一种多源异构软件缺陷预测方法
2019-05-05范贵生虞慧群
杨 杰,范贵生,虞慧群
1(华东理工大学 计算机科学与工程系,上海 200237)2(上海市计算机软件测评重点实验室,上海 201112)
1 引 言
随着软件规模的不断扩大,软件缺陷也随之增多,软件质量成为人们关注的焦点.软件测试是常用、有效的软件质量保障手段,对于大规模程序而言,如果测试程序的所有模块则会消耗大量人力物力,如何合理有效地分配测试资源是一个亟待解决的问题.软件缺陷预测是一种可行的解决方法,它能够在系统开发初期,及时准确地预测软件模块是否包含缺陷,合理分配测试资源,针对性地对缺陷模块进行分析提高产品质量[1].
软件缺陷预测一般通过分析历史程序源代码或开发活动提取出与缺陷相关的度量元创建源数据集,运用机器学习等方法构建预测模型,最后使用该模型对目标软件项目的缺陷情况进行预测[2].根据数据集来源的不同可将软件缺陷预测分为同项目缺陷预测(Within-project defect prediction,WPDP)、跨项目缺陷预测(Cross-project Defect Prediction,CPDP).如果源数据集与目标数据集来自同一项目,则称之为同项目缺陷预测,反之称为跨项目缺陷预测.在实际开发过程中,需要进行缺陷预测的项目可能是一个全新的项目,而重新标记一个数据集的代价是非常昂贵的,因此跨项目缺陷预测更具实际意义.
近年来在跨项目缺陷预测上已有许多研究成果[3].Canfora[4]等将软件缺陷预测转化为一个多目标优化问题,在考虑成本和效率的前提下利用进化算法确定预测模型参数,提供了一种折中的解决方案.Ryu[5]等提出了一种与boosting算法相结合、基于相似度的重采样方法,该方法有效解决了类不平衡问题,提高了预测性能.Kawata[6]等使用聚类算法DBSCAN选择出与目标项目相关的数据进行跨项目缺陷预测,该方法获得了与其它聚类算法相比更优的预测效果.
上述跨项目缺陷预测方法存在一个问题,它们要求源项目与目标项目具有相同的度量元,这在某些情况下是无法满足的.如果源项目与目标项目使用不同的编程语言进行开发,一些与编程语言相关的度量元就无法统一;除此之外由于一些商业工具的许可证问题,使用这些工具采集目标项目数据还会产生额外的费用[7].为解决上述问题,部分学者提出了异构缺陷预测方法(Heterogeneous Defect Prediction,HDP).Li[8]等提出了一种使用多核学习、集成学习的异构缺陷预测方法,该方法解决了数据线性不可分和类不平衡问题,然而该方法改变了原始数据,导致数据不具有可读性.Li[9]等还提出了一种多源、关注数据隐私保护的异构缺陷预测方法,然而该方法要求目标项目存在少量已标记数据,这限制了其应用场景.Nam[7]等通过比较度量元之间的分布情况匹配源项目与目标项目的度量元,最后使用匹配得到的度量元组建立模型并对目标项目的缺陷情况进行预测.该方法对数据无特殊要求,适用于各种情况,且不改变原始数据,保证了数据的可读性,然而其存在以下2个问题:
1)度量元相似度计算方法不合理.Nam[7]等使用百分位数、K-S检验(Kolmogorov-Smirnov Test)、 spearman相关系数(Spearman′s correlation coefficient)3种方法计算度量元相似度.其中K-S检验法的实验效果最优,然而该方法直接使用p值作为两个度量元的相似度评分,这并不合理,p值仅能反应检验结果的显著性大小,与度量元相似度无实质关系.
2)预测性能不稳定.目前异构缺陷预测方法的有效性高度依赖于源项目与目标项目缺陷倾向的异同,在不考虑目标项目存在已标记数据的前提下,预先识别出这一点是非常困难的.
为解决上述2个问题,本文提出一种基于度量元相似度的多源异构软件缺陷预测方法(Multi-Source Heterogeneous Defect Prediction-Metric Similarity,MSHDP).具体来说:
1)针对问题1,MSHDP在K-S检验的基础上使用数据统计特征对度量元相似度进行计算.
2)针对问题2,MSHDP利用异构缺陷预测多源的特点将不同源项目构建的预测模型输出结果根据其相似度大小进行加权整合以得到最终的预测结果.
实验结果表明,MSHDP显著提高了异构缺陷预测的性能,缩小了与同项目缺陷预测的差距.
2 基于度量元匹配的异构软件缺陷预测
Nam[7]等提出了一种基于度量元匹配的异构软件缺陷预测方法(Heterogeneous Defect Prediction-Match Metrics,HDP-MM),本节简要介绍该方法并分析其存在的问题.
2.1 度量元选择
特征选择是一种常用的数据预处理过程,它从数据集的所有特征当中筛选出最为重要的几个特征,降低数据维度,有效减轻维数灾难问题;与此同时它去除了许多冗余、不相关的特征,提高了模型的预测性能.在HDP-MM中,使用信息增益比(gain ratio)对源项目数据集进行特征选择,保留排名前15%的度量元.
2.2 度量元匹配
通过匹配源项目数据集与目标项目数据集的度量元,HDP-MM将源项目的缺陷倾向信息迁移至目标项目.首先使用K-S检验计算每一对源项目度量元与目标项目度量元的相似度.K-S检验是一种比较两个样本的非参数统计检验,它无需事先明确样本的分布情况,这非常重要,因为数据集中可能存在未知的分布.在K-S检验中,p值的大小意味着是否有足够的理由拒绝零假设,即两个样本的分布情况是一致的.HDP-MM直接使用p值作为两个度量元的相似度评分,这并不合理,p值仅能反应检验结果的显著性大小,p值越大并不意味着度量元的相似度越高.为解决该问题,本文将在K-S检验的基础上使用数据统计特征对度量元相似度进行计算.
相似度评分计算完毕后,剔除评分小于0.05(统计检验中常用的显著性水平)的度量元组,最后将度量元匹配问题转换为二分图最大权匹配问题,利用K-M算法(Kuhn-Munkres algorithm)求得一组相似度评分之和最大且不包含重复度量元的度量元组.
2.3 模型建立
得到匹配的度量元组后,HDP-MM即可使用源项目数据集训练模型并对目标项目的缺陷情况进行预测.然而其预测性能高度依赖于源项目与目标项目缺陷倾向的异同,极不稳定.为解决该问题,本文将提出一种多源异构软件缺陷预测模型建立方法.
3 基于度量元相似度的多源异构软件缺陷预测
MSHDP的大致流程如图1所示.首先对源项目数据集进行特征选择,之后根据计算的度量元相似度匹配各个源项目与目标项目的度量元,最后基于得到的匹配度量元组建立多源预测模型预测目标项目的缺陷情况. 在3. 1、3. 2、3. 3节中将分别介绍度量元相似度计算、多源预测模型建立以及MSHDP 的详细步骤.
3.1 度量元相似度计算
异构软件缺陷预测的性能与源项目、目标项目的数据分布密切相关,K-S检验能够有效判别两组数据是否来自同一分布,因此HDP-MM在使用K-S检验时性能最优[7].然而直接使用p值作为度量元相似度评分是不合理的,原因如2.2节所述.本文在度量元匹配时,首先使用K-S检验(p>0.05)筛选出分布情况相似的度量元组,之后使用数据统计特征计算度量元相似度评分.
定义度量元i的统计特征向量SCVi={min,max,p10,…,p90,mean,std},分别为度量元i的最小值、最大值、第10百分位数~第90百分位数、均值、标准差.最小值、最大值和百分位数反应了数据的分布情况,均值反应了数据的集中趋势,标准差反应了数据的离散程度,因此该向量可以较好反应一组数据的各类特征.基于该统计特征向量计算度量元相似度,借鉴[7]中比较百分位数的做法,得到如下计算公式:
(1)
式(1)中MSij表示度量元i与度量元j的相似度评分,SCVi(k) 表示度量元i统计特征向量的第k个特征值.该公式分别计算统计特征向量中每一项的相似度,最后取均值作为度量元相似度评分,评分介于0-1之间,值越大意味着度量元相似度越高.
3.2 多源异构软件缺陷预测模型建立
HDP-MM的核心思想是将源项目的缺陷倾向信息迁移至目标项目以对目标项目的缺陷情况进行预测,其认为源项目与目标项目的缺陷倾向是一致的.然而在实际应用过程中,往往存在部分源项目缺陷倾向与目标项目不一致、甚至截然相反的情况,此时模型的预测效果就会不尽理想,这也是造成HDP-MM预测性能不稳定的根本原因.预先识别出源项目与目标项目的缺陷倾向是非常困难的,因为这需要目标项目提供部分已标记数据,这不在本文的讨论范围之内.基于一般常识,数据量越大,其能够提供的信息也就越多,建立的模型也就越高效.对于异构软件缺陷预测来说,由于不需要源项目与目标项目具有相同的度量元,往往可以收集并使用多个源项目数据集.本文将利用该特点提出一种多源异构软件缺陷预测模型建立方法.
为减少量纲差异在模型建立时造成的影响,首先对源数据集与目标数据集进行z-score标准化操作,其计算公式如下:
(2)
式(2)中x*(i)表示实例x第i个特征在z-score标准化后的值,x(i)表示实例x第i个特征的原值,μi表示特征i在整个数据集中的均值,εi表示特征i在整个数据集中的标准差.
在不考虑目标项目存在已标记数据的情况下,无法直接以预测结果为依据建立多源预测模型.本文认为源项目与目标项目的相似度越高,其蕴含的有效信息也就越多,构建的模型效果也越好.基于3.1节提出的度量元相似度计算方法,计算数据集相似度,其计算公式如下:
(3)
(4)
式(3)、(4)中DSij表示数据集i与数据集j的相似度评分,MSk表示第k对匹配度量元组的相似度评分,m表示数据集i与数据集j的匹配度量元组个数.式(3)假设数据集相似度与匹配度量元组个数没有关系,取所有匹配度量元组相似度均值作为数据集相似度;式(4)假设匹配度量元组个数越多数据集相似度就越高,取所有匹配度量元组相似度之和作为数据集相似度.后续将通过实验验证两种计算方法的有效性.
集成学习是一种常用的提高机器学习性能的方法,其通过构建并结合多个学习器来完成最终的学习任务.在异构缺陷预测场景下,不同源项目构建的模型即一个个基学习器,在得到每个源项目数据集与目标项目数据集的相似度后,可根据其相似度大小确定每个基学习器的权值,权值计算公式如下:
(5)
式(5)中ωij表示为预测项目j,基于项目i构建的预测模型应当设定的权值,m表示与项目j存在匹配度量元组的项目个数.最后使用计算得到的权值,整合所有基分类器的输出结果以得到最终的预测结果,其计算公式如下:
(6)
式(6)中Pj(x)表示对目标项目j实例x的最终预测结果,fkj(x)表示以项目k构建的基分类器对目标项目j实例x的预测结果.
3.3 MSHDP详细步骤
输入:源项目数据集SD1,SD2,…,SDi,目标项目数据集TD.
输出:对TD的预测结果.

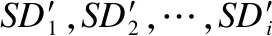
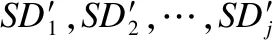

步骤7.使用数据集相似度DS1,DS2,…,DSj,根据式(5)计算基分类器f1,f2,…,fj的权值,得到ω1,ω2,…,ωj.
步骤8.使用匹配度量元组M1,M2,…,Mj、基分类器f1,f2,…,fj、权值ω1,ω2,…,ωj根据式(6)对数据集TD′进行预测,输出预测结果.
4 实验与分析
4.1 实验环境
本文使用Weka[10]、Apache commons math工具包进行实验.在特征选择、模型训练、模型评价上使用Weka默认实现,在统计检验上使用Apache commons math默认实现.
4.2 实验数据
本文收集了许多公开的数据集,包括AEEEM[11]、NASA[12]、PROMISE[13]、SOFTLAB[14]总计38个数据集.数据集详细信息如表1所示.
38个数据集被分为9组,同组的数据集具有相同的度量元.在进行异构缺陷预测时,源项目与目标项目需来自不同组以满足异构度量元的要求.
4.3 实验设计
为了验证MSHDP的有效性,本文将与WPDP、HDP-MM进行比较.所有方法都使用逻辑模型(Logistic)作为分类器原型.在实现WPDP时,与HDP-MM、MSHDP一样先对数据集进行特征选择,然后使用2折交叉验证(2-fold cross-validation)产生训练集、测试集,该过程保证训练集和测试集的缺陷率相同.同时为了减少随机性的影响,重复执行该过程500次,总计产生1000组数据.所有方法都使用这1000组数据对模型性能进行评估.
表1 实验数据集
Table 1 Experimental data sets

组特征数数据集实例数缺陷数缺陷比AEEEM71equinox32412939.81%jdt99720620.66%lucene691649.26%mylyn186224513.16%pde149720913.96%NASA137cm13444212.21%mw12642710.23%pc1705618.65%pc3112514012.44%pc4139917812.72%NASA221jm19593175918.34%kc252210720.50%NASA336pc21585161.01%NASA438mc19277680.73%pc5171865163.00%NASA539kc31943618.56%mc21274434.65%NASA694kc11456041.38%PROMISE20ant-1.774516622.28%arc2342711.54%camel-1.696518819.48%ivy-2.03524011.36%jedit-4.3492112.24%log4j-1.220518992.20%poi-3.044228163.57%prop-6606610.00%redaktor1762715.34%skarbonka45920.00%synapse-1.22568633.59%tomcat858778.97%velocity-1.62297834.06%xalan-2.790989898.79%xerces-1.458843774.32%SOFTLAB29ar112197.44%ar363812.7%ar41072018.69%ar536822.22%ar61011514.85%
4.4 评价指标
由于精确度、召回率等评价指标会受到阈值设定、类不平衡等问题的影响[15],本文使用受试者工作特征曲线下面积(AUC)作为预测模型的评价指标.AUC的取值范围在0~1之间,值越大模型的效果越好.
本文也统计MSHDP与WPDP、HDP-MM的胜负情况.每个方法在1个数据集上会得到1000个AUC值,使用威尔科克森符号秩检验(Wilcoxon Signed Rank Test)判断不同方法的AUC之间是否存在显著性差异.显著性水平设为0.05,当p<0.05时则认为两组数据存在显著性差异.当MSHDP的AUC中位数大于其它方法且存在显著性差异时,记MSHDP胜;当MSHDP的AUC中位数小于其它方法且存在显著性差异时,记MSHDP负;当不存在显著性差异时,记平局.
为了衡量MSHDP与WPDP、HDP-MM在AUC上的差异程度,本文还将计算Cliff′sδ[16].Cliff′sδ是一种非参数效应量检验,在软件缺陷预测领域被广泛使用[7-9].Cliff′sδ的取值介于-1~1之间,其评价标准如下[16]:极微弱(|δ|<0.147)、微弱(0.147≤|δ|<0.33)、普通(0.33≤|δ|<0.474)、显著(|δ|≥0.474).
4.5 实验结果分析
根据4.3节所述进行实验,实验结果见表2-表4所示.
表2 不同方法AUC中位数比较结果
Table 2 Comparison results among different methods in a median AUC
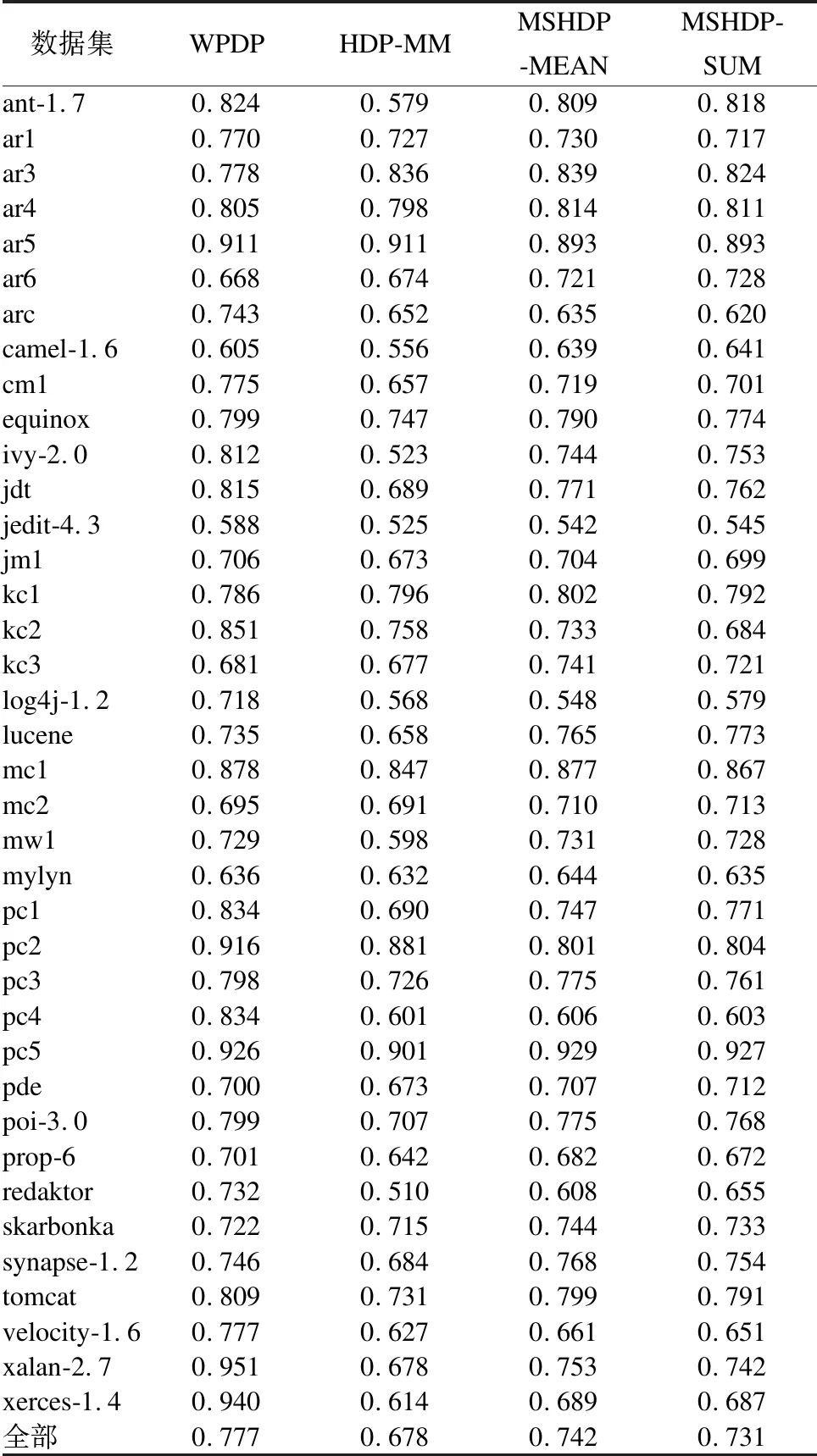
数据集WPDPHDP-MMMSHDP-MEANMSHDP-SUMant-1.70.8240.5790.8090.818ar10.7700.7270.7300.717ar30.7780.8360.8390.824ar40.8050.7980.8140.811ar50.9110.9110.8930.893ar60.6680.6740.7210.728arc0.7430.6520.6350.620camel-1.60.6050.5560.6390.641cm10.7750.6570.7190.701equinox0.7990.7470.7900.774ivy-2.00.8120.5230.7440.753jdt0.8150.6890.7710.762jedit-4.30.5880.5250.5420.545jm10.7060.6730.7040.699kc10.7860.7960.8020.792kc20.8510.7580.7330.684kc30.6810.6770.7410.721log4j-1.20.7180.5680.5480.579lucene0.7350.6580.7650.773mc10.8780.8470.8770.867mc20.6950.6910.7100.713mw10.7290.5980.7310.728mylyn0.6360.6320.6440.635pc10.8340.6900.7470.771pc20.9160.8810.8010.804pc30.7980.7260.7750.761pc40.8340.6010.6060.603pc50.9260.9010.9290.927pde0.7000.6730.7070.712poi-3.00.7990.7070.7750.768prop-60.7010.6420.6820.672redaktor0.7320.5100.6080.655skarbonka0.7220.7150.7440.733synapse-1.20.7460.6840.7680.754tomcat0.8090.7310.7990.791velocity-1.60.7770.6270.6610.651xalan-2.70.9510.6780.7530.742xerces-1.40.9400.6140.6890.687全部0.7770.6780.7420.731
表2展示了WPDP、HDP-MM、MSHDP-MEAN、MSHDP-SUM在38个数据集上的AUC中位数.表3展示了MSHDP-MEAN与WPDP、HDP-MM的胜负结果.表4展示了MSHDP-MEAN与WPDP、HDP-MM的Cliff′sδ效应量均值.从整体上看,WPDP性能最优,MSHDP-MEAN次之,MSHDP-SUM再次,HDP-MM最次.MSHDP-MEAN的AUC中位数在25个数据集上要优于MSHDP-SUM,因此可以认为MSHDP在使用式(3)计算数据集相似度时性能最优.与HDP-MM相比,MSHDP-MEAN的AUC在38个数据集上平均有0.064的提高,优于71.26%的HDP-MM,在效应量上也有0.415(普通)的优势,因此可以认为MSHDP显著提高了异构缺陷预测的性能.与WPDP相比,MSHDP-MEAN的AUC在38个数据集上平均有0.046的差距,不及57.89%的WPDP,在效应量上也有0.275(微弱)的差距,但相较于HDP-MM已大幅缩小了与WPDP的差距.WPDP是理论上软件缺陷预测的最优方法,MSHDP-MEAN能有如此表现甚至优于34.21%的WPDP是一个完全可以接受的结果.综上所述,本文提出的MSHDP方法显著提高了异构缺陷预测的性能,缩小了与同项目缺陷预测的差距.
表3 MSHDP-MEAN与WPDP、HDP-MM胜负结果
Table 3 Win/Tie/Loss results of MSHDP-MEAN against WPDP,HDP-MM
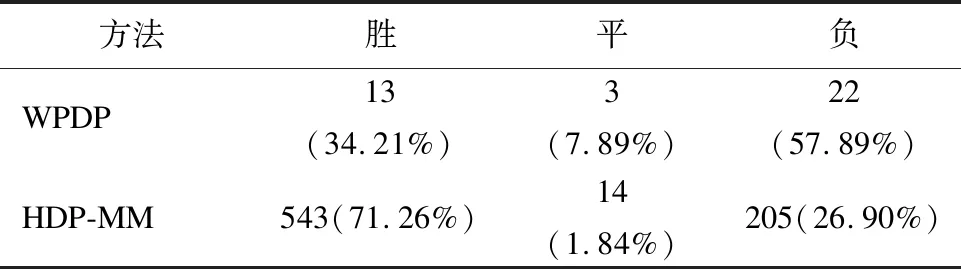
方法胜平负WPDP13(34.21%)3(7.89%)22(57.89%)HDP-MM543(71.26%)14(1.84%)205(26.90%)
表4 MSHDP-MEAN与WPDP、HDP-MM的Cliff′sδ均值
Table 4 Cliff′sδof MSHDP-MEAN against WPDP,HDP-MM in an average

方法Cliff′s δWPDP-0.275(微弱)HDP-MM0.415(普通)
5 总 结
为解决异构软件缺陷预测中度量元相似度计算方法不合理、预测性能不稳定的问题,本文提出一种基于度量元相似度的多源异构软件缺陷预测方法.该方法使用数据统计特征计算度量元相似度,并将不同源项目构建的预测模型输出结果根据其相似度大小进行加权整合以得到最终的预测结果.实验结果表明本文提出的方法显著提高了异构缺陷预测的性能,缩小了与同项目缺陷预测的差距.在后续工作中,将考虑实例与目标项目的相似度以进一步提高异构缺陷预测的性能.
