一种多维Turbo码盲识别方法*
2019-04-30范雪林鲁战锋
范雪林,鲁战锋,胥 桓
(中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引 言
Turbo码自1993年提出以来,因为优越的纠错性能和较低的编译码复杂度得到了广泛应用。经典的Turbo码通常采用PCCC结构,最常采用两个编码器进行编码,称为二维Turbo码。相对二维Turbo码,多维Turbo码由多个子编码器组成。研究发现,在同等信道条件下,采用多维Turbo码可以获得更好的编码传输增益,但这并不说明Turbo码维数越多越好。在具体工程实现时,维数的增多将带来系统复杂性的增加,因此选取时需同时兼顾编码性能和系统实现复杂度。
信道编码理论的不断发展,给智能通信和信息对抗带来了新挑战。目前,对信道编码的盲识别技术已经成为经久不息的研究热点,主要包括对线性分组码的盲识别分析。例如:文献[1]提出了一种基于码重分布信息熵的线性分组码盲识别方法,但是该方法需具备一定的先验条件,然后在此条件下通过统计熵值完成分组码的起点、长度等识别,具有一定的限制;文献[2]采用欧几里得完成对RS码字的识别分析;文献[3]则采用中国剩余定理算法完成对RS码字的识别分析。目前,对卷积码的盲识别分析更多集中在对1/n、(n-1)/n卷积码的识别,主要识别方法包括矩阵求解秩的分析方法[4-5]、基于Walsh-Hadamard变换[6]、基于求解校验序列[7]、基于改进的欧几里得[8]及基于改进高斯法[9]等。相较于卷积码,对Turbo码的盲识别研究起步较晚,最早可追溯到Ali Naseri及张永光等在2011年开始对经典Turbo码结构的二维码盲识别分析[10-11]以及2016年范雪林等开展的双二元Turbo码盲识别分析[12]。
鉴于对多维Turbo码盲识别分析较为少见,本文在对比特流和编码器结构综合分析的基础上,实现了对多元Turbo码盲识别的分析。
1 多维Turbo码介绍
多维Turbo码通过牺牲硬件的复杂度达到更高的编码性能。传统的Turbo码采用2个并行的递归卷积码作为分量码,而在多维Turbo码中分量码增加为J个,如图1所示。

图1 双二元Turbo码编码器
从图1可以看出,多维Turbo码采用多个分量编码器,分量编码器结构可以相同也可以不同;分量编码器前输入数据序列采用相同或者不同的交织器。因此,对多维Turbo码的识别分析需要识别的未知参数包括码率、码字起始位置、分量编码器参数和交织参数(交织长度、交织关系、交织起点等)等识别。
2 多维Turbo码降维分析
多维Turbo码与经典Turbo码识别最主要的区别在于编码维数较高。待识别的数据流比特由多个支路编码输出数据组合而成,无法直接利用常规的Turbo码编码盲识别分析算法,需通过对其数据流比特即编码器结构分析实现多维Turbo码的降维转换,最终转化为常规Turbo码的盲识别分析。因此,对多维Turbo码的降维分析是对多维Turbo码盲识别分析的关键。
根据图1多维Turbo码的编码结构,系统输出Turbo编码后的数据流可表示为:

可以看出,各个支路输出比特间隔区间与Turbo码的维数J相关,各个支路输出的校验比特与输入序列存在一定的线性关系。该线性关系可能直接由分量编码器产生,或由交织器及分量编码器共同产生。对一个完整的交织块数据的输入数据序列与各个支路的校验序列进行最低约束关系求解后,可以获得一个与维数相关的最低秩数据表现,即将输入和校验序列作为编码器的识别数据序列,并排列成p×q(p>q)的矩阵。当q为J+1的整数倍时,此时对该矩阵进行去相关计算,矩阵的秩将小于q。这是因为当矩阵每行按照J+1的整数倍排列时,输入序列的数据序列和校验序列在列上对齐。此时,由于在一个约束长度内的约束关系相同,表现为线性相关,故此时去相关处理后,其秩小于q。
定理1 对J维的多维Turbo码,编码后序列排列为p×q(p>q)的矩阵,当q为J+1的整数倍时,对矩阵去相关运算,此时矩阵秩小于q。
根据定理1,即可实现对多维Turbo码的编码维数、编码起始位置识别,然后在此基础上完成对数据比特流的降维处理。将数据比特流组合为:

至此,完成对多维Turbo码的降维分析。
3 多维Turbo码参数盲识别
式(2)中第一个降维后,比特流支路为1/2率卷积码。此时,通过采用常规的1/2率卷积码盲识别方法,即可实现对卷积码第一个分量编码器的参数识别。对其他支路的交织参数和分量编码器参数识别,主要依靠对信息序列与其交织后序列存在一定的相关关系完成。图2为分量编码器结构图。

图2 多维Turbo码RSC子编码器
分析结构,可知:

观察图2中寄存器结果,由dk得到vk的寄存器结构与自同步加扰器结构类似,因此对vk进行一次自同步加扰即可得到dk,再根据式(3)得到uk,此时即可完成对交织后数据序列的识别。在此基础上,对交织参数的识别如定理2。
定理2 由信息序列与其经交织后得到的交织序列进行交叉组合得到的新序列,如果其交织深度为L,那么对该序列组成的p×p(p为2L的a倍)方阵进行去相关处理化后,其左上角单位阵的维数必不大于p/2(1+1/a),且当交织起点与方阵起点重合时,此时矩阵秩最小。
因此,虽然在求解交织后的序列时涉及到自同步扰码器的初始状态选择,但是根据上述定理,将每次所求的uk序列和Turbo码的信息序列进行组合得到新的分析序列会出现定理2所描述的结果,从而确定交织深度L和交织起始位置。
在此基础上,根据交织仅对数据位置进行置换,且根据每次置换位置固定的原理,通过对连续多帧采样数据重量计算,根据交织前后各点重量的前后对比完成交织置换关系的确认。
4 识别举例
以CCSDS系统中规定的多维Turbo码进行编码参数盲识别分析,图3为CCSDS协议使用的多维Turbo码编码器结构。
从图3可以看出,CCSDS协议中使用的Turbo码最大维数为7维,1、2、3支路数据未经过交织直接送入分量编码器完成编码,第3、4、5支路编码数据经过交织后输入分量编码器完成编码。对CCSDS系统Turbo码的识别主要包括编码维数、分量编码器参数和交织参数等。

图3 CCSDS Turbo编码器
以交织深度1 784的4维Turbo码识别为例。此时,第一个分量编码器输出第1、2支路编码后数据,第二个分量编码器输出第一路编码后数据,可获得比特流数据为:

根据定理1对其维数识别的结果如图4所示。随着码长N的增加,周期性出现谷底,周期为4。对编码起始位置识别的结果如图5所示。

图4 维数识别结果
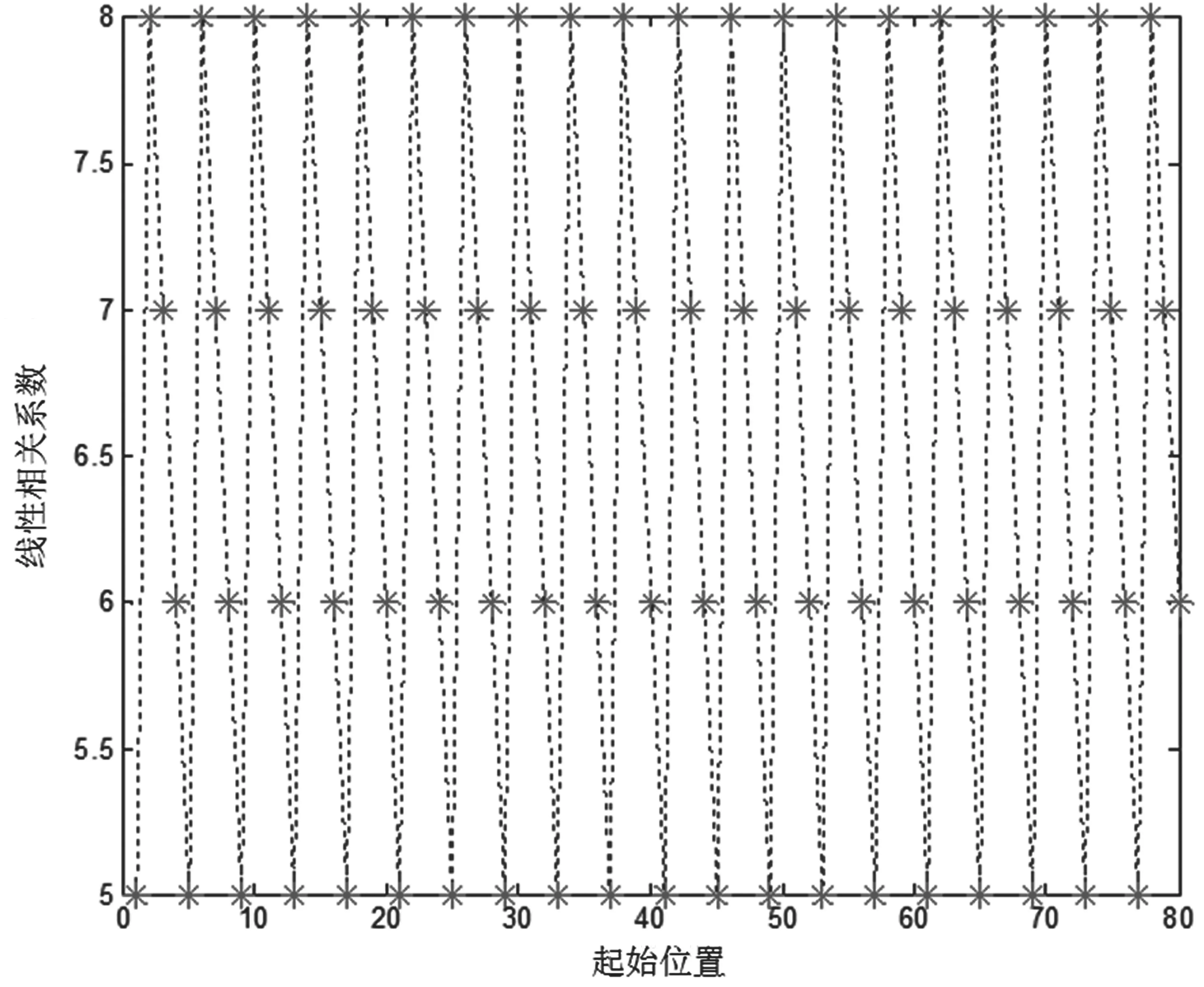
图5 多维Turbo码起始位置识别结果
图5 中以4n+0为起点时,周期出现最低秩,因此起始位置为0。
此时,按照以上识别结果对数据流进行降维处理,形成如式(6)表示的3个比特流数据:

对3个支路的比特流识别的结果如图6所示。
可见,其中一个支路与第一个支路组合进行识别未能成功识别出任何码字,而另外两个支路与第一个支路组合进行识别可以得到(2,1,5)卷积码。通过对uiv1,iv2,i支路数据进行去相关处理,可得到相应卷积码的编码器参数识别结果,如图7所示。

图6 支路信息识别结果

图7 分量编码器参数识别结果
根据图7所识别约束关系结果,可获得编码多项式识别结果:

其中g为反馈多项式,f1为v0支路的前向多项式,f2为v1支路的前向多项式。
在子编码器参数识别的基础上,结合式(3),完成第二个分量编码器输入序列(即对uk交织后的序列)识别,并将其与uk序列进行交叉组合成交织分析序列。按照定理2,可获得交织长度和起始位置识别结果如图8所示。

图8 交织长度识别结果
对交织关系的识别通过对多帧数据计算汉明重量并进行比对,图9为多帧数据进行汉明比对过程。可见,在进行至435帧时,完成了所有交织置换关系的确认。

图9 交织识别结果
5 结 语
相较于经典Turbo码,多维Turbo码引入了多个子编码器,因此对其盲识别的关键因素在于通过降维处理转换为经典Turbo码的盲识别方法。本文在对多维Turbo编码器结构深入分析的基础上,通过降维处理,将数据比特流转化为普通RSC编码数据流,并在此基础上完成编码器结构参数分析,以求解自同步扰码的方式实现对交织后序列的恢复,最终完成交织参数识别分析。最后,文章以CCSDS协议规定的1/4率多维Turbo码为例对识别算法进行验证,证明了方法的有效性。
