深度学习在藻类分类识别中的应用
2019-04-24万永清张奇志
万永清 张奇志
北京信息科技大学 自动化学院,北京 100192
一、引言
随着人口的增加,工农业的快速发展,人民生活水平的提升,在享受生活便利的同时,也加剧了对水生态系统的破坏。大量含有营养物质的工业废水和生活污水的排放导致水体富营养化,使得藻类大量迅速繁殖[1],并引起水华或者赤潮现象,破坏了生态系统,所以对赤潮或者水华现象进行监测和预测是迫在眉睫的任务。
藻类的种类和数量是水华或者赤潮的关键指标,常规方法是人工检测,这种方法存在很大的缺陷:对员工的技能和熟练度要求很高,而且在大量检测过程中,员工容易疲劳和缺乏客观性,使得检测结果不合格、错误率高。
藻类分类识别一直是生物学领域的一个热点问题,有很多人在研究,现在有很多使用传统识别算法替代人工检测,取得一定的效果,但还是有很多局限性。
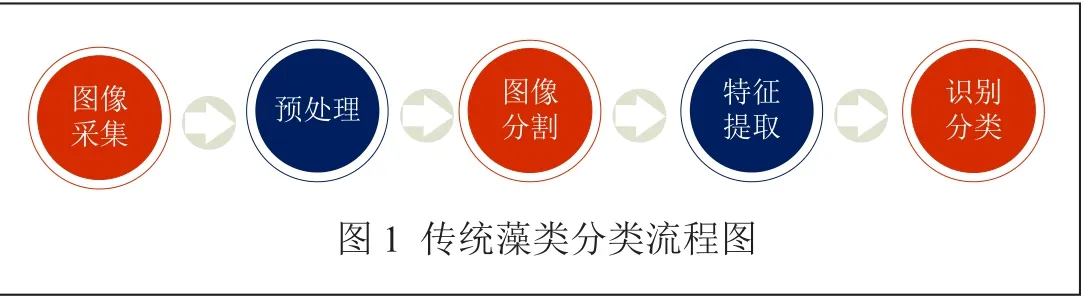
传统的藻类图像识别过程中,通常需要对采集到的各种藻类图像进行各种预处理,为了得到好的特征,还需要对预处理后的图像进行分割,得到目标物,最后还得进行人工选取特征。其中,张松等[2]传统识别算法识别三种藻类,最终的分类正确率为83.3 %。这种采取传统的人工选取特征的方法获得识别率不是很高,而采用深度学习方法可以化繁为简,自动选择特征,较好地解决这些问题。
本文提出了使用现在图像识别领域应用比较广泛的深度学习工具Caあe来做藻类分类,设计出深度学习网络模型,对设计的几种网络模型进行比较,得到最优的模型,然后对测试集进行测试。实验表明,基于深度学习模型的藻类分类,可以得到优于前人的结果,达到100 %的识别率。
二、藻类识别的复杂性与传统识别算法的问题
1、藻类识别的复杂性
藻类识别是藻类计数很重要的一个环节,其过程比较复杂,藻类识别的复杂性分为人工镜检复杂性和传统算法识别复杂性两方面。
(1)人工镜检复杂性
通常,藻类分类计数的数量特别大,成百上千,甚至更多,而且需要连续观察。如果操作者在高倍显微镜下长时间用肉眼观察,容易导致视力损伤和精神疲劳。操作者在进行人工镜检之前,需要学习大量藻类知识,而且得非常熟练地掌握藻类知识。他们主要是根据藻类的形状区别藻类,但也只能检测出典型的藻类,对于相似的藻类很难区别。而中国具有大约8900多种淡水和海洋藻类,操作者很难记忆这么多藻类,这样就会出现由人工经验不足而导致误检。在环境检测中,通常需要对藻类分类和计数,镜检时,由于藻类数量大,种类多,导致无法对已经检出的藻类进行标记而使得漏检或者误检[3]。
(2)传统算法识别复杂性
传统算法做藻类分类的基本步骤如图1所示。传统算法识别复杂性在于:优质藻类样本图像获取;噪声图像预处理;使用图像分割技术得到好的目标检测物;选取好的藻类特征。
在得到优质藻类样本图像时,通常会遇到聚焦均匀性问题和杂质干扰问题。通常得到的图像由于在图像信号转变为数字信号的时候,有些原有的特征遭到破坏,使得图像出现噪声,有畸变,需要得到特征明显的图像,这时需要对图像做预处理。
常用的操作有图像增强、图像锐化、数学形态学。通过灰度变换、直方图修正、噪声处理等图像增强算法来改变图像的亮度、对比度或者灰度分布情况等。赵文仓[4]等人利用数学形态学提取特征方法对17种浮游植物进行识别实验,达到95 %以上的正确率。
图像分割是藻类识别中很重要的一环,其主要将目标物藻类与背景分离,后面的特征选择及识别的准确性取决于分割效果的好坏。常用的分割算法有基于边缘和基于区域两大类,使用其中一种算法很难取得好的效果,通常是结合两者的优势。王迪[5]在藻类识别过程中边缘分割和基于区域的阈值分割相结合的分割方法。
在进行藻类识别中,选择好的特征非常重要,通常由多个特征组成特征集,其特征有颜色特征、空间关系、形状特征、纹理特征等。
人们区别物体时,很多时候是根据物体的形状来区别,形状也是最基本的分类标准。提取形状特征有基于目标区域和基于物体轮廓形状特征两种方法。基于物体轮廓形状特征法只考虑物体的轮廓也就是边界,不需要考虑目标物体的具体内容,其描述方法通常有几何特征、傅里叶描述符、链码等。其中,根据全局几何特征,定义物体的几何特征参数,就能区别差异比较大的检测物,进行粗分类;傅里叶描述符的计算方法基于傅里叶变换,使用该种方法,提取特征就更复杂。基于目标区域形状特征法是从目标的整体出发,全面反应检测物体的所有特征。在经过图像分割后得到检测物区域,分析区域内的每个像素得到形状特征。其中,矩特征在区域形状特征中应用最广泛,有中心矩和几何矩,但由于几何矩对图像不具有不变性,中心矩对图像的旋转也不具备不变性,都不满足要求,需要经过各种变换处理得到不变矩。
纹理是物体的天然特征,不同的物体其纹理不同,就算是同一个物体其纹理也会不同,通过区分纹理可以把物体区分开来。图像纹理的分析方法有频谱分析法、统计分析法、模型分析法、结构分析法等。常用的纹理提取算法有很多,但涉及知识点多,计算复杂。
2、传统藻类识别算法的问题
为了获取好的藻类特征,通常在前期需要分析采集到的藻类图像,接着对图像处理和图像分割。选取藻类图像的可取的特征进行各种变换处理,找到合适的分类器,进行识别分类。而使用深度学习进行藻类识别,不需要这么多繁琐处理就能取得很好的效果。只要设计好网络结构,有好的数据集,在训练时调节好参数,就能达到理想。
三、藻类分类识别流程
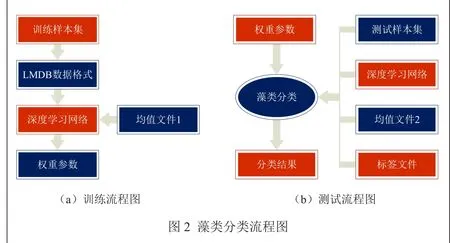
本文分为训练和测试分类两阶段。训练阶段,首先准备藻类图片样本集,把训练样本集图片格式文件转换为LMDB格式文件,获取像素均值文件,配置网络参数,然后通过设计好的深度学习网络对训练集进行训练,调节参数,获得权重参数。在预测分类阶段,把测试样本集转换为LMDB格式,加载训练使用的深度学习网络结构、训练得到的权重参数和标签文件,得到预测藻类类别排序,得分由高到低,第一个即为预测到的类别。藻类分类识别总的流程图如图2。
四、深度学习
机器学习是人工智能技术最活跃的研究领域,而深度学习是机器学习应用最广泛的分支之一。深度学习是通过提取具体的低层特征形成抽象的高层来发现数据分布式特征。常见的深度学习模型有卷积神经网络(Convolutional neural network,CNN)、循环卷积神经网络和堆栈式自编码器等[6]。本文使用基于Caあe的CNN,使用softmax作为分类器。
本文采用的深度学习模型卷积神经网络是图像分类识别研究领域的热点,比传统神经网络有更多的优势。卷积神经网络的结构借鉴生物神经网络结构,优于传统神经网络,区别于传统神经网络的地方主要在网络中非全连接的神经元和同一层中共享部分神经元的权值。非全连接时,可以大大降低神经网络模型的复杂性。神经元的权值共享可以使需要计算的权值数量大大减少。网络的非全连接和权值共享使得网络的泛化能力大大增强。
CNN的优势对于输入为图像数据时则表现得非常明显,将图像看作是数据,以图像数据作为输入,可以减少传统图像识别中图像处理的复杂过程。CNN的多层感知器结构具有一个很好的优势,在于其对比例缩放、平移、倾斜或者其他形式的变形具有高度不变性。
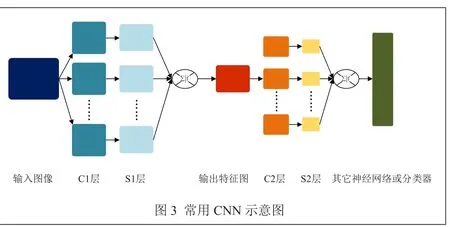
为了说明CNN结构,选择图像为输入数据,其一般的网络结构如图3所示。输入图像经过n个可训练的滤波器和可加偏置进行卷积运算得到C1层特征图,对C1层的特征图进行池化操作,得到S1层,对S1层特征图求和,带入激活函数得到经过卷积的特征图,类似这样经过若干次卷积、池化、经过激活函数,得到最终的特征图,此特征图经过全连接,连接成一个向量,根据实际的需求,接入其他神经网络或者分类器。
五、实验及结果分析
1、实验
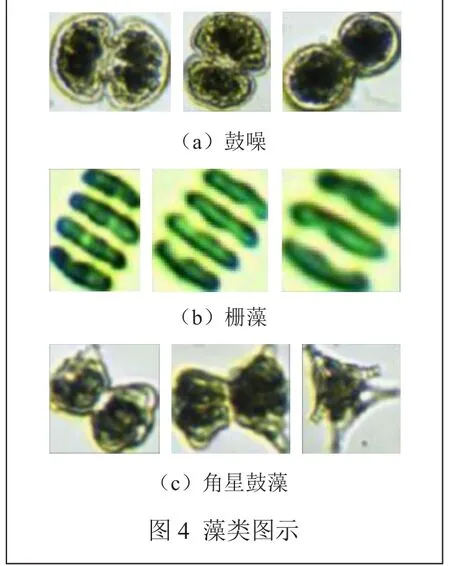
本文使用文献[2]相同的数据集,使用设计的深度学习模型进行训练和测试,对鼓噪、栅藻、角星鼓藻三类藻类分类进行验证。三种藻类分别如图4所示。
训练样本每类100张,总共300张,测试样本每类10张,总共30张,识别正确率计算公式为:

其中,n —测试集中识别正确的藻类数量;N —整个测试集藻类的数量。
实验平台为UBuntu 16.04系统,使用深度学习工具Caあe,基于GTX 960M显卡测试和训练。
对于使用的深度学习网络,训练次数、网络层数、学习率3个核心参数,本文选取多种组合,并分析算法性能的影响。选取深度学习网络层数为8,选取一定的训练次数和学习率,其所测的loss值如表1,学习率与loss值关系如图 5(a)。选取训练次数为1000,选取一定的学习率和网络层数,其所测的loss值如表2,网络层数与loss值关系如图5(b)。选取学习率为0.001,选取一定的网络层数和训练层数,其所测的loss值如表3,训练次数与loss值关系如图5(c)。
2、实验结果分析
由图5可以看出,不同的训练次数、网络层数和学习率对loss值有很大影响。在设计深度学习网络结构时,需要考虑这些重要参数。
由图5(a)可以看出,当网络层数为8层,学习率为0.01,随着训练次数增加,loss值几乎不变;当学习率为0.001和0.0001时,随着训练次数增加,loss值下降很快,慢慢趋于稳定,但是在学习率为0.001时,loss值下降更快,在相同训练次数时,loss值更小,效果越好,说明并不是学习率越小越好,需要根据实际需求选取一个合适的学习率。
由图5(b)可知,在学习率为0.01时,随着网络层数增加,loss值开始不变,直到网络层数为8时,loss值才改变,但是loss还是太大,不能达到要求;在学习率为0.001和0.0001时,随着网络层数的增加,loss值先减小,后增加,学习率越小,loss值越好,说明并不是网络层数越多越好。
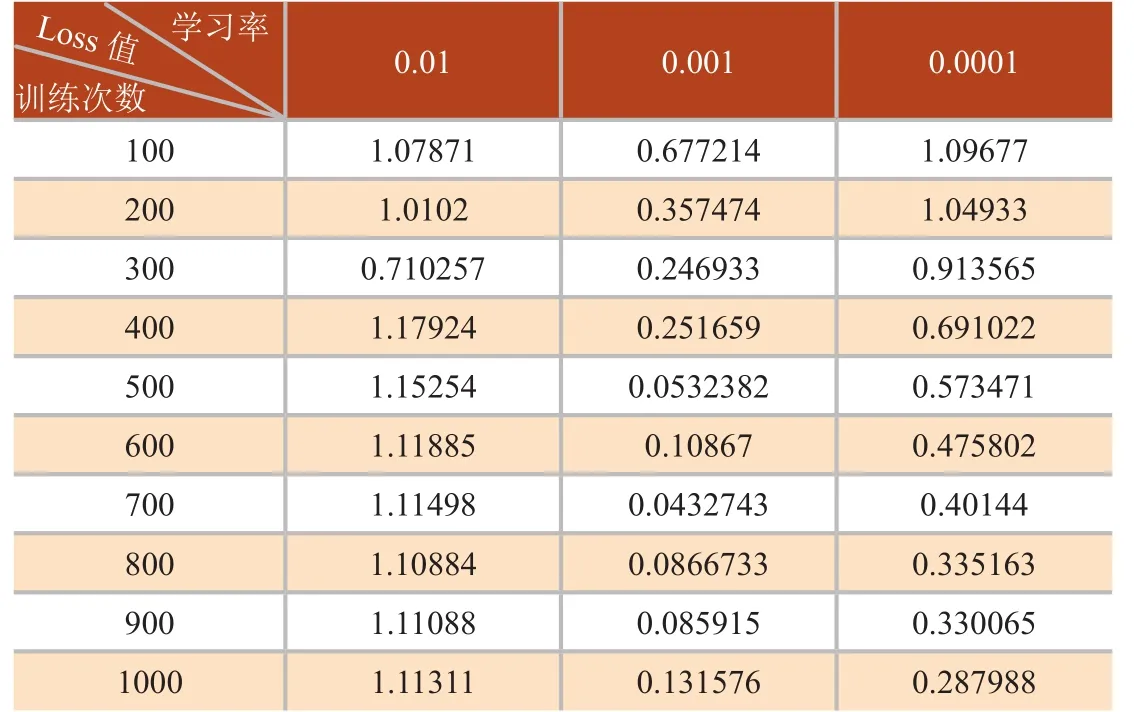
表1 网络层数为8所测的loss值
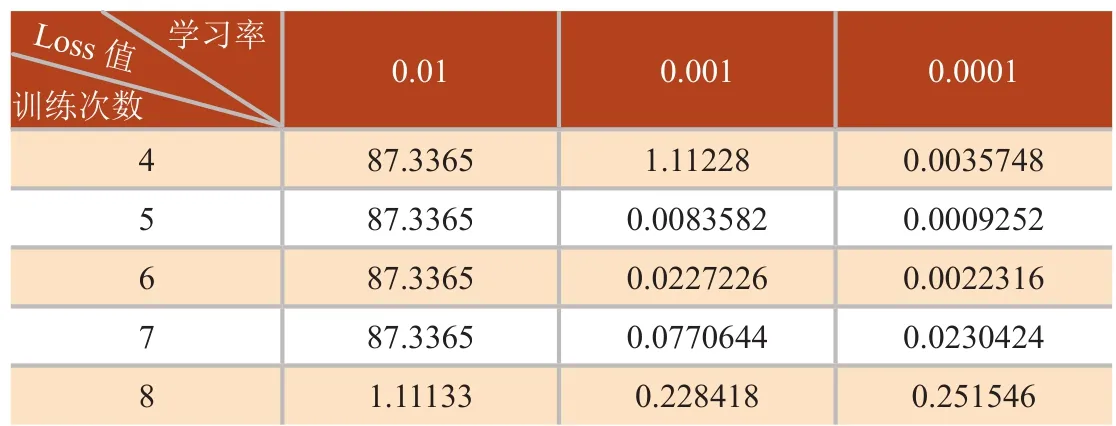
表2 训练次数为1000所测的loss值
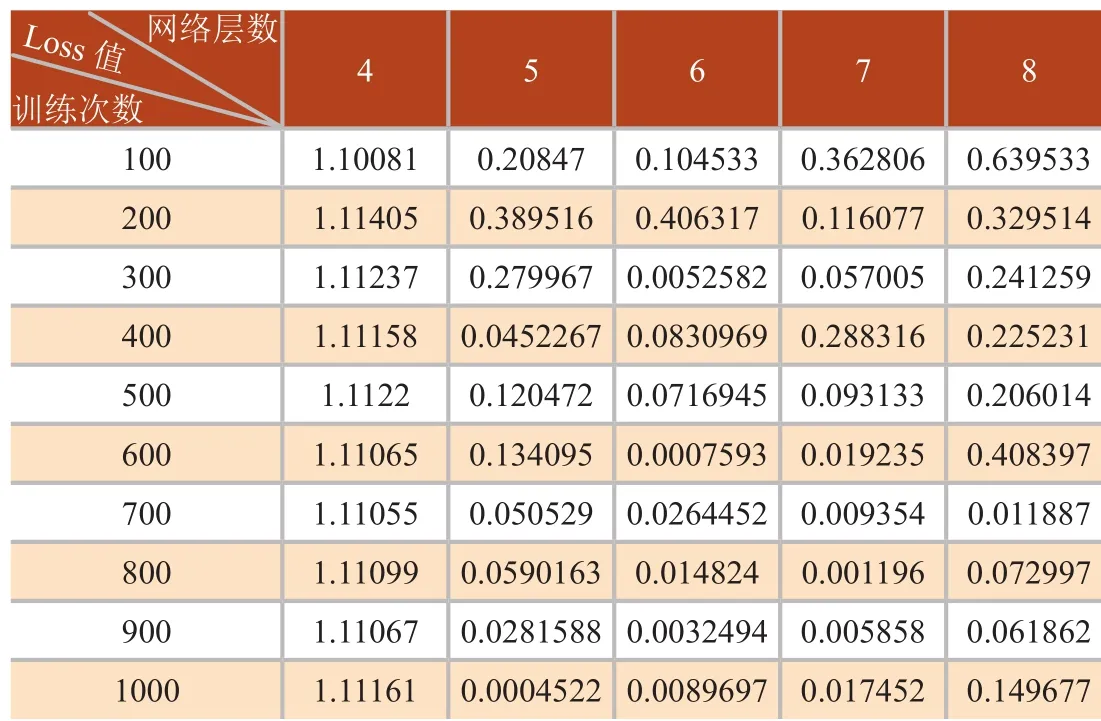
表3 学习率为0.001所测的loss值
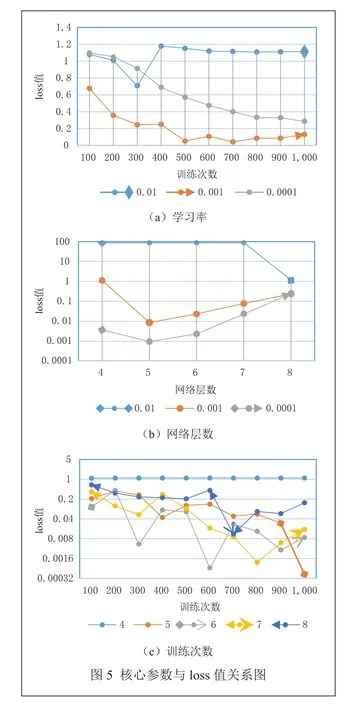
由图5(c)可知,当网络层数为4时,随着训练次数增加,loss值几乎不变,而且loss值大于1不满足要求;当网络层数大于4,随着训练次数增加,loss值都在震荡,但总体在减小,但是减小的程度不一样;层数为5时,loss值随着训练次数增加,其值越来越小,效果越来越好。
经过对实验结果进行分析,本文最终选择网络层数为5,学习率为0.001,训练次数为1000的深度学习模型对训练数据集进行训练,得到权重参数,然后对所使用的数据集进行测试,可以达到100 %的识别率,优于该论文中的83.3 %的识别率。
六、结束语
本文提出一种基于深度学习的藻类分类识别的方法,通过设计一种卷积神经网络自动学习藻类的特征,从而避免传统人工选取特征困难。通过实验对比设计的几种模型,选取最优的模型,对测试数据集进行测试,得到100 %的识别率。由于本实验所使用的训练集和测试集的藻类种类较少,但工程实践中,需要识别的藻类种类非常多,下一步,应该增加藻类的种类进行实验。
