基于BiLSTM神经网络的特征融合短文本分类算法
2019-05-16和志强罗长玲
和志强,杨 建,罗长玲
(河北经贸大学信息技术学院,石家庄050061)
0 引 言
随着互联网技术的快速发展,信息以文本、图片、视频、音频等多种方式进行广泛传播,在众多传播方式中文本仍旧是人们获取信息的主要方式[1]。目前,文本信息的表现方式已呈现出多样化,迄今为止则衍生出包括微博、新闻简讯、标题摘要、事件评论等在内的多种类型,与之前长文本相比,具有词数少、数量大、实时性强等特点。网络上海量短文本信息与当前社会的热点事件紧密相关,对这些信息进行有效分类管理,有助于政府、企业了解政治、经济、文化等领域发生的最新变化,更好地做到舆情疏导、危机公关、产品营销等[2]。因此,这些海量短文本数据极具研究价值,如何实现对海量短文本高效、准确分类并获得有价值信息,已成为学界亟待解决的研究课题。
目前,针对短文本分类问题的研究,主要可分为2个方面,即:文本向量化表示和分类模型。其中,文本向量化表示重点包括向量空间模型(Vector Space Model, VSM)[3]和基于文本分布式表示两种方法。前者是基于文本表层信息的提取,只限于对词频的简单统计、计算,常存在特征矩阵稀疏、维度高、词汇鸿沟等问题[4]。而后者是对文本深层信息的提取,根据词汇的概率分布获取词汇语义信息。文献[5]利用大规模语料训练Word2vec模型,学习文本中词汇间潜在的语义关联,在词汇粒度层面提取特征,得到词向量,解决矩阵稀疏、无语义特征问题。文献[6-8]利用LDA主题模型提取文章主题,在文本粒度层面扩展文本特征。文献[9-10]在Word2vec向量的基础上,结合TFIDF算法对词向量进行加权,以考虑词汇在不同类别中的重要程度。
文本分类模型中,深度学习模型的分类效果一般要优于传统的机器学习算法。总地来说,卷积神经网络(Convolutional Neural Network,CNN)就常常用来获取邻近词汇间的关联,注重捕捉文本局部特征[11]。 循环神经网络 (Recurrent Neural Network,RNN)作为一种序列模型,可以由前向后读取文档词汇,并可以对获取的语义信息进行记忆,因此RNN模型可以在获取文本局部特征的基础上捕捉到更广范围内的特征信息。相比于CNN模型,RNN模型更适合处理短文本这种序列化数据,然而RNN模型在实际处理文本数据过程中,常出现梯度爆炸和梯度消失的问题。为解决梯度消失问题,文献[12]对RNN模型做出改进,提出了长短时记忆模型(Long and short time memory model, LSTM)。 类似RNN,LSTM模型也按照文档输入顺序学习词汇间的特征信息。文档中词汇的正确理解要依赖于上下文信息,因此文献[13]提出双向循环神经网络处理短文本数据能够更充分抓取上下文关联信息。
在文本向量化过程中通常只单独考虑词汇的词义特征或者文本的语义特征,然而词义和语义概念不同,词义代表单个词汇的意思,而语义是多个词汇按照一定顺序综合表达的意思[14],因此为了丰富文本特征信息,文章对短文本向量化表示方法加以改进,结合Word2vec、LDA与TF-IDF三种模型,分别在词汇粒度和文本粒度两个层面提取文本特征,并计算词汇TF-IDF值,对多维词汇向量进行加权,以表现词汇的重要程度。将3种算法获取的文本特征组合成为向量矩阵。另外,利用双向LSTM作为分类模型,既能解决RNN梯度消失问题,又能从2个方向充分捕捉上下文特征信息。
1 改进的短文本分类算法WTL-BiLSTM
1.1 算法流程
文章设计的短文本分类模型将Word2vec、TFIDF与LDA三种模型提取的特征向量组合成输入矩阵,输入到BiLSTM中利用隐藏层节点获取短文本内部的关联关系,最后利用softmax分类器对神经网络层的输出进行类别判定。主要包括文本预处理、向量化表示、神经网络层及分类与评估四部分,算法设计流程如图1所示。
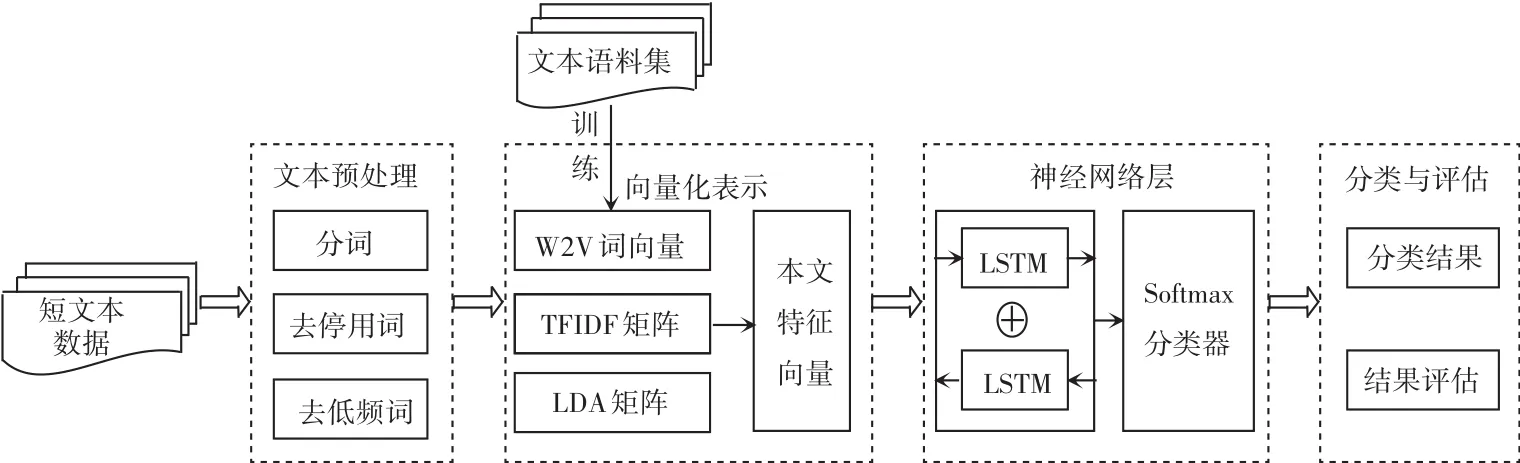
图1 算法流程图Fig.1 Algorithm flow chart
1.2 文本预处理
文本预处理是文本分类过程中基础、且重要的一项操作,训练数据的质量对分类准确程度有很大影响。本次设计的文本预处理主要包括:分词、去停用词与去低频词。
研究可知,中文分词不同于英文分词,词与词之间没有明显的界限,本文利用jieba分词软件将文本切割为若干个有意义的词语,并使用含有36 000余个常用词条的分词字典以提高分词的正确率。文本分词得到的词组中通常包括一些高频但无意义的词语、标点符号,如“一会儿”、“的”、“了”、“。”等,这些被统称为停用词。为保证文本特征的有效性,利用停用词表过滤掉这些干扰项,保留有价值的特征项;词组还包括部分出现频率低、对分类结果影响小的低频次分项,考虑到处理的数据为短文本,所以去掉出现次数为1的词汇,在一定程度上降低了特征维度。
1.3 文本向量化
文本向量化指的是将一篇文档表示为一个向量或矩阵的形式,主要是基于词的向量化[15]。利用大规模语料训练Word2vec模型,将每个单词表示为n维向量,再结合TF-IDF算法、LDA主题模型提取的词汇权重向量和文档主题向量,实现文本的向量化表示。对此可展开研究论述如下。
1.3.1 Word2vec 模型
Word2vec是一种轻量级神经网络,能够简单、高效地将词语映射为一个低维、稠密的向量。语料集则构成一个巨大的词向量空间,每个词向量映射为其中的一个点,此后则可通过计算向量点间的距离来判断词汇间的相似性。该模型包括:CBOM(Continuous Bag-of-Word Model) 和 Skip-gram(Continuous Skip-gram Model)两种训练方式,两者都包括输入层、投影层和输出层三层网络,主要区别在于:前者通过上下文信息预测当前词汇,而后者是通过当前词汇信息预测上下文,两者网络结构分别如图2、图3所示。
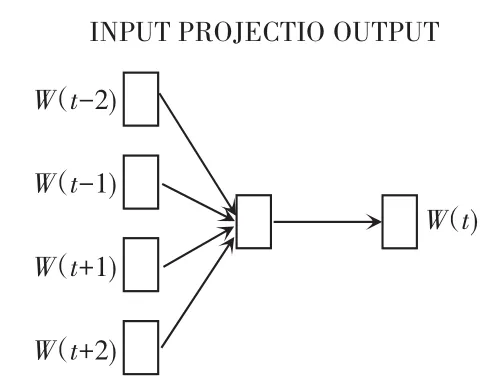
图2 CBOM网络结构Fig.2 The network structure of CBOM
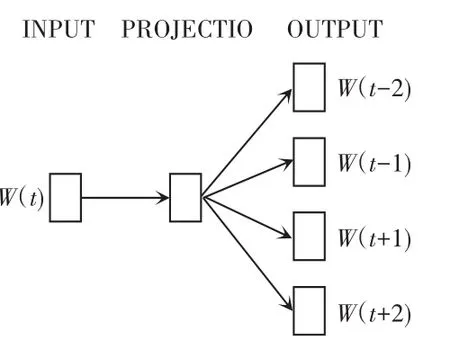
图3 Skip-gram网络结构Fig.3 The network structure of Skip-gram
由于短文本中词汇数量较少,上下文信息缺失,故本次设计使用Skip-gram方式来获取包含上下文词义信息的词向量,训练参数见表1。设置窗口大小为5,语料库中包括27 243 978个词汇,经训练得到167 299个100维的词向量。以“伊拉克”为例,查看与其词义相关联的词汇集合如图4所示,可以看出训练结果良好。

表1 Word2vec训练参数Tab.1 The training parameters of Word2vec
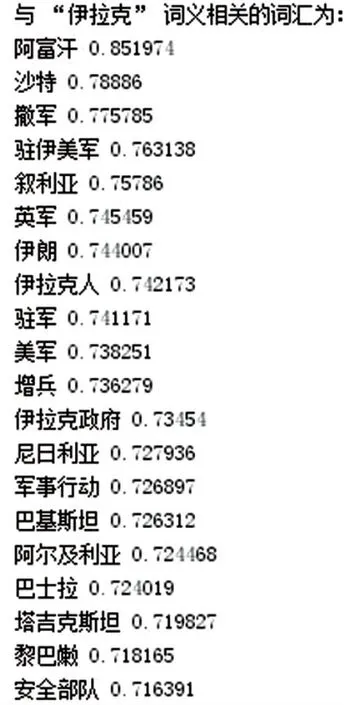
图4 Word2vec模型词义相关度Fig.4 Word relevance of Word2vec model
Skip-gram预测上文词汇概率的表示公式为:
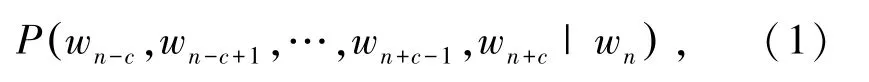
其中,wn表示语料集中的一个词汇;c为滑动窗口的大小;wn-c,wn-c+1,…,wn+c-1,wn+c为根据wn预测的前后2∗c个词汇。
假设文档dm为文档集D={d1,d2,…,dm,…,dM}中的任意一篇文档,dm有词汇集合W={w1,w2,…,wn,…,wN}, 利用 Word2vec 训练得到的词向量对文档dm进行文本向量化,文档dm转化为一个N∗V的二维矩阵,文档集D则表示为一个M∗N∗V的三维矩阵。由此可得对应的数学表述如下:

其中,M表示文档集中文档总数;N表示每篇文档的词汇数量;V表示Word2vec模型训练得到的词向量的维度。
Word2vec模型将词汇映射为包含上下文词义信息的V维词向量,很好地解决了one-hot编码方式出现的词汇鸿沟问题,而且有效降低了特征维度,避免了维度灾难问题。然而Word2vec模型无法区分词汇在文档中的重要程度,所以接下来研究将利用TF-IDF算法计算词汇的权重,为词向量进行加权。
1.3.2 TF-IDF 算法
TF-IDF模型广泛应用于信息检索、搜索引擎中,其主要思想为:若某一词汇wn在一类文档Di(Di⊆D)有很高的出现频率,而在其它类文档中很少出现,则认为该词汇能够代表该类文章,具有良好的类别区分能力。该模型主要包括:词频(Term frequency,TF) 和逆文档频率(Inverse document frequency,IDF)两部分。这里,TF表示某个词wn在文档dm中出现的频率,IDF则代表该词的类别区分度,其数学公式可表示为:

其中,fn,m表示词wn在文档dm中出现的次数;表示文档dm中出现的词汇总数;为文档集包含的文档数量;表示出现词wn的文档数量,为避免因语料集中不包括词wn,出现分母为零的情况,为分母添加一个常量,同时减小常量的影响,故分母设置为
TFIDF权重即为TF与IDF的乘积。总结来说,词wn的重要性与其在文档中的出现频率成正比增加,同时也与其在语料集中的出现频率成反比下降。经计算可得文档集的权重矩阵的数学公式如下:
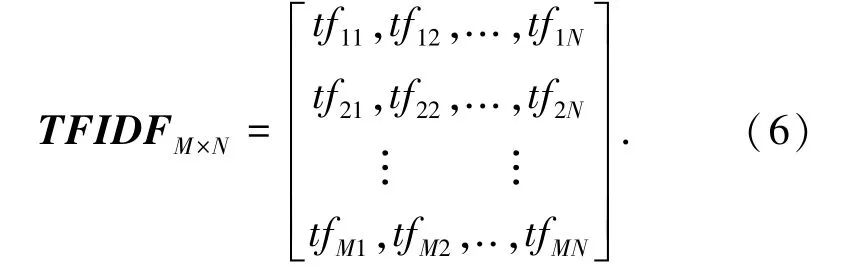
1.3.3 LDA 主题模型
LDA是一种无监督学习的主题概率生成模型,其核心思想为:每篇文档含有若干个隐含主题,每个隐含主题又包含一个与该主题相关的词汇集合。LDA主题模型主要包括2个多项式分布:文档-主题分布θ和主题-词汇分布φ。 前者表示各个主题在文档中出现的概率分布;后者表示每个词汇在主题中出现的概率分布。该模型的设计结构如图5所示,其中α、β、K分别表示:文档中主题分布的先验分布(Dirichlet分布)的参数、主题中词汇分布的先验分布(Dirichlet分布)的参数、主题个数。这3个参数均需手动设置。
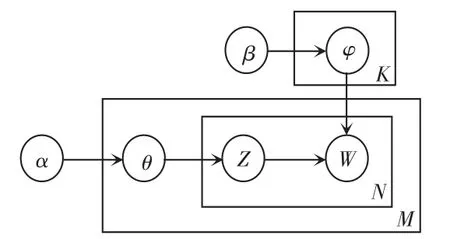
图5 LDA模型结构Fig.5 Structure of LDA model
短文本集经LDA主题模型训练后,输出文档-主题矩阵、主题-词汇矩阵[6],以概率形式体现文档隐含的语义特征,是对文档深层特征的直接提取。经实验检验,本次设计LDA主题模型的参数设置见表2。

表2 LDA主题模型参数Tab.2 Parameters of LDA topic model
其中,iter为迭代次数,主题数量K设置与Word2vec的维度相同,以便进行模型组合,最后得到文档-主题矩阵向量L,用此表示语料库中每篇文档K个主题的概率分布。研究推得其数学运算公式如下:

1.3.4 模型组合
改进的短文本向量化表示方法主要对3种模型提取的文本特征进行组合,首先利用计算的TFIDF值对Word2vec词向量进行加权,再将Word2vec词向量与LDA主题向量进行拼接构成新的向量矩阵,使其包含词汇语义信息的同时又包含文档的主题信息,则文档集中文档m的向量化表示则可写作如下形式:
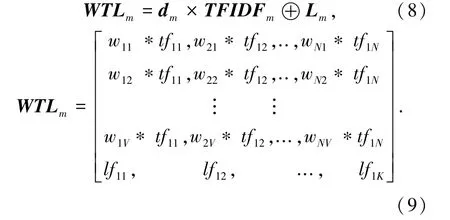
1.4 双向LSTM神经网络
自然语言是典型的序列数据,RNN目前已经常应用于序列数据的处理和预测。RNN能够记忆之前学习的信息,并利用之前的信息对当前输出施加影响,刻画一个当前输出与之前信息的关系。典型的RNN结构及其时序展开结构如图6所示。
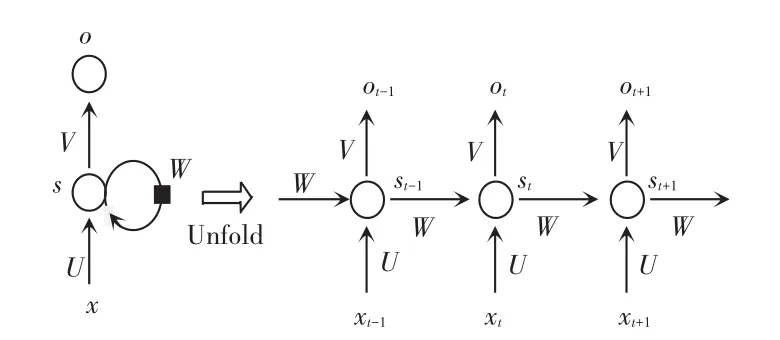
图6 RNN结构图Fig.6 Structure of RNN
由图6可以看出,当前t时刻RNN的输入除了来自输入层的xt,还包括之前时刻隐藏层的状态st-1,而当前时刻隐藏层的状态st,不仅作为当前时刻输出层的输入,还被RNN记忆下来作为下一时刻隐藏层st+1的输入,RNN正是基于以上原理对序列数据实现处理。理论上该神经网络模型可以处理无限长的序列,然而在实际应用中训练RNN时容易出现梯度爆炸和梯度消失的问题,使得RNN无法应对长距离的影响,导致其处理长序列的结果并不理想。针对研究中可能面临的梯度问题,一般通过设置梯度阈值来解决梯度爆炸问题,当梯度值超过该阈值时直接进行截取;而对于梯度消失问题,则流行使用对RNN做出改进的LSTM。
LSTM在RNN的基础上新增一种自我连接的CEC(Constant Error Carrousel)单元来记忆长距离信息,并引入门(gate)机制来对输入、输出信息进行限制管理。门实际上是一层全连接层,其输入为一个向量,输出一个取值范围在[0,1]之间的实数向量,LSTM的设计结构如图7所示。
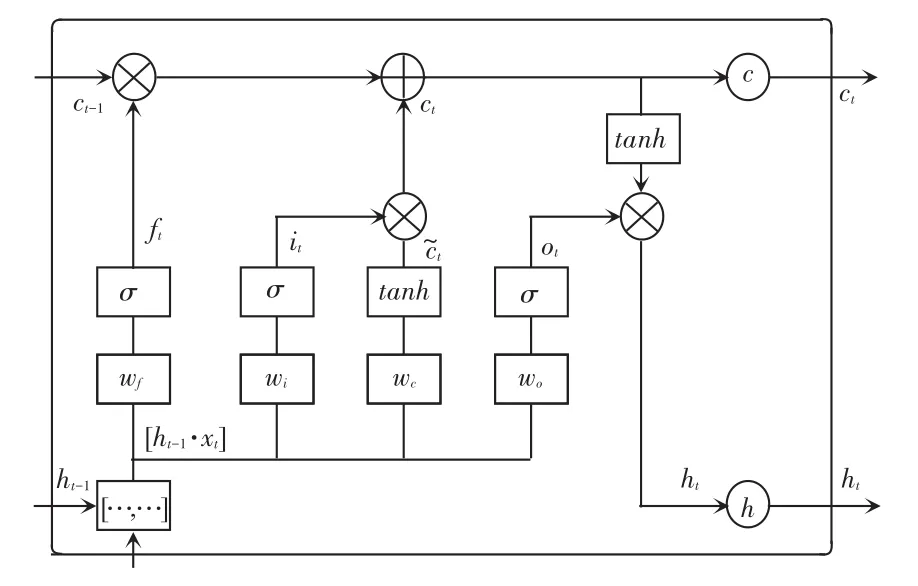
图7 LSTM结构图Fig.7 Structure of LSTM
由图7可知,LSTM主要包括记忆单元c、输入门i、遗忘门f以及输出门o。其中,遗忘门f和输入门i用来控制记忆单元的输入信息,决定之前时刻单元状态Ct-1和当前时刻网络输入xt的保留比例。输出门o用来控制单元状态Ct输入到当前时刻输出值ht的信息量。LSTM工作过程主要涉及各符号的阐释解读见表3。其中将用到如下数学公式:

表3 符号解释说明表Tab.3 Symbolic interpretation

通常情况下,文档中每个词汇语义的正确理解不但依赖于之前的元素,而且还与之后的元素密切相关。比如下面这句话:“我的硬盘坏了,我想____一个新硬盘。”,要补全这句话,若只考虑前面的元素信息,则横线处可以填:“修一下”、“买一个”、“扔掉”等,具有很大的不确定性。若同时考虑横线前后的元素信息,则选择填“买”的概率较大。LSTM为单向神经网络只能从前往后传输状态信息,而不能获取后文对当前词汇的影响,因此,本次设计使用2个方向相反的双向LSTM来充分捕捉词汇的上下文信息,最大限度理解当前词汇的语义信息,其网络结构如图8所示。
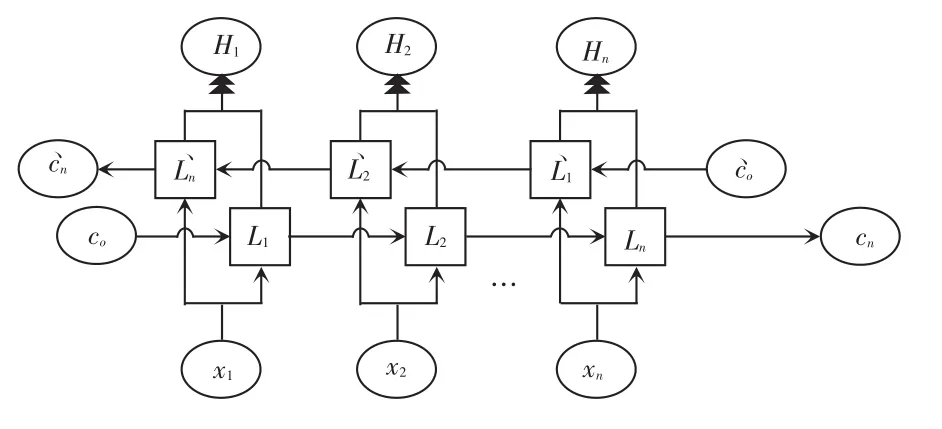
图8 BiLSTM结构图Fig.8 Structure of BiLSTM
可以看出,BiLSTM神经网络最后输出Hn由2个单向、反向的LSTM输出结果拼接得到,其拼接公式为:

2 实验结果分析
2.1 实验数据
本文利用22万余条新闻简讯作为实验数据,数据集中涉及13个栏目的分类新闻,从中选择affairs、economic、education、game 等 8 类新闻,并将其以8:2的比例划分为训练集和测试集。经统计部分文档,发现分词后大部分文档由100~200个词汇组成,文档词汇数目分布如图9所示,在完成预处理操作后文档保持在100词左右,故本次设计对文档长度进行标准化,保证每篇文档词汇数目为100,超出部分进行截断,不足则补0。
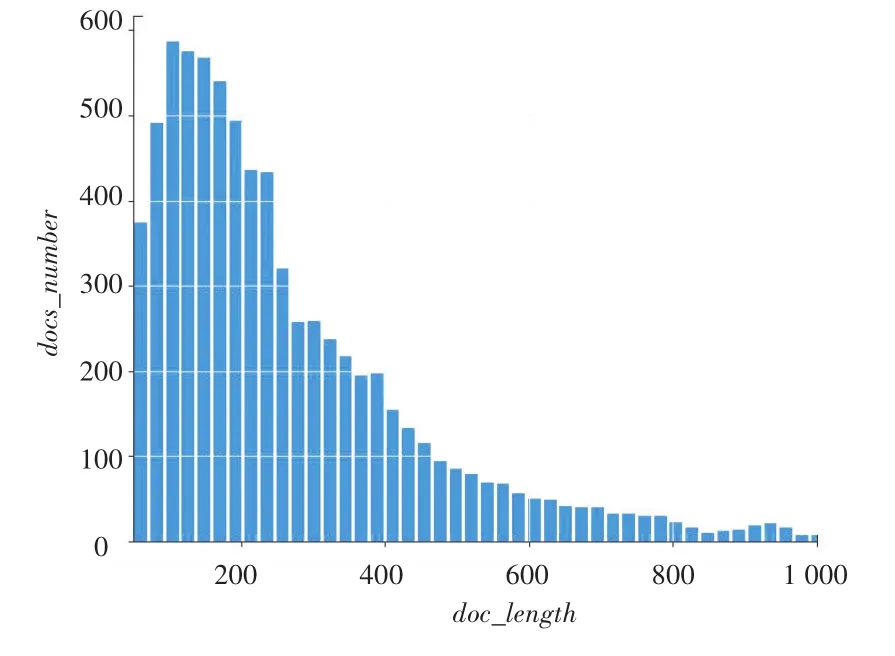
图9 文档词汇数目分布图Fig.9 Document vocabulary number distribution
2.2 实验参数
实验参数的合理设置对实验结果有直接影响,Word2vec模型与LDA主题模型的训练参数已在上文列出,神经网络部分的参数设置见表4。参数调整过程中使用固定参数的方法,分别对LSTM层单元数、Dense层单元数、丢弃率等参数进行了对比实验,并利用EarlyStopping机制对val_acc值进行监控,当准确率不再上升时则停止训练,以避免过拟合、不收敛等问题,同时可以加快学习速度,提高调参效率。
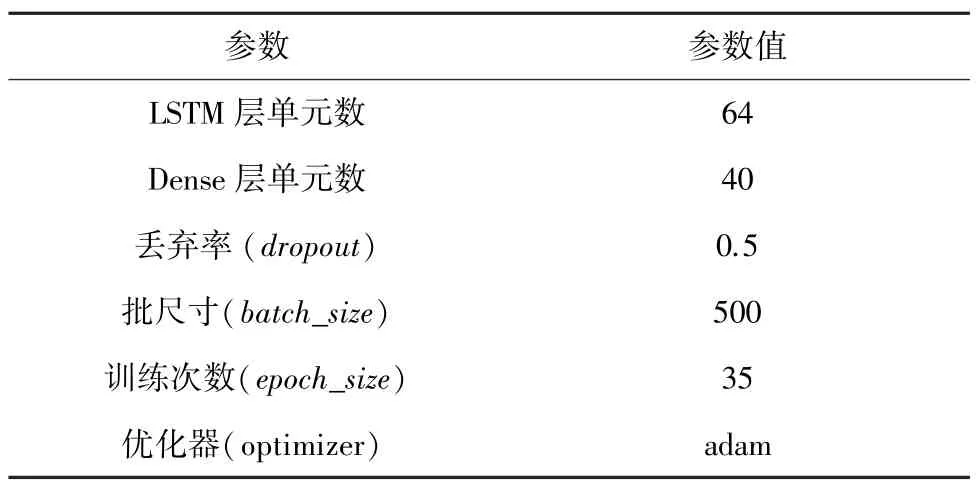
表4 神经网络参数设置Tab.4 Neural network parameter setting
2.3 实验结果及分析
为验证WTL-BiLSTM模型的有效性,分别与基于词向量的 LSTM模型(Word2vec LSTM,WLSTM)、双向 LSTM模型(Word2vec BiLSTM ,WBiLSTM)及传统机器学习算法SVM进行如下的对比实验研究。
首先与基于神经网络的分类算法进行对比,实验中各模型的参数设置保持一致。图10~图15分别为W-LSTM、W-BiLSTM、WTL-BiLSTM的损失函数变化趋势和分类准确率,利用Python绘图模块matplotlib绘制得到。在图10~图15中,train_~和val_~分别表示训练集和测试集。对比三者损失函数变化图发现,基于词向量的双向LSTM模型(WBiLSTM)下降到稳定值的速度最快,文章设计的模型(WTL-BiLSTM)下降到稳定值的速度稍慢,但相对其它2种模型最后训练得到的损失函数值最小,即说明分类效果最优。通过对比分类准确率图也可以发现,3种模型分类准确率从高到低依次为:WTL-BiLSTM模型、W-BiLSTM模型和W-LSTM模型。
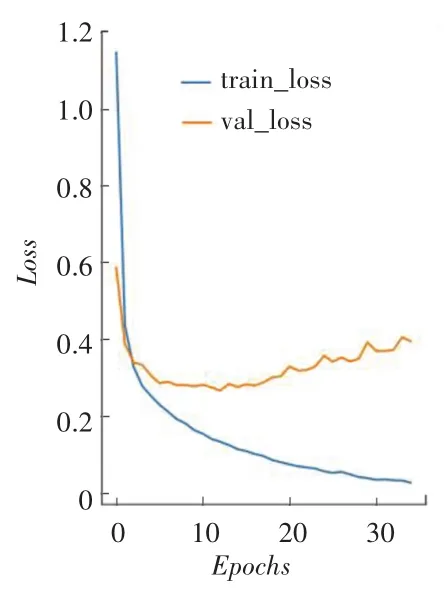
图10 W-LSTM损失函数变化图Fig.10 Change graph of WLSTM loss function
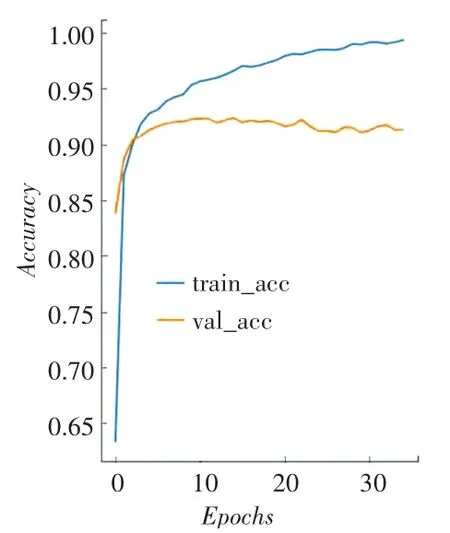
图11 W-LSTM分类准确率Fig.11 Classification accuracy of W-LSTM

图12 W-BiLSTM损失函数变化图Fig.12 Change graph of WBiLSTM loss function

图13 W-BiLSTM分类准确率Fig.13 Classification accuracy of W-BiLSTM
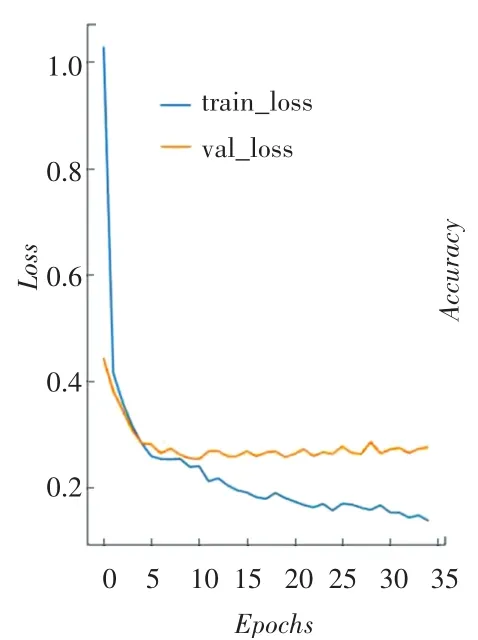
图14 WTL-BiLSTM损失函数变化图Fig.14 Change graph of WTLBiLSTM loss function
本次实验还与SVM算法进行对比,实验思路按照文献[9]的处理方法,利用TFIDF权重对Word2vec模型训练的词向量进行加权,然后将文档中的加权词向量累加后作为文档向量,最后输入到SVM中实现分类,算法运行后的分类准确率对比见表5。根据分类准确率对比发现,本次设计模型的分类效果要远远优于传统机器学习算法。

表5 各分类模型分类准确率Tab.5 Classification accuracy of each classification model
3 结束语
文章提出一种基于双向LSTM神经网络的短文本分类算法,从文本向量化表示和分类模型两方面分别提供了改进。文本向量化表示融合Word2vec模型、TFIDF模型与LDA主题模型,丰富了文本特征信息。分类模型则采用双向的LSTM从词汇前后两个方向充分提取上下文信息。通过实验对比发现,文章提出算法的分类效果要优于只利用Word2vec模型进行文本向量化的 LSTM模型、BiLSTM模型。另外还与传统机器学习算法SVM进行了比较,本次设计的算法同样优于SVM模型,进一步验证了本次设计改进文本向量化表示和分类模型的有效性。
