GA方法在3个室内数据集(包含“通风率”特征)上所得结果相对误差分布的散点图。从图中可以看到,分布于对角线上方的数据点都要多于直线下方的数据点,即相较于GA方法所得结果中,MI-GA方法所得结果中相对误差RE较大的点要更少,即MI-GA方法预测结果中有更多的数据比较接近标签。 (a) Summer数据集预测结果 (b) Autumn数据集预测结果 (c) Winter数据集预测结果图3 MI-GA与GA方法在三个数据集上的RE比较散点图 图4为测试样本在六种方法上预测结果在不同误差区间内的分布直方图。从图中可以看出,本文提出的MI-GA方法在室内数据集预测结果中,RE低于5%的样本个数有517个,比GA方法多339个,比SVR方法多252个,比RF方法多226个,比LR方法多92个,比DT多194个,比LASSO多138个。而在RE大于30%样本中,MI-GA方法的样本点最少,由此可见MI-GA方法不仅具有较高的预测准确度,还具有很好的稳定性。MI-GA能取得更好的预测结果,原因可能是多示例神经网络方法将某个时间范围内的多条数据集中于一个包中,充分考虑了包中各个示例之间隐藏的关系,进而更深层地挖掘出PM2.5的序列特征,从而提高预测的精确度。 图4 不同RE区间内样本分布直方图 综合以上对多示例遗传神经网络模型的分析和实验的实现,表明以时间戳、温湿度、通风率以及室外PM2.5等因子作为网络的特征输入,可以较为准确地预测出室内的PM2.5。最后从医院房间采集了28 800条数据进行实验验证,结果显示相对误差为5.60%,比传统遗传神经网络降低7.55%,比支持向量回归方法降低5.98%,比随机森林低8.36%,比线性回归低7.66%,比决策树低14.69%, 比LASSO回归低8.21%。这样的结果对于医院房间内预警污染的发生是可行的。 本文中所采用的遗传算法是最基本的遗传算法,遗传算法的设定在一定程度上会影响神经网络参数的优化,所以如何对遗传算法做进一步的改良或者选取更优的进化算法,进而优化多示例神经网络的模型结构,从而降低预测模型的误差率将是我们下一步的研究方向。同时,医院室内空气质量的预测是一种小范围问题,接下来的工作将考虑到将算法用于住宅、教室等更为复杂的环境,进一步验证算法的性能。2 结果分析
2.1 评价指标

2.2 结果与分析


2.3 MI-GA方法与其他六种方法预测结果比较


3 结 语
